大家好,又见面了,我是你们的朋友全栈君。
ES数据库
文章目录
一、入门
1.索引
索引:名词时,类似于传统数据库中的数据库概念;
动词类似于插入这一概念。
eg:
对于员工目录,我们将做如下操作:
- 每个员工索引一个文档,文档包含该员工的所有信息。
- 每个文档都将是
employee类型 。 - 该类型位于 索引
megacorp内。 - 该索引保存在我们的 Elasticsearch 集群中。
操作如下:
PUT /megacorp/employee/1 -- 这里包含了索引名称、类型名词、特定雇员id
{
"first_name" : "John",
"last_name" : "Smith",
"age" : 25,
"about" : "I love to go rock climbing",
"interests": [ "sports", "music" ]
} -- 这里为具体内容
注意,路径 /megacorp/employee/1 包含了三部分的信息:
-
megacorp索引名称
-
employee类型名称
-
1特定雇员的ID
请求体 —— JSON 文档 —— 包含了这位员工的所有详细信息,他的名字叫 John Smith ,今年 25 岁,喜欢攀岩。
2.搜索
– 检索文档(id匹配)
执行 一个 HTTP GET 请求并指定文档的地址——索引库、类型和ID。 使用这三个信息可以返回原始的 JSON 文档
GET /megacorp/employee/1
返回结果包含了文档的一些元数据,以及 _source 属性,内容是 John Smith 雇员的原始 JSON 文档:
{
"_index" : "megacorp",
"_type" : "employee",
"_id" : "1",
"_version" : 1,
"found" : true,
"_source" : {
"first_name" : "John",
"last_name" : "Smith",
"age" : 25,
"about" : "I love to go rock climbing",
"interests": [ "sports", "music" ]
}
}
_source里面是原json文档
将 HTTP 命令由 PUT 改为 GET 可以用来检索文档,同样的,可以使用 DELETE 命令来删除文档,以及使用 HEAD 指令来检查文档是否存在。如果想更新已存在的文档,只需再次 PUT 。
– 轻量搜索(Query-string 搜索)
a.查询所有雇员信息(返回结果包括了所有三个文档,放在数组 hits 中。一个搜索默认返回十条结果。)
GET /megacorp/employee/_search
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kHlpYDpg-1616748970350)(C:\Users\EDZ\AppData\Roaming\Typora\typora-user-images\image-20210323113245618.png)]](https://img-blog.csdnimg.cn/20210326165649390.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kHlpYDpg-1616748970350)(C:\Users\EDZ\AppData\Roaming\Typora\typora-user-images\image-20210323113245618.png)]](http://javaforall.cn/wp-content/themes/justnews/themer/assets/images/lazy.png)
b.带初步的筛选
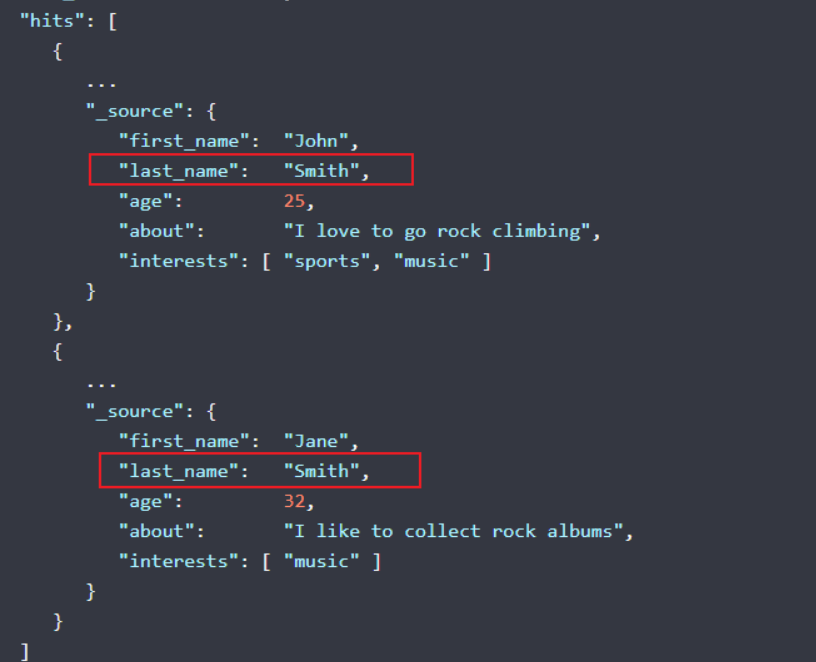
GET /megacorp/employee/_search?q=last_name:Smith
仍然在请求路径中使用 _search 端点,并将查询本身赋值给参数 q= 。返回结果给出了所有的 Smith:
– 使用查询表达式搜索
领域特定语言 (DSL), 使用 JSON 构造了一个请求。我们可以像这样重写之前的查询所有名为 Smith 的搜索 :
GET /megacorp/employee/_search
{
"query" : {
"match" : {
"last_name" : "Smith"
}
}
}
请求使用 JSON 构造,并使用了一个 match 查询(属于查询类型之一,后面将继续介绍)。
– 更复杂的搜索(添加过滤)
同样搜索姓氏为 Smith 的员工,但这次我们只需要年龄大于 30 的。查询需要稍作调整,使用过滤器 filter ,它支持高效地执行一个结构化查询。
GET /megacorp/employee/_search
{
"query" : {
"bool": {
"must": {
"match" : {
"last_name" : "smith"
}
},
"filter": {
"range" : {
"age" : { "gt" : 30 }
}
}
}
}
}
a. 这部分与我们之前使用的 match 查询 一样。
b. 这部分是一个 range 过滤器 , 它能找到年龄大于 30 的文档,其中 gt 表示_大于_(great than)。
现在结果只返回了一名员工,叫 Jane Smith,32 岁。
– 全文搜索
全文搜索,搜索下所有喜欢攀岩(rock climbing)的员工
GET /megacorp/employee/_search
{
"query" : {
"match" : {
"about" : "rock climbing"
}
}
}
使用match 查询在about 属性上搜索 “rock climbing” 。

这是一个很好的案例,阐明了 Elasticsearch 如何 在 全文属性上搜索并返回相关性最强的结果。Elasticsearch中的 相关性 概念非常重要,也是完全区别于传统关系型数据库的一个概念,数据库中的一条记录要么匹配要么不匹配。
– 短语搜索
想要精确匹配一系列单词或者_短语_ ,以短语 “rock climbing” 的形式进行匹配。
GET /megacorp/employee/_search
{
"query" : {
"match_phrase" : {
"about" : "rock climbing"
}
}
}
毫无悬念,返回结果仅有 John Smith 的文档。
– 高亮搜索
在每个搜索结果中 高亮 部分文本片段,以便让用户知道为何该文档符合查询条件。在 Elasticsearch 中检索出高亮片段也很容易。
再次执行前面的查询,并增加一个新的 highlight 参数:
GET /megacorp/employee/_search
{
"query" : {
"match_phrase" : {
"about" : "rock climbing"
}
},
"highlight": {
"fields" : {
"about" : {}
}
}
}
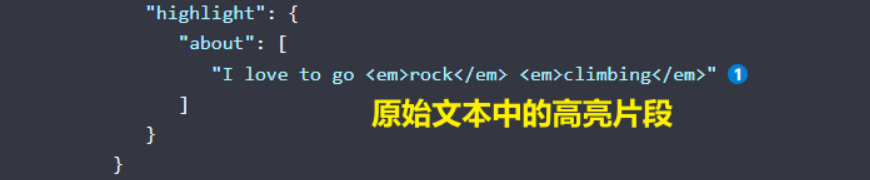
当执行该查询时,返回结果与之前一样,与此同时结果中还多了一个叫做 highlight 的部分。这个部分包含了 about 属性匹配的文本片段,并以 HTML 标签 <em></em> 封装:
– 分析(聚合功能aggregation)
聚合与 SQL 中的 GROUP BY 类似但更强大。
挖掘出员工中最受欢迎的兴趣爱好:
GET /megacorp/employee/_search
{
"aggs": {
"all_interests": {
"terms": { "field": "interests" }
}
}
}
返回
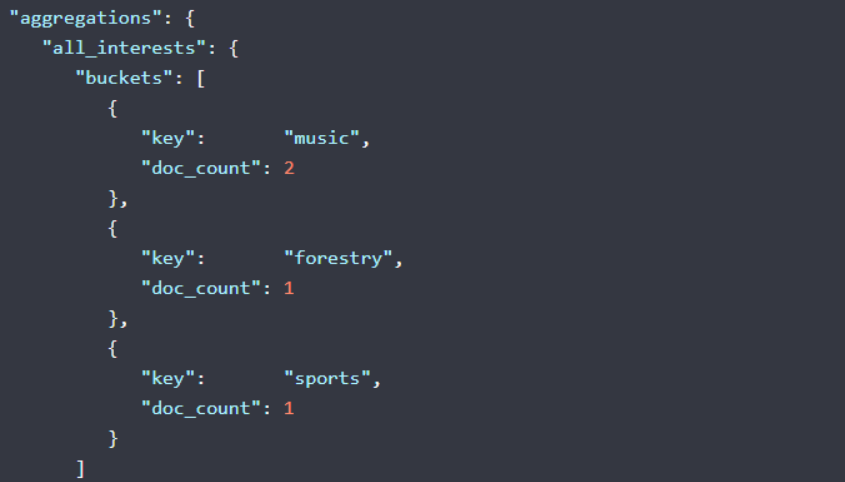
两位员工对音乐感兴趣,一位对林业感兴趣,一位对运动感兴趣。
叫 Smith 的员工中最受欢迎的兴趣爱好,可以直接构造一个组合查询:
GET /megacorp/employee/_search
{
"query": {
"match": {
"last_name": "smith"
}
},
"aggs": {
"all_interests": {
"terms": {
"field": "interests"
}
}
}
}

聚合还支持分级汇总 。比如,查询特定兴趣爱好员工的平均年龄:
GET /megacorp/employee/_search
{
"aggs" : {
"all_interests" : {
"terms" : { "field" : "interests" },
"aggs" : {
"avg_age" : {
"avg" : { "field" : "age" }
}
}
}
}
}

参考:
参考文档1
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/135189.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
