大家好,又见面了,我是你们的朋友全栈君。
当一个数据表的数据量达到千万级别以后,每次查询都需要消耗大量的时间,所以当表数据量达到一定量级后我们需要对数据表水平切割。水平分区分表就是把逻辑上的一个表,在物理上按照你指定的规则分放到不同的文件里,把一个大的数据文件拆分为多个小文件,还可以把这些小文件放在不同的磁盘下。这样把一个大的文件拆分成多个小文件,便于我们对数据的管理。
下面我们来创建表分区
代码创建分区表
添加文件组
代码格式:
ALTER DATABASE <数据库名称> ADD FILEGROUP<文件组名>代码示例:
ALTER DATABASE TestDb ADD FILEGROUP TestDbFileGroup添加文件
代码格式:
ALTER DATABASE<数据库名称>ADD FILE <数据标识> TO FILEGROUP<文件组名称> 注意:数据标识中name为逻辑文件名、filename为物理文件路径名、size为文件初始大小(单位:kb/mb/gb/tb)、filegrowth为文件自动增量(单位:kb/mb/gb/tb)、maxsize为文件增大的最大大小(单位:kb/mb/gb/tb/unlimited)
代码示例:
ALTER DATABASE TestDb ADD FILE (
NAME='TestFile1',
FILENAME='D:\ProgramFiles\Microsoft SQL Server\MSSQL\DATA\TestFile1.mdf',
SIZE=5MB,
FILEGROWTH=5MB)
TO FILEGROUP TestFileGroup定义分区函数
分区函数是用于判定数据行该属于哪个分区,通过分区函数中设置边界值来使得根据行中特定列的值来确定其分区。
代码格式:
CREATE PARTITIONFUNCTION partition_function_name(input_parameter_type )
ASRANGE[ LEFT | RIGHT ]
FORVALUES( [ boundary_value [ ,...n ] ]) 其中“LEFT”和“RIGHT”决定了“VALUES”中的边界值被划分到哪一个分区中(即,边界值属于左侧分区还是右侧分区)。
代码示例:
CREATE PARTITIONFUNCTION TestPartitionFunction(datetime2(0))
ASRANG ERIGHT
FORVALUES('2018-01-01 00:00:00','2019-01-01 00:00:00')查看分区函数是否创建成功:
SELECT *FROM sys.partition_functions定义分区架构
定义完分区函数仅仅是知道了如何将列的值区分到了不同的分区,而每个分区的存储方式,则需要分区构架来定义。分区构架仅仅是依赖分区函数.分区构架中负责分配每个区属于哪个文件组,而分区函数是决定如何在逻辑上分区。
代码格式:
CREATE PARTITIONSCHEME partition_scheme_name
ASPARTITION partition_function_name [ ALL ]
TO( { file_group_name | [ PRIMARY ] } [ ,...n ])代码示例:
CREATE PARTITIONSCHEME TestPartitionScheme
ASPARTITION TestPartitionFunction
TO (TestFileGroup,[PRIMARY],TestFileGroup)查看分区架构是否创建完成:
SELECT *FROM sys.partition_schemes定义分区表
表在创建的时候就已经决定是否是分区表了。虽然在很多情况下都是你在发现已经表已经足够大的时候才想到要把表分区,但是分区表只能够在创建的时候指定为分区表。
代码格式:
CREATE TABLE table_name(
...
) ON partition_scheme_name(column_name)代码示例:
CREATE TABLE dt(
id BIGINT,
date datetime2(0),
desc varchar(50)
) ON TestPartitionScheme(date)界面向导表分区
创建文件组
右键数据库,选择“属性”
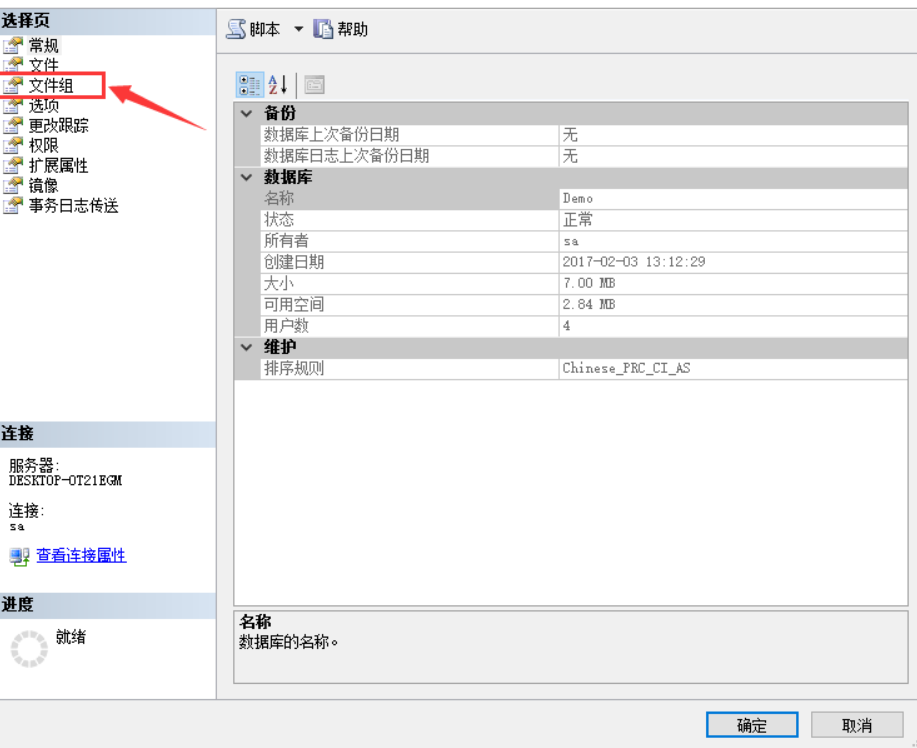

在属性界面中,点击箭头所示的“文件组”选项,进入文件组编辑界面
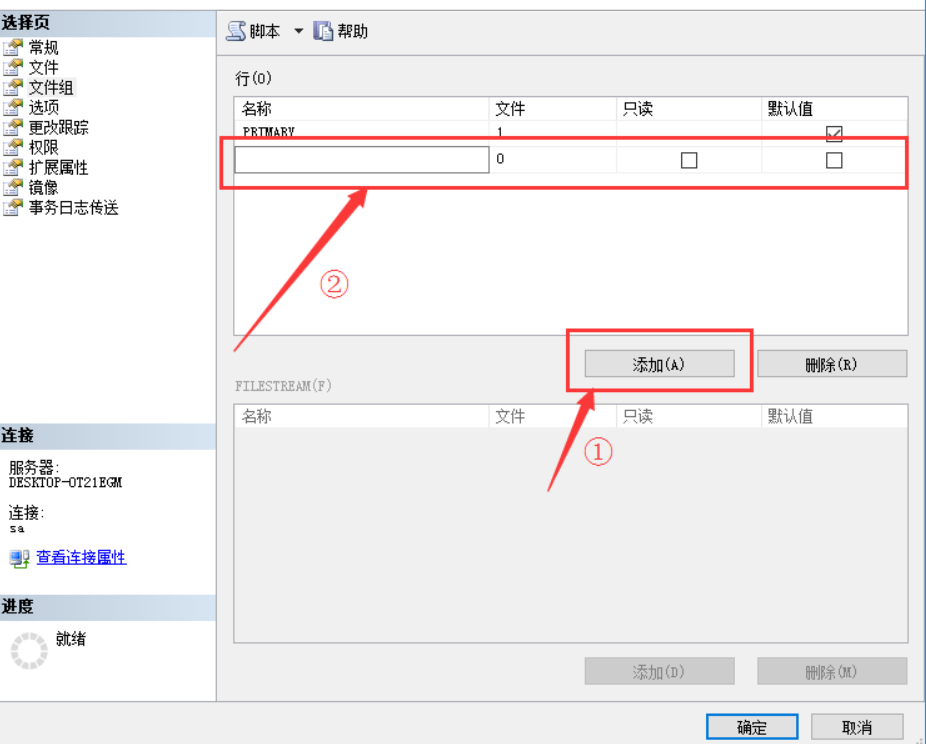
在文件组管理界面中点击箭头①所示的“添加”选项,添加新的文件组,界面中会出现箭头②所示的属性框,并键入对应的属性值,之后点击“确定”,完成新建文件组。
添加文件
和添加文件组的方式一样,右键数据库,选择“属性”,打开数据库属性界面,这次选择“文件”,打开文件管理界面
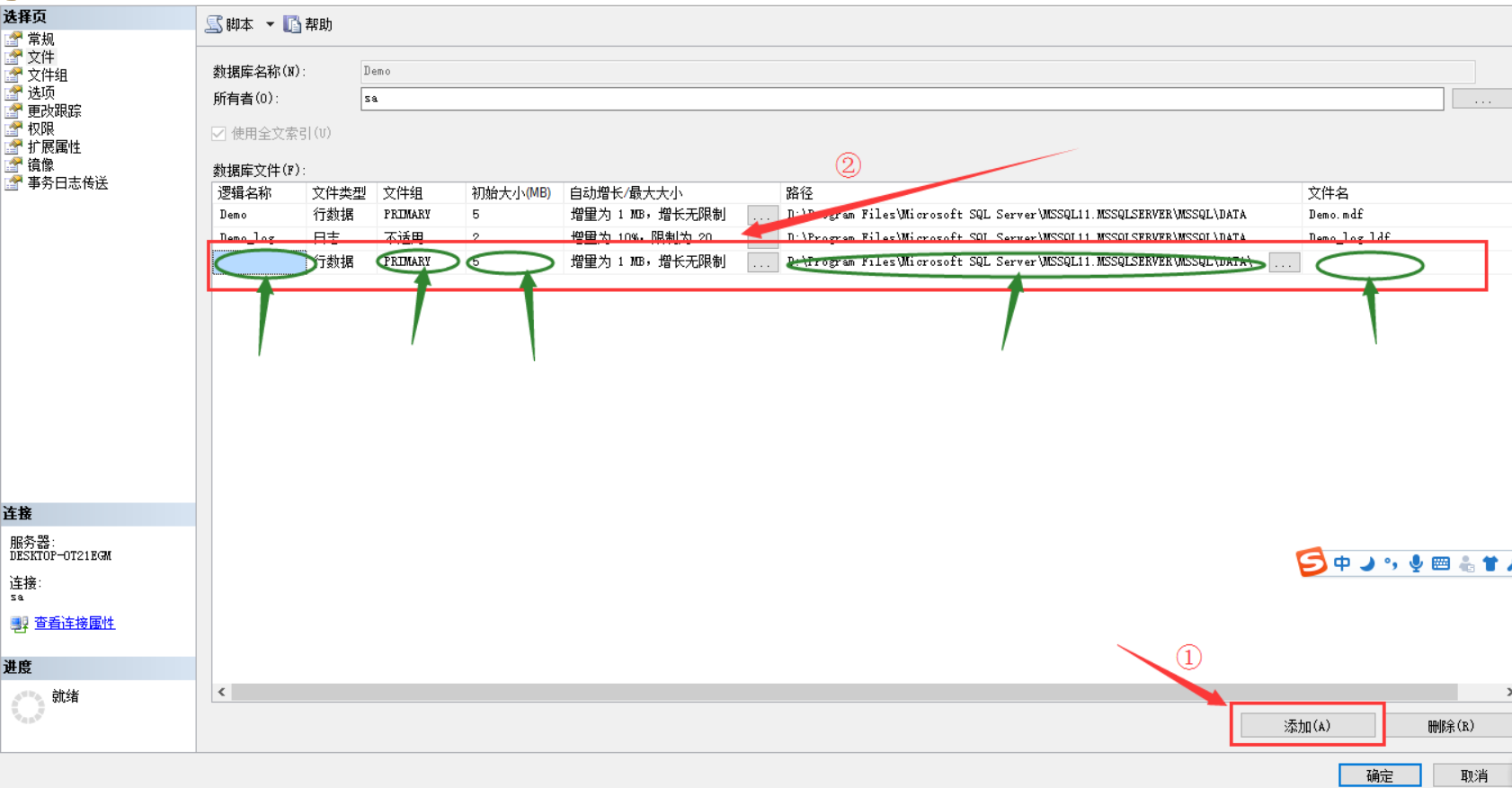
在文件管理界面中,点击箭头①所示的“添加”选项,添加新的文件,在新添加的箭头②所示的区域,根据实际需求,填写对应的文件属性值,填写完成后点击“确定”。其中,一个文件组中可以添加多个文件,即“文件组”属性的值是可以重复的。
定义分区表
在SQL Server 2012 Management Studio的界面中,找到目标数据库下的“表”菜单,右键点击,选择“新建数据库表”,打开新建数据库表界面,新建一个分区表。
添加分区函数和分区架构
完成新建分区表后,我们就可以在分区表上添加分区函数和分区架构了。右键点击分区表,选择“存储”,然后选择“创建分区”,开始添加分区函数和分区架构
点击“下一步”
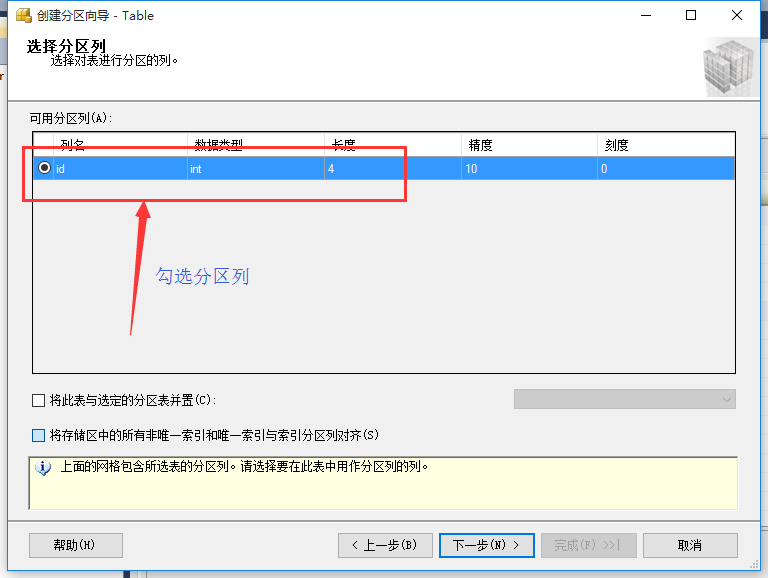
选择分区列
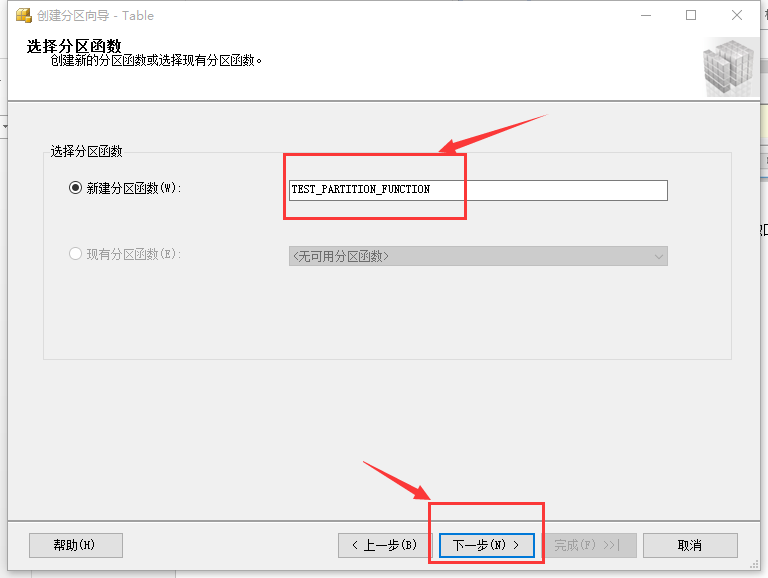
填写分区函数
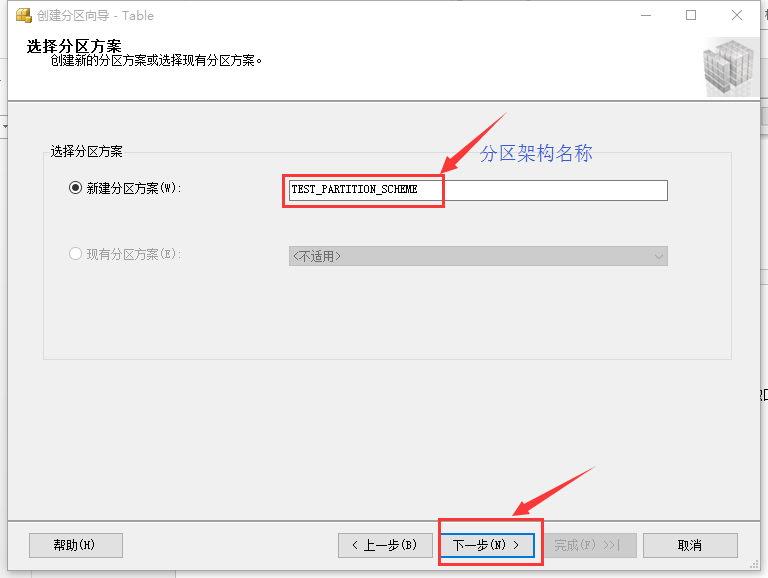
填写分区架构
指定文件组
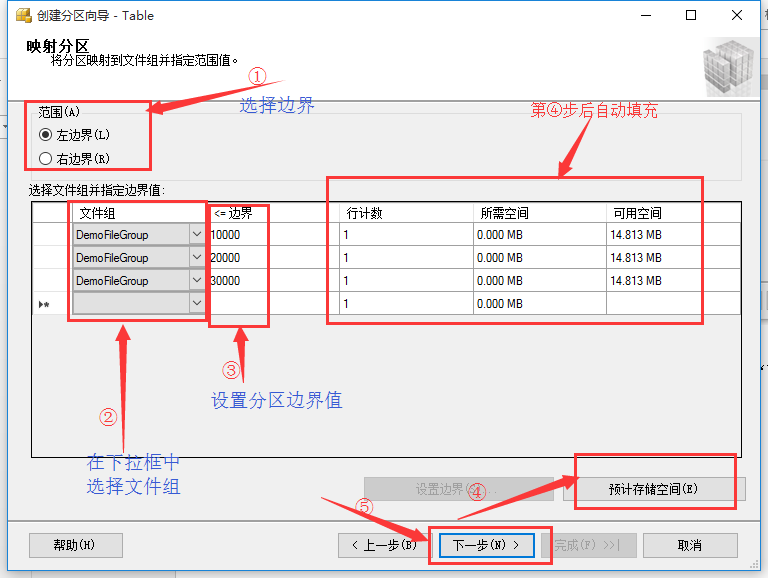
按照图示箭头步骤,一步步设置文件组参数。首先选择分区边界值划分在左边界分区还是右边界分区,然后进行第二步,设置分区所属文件组,再设置分区边界值(该值要与分区表的分区字段类型对应),最后点击“预计存储空间(E)”对其他参数进行自动填充。设置完成后点击“下一步”
脚本设置
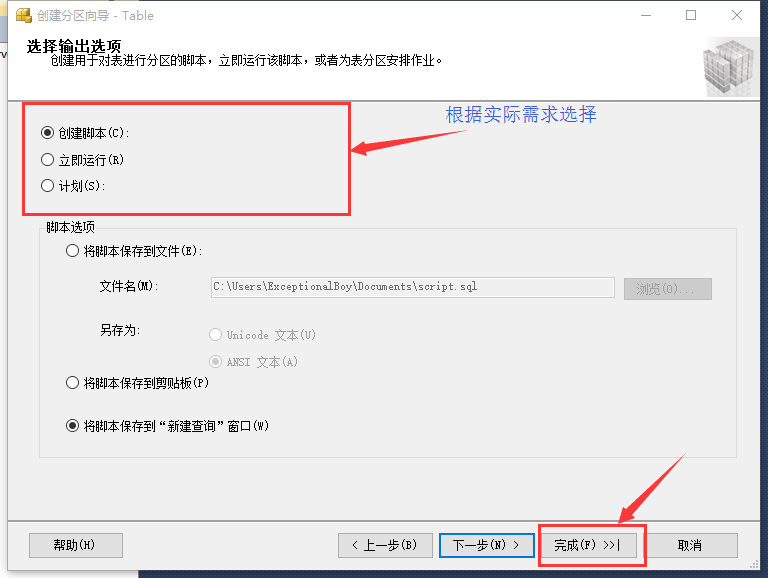
根据实际需求完成最后的设置(一般不做设置),然后点击“完成”,在下一个界面中再次点击“完成”,然后等待数据库执行操作,最后关闭界面。
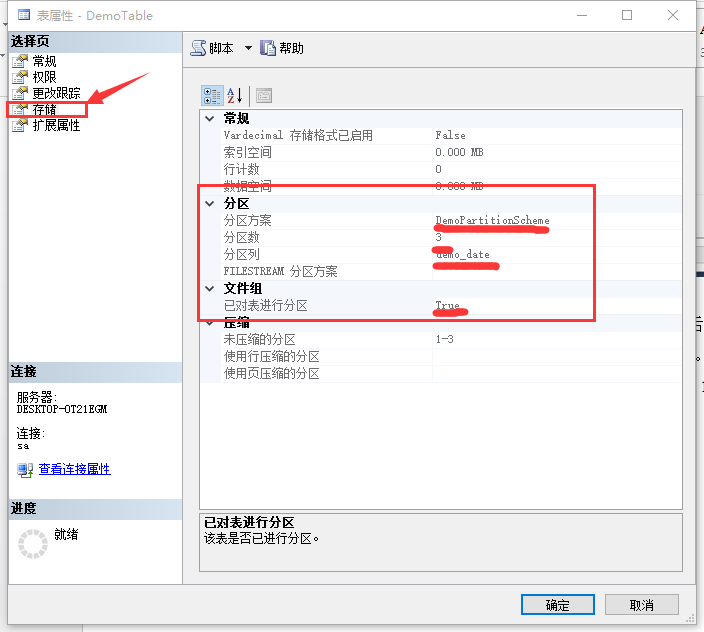
分区完成后,右键点击分区表,选择“属性”,然后选择“存储”
表分区查看
在已分区的表上创建索引(分区索引)时,应该注意以下事项:
l 唯一索引
建立唯一索引(聚集或者非聚集)时,分区列必须出现在索引列中。此限制将使SQL Server只调查单个分区,并确保表中宠物的新键值。如果分区依据列不可能包含在唯一键中,则必须使用DML触发器,而不是强制实现唯一性。
l 非唯一索引
对非唯一的聚集索引进行分区时,如果未在聚集键中明确指定分区依据列,默认情况下SQL Server 将在聚集索引列中添加分区依据列。
对非唯一的非聚集索引进行分区时,默认情况下SQL Server 将分区依据列添加为索引的包含性列,以确保索引与基表对齐,若果索引中已经存在分区依据列,SQL Server 将不会像索引中添加分区依据列。
表分区的优点:
1、改善查询性能:对分区对象的查询可以仅搜索自己关心的分区,提高检索速度。
2、增强可用性:如果表的某个分区出现故障,表在其他分区的数据仍然可用;
3、维护方便:如果表的某个分区出现故障,需要修复数据,只修复该分区即可;
4、均衡I/O:可以把不同的分区映射到磁盘以平衡I/O,改善整个系统性能。
表分区的缺点:
已经存在的表没有方法可以直接转化为分区表
什么时候使用分区表:
1、表的大小超过2GB。
2、表中包含历史数据,新的数据被增加都新的分区中。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/135079.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
