大家好,又见面了,我是你们的朋友全栈君。
原标题:PISA2018阅读素养计算机化自适应测试的技术与方法探析


摘要:PISA2018阅读素养的计算机化自适应测试采用核心阶段、阶段1和阶段2的3阶段自适应测试,题库设定有245道题目,组成45个测试单元,并将其组合成若干题组,用于不同阶段的测试。在路径设计上,为避免位置效应问题,除核心阶段→阶段1→阶段2的标准路径之外,还采用核心阶段→阶段2→阶段1的替代路径。PISA2018阅读素养计算机化自适应测试建立了能力覆盖范围较为完整的题库,减少了学生群体差异带来的测量误差,进一步提高了测量效度和效率,但在更大范围推广、人工评分题目的信息无法用于测试选题等方面,计算机化自适应测试仍需要进一步探索。
关键词:PISA2018;计算机化自适应测试;多阶段自适应测试;项目反应理论
随着测量理论和技术的不断发展,出现了覆盖面更广、效度和灵活度更高的测试——计算机化自适应测试(computerized adaptive testing)。计算机化自适应测试以项目反应理论为基础,摒弃传统标准化测验中所有被试都使用相同题目的弊端,试图为每一位被试构建对其能力估计最优的测验,做到“因人施测”。作为具有重要影响力的国际大型测试项目,PISA在测试技术上不断探索,PISA2018的最大技术革新是采用计算机化自适应测试。 本文分析PISA2018阅读素养计算机化自适应测试的技术与方法,以期为我国计算机化考试提供启示和借鉴。
1
计算机化自适应测试在PISA中的应用
计算机化自适应测试是基于项目反应理论的一种测试方式,测试自行适应被试水平,灵活施测与被试能力水平相匹配的题目,实现测试的准确与高效 [1] 。计算机化自适应测试相比纸笔测试和一般计算机化测试具有较多优点,如:具有估计被试能力值不依赖于测试题目的特性;可以根据题目的信息量,选择与被试能力相匹配的题目;每个被试完成测试题目的数量可以大幅减少;测试可以达到预定的测试效度要求等 [2] 。鉴于计算机化自适应测试的优势,OECD已经持续多年进行PISA计算机化自适应测试的研究和探索。随着参加PISA测试的国家或地区在计算机化测试实施经验上的逐步积累,PISA2018在阅读领域正式引入计算机化自适应测试。
PISA2018阅读领域的计算机化自适应测试采用多阶段自适应测试(multistage adaptive test,MSAT)。多阶段自适应测试能够根据被试能力水平选择相应的题目,更加精确地估计被试的能力和潜在特质;通过计算机管理题库,测试题目因人而异,并使被试能以更少的题目完成测验,提高考试的效率 [3] 。
计算机化自适应测试题目通常要尽可能覆盖测试所涉及的知识点和能力,因此需要建设一个题目涵盖面广、题量较大的题库。计算机化自适应测试最核心的部分是题目的挑选,题目挑选过程中需要明确2个标准:一是题目选择的标准,二是题目终止的标准。
计算机化自适应测试的施测过程大体可以分为2个阶段:第一阶段为探索被试的能力水平,估计被试能力的初值;第二阶段对第一阶段被试的能力估计值进行不断修正。PISA2018阅读素养计算机化自适应测试采用3阶段设计:核心阶段、阶段1和阶段2 [4] 。核心阶段属于试验性探查阶段,阶段1和阶段2属于精确估计阶段。在试验性探查阶段,被试的能力水平信息是未知的,需要先选择一些难度中等的题目来大致估计被试的能力水平范围。具体过程为:先由计算机从题库中随机选取难度适中的题目进行测试,如果被试回答正确,则下一题的难度适度增加;如果被试回答错误,则下一题的难度适当减小,也就是能够保证呈现给被试的题目对于估计其能力信息量是最大的。在阶段1和阶段2,计算机根据前一阶段初步估计的能力值,从现有题库中挑选对被试的能力估计能提供最大贡献的题目进行测试,随着测试题目的增加,信息量累积,以达到精确考查被试能力的目的。
计算机化自适应测试需要即时对被试的作答作出反应,根据被试的作答状况选择被试需要完成的下一道题目;因此,计算机化自适应测试一般都设有自动评分系统。系统自动评分的结果作为即时信息,为下一道题目的选择提供依据。
2
计算机化自适应测试题库与测试设计
PISA2018测试延续以往以测试单元作为基本单位的测试形式,每位被试作答相同数量的测试单元。每个测试单元包含一篇阅读材料及若干道题目,若干测试单元组成一个题组。测试中通过不同阶段完成不同的题组来实现计算机化自适应测试。
在PISA2018题目设计过程中,共命制34个阅读测试单元、318道题目。根据对所有参加PISA2018测试的国家或地区基本情况的调查、专家组的反馈和预先设定的测试框架,由阅读专家组挑选出31个单元的254道题目进入预试。测试开发团队通过预试收集题目的信息,对题目进行筛选:第一步,评估各题目的功能,每题设计二级评分,删除难度小于0.05的题目,以及单个题目与一组题目总分之间相关性接近于0的题目;第二步,删除质量不好的题目,包括难度小于0.2或者难度大于0.9的题目、题目与能力的相关性小于0.2的题目、IRT的斜率小于0.4的题目、10%的参测国家或地区的题目功能差异参数(DIF)不稳定的题目,以及10%的参测国家或地区评分者信度低的题目,共删掉19道题目;第三步,精简测试单元内的题目,本着充分利用单元文本,尽量使用体现阅读素养新要求的题目原则,将之前每个单元最多包含7道题目,改为每个单元包括的题目数不超过5道,据此删除50道题目。
在每个测试阶段的题目选择上,遵循不同的原则。核心阶段的每个题组大约包含10道题目,系统自动评分题目达到80%以上,以便为下一阶段题目的选择提供足够的信息。每个题组需同时包括2018年之前PISA阅读素养测试的题目及2018年新设计的题目2类,2类题目的比率各占一半。在阶段1,每个题组由3个单元组成,共15道题目,自动评分题目的比率在60%左右,且每个题组中至少有1个单元的题目来自2018年之前的阅读测试,以及至少1个单元的题目来自本轮新开发的题目。阶段2仅有2个题组,每个题组2个单元,共14道题目,该阶段各单元题目数量是3个阶段中最多的,阅读材料的文本长度也是最长的。
预试结果显示,按照上述标准筛选出的题目参数误差较小,且题目表现出的被试能力水平信息与随机选择的题目信息相比提高11%。根据设计框架和专家组的建议,PISA2018正式测试的阅读题库设定为245道题目,其中包括72道2018年之前测试使用过的旧题目和173道新开发的题目,共45个单元 [4] 。核心阶段包括5个单元,每个单元由3~5道题目组成。阶段1包括24个单元,每个单元由3~6道不同难度的题目组成。阶段2包括16个单元,每个单元由5~8道不同难度的题目组成。每个被试的试卷都包括7个单元的测试题目,其中核心阶段2个单元,阶段1有3个单元,阶段2有2个单元。
在题组的组织上,每个测试单元可以重复出现在不同的题组中。核心阶段有8个题组,由5个测试单元组合而成,见表1,其中“X”代表测试题组由该测试单元构成,例如Core1题组包括C1.1和C1.2两个单元。利用题组之间拥有共同单元的设计,可以实现不同题组之间的链接,确保测试题目的覆盖面更广 [5] 。
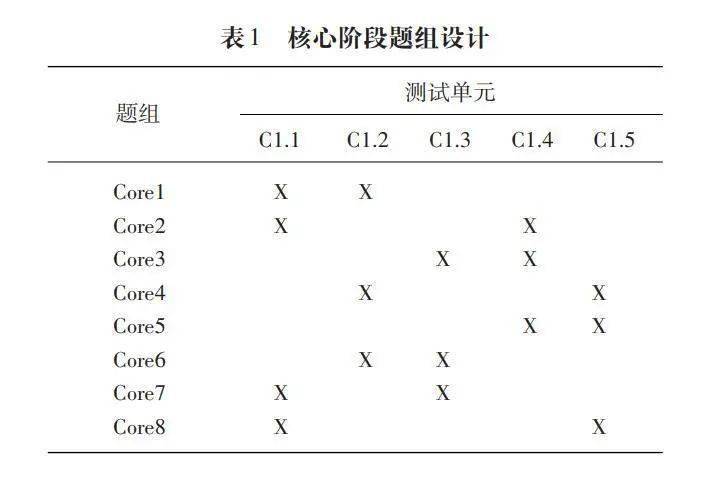
被试完成核心阶段的测试后,计算机将自动链接到阶段1,再根据阶段1的测试结果链接到阶段2。阶段1和阶段2分别包含8个标记为“high”的高难度题组和8个标记为“low”的低难度题组。由于在预试中出现被试因为疲劳或其他原因而导致的位置效应问题(即阶段2的题目无响应率比核心阶段和阶段1更高)。为了提高测试的精准度,PISA2018测试在原有标准路径(核心阶段→阶段1→阶段2)的基础上,增加了额外的替代路径(核心阶段→阶段2→阶段1),见图1和图2。
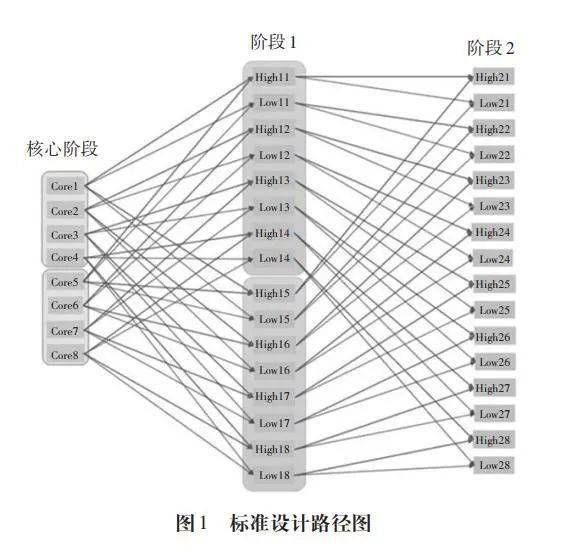
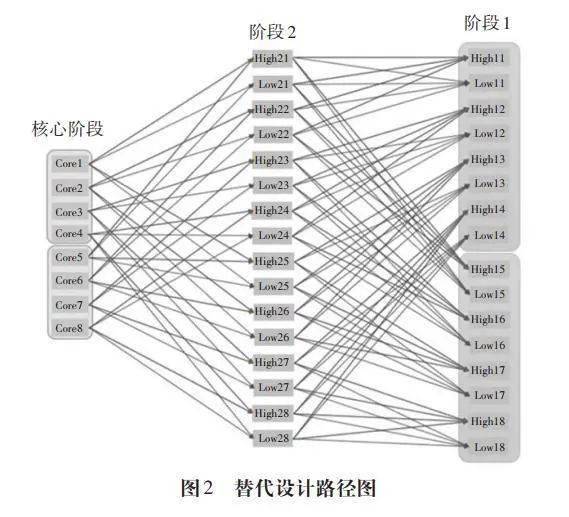
在预试期间,测验开发团队通过改变单元顺序,分析单元呈现顺序是否对题目参数和能力评估产生影响。结果表明,单元呈现顺序对题目参数和熟练度没有显著影响,因此替代路径是可行的。在PISA2018测试原有标准路径中,核心阶段包括8个题组,阶段1有16个题组,核心阶段的每个题组有4条路径可以链接到阶段1,“高难度”和“低难度”各2条,共计32条;阶段1和阶段2各有16个题组,阶段1的每个题组有2条路径可以链接到阶段2,“高难度”和“低难度”各1条,共计32条。标准设计路径共有64条。增加替代路径后,增加了“高难度”和“低难度”并行题组之间的链接,使得路径数增加1倍,从标准设计中的64条路径增加到替代设计的128条路径。具体来说,在标准设计中,阶段2的“高难度”选项仅从阶段1的“高难度题组”链接而来(例如,high21从high11和high15链接而来),见图1。在替代路径的设计中,阶段2的“高难度题组”不仅能链接到阶段1的“高难度题组”,还能链接到“低难度题组”(例如,high21链接到high11、high15、low11和low15),见图2。
3
计算机化自适应测试过程
在PISA2018阅读测试正式实施时,同时使用标准设计和替代设计2种路径,75%的被试作答标准设计路径题目,其余25%的被试作答替代设计路径题目。
测试过程中,被试在核心阶段的测试题组分配是基于1~8的随机数,阶段1测试题组的分配基于核心阶段分配的题组、被试在核心阶段的测试表现(即在给定的测试中系统自动评分题目的正确总数)及下一阶段分配的概率矩阵,阶段2的测试题组分配主要基于阶段1的分配题组、被试在核心阶段和阶段1中的表现及分配的概率矩阵。具体来说,计算机根据系统自动评分的结果,将被试分为3个组:“低”表现组——题目作答正确的总数小于每个测试规定的下限,“中等”表现组——题目作答正确的总数在每个测试规定的上下阈值之间,“高”表现组——题目作答正确的总数高于每个测试规定的上限。被试具体分组的依据:首先是分别以PISA标准分数的425分和530分设置分界线,低于425分为“低”表现组,425~530分为“中等”表现组,高于530分为“高”表现组;然后以425分和530分作为下限和上限,根据每个题组包含的自动评分题目的数量和题目特征曲线计算题组的下限和上限;最后根据被试在该题组上正确作答的情况进行分组。
以标准设计路径为例,在核心阶段被试被随机分配到题组RC1,该题组有9道自动评分的题目。如果被试回答正确的题目数量低于4道,那么就被分配到“低”表现组;如果回答正确的题目数量在4~6道,被试被分配到“中等”表现组;如果回答正确的题目数量在6道以上,被试被分配到“高”表现组。“低”表现组的被试将有90%的概率在阶段1被分配到难度较低的测试题组R11L(或R15L)和10%的概率被分配到难度较高的测试题组R11H(或R15H);对“高”表现组的被试来说,题目分配则相反;被分配到“中等”表现组的被试有相同的概率被分配到阶段1的2个高难度测试题组R11H(或R15H)或2个低难度的测试题组R11L(或R15L)。
在阶段1到阶段2的路径中,需要综合考虑被试前2个阶段的整体表现,也就是在核心阶段和阶段1正确作答题目数量的总和。例如,一个被试被分配作答RC1题组,并在阶段1被分配到R11H题组,如果回答正确的题目数量小于8道,则被分入“低”表现组;如果回答正确的题目数量在8~13道,则分入“中等”表现组;“高”表现组须正确作答13道以上的题目。同样,被试在阶段1为“低”表现组,将有90%的概率在阶段2被分配到低难度题组R21L和10%的概率被分配到高难度题组R21H。在阶段1为“高”表现组的被试则相反,“中等”表现组的被试则有相同的概率被分配到2个高难度或2个低难度的题组。
计算机化自适应测试的终止规则有2种:一种是固定测验长度,即当测试题目累积到预设值时就停止测验;另一种是不定长测验,即当被试能力水平估计的信息量达到要求时就停止测验。由于每个题目所包含的信息量不同,每一个被试达到相同信息量所需要的测试题目数量也不相同,测验的长度随被试的不同而变化。PISA2018阅读素养测试采用固定测验长度的终止标准,有助于保证测试的公平性,并且更易被接受。每个被试都参加相同单元数量和相同时长的测试,但每个被试作答的题目数量不同,从33道到40道题目不等,大部分被试作答35~37道题目。
4
启示与反思
PISA2018阅读素养计算机化自适应测试表现出多个方面的优点。首先,建立了能力覆盖范围较为完整的题库,丰富的题目能够更好地满足阅读素养新的测量要求。其次,作为在国际范围内使用的评估项目,PISA涉及的测试人群内部差异较大,计算机化自适应测试能够减少人群差异带来的测量误差。PISA2018阅读素养测试数据显示,与传统的非适应性PISA测试相比,计算机化自适应测试将测量标准误差减少10%。最后,计算机化自适应测试能够根据被试的作答反应灵活选择测试题目,以较少的测验题目达到对被试能力精确估计的目的。在保证测试效度的同时,还减轻被试的负担。测量效度和效率的进一步提高,能够使PISA对更多不同能力水平的被试进行更加精准的测量,为PISA项目在国际上的进一步推广提供有力的支持。
但是,PISA2018阅读素养计算机化自适应测试仍然存在一些限制和不足。首先,计算机化自适应测试依赖于计算机技术的发展,有些地区由于网络和计算机的缺乏,该测试无法在这些地区实施。其次,计算机化自适应测试的效度依赖于与被试能力相匹配的题目,需要建立大容量的题库,且题库需要及时更新,因此需要大量资源的支持,进行大量的预试和信息积累等,在现实中实现难度较大。最后,在结果分析方面,计算机化自适应测试对于一些开放性的主观题无法做到即时评估,仍然需要借助人工评分,这部分题目的结果无法为下一题目的选择提供有效信息,对于下一阶段的题目选择和被试的能力估计都会带来影响。计算机多阶段自适应测试在大型教育评估项目中的应用仍处于发展阶段,尽管PISA2018阅读素养测试促进了这一技术在更大范围内的使用与发展,但还需要进一步的探索。

作者:
赵茜,北京师范大学中国基础教育质量监测协同创新中心,副教授;
马力,北京师范大学中国基础教育质量监测协同创新中心;
温红博,北京师范大学中国基础教育质量监测协同创新中心,副教授。
原文刊载于《中国考试》2020年第11期第74—78页。返回搜狐,查看更多
责任编辑:
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/134966.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
