大家好,又见面了,我是你们的朋友全栈君。
如果你的数据库中某一个表中的数据满足以下几个条件,那么你就要考虑创建分区表了。
1、数据库中某个表中的数据很多。很多是什么概念?一万条?两万条?还是十万条、一百万条?这个,我觉得是仁者见仁、智者见智的问题。当然数据表中的数据多到查询时明显感觉到数据很慢了,那么,你就可以考虑使用分区表了。如果非要我说一个数值的话,我认为是100万条。
2、但是,数据多了并不是创建分区表的惟一条件,哪怕你有一千万条记录,但是这一千万条记录都是常用的记录,那么最好也不要使用分区表,说不定会得不偿失。只有你的数据是分段的数据,那么才要考虑到是否需要使用分区表。
3、什么叫数据是分段的?这个说法虽然很不专业,但很好理解。比如说,你的数据是以年为分隔的,对于今年的数据而言,你常进行的操作是添加、修改、删除和查询,而对于往年的数据而言,你几乎不需要操作,或者你的操作往往只限于查询,那么恭喜你,你可以使用分区表。换名话说,你对数据的操作往往只涉及到一部分数据而不是所有数据的话,那么你就可以考虑什么分区表了。
那么,什么是分区表呢?
简单一点说,分区表就是将一个大表分成若干个小表。假设,你有一个销售记录表,记录着每个每个商场的销售情况,那么你就可以把这个销售记录表按时间分成几个小表,例如说5个小表吧。2009年以前的记录使用一个表,2010年的记录使用一个表,2011年的记录使用一个表,2012年的记录使用一个表,2012年以后的记录使用一个表。那么,你想查询哪个年份的记录,就可以去相对应的表里查询,由于每个表中的记录数少了,查询起来时间自然也会减少。
但将一个大表分成几个小表的处理方式,会给程序员增加编程上的难度。以添加记录为例,以上5个表是独立的5个表,在不同时间添加记录的时候,程序员要使用不同的SQL语句,例如在2011年添加记录时,程序员要将记录添加到2011年那个表里;在2012年添加记录时,程序员要将记录添加到2012年的那个表里。这样,程序员的工作量会增加,出错的可能性也会增加。
使用分区表就可以很好的解决以上问题。分区表可以从物理上将一个大表分成几个小表,但是从逻辑上来看,还是一个大表。
接着上面的例子,分区表可以将一个销售记录表分成五个物理上的小表,但是对于程序员而言,他所面对的依然是一个大表,无论是2010年添加记录还是2012年添加记录,对于程序员而言是不需要考虑的,他只要将记录插入到销售记录表——这个逻辑中的大表里就行了。SQL Server会自动地将它放在它应该呆在的那个物理上的小表里。
同样,对于查询而言,程序员也只需要设置好查询条件,OK,SQL Server会自动将去相应的表里查询,不用管太多事了。
这一切是不是很诱人?
的确,那么我们就可以开始动手创建分区表了。
第一、创建分区表的第一步,先创建数据库文件组,但这一步可以省略,因为你可以直接使用PRIMARY文件。但我个人认为,为了方便管理,还是可以先创建几个文件组,这样可以将不同的小表放在不同的文件组里,既便于理解又可以提高运行速度。创建文件组的方法很简单,打开SQL Server Management Studio,找到分区表所在数据库,右键单击,在弹出的菜单里选择“属性”。然后选择“文件组”选项,再单击下面的“添加”按钮,如下图所示:

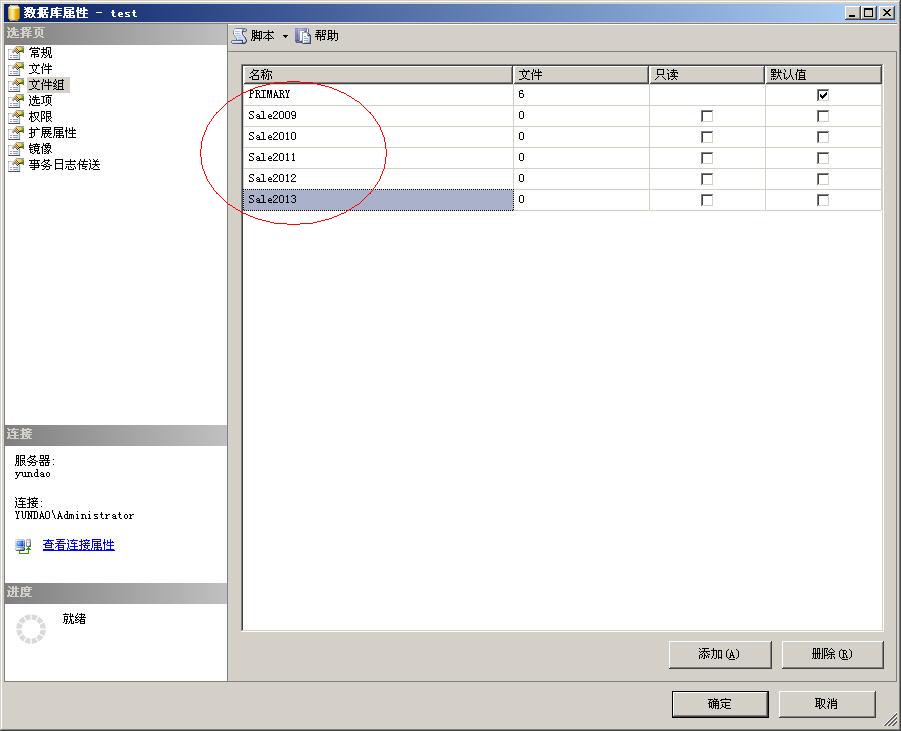
第二,创建了文件组之后,还要再创建几个数据库文件。为什么要创建数据库文件,这很好理解,因为分区的小表必须要放在硬盘上,而放在硬盘上的什么地方呢?当然是文件里啦。再说了,文件组中没有文件,文件组还要来有啥用呢?还是在上图的那个界面,选择“文件”选项,然后添加几个文件。在添加文件的时候要注意以下几点:
1、不要忘记将不同的文件放在文件组中。当然一个文件组中也可以包含多个不同的文件。
2、如果可以的话,将不同的文件放在不同的硬盘分区里,最好是放在不同的独立硬盘里。要知道IQ的速度往往是影响SQL Server运行速度的重要条件之一。将不同的文件放在不同的硬盘上,可以加快SQL Server的运行速度。
在本例中,为了方便起见,将所有数据库文件都放在了同一个硬盘下,并且每个文件组中只有一个文件。如下图所示。
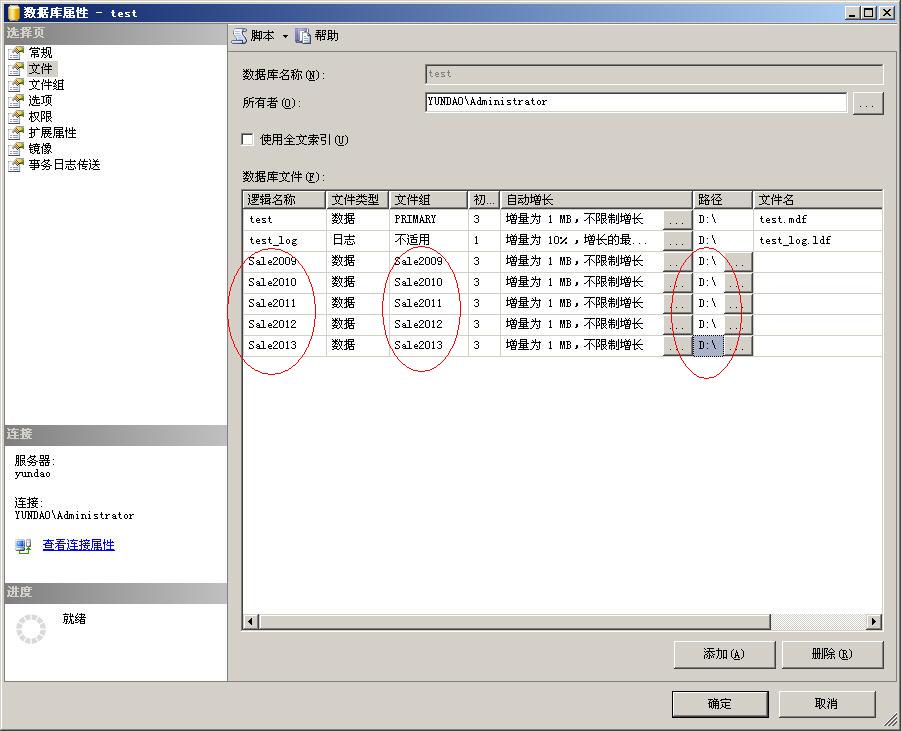
第三、创建一个分区函数。这一步是必须的了,创建分区函数的目的是告诉SQL Server以什么方式对分区表进行分区。这一步必须要什么SQL脚本来完成。以上面的例子,我们要将销售表按时间分成5个小表。假设划分的时间为:
第1个小表:2010-1-1以前的数据(不包含2010-1-1)。
第2个小表:2010-1-1(包含2010-1-1)到2010-12-31之间的数据。
第3个小表:2011-1-1(包含2011-1-1)到2011-12-31之间的数据。
第4个小表:2012-1-1(包含2012-1-1)到2012-12-31之间的数据。
第5个小表:2013-1-1(包含2013-1-1)之后的数据。
那么分区函数的代码如下所示:
CREATE PARTITION FUNCTION partfunSale (datetime) AS RANGE RIGHT FOR VALUES ('20100101','20110101','20120101','20130101') 其中:
1、CREATE PARTITION FUNCTION意思是创建一个分区函数。
2、partfunSale为分区函数名称。
3、AS RANGE RIGHT为设置分区范围的方式为Right,也就是右置方式。
4、FOR VALUES (‘20100101’,’20110101’,’20120101’,’20130101’)为按这几个值来分区。
这里需要说明的一下,在Values中,’20100101’、’20110101’、’20120101’、’20130101’,这些都是分区的条件。“ 20100101”代表2010年1月1日,在小于这个值的记录,都会分成一个小表中,如表1;而小于或等于’20100101’并且小于’20110101’的值,会放在另一个表中,如表2。以此类推,到最后,所有大小或等于’20130101’的值会放在另一个表中,如表5。
也许有人会问,为什么值“ 20100101”会放在表2中,而不是表1中呢?这是由AS RANGE RIGHT中的RIGHT所决定的,RIGHT的意思是将等于这个值的数据放在右边的那个表里,也就是表2中。如果您的SQL语句中使用的是Left而不是RIGHT,那么就会放在左边的表中,也就是表1中。
第四、创建一个分区方案。分区方案的作用是将分区函数生成的分区映射到文件组中去。分区函数的作用是告诉SQL Server,如何将数据进行分区,而分区方案的作用则是告诉SQL Server将已分区的数据放在哪个文件组中。分区方案的代码如下所示:
CREATE PARTITION SCHEME partschSale AS PARTITION partfunSale TO ( Sale2009, Sale2010, Sale2011, Sale2012, Sale2013) 其中:
1、CREATE PARTITION SCHEME意思是创建一个分区方案。
2、partschSale为分区方案名称。
3、AS PARTITION partfunSale说明该分区方案所使用的数据划分条件(也就是所使用的分区函数)为partfunSale。
4、TO后面的内容是指partfunSale分区函数划分出来的数据对应存放的文件组。
到此为止,分区函数和分区方案就创建完毕了。创建后的分区函数和分区方案在数据库的“存储”中可以看到,如下图所示:
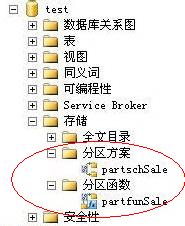
CREATE TABLE Sale( [Id] [int] IDENTITY(1,1) NOT NULL, [Name] [varchar](16) NOT NULL, [SaleTime][datetime] NOT NULL ) ON partschSale([SaleTime]) 其中:
1、CREATE TABLE 意思是创建一个数据表。
2、Sale为数据表名。
3、()中为表中的字段,这里的内容和创建普通数据表没有什么区别,惟一需要注意的是不能再创建聚集索引了。道理很简单,聚集索引可以将记录在物理上顺序存储的,而分区表是将数据分别存储在不同的表中,这两个概念是冲突的,所以,在创建分区表的时候就不能再创建聚集索引了。
4、ON partschSale()说明使用名为partschSale的分区方案。
5、partschSale()括号中为用于分区条件的字段是SaleTime。
OK,一个物理上是分离的,逻辑上是一体的分区表就创建完毕了。查看该表的属性,可以看到该表已经属于分区表了。
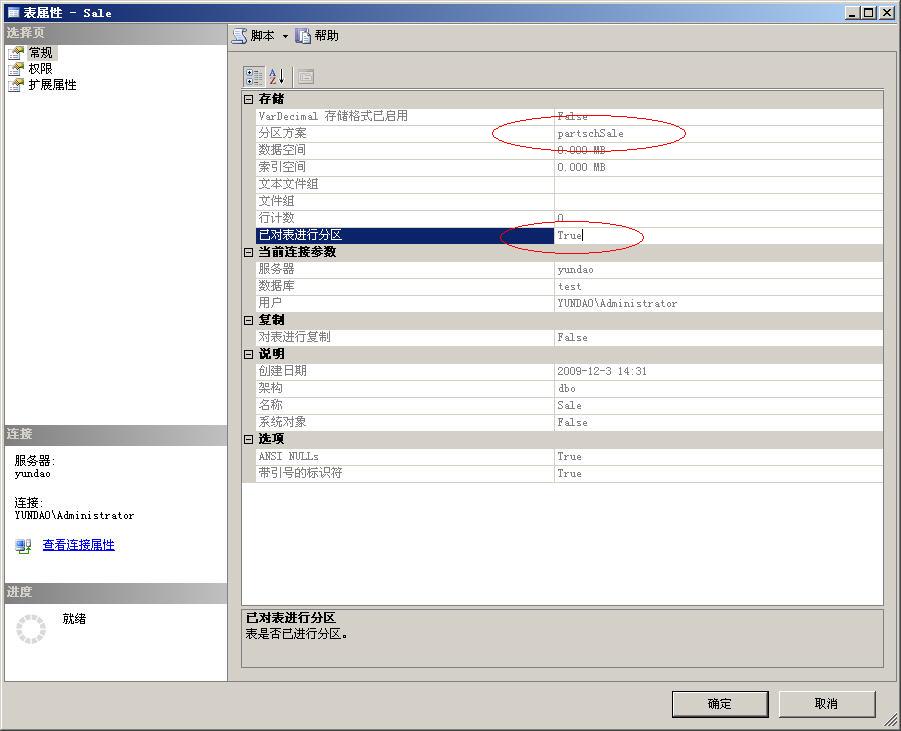
如何添加、查询、修改分区表中的数据
在创建完分区表后,可以向分区表中直接插入数据,而不用去管它这些数据放在哪个物理上的数据表中。接上篇文章,我们在创建好的分区表中插入几条数据:
insert Sale ([Name],[SaleTime]) values ('张三','2009-1-1') insert Sale ([Name],[SaleTime]) values ('李四','2009-2-1') insert Sale ([Name],[SaleTime]) values ('王五','2009-3-1') insert Sale ([Name],[SaleTime]) values ('钱六','2010-4-1') insert Sale ([Name],[SaleTime]) values ('赵七','2010-5-1') insert Sale ([Name],[SaleTime]) values ('张三','2011-6-1') insert Sale ([Name],[SaleTime]) values ('李四','2011-7-1') insert Sale ([Name],[SaleTime]) values ('王五','2011-8-1') insert Sale ([Name],[SaleTime]) values ('钱六','2012-9-1') insert Sale ([Name],[SaleTime]) values ('赵七','2012-10-1') insert Sale ([Name],[SaleTime]) values ('张三','2012-11-1') insert Sale ([Name],[SaleTime]) values ('李四','2013-12-1') insert Sale ([Name],[SaleTime]) values ('王五','2014-12-1')从以上代码中可以看出,我们一共在数据表中插入了13条数据,其中第1至3条数据是插入到第1个物理分区表中的;第4、5条数据是插入到第2个物理分区表中的;第6至8条数据是插入到第3个物理分区表中的;第9至11条数据是插入到第4个物理分区表中的;第12、13条数据是插入到第5个物理分区表中的。
从SQL语句中可以看出,在向分区表中插入数据方法和在普遍表中插入数据的方法是完全相同的,对于程序员而言,不需要去理会这13条记录研究放在哪个数据表中。当然,在查询数据时,也可以不用理会数据到底是存放在哪个物理上的数据表中。如使用以下SQL语句进行查询:
select * from Sale查询的结果如下图所示:
PARTITION函数,这个函数的可以调用分区函数,并返回数据所在物理分区的编号。说起来有点难懂,不过用起来很简单。
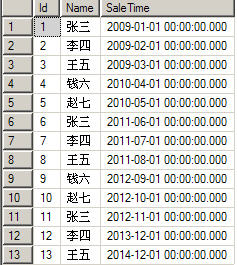
PARTITION的语法是: $PARTITION.分区函数名(表达式) 假设,你想知道2010年10月1日的数据会放在哪个物理分区表中,你就可以使用以下语句来查看。
select $PARTITION.partfunSale ('2010-10-1')在以上语句中,partfunSale()为分区函数名,括号中的表达式必须是日期型的数据或可以隐式转换成日期型的数据,如果要问我为什么,那么就回想一个怎么定义分区函数的吧(CREATE PARTITION FUNCTION partfunSale (datetime))。在定义partfunSale()函数时,指定了参数为日期型,所以括号中的表达式必须是日期型或可以隐式转换成日期型的数据。以上代码的运行结果如下图所示:
在该图中可以看出,分区函数返回的结果为2,也就是说,2010年10月1日的数据会放在第2个物理分区表中。
再进一步考虑,如果想具体知道每个物理分区表中存放了哪些记录,也可以使用 PARTITION函数。因为 PARTITION函数可以得到物理分区表的编号,那么只要将$PARTITION.partfunSale(SaleTime)做为where的条件使用即可,如以下代码 所示:
select * from Sale where $PARTITION.partfunSale(SaleTime)=1
select * from Sale where $PARTITION.partfunSale(SaleTime)=2
select * from Sale where $PARTITION.partfunSale(SaleTime)=3
select * from Sale where $PARTITION.partfunSale(SaleTime)=4
select * from Sale where $PARTITION.partfunSale(SaleTime)=5 以上代码的运行结果如下图所示:
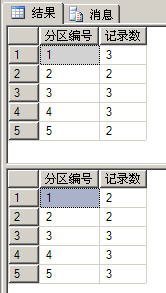
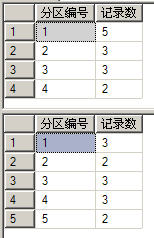
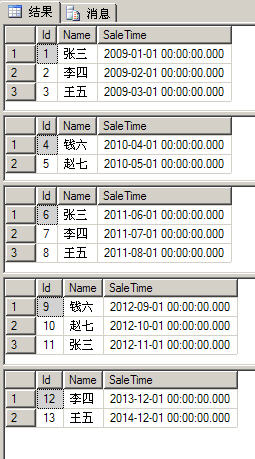 从上图中我们可以看到每个分区表中的数据记录情况——和我们插入时设置的情况完全一致。同理可得,如果要统计每个物理分区表中的记录数,可以使用如下代码:
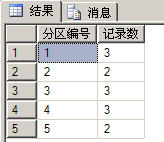
select $PARTITION.partfunSale(SaleTime) as 分区编号,count(id) as 记录数 from Sale group by $PARTITION.partfunSale(SaleTime) 以上代码的运行结果如下图所示:
 除了在插入数据时程序员不需要去考虑分区表的物理情况之外,就是连修改数据也不需要考虑。SQL Server会自动将记录从一个分区表移到另一个分区表中,如以下代码所示:
--统计所有分区表中的记录总数
select $PARTITION.partfunSale(SaleTime) as 分区编号,count(id) as 记录数 from Sale group by $PARTITION.partfunSale(SaleTime) --修改编号为1的记录,将时间改为2019年1月1日 update Sale set SaleTime='2019-1-1' where id=1 --重新统计所有分区表中的记录总数 select $PARTITION.partfunSale(SaleTime) as 分区编号,count(id) as 记录数 from Sale group by $PARTITION.partfunSale(SaleTime) 在以上代码中,程序员将其中一条数据的时间改变了,从分区函数中可以得知,这条记录应该从第一个分区表移到第五个分区表中,如下图所示。而整个操作过程,程序员是完全不需要干预的。
将普通表转换成分区表
在设计数据库时,经常没有考虑到表分区的问题,往往在数据表承重的负担越来越重时,才会考虑到分区方式,这时,就涉及到如何将普通表转换成分区表的问题了。
那么,如何将一个普通表转换成一个分区表 呢?说到底,只要将该表创建一个聚集索引,并在聚集索引上使用分区方案即可。
不过,这回说起来简单,做起来就复杂了一点。还是接着上面的例子,我们先使用以下SQL语句将原有的Sale表删除。
--删除原来的数据表
drop table Sale 然后使用以下SQL语句创建一个新的普通表,并在这个表里插入一些数据。
--新建一个普通的数据表
CREATE TABLE Sale( [Id] [int] IDENTITY(1,1) NOT NULL, --自动增长 [Name] [varchar](16) NOT NULL, [SaleTime] [datetime] NOT NULL, CONSTRAINT [PK_Sale] PRIMARY KEY CLUSTERED --创建主键 ( [Id] ASC ) ) --插入一些记录 insert Sale ([Name],[SaleTime]) values ('张三','2009-1-1') insert Sale ([Name],[SaleTime]) values ('李四','2009-2-1') insert Sale ([Name],[SaleTime]) values ('王五','2009-3-1') insert Sale ([Name],[SaleTime]) values ('钱六','2010-4-1') insert Sale ([Name],[SaleTime]) values ('赵七','2010-5-1') insert Sale ([Name],[SaleTime]) values ('张三','2011-6-1') insert Sale ([Name],[SaleTime]) values ('李四','2011-7-1') insert Sale ([Name],[SaleTime]) values ('王五','2011-8-1') insert Sale ([Name],[SaleTime]) values ('钱六','2012-9-1') insert Sale ([Name],[SaleTime]) values ('赵七','2012-10-1') insert Sale ([Name],[SaleTime]) values ('张三','2012-11-1') insert Sale ([Name],[SaleTime]) values ('李四','2013-12-1') insert Sale ([Name],[SaleTime]) values ('王五','2014-12-1') 使用以上代码创建的表是普通表,我们来看一下表的属性,如下图所示。
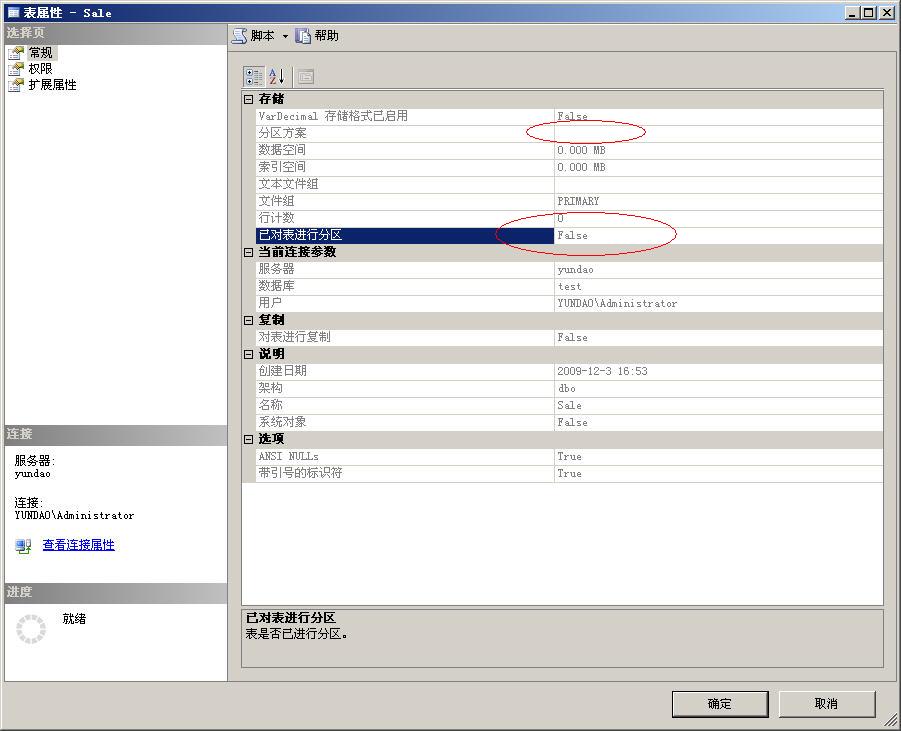
在以上代码中,我们可以看出,这个表拥有一般普通表的特性——有主键,同时这个主键还是聚集索引。前面说过,分区表是以某个字段为分区条件,所以,除了这个字段以外的其他字段,是不能创建聚集索引的。因此,要想将普通表转换成分区表,就必须要先删除聚集索引,然后再创建一个新的聚集索引,在该聚集索引中使用分区方案。
可惜的是,在SQL Server中,如果一个字段既是主键又是聚集索引时,并不能仅仅删除聚集索引。因此,我们只能将整个主键删除,然后重新创建一个主键,只是在创建主键时,不将其设为聚集索引,如以下代码所示:
--删掉主键
ALTER TABLE Sale DROP constraint PK_Sale --创建主键,但不设为聚集索引 ALTER TABLE Sale ADD CONSTRAINT PK_Sale PRIMARY KEY NONCLUSTERED ( [ID] ASC ) ON [PRIMARY] 在重新非聚集主键之后,就可以为表创建一个新的聚集索引,并且在这个聚集索引中使用分区方案,如以下代码所示:
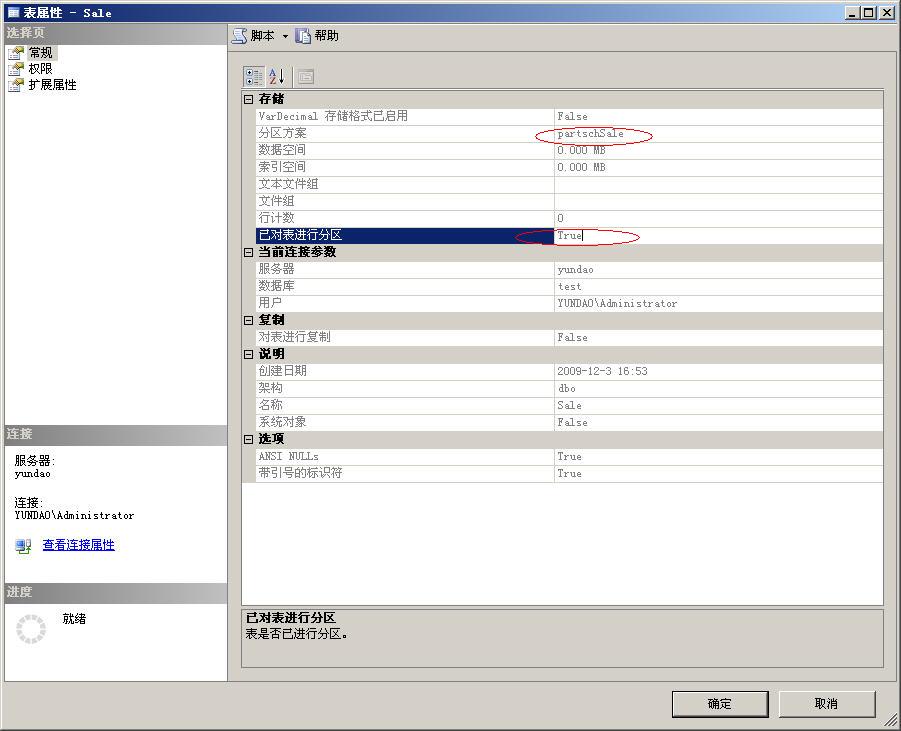
--创建一个新的聚集索引,在该聚集索引中使用分区方案
CREATE CLUSTERED INDEX CT_Sale ON Sale([SaleTime]) ON partschSale([SaleTime]) 为表创建了一个使用分区方案的聚集索引之后,该表就变成了一个分区表,查看其属性,如下图所示。
我们可以再一次使用以下代码来看看每个分区表中的记录数。
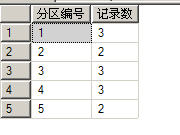
--统计所有分区表中的记录总数
select $PARTITION.partfunSale(SaleTime) as 分区编号,count(id) as 记录数 from Sale group by $PARTITION.partfunSale(SaleTime) 以上代码的运行结果如下所示,说明在将普通表转换成分区表之后,数据不但没有丢失,而且还自动地放在了它应在的分区表中了。
删除(合并)一个分区
在前面我们介绍过如何创建和使用一个分区表,并举了一个例子,将不 同年份的数据放在不同的物理分区表里。具体的分区方式为:
第1个小表:2010-1-1以前的数据(不包含2010-1-1)。
第2个小表:2010-1-1(包含2010-1-1)到2010-12-31之间的数据。
第3个小表:2011-1-1(包含2011-1-1)到2011-12-31之间的数据。
第4个小表:2012-1-1(包含2012-1-1)到2012-12-31之间的数据。
第5个小表:2013-1-1(包含2013-1-1)之后的数据。
分区函数的代码如下所示:
CREATE PARTITION FUNCTION partfunSale (datetime) AS RANGE RIGHT FOR VALUES ('20100101','20110101','20120101','20130101') 假设我们在创建分区表之后发现,2010年以前的数据并不多,完全可以将它们与2010年的数据进行合并,放在同一个分区里,也就是说,具体的分区方式改为:
第1个小表:2011-1-1以前的数据(不包含2011-1-1)。
第2个小表:2011-1-1(包含2011-1-1)到2011-12-31之间的数据。
第3个小表:2012-1-1(包含2012-1-1)到2012-12-31之间的数据。
第4个小表:2013-1-1(包含2013-1-1)之后的数据。
由于上面的需求更改了数据分区的条件,因此,我们必须要修改分区函数,因为分区函数的作用就是要来告诉SQL Server怎么存放数据的。只要分区函数修改了,SQL Server会自动将数据重新分配,按照新的分区函数指定的方式来存储数据。
先假设我们还没有创建过分区表,要满足上面的条件,我们必须要写出如下代码的创建分区函数的SQL语句
CREATE PARTITION FUNCTION partfunSale (datetime) AS RANGE RIGHT FOR VALUES ('20110101','20120101','20130101') 比较一个新的分区函数和老的分区函数,看看他们有什么区别?
的确,我们很容易就可以发现,老的分区函数里多了一个分界值——也就是’20100101’。那么,修改老的分区函数,事实上就是将这分界值删除。简单一点说,删除(合并)一个分区,事实上就是在分区函数中将多余的分界值删除。
删除分区函数中的分界值,也就是修改分区函数的方法如下所示:
ALTER PARTITION FUNCTION partfunSale() MERGE RANGE ('20100101') 其中:
1、ALTER PARTITION FUNCTION 意思是修改分区函数
2、partfunSale()为分区函数名
3、MERGE RANGE意思是合并界限。事实上,合并界限和删除分界值是一个意思。
我们可以在修改分区函数时先统计一下各物理分区中的记录总数,在修改分区之后,再统计一下各物理分区中的记录总数,看一下修改分区函数后的数据变化情况,代码如下所示:
--统计所有分区表中的记录总数
select $PARTITION.partfunSale(SaleTime) as 分区编号,count(id) as 记录数 from Sale group by $PARTITION.partfunSale(SaleTime) --原来的分区函数是将2010-1-1之前的数据放在第1个分区表中,将2010-1-1至2011-1-1之间的数据放在第2个分区表中 --现在需要将2011-1-1之前的数据都放在第1个分区表中,也就是将第1个分区表和第2个分区表中的数据合并 --修改分区函数 ALTER PARTITION FUNCTION partfunSale() MERGE RANGE ('20100101') --统计所有分区表中的记录总数 select $PARTITION.partfunSale(SaleTime) as 分区编号,count(id) as 记录数 from Sale group by $PARTITION.partfunSale(SaleTime) 运行结果如下图所示:

现在还有一个问题,就是通过修改分区函数合并数据之后,数据都存放在哪里了?在修改之前,数据分别存放在文件组Sale2009和Sale2010中,修改之后,数据放到哪里去了呢?
事实上,在修改分区函数之后,SQL Server也会自动修改分区方案,将处于两个物理分区中的数据放在同一个物理分区里了。可以通过查看分区方案的方式来查看数据具体的存放位置。
查看分区方案的方式为:在SQL Server Management Studio中,选择数据库–>存储–>分区方案,右击分区方案名,在弹出的菜单中选择“编写分区方案脚本为”–>CREATE到–>新查询编辑器窗口
然后在新查询编辑器窗口可以看到下图代码。

从上图中可以看出,分区方案将原来Sale2010文件组中的数据合并到了Sale2009文件组中。
添加一个分区
所谓天下大事,分久必合,合久必分,对于分区表而言也一样。前面我们介绍过如何删除(合并)分区表中的一个分区,下面我们介绍一下如何为分区表添加一个分区。
为分区表添加一个分区,这种情况是时常会 发生的。比如,最初在数据库设计时,只预计了存放3年的数据,可是到了第4天怎么办?这样的话,我们就可以为分区表添加一个分区,让它把新的数据放在新的分区里。再比如,最初设计时,一个分区用于存放一年的数据,结果在使用的时候才发现,一年的数据太多,想将一个分区中的数据分为两个分区来存放。
遇到这种情况,就必须要为分区表添加一个分区了。
当然,我们也可以使用修改分区函数的方式来添加一个分区,但是在修改分区函数时,我们必须要注意另一个问题——分区方案。为什么还要注意分区方案呢?我们回过头来看一下前面是怎么定义分区函数和分区方案的,如以下代码所示:
--添加分区函数
CREATE PARTITION FUNCTION partfunSale (datetime) AS RANGE RIGHT FOR VALUES ('20100101','20110101','20120101','20130101') --添加分区方案 CREATE PARTITION SCHEME partschSale AS PARTITION partfunSale TO ( Sale2009, Sale2010, Sale2011, Sale2012, Sale2013) 从以上代码中可以看出,分区函数定义了用于分区的数据边界,而分区函数指定了符合分区边界的数据存放在文件组。因此,分区方案中指定的文件组个数应该是比分区函数中指定的边界数大1的。如上例中,分区函数中指定的边界数为4,那么在分区方案中指定的文件组数就为5。
如果,我们将分区函数中的边界数增加一个,那么分区方案中的文件组数也就要相应地增加一个。因此,我们不能简简单单地通过修改分区函数的方式来为分区表添加一个分区。
那么,我们应该怎么做呢?是不是要先为分区方案添加一个文件组?
这种想法是没有错的,想要为分区表添加一个分区,可以通过以下两个步骤来实现:
1、为分区方案指定一个可以使用的文件组。
2、修改分区函数。
在为分区方案指定一个可用的文件组时,该分区方案并没有立刻使用这个文件组,只是将文件组先备用着,等修改了分区函数之后分区方案才会使用这个文件组(不要忘记了,如果分区函数没有变,分区方案中的文件组个数就不能变)。
为分区方案指定一个可用的文件组的代码如下所示:
ALTER PARTITION SCHEME partschSale NEXT USED [Sale2010] 其中:
1、ALTER PARTITION SCHEME意思是修改分区方案
2、partschSale是分区方案名
3、NEXT USED意思是下一个可使用的文件组
4、[Sale2010]是文件组名
为分区方案添加了下一个可使用的文件组之后,分区方案并没有立刻使用这个文件组,此时我们可以通过查看分区方案的源代码来证实。查看方法是:在SQL Server Management Studio中,选择数据库–>存储–>分区方案,右击分区方案名,在弹出的菜单中选择“编写分区方案脚本为”–>CREATE到–>新查询编辑器窗口,如下图所示:

为分区方案添加了下一个可使用的文件组之后,我们就可以动手修改分区函数了,使用代码如下所示:
ALTER PARTITION FUNCTION partfunSale() SPLIT RANGE ('20100101') 其中:
1、ALTER PARTITION FUNCTION意思是修改分区函数
2、partfunSale()为分区函数名
3、SPLIT RANGE 意思是分割界限
4、’20100101’ 是用于分割的界限值
当然,我们在修改分区函数前后都可以统计一下各物理分区的数据记录情况,如以下代码所示:
--统计所有分区表中的记录总数
select $PARTITION.partfunSale(SaleTime) as 分区编号,count(id) as 记录数 from Sale group by $PARTITION.partfunSale(SaleTime) --原来的分区函数是将2010-1-1之前的数据放在第1个分区表中,将2010-1-1至2011-1-1之间的数据放在第2个分区表中 --现在需要将2011-1-1之前的数据都放在第1个分区表中,也就是将第1个分区表和第2个分区表中的数据合并 --修改分区函数 ALTER PARTITION FUNCTION partfunSale() SPLIT RANGE ('20100101') --统计所有分区表中的记录总数 select $PARTITION.partfunSale(SaleTime) as 分区编号,count(id) as 记录数 from Sale group by $PARTITION.partfunSale(SaleTime) 以上代码的运行结果如下图所示:
从上图中可以看出,分区表中已经添加了一个分区,我们也可以再一次查看分区方案的源代码,如下图所示,这个时候分区方案也自动添加了一个文件组。

将已分区表转换成普通表
我的俄罗斯名叫作“不折腾不舒服斯基”,所以,不将分区表好好折腾一下,我就是不舒服。
在前面,我们介绍过怎么样直接创建一个分区表,也介绍过怎么将一个普通表转换成一个分区表。那么,这两种方式创建的表有什么区别呢?现在,我又最新地创建了两个表:
第一个表名为Sale,这个表使用的是《SQL Server 2005中的分区表(一):什么是分区表?为什么要用分区表?如何创建分区表?》中的方法创建的,在创建完之后,还为该表添加了一个主键。
第二个表名Sale1,这个表使用的是《SQL Server 2005中的分区表(三):将普通表转换成分区表 》中的方法创建的,也就是先创建了一个普通表,然后通过为普通表添加聚集索引的方式将普通表转换成已分区表的方式。
通过以上方法都可以得到一个已分区表,但是,这两个已分区表还是有点区别的,区别在哪里呢?我们分别查看一下这两个表的索引和主键吧,如下图所示。
 从上图可以看出,直接创建的分区表Sale的索引里,只有一个名为PK_Sale的索引,这个索引是唯一的、非聚集的索引,也就是在创建PK_Sale主键时SQL Server自动创建的索引。而经普通表转换成分区表的Sale1的索引里,除了在创建主键时由SQL Server自动创建的名为PK_Sale1的唯一的、非聚集的索引之外,还存在一个名为CT_Sale1的聚集索引。 对于表Sale来说,可以通过修改分区函数的方式来将其转换成普通表,具体的修改方式请看《SQL Server 2005中的分区表(四):删除(合并)一个分区》,事实上,就是将分区函数中的所有分区分界都删除,那么,这个分区表中的所有数据就只能存在第一个分区表中了。在本例中,可以使用以下代码来修改分区函数。
ALTER PARTITION FUNCTION partfunSale() MERGE RANGE ('20100101') ALTER PARTITION FUNCTION partfunSale() MERGE RANGE ('20110101') ALTER PARTITION FUNCTION partfunSale() MERGE RANGE ('20120101') ALTER PARTITION FUNCTION partfunSale() MERGE RANGE ('20130101') 事实上,这么操作之后,表Sale还是一个分区表,如下图所示,只不过是只有一个分区的分区了,这和普遍表就没有什么区别了。

对于通过创建分区索引的方法将普通表转换成的分区表而言,除了上面的方法之外,还可以通过删除分区索引的办法来将分区表转换成普通表。但必须要经过以下两个步骤:
1、删除分区索引
2、在原来的索引字段上重建一个索引。
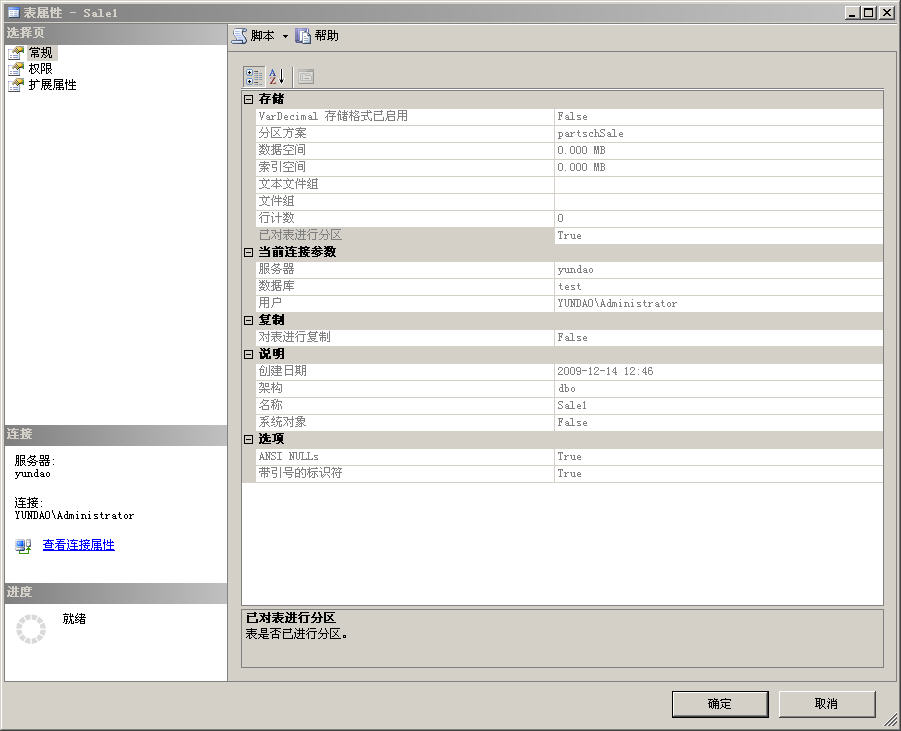
先说删除分区索引吧,这一步很简单,你可以直接在SQL Server Management Studio上将分区索引删除,也可以使用SQL语句删除,如本例中可以使用以下代码删除已经创建的分区索引。
drop index Sale1.CT_Sale1 一开始,我还以为只要删除了分区索引,那么分区表就会自动转换成普通表了,可是在删除索引之后,查看一下该表的属性,结果还是已分区表,如下图所示。
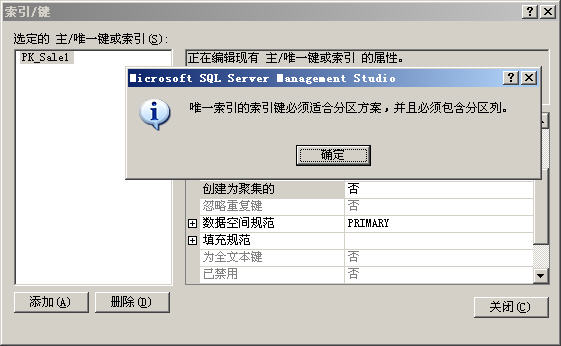
不但如此,而且,还不能将原来的聚集的唯一索引(在本例中为主键的那个索引)改成聚集索引,如下图所示。
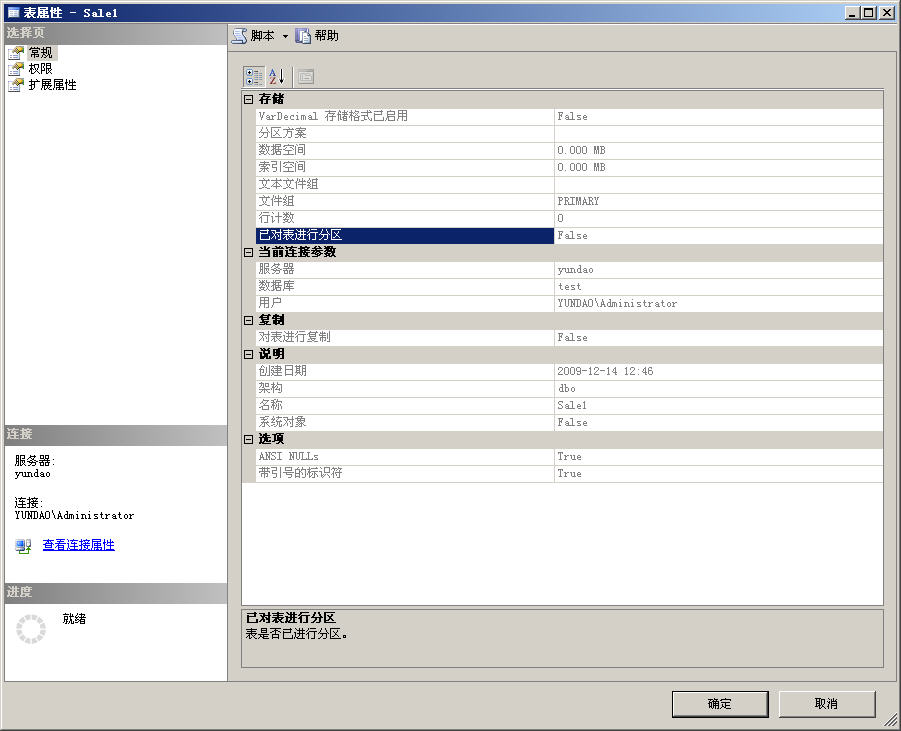
如果要彻底解决这个问题,还必须要在原来创建分区索引的字段上重新创建一下索引,只有重新创建过索引之后,SQL Server才能将已分区表转换成普通表。在本例中可以使用以下代码重新创建索引。
CREATE CLUSTERED INDEX CT_Sale1 ON Sale1([SaleTime]) ON [PRIMARY] Go 重建索引之后,分区表就变成了普通表,现在再查看一下Sale1表的属性,我们可以看到原来的分区表已经变成了普通表,如下图所示。
当然,以上两个步骤也可以合成一步完成,也就是在重建索引的同时,将原索引删除。如以下代码所示:
CREATE CLUSTERED INDEX CT_Sale1 ON Sale1([SaleTime]) WITH ( DROP_EXISTING = ON) ON [PRIMARY] 按理说,在SQL Server Management Studio中的操作和使用SQL语句的操作是一样的,可是我在SQL Server Management Studio中将聚集索引删除后再在该字段上重新创建一个同名的索引,并重新生成和组织该索引,可是分区表还是没有变成普通表,这就让我百思不得其解了。不过呢,只要能用SQL语句达到目的,那我们就用它吧。
转载自:http://blog.csdn.net/smallfools/article/category/213917
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/134828.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
