大家好,又见面了,我是你们的朋友全栈君。
目录
一、SVM简介
简介:SVM的英文全称是Support Vector Machines,中文叫支持向量机。支持向量机是我们用于分类的一种算法。支持向量也可以用于回归,此时叫支持向量回归(Support Vector Regression,简称SVR)。
发展历史:1963年,ATE-T Bell实验室研究小组在Vanpik的领导下,首次提出了支持向量机(SVM)理论方法。但在当时,SVM在数学上不能明晰地表示,人们对模式识别问题的研究很不完善,因此SVM的研究没有得到进一步的发展与重视。 1971年,Kimeldorf提出了使用线性不等约束重新构造SV的核空间,使一部分线性不可分的问题得到了解决。20世纪90年代,一个比较完善的理论体系——统计学习理论(Statistical Learning Theory,SLT)形成了,此时一些新兴的机器学习方法(如神经网络等)的研究遇到了一些重大的困难,比如欠学习与过学习问题、如何确定网络结构的问题、局部极小点问题等,这两方面的因素使得SVM迅速发展和完善,并在很多问题的解决中表现出许多特有优势,而且能够推广应用到函数拟合等其他机器学习问题中,从此迅速发展了起来,目前已经成功地在许多领域里得到了成功应用。
思想:SVM的主要思想可以概括为如下两点:
(1)它是针对线性可分的情况进行分析的。对于线性不可分的情况,通过使用非线性映射算法将低维输入空间线性不可分的样本转化为高维特征空间,使其线性可分,从而使得在高维特征空间中采用线性算法对样本的非线性特征进行线性分析成为可能。
(2)它基于结构风险最小化理论,在特征空间中构建最优分类面,使得学习器能够得到全局最优化,并且使整个样本空间的期望风险以某个概率满足一定上界。
从上面的两点基本思想来看,SVM没有使用传统的推导过程,简化了通常的分类和回归等问题;少数的支持向量确定了SVM 的最终决策函数,计算的复杂性取决于支持向量,而不是整个样本空间,这就可以避免“维数灾难”。少数支持向量决定了最终结果,这不但可以帮助我们抓住关键样本,而且注定了该方法不但算法简单,而且具有较好的“鲁棒”性。
数学基础:拉格朗日乘子法、对偶问题、KKT条件
应用:人脸检测、验证和识别,说话人/语音识别,文字/手写体识别 ,图像处理等等
二、推导过程
SVM有三宝:间隔、对偶、核技巧。
遇到的问题大致可以分为线性可分和线性不可分的情况,因此,我将分开介绍:
1.线性可分
1.1 硬间隔
1. 基本模型
训练样本集 D = { ( x 1 , y 1 ) , ( x 1 , y 1 ) , … … , ( x m , y m ) } , y i = 1 或 y i = − 1 D=\{(x_{1},y_{1}),(x_{1},y_{1}),……,(x_{m},y_{m})\},y_{i}=1或y_{i}=-1 D={
(x1,y1),(x1,y1),……,(xm,ym)},yi=1或yi=−1,分类学习的思想:找一个划分超平面,将不同类别的样本分开。
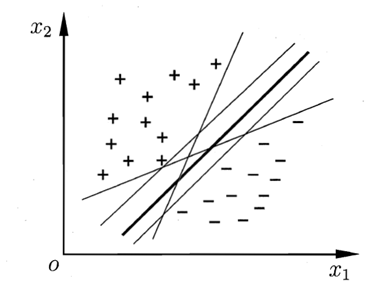

划分的超平面很多,我们去找哪一个?直观上看,我们应该找位于两类训练样本“正中间”的超平面。
在样本空间中,划分超平面可通过如下线性方程来描述: w T x + b = 0 {\color{Red} w^{T}x+b=0} wTx+b=0
其 w = ( w 1 ; w 2 ; … ; w d ) w=(w_{1};w_{2};…;w_{d}) w=(w1;w2;…;wd)为法向量,决定了超平面的方向;b为位移项,决定了超平面与原点之间的距离。
显然,划分超平面可被法向量w和位移b确定,下面我们将其记为(w,b)。 样本空间中任意点x到超平面(w,b)的距离可写为 r = ∣ w T x + b ∣ ∥ w ∥ {\color{Red} r=\frac{\left | w^{T}x+b \right |}{\left \| w \right \|}} r=∥w∥∣wTx+b∣
假设超平面(w,b)能将训练样本正确分类,即对 ( x i , y i ) ∈ D (x_{i},y_{i} )\in D (xi,yi)∈D,若 y i = + 1 y_{i}=+1 yi=+1,则 w T x i + b > 0 w^{T}x_{i}+b>0 wTxi+b>0.否则: w T x i + b < 0 w^{T}x_{i}+b<0 wTxi+b<0,令
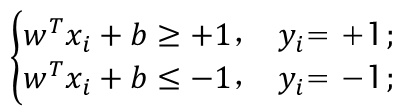
对应如下:
问题只与投影方向有关,一旦方向定了,通过缩放w和b,总能使上式成立。所以,求超平面的问题转化为求w和b的问题。
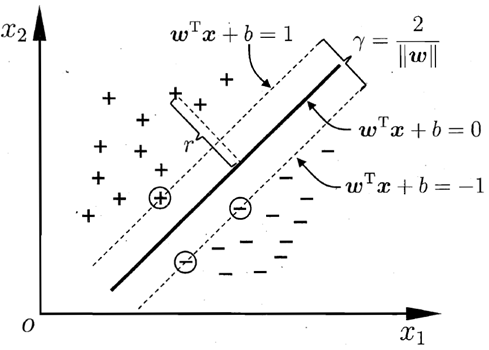
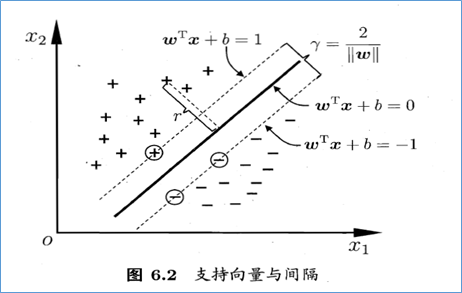
如下图所示,距离超平面最近的这几个训练样本点使上式的等号成立,它们被称为“支持向量”(support vector),两个异类支持向量机到超平面的距离之和为 : r = ∣ w T x + b ∣ ∥ w ∥ {\color{Red} r=\frac{\left | w^{T}x+b \right |}{\left \| w \right \|}} r=∥w∥∣wTx+b∣
上图中,两条虚线之间的距离为: γ = 2 ∥ w ∥ \gamma =\frac{2}{\left \| w \right \|} γ=∥w∥2,将其称之为间隔。欲找到具有“最大间隔”(maximum margin)的划分超平面,也就是找到参数w和b,使得γ最大,即:
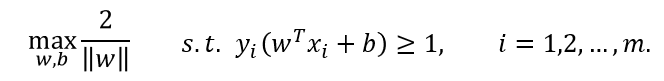
上面的约束等价于如下约束:
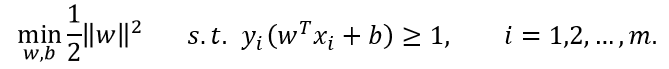
即支持向量机(Support Vector Machine,简称SVM)的基本型。
2. 模型求解
上式中,其中w和b是模型参数。注意到上式本身是一个凸二次规划问题,能直接用现成的优化计算包求解,但我们可以有更高效的办法,可以求出闭式解。
对式使用拉格朗日乘子法可得到其“对偶问题”(dual problem):
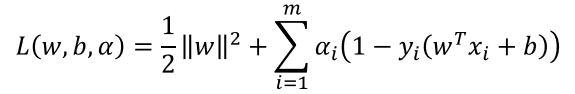
其中 α = ( α 1 ; α 2 ; … ; α m ) \alpha =(\alpha _{1};\alpha _{2};…;\alpha _{m}) α=(α1;α2;…;αm),令 L ( w , b , α ) L(w,b,\alpha) L(w,b,α)对w和b的偏导数等于零得:
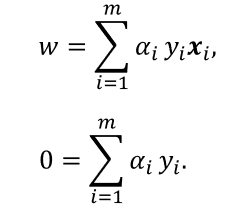
将第一个式代入L,即可将 L ( w , b , α ) L(w,b,α) L(w,b,α)中的w和b消去,再考虑第二个式的约束,就得到对偶问题:
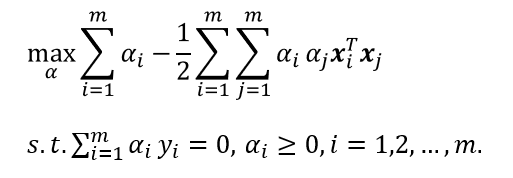
解出α后,求出w和b即可得到模型:
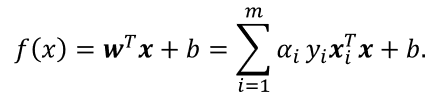
从对偶问题解出的 α i α_i αi是拉格朗日乘子,它恰对应着训练样本 ( x i , y i ) (x_i,y_i) (xi,yi)。注意到支持向量机最优化问题中有不等式约束,因此上述过程需满足KKT条件,即要求:
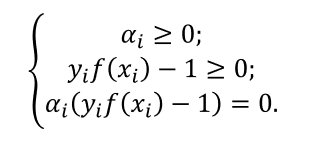
最后一个条件,对任意训练样本 ( x i , y i ) (x_i,y_i) (xi,yi),总有 α i = 0 \alpha _{i}=0 αi=0或 y i f ( x i ) = 1 y_{i}f(x_{i})=1 yif(xi)=1.
则有以下两种情况:
(1) 若 α i = 0 α_i=0 αi=0,则该样本将不会在求和中出现,不会对f(x)有任何影响;
(2) 若 α i > 0 α_i>0 αi>0,则必有 y i f ( x i ) = 1 y_i f(x_i )=1 yif(xi)=1,位于最大间隔边界上,是一个支持向量。
这显示出支持向量机的一个重要性质:训练完成后,大部分的训练样本都不需保留,最终模型仅与支持向量有关.
如何求解 α i α_i αi:二次规划问题,通过SMO算法求解。
基本思路:每次选择两个变量α_i和α_j,并固定其他参数。这样,在参数初始化后,SMO不断执行如下两个步骤直至收敛:
(1) 选取一对需更新的变量 α i α_i αi和 α j α_j αj;
(2) 固定 α i α_i αi和 α j α_j αj以外的参数,求解式获得更新后的 α i α_i αi和 α j α_j αj.
分析:KKT条件违背的程度越大,则变量更新后可能导致的且标函数值减幅越大。
第一个变量:SMO先选取违背KKT条件程度最大的变量。
第二个变量:应选择一个使且标函数值减小最快的变量,使选取的两变量所对应样本之间的间隔最大。
为什么更新两个,而非一个?原因是,若仅选择一个,则其可有其他变量导出。因此更新两个。
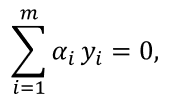
SMO算法之所以高效,是由于在固定其他参数后,仅优化两个参数的过程能做到非常高效。
之前的优化问题:
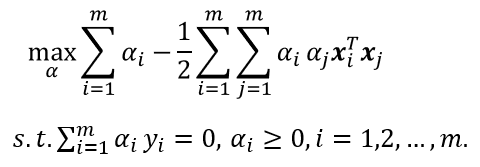
仅考虑 α i α_i αi和 α j α_j αj时,式中的约束可重写为:
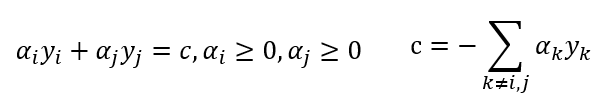
其中c是使 ∑ i = 0 m α i y i = 0 ∑_{i=0}^mα_i y_i=0 ∑i=0mαiyi=0成立的常数。用 α i y i + α j y j = c α_i y_i+α_j y_j=c αiyi+αjyj=c消去上式中的变量 α j α_j αj,则得到一个关于 α i α_i αi的单变量二次规划问题,仅有的约束是 α i ≥ 0 α_i≥0 αi≥0。
不难发现,这样的二次规划问题具有闭式解,于是不必调用数值优化算法即可高效地计算出更新后的 α i α_i αi和 α j α_j αj.
确定偏移项b:
対任意支持向量 ( x i , y k ) (x_i,y_k) (xi,yk) 都有 y s f ( x s ) = 1 y_s f(x_s )=1 ysf(xs)=1,即
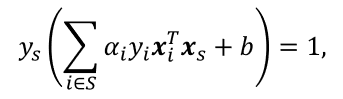
其中 S = { i ∣ α i > 0 , i = 1 , 2 , … , m } S=\{i|α_{i}>0,i=1,2,…,m\} S={
i∣αi>0,i=1,2,…,m} 为所有支持向量的下标集,但现实任务中常采用一种更鲁棒的做法:使用所有支持向量求解的平均值
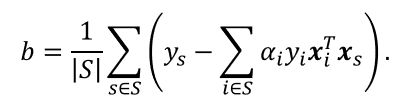
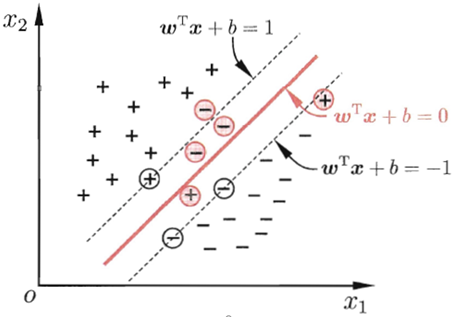
1.2 软间隔
在现实任务中往往很难确定合适的核函数使得训练样本在特征空间中线性可分。
缓解该问题的一个办法是允许支持向量机在一-些样本上出错.为此,要引入“软间隔”的概念,如图所示:
在最大化间隔的同时,不满足约束的样本应尽可能少.于是,优化目标可写为:
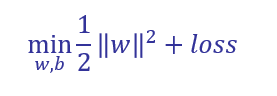
即,在间隔上加一个损失,允许错分,但是损失应该尽量小。
(1)0/1损失函数
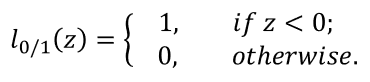
显然,当C为无穷大时,迫使所有样本均满足约束,于是等价于经典支持向量机方法;
当C取有限值时,允许一些样本不满足约束。
然而, l 0 / 1 l_{0/1} l0/1非凸、非连续,不易直接求解。人们通常用其他一些函数来代替 l 0 / 1 l_{0/1} l0/1,称为“替代损失”(surrogate loss),通常是凸的连续函数且是 l 0 / 1 l_{0/1} l0/1的上界。
(2)hinge损失函数
若采用hinge损失,则代价函数变成:
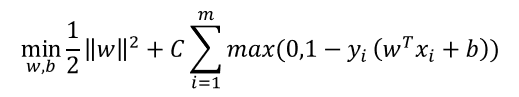
引入“松弛变量”(slack variables) ξ i ≥ 0 ξ_i≥0 ξi≥0,可将重写为:
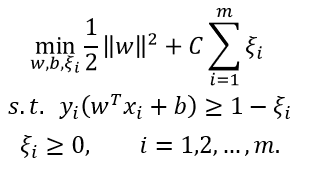
这就是常用的“软间隔支持向量机”。
(3)其他损失函数
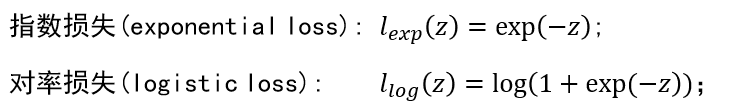
损失函数:
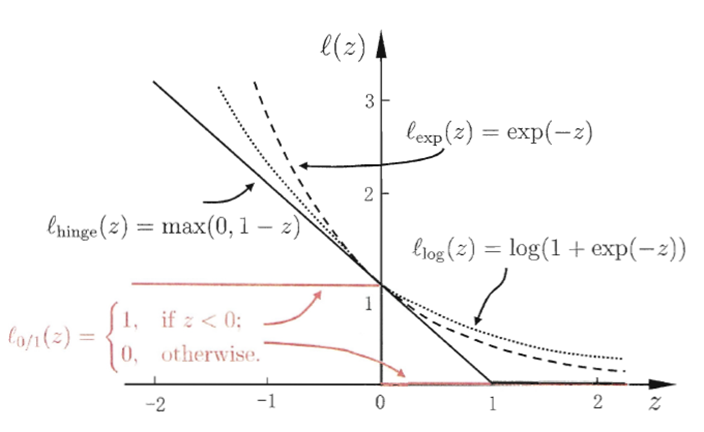
标准:>0时,尽可能小,<0时,尽可能大。从而保证分类的准确性。
2.线性不可分(核函数)
我们假设训练样本是线性可分的,超平面能将训练样本正确分类。然而在现实任务中,原始样本空间内也许并不存在一个能正确划分两类样本的超平面。例如图中的“异或”问题就不是线性可分的.
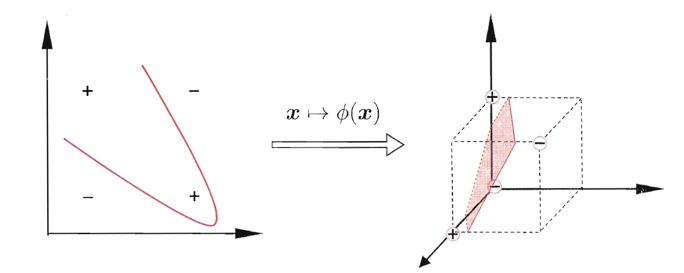
对这样的问题,可将样本从原始空间映射到一个更高维的特征空间,使得样本在这个特征空间内线性可分。
例如在图中,若将原始的二维空间映射到一个合适的三维空间,就能找到一个合适的划分超平面。
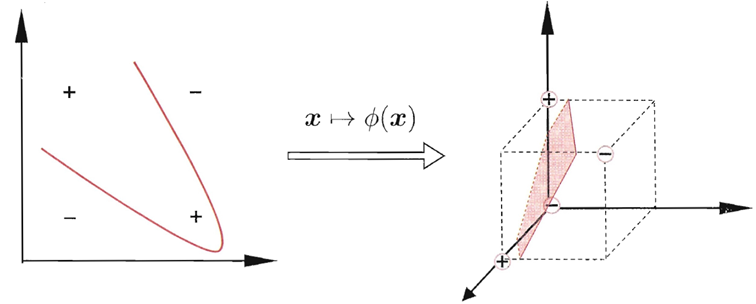
如何映射?有没有通用的办法?
幸运的是,如果原始空间是有限维,即属性数有限,那么一定存在一个高维特征空间使样本可分。 令∅(x)表示将x映射后的特征向量,于是,在特征空间中划分超平面所对应的模型可表示为:
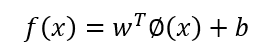
其中w和b是模型参数。
问题转化为:
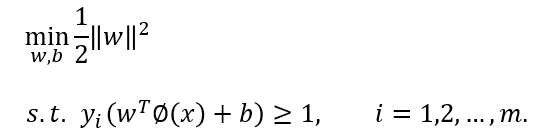
其对偶问题是:
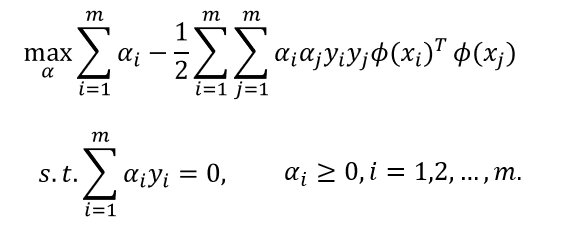
求解式涉及到计算 ϕ ( x i ) T ϕ ( x j ) ϕ(x_i )^T ϕ(x_j ) ϕ(xi)Tϕ(xj),这是样本 x i x_i xi与 x j x_j xj映射到特征空间之后的内积。
由于特征空间维数可能很高,甚至可能是无穷维,因此直接计算 ϕ ( x i ) T ϕ ( x j ) ϕ(x_i )^T ϕ(x_j ) ϕ(xi)Tϕ(xj)通常是困难的。
为了避开这个障碍,可以设想这样一个函数:
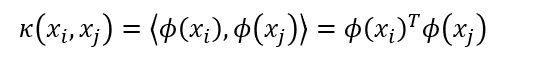
即 x i x_i xi与 x j x_j xj在特征空间的内积等于它们在原始样本空间中通过函数κ(∙,∙ )计算的结果。
有了这样的函数,我们就不必直接去计算高维甚至无穷维特征空间中的内积。
于是式可重写为:
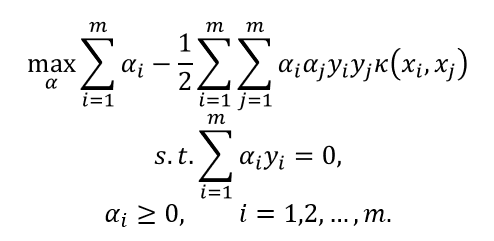
于是,求解后即可得到:
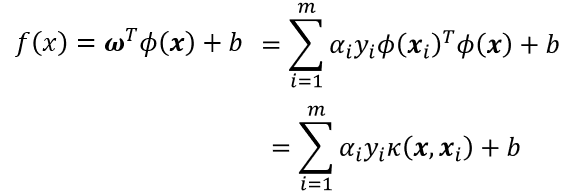
这里的函数κ(∙,∙ )就是“核函数”(kernel function)。上式显示出模型最优解可通过训练样本的核函数展开,这一展式亦称“支持向量展式”(support vector expansion)。
问题:显然,若已知合适映射ϕ(∙)的具体形式,则可写出核函数κ(∙,∙ ),但在现实任务中我们通常不知道ϕ(∙)是什么形式。
合适的核函数是否一定存在呢?什么样的函数能做核函数呢?
答案是肯定的。
定理(核函数) 令χ为输入空间,κ(∙,∙ )是定义在 χ × χ χ×χ χ×χ上的对称函数,则κ是核函数当且仅当对于任意数据 D = { x 1 , x 2 , … , x m } D=\{x_{1},x_{2},…,x_{m}\} D={
x1,x2,…,xm},“核矩阵”(kernel matrix)K总是半正定的:
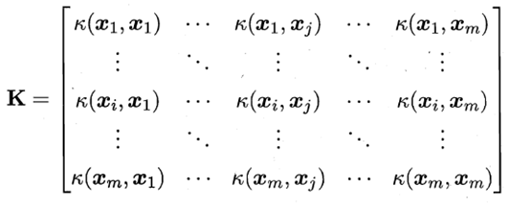
定理表明,只要一个对称函数所对应的核矩阵半正定,它就能作为核函数使用。
在不知道特征映射的形式时,我们并不知道什么样的核函数是合适的,“核函数选择”成为支持向量机的最大变数。
通常,可选择如下核函数,选择性能最优者作为某一问题的核函数:

注意:当d=1时,高斯核也成为径向基核函数(RBF)核。
此外,还可通过函数组合得到,例如:
(1) 若κ_1和κ_2为核函数,则对于任意正数 γ 1 、 γ 2 γ_1、γ_2 γ1、γ2,其线性组合也是核函数:
γ 1 κ 1 + γ 2 κ 2 γ_1 κ_1+γ_2 κ_2 γ1κ1+γ2κ2
(2) 若κ_1和κ_2为核函数,则核函数的直积也是核函数;
κ 1 ⊗ κ 2 ( x , z ) = κ 1 ( x , z ) κ 2 ( x , z ) κ_1 ⊗κ_2 (x,z)=κ_1 ( x,z)κ_2 (x,z) κ1⊗κ2(x,z)=κ1(x,z)κ2(x,z)
(3) 若κ_1为核函数,则对于任意函数g(x),也是核函数;
κ ( x , z ) = g ( x ) κ 1 ( x , z ) g ( z ) κ(x,z)=g(x)κ_1 (x,z)g (z) κ(x,z)=g(x)κ1(x,z)g(z)
3.SVR支持向量回归
给定训练样本 D = { ( x 1 , y 1 ) , ( x 1 , y 1 ) , … … , ( x m , y m ) } , y i ∈ R D=\{(x_{1},y_{1}),(x_{1},y_{1}),……,(x_{m},y_{m})\},y_{i}∈R D={
(x1,y1),(x1,y1),……,(xm,ym)},yi∈R,希望学得一个回归模型,使得 f ( x ) f(x) f(x)与 y y y尽可能接近, w w w和 b b b是待确定的模型参数。
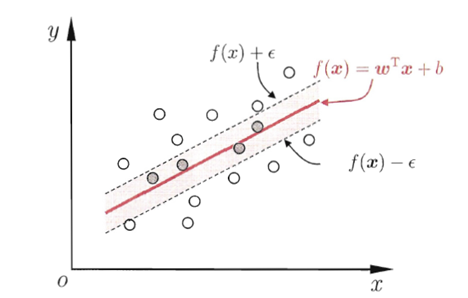
假设我们能容忍 f ( x ) f(x) f(x)与 y y y之间最多有 ϵ ϵ ϵ的偏差,即仅当 f ( x ) f(x) f(x)与 y y y之间的差别绝对值大于 ϵ ϵ ϵ时才计算损失.
于是,SVR问题可形式化为:
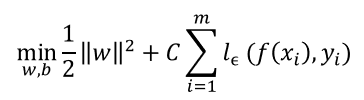
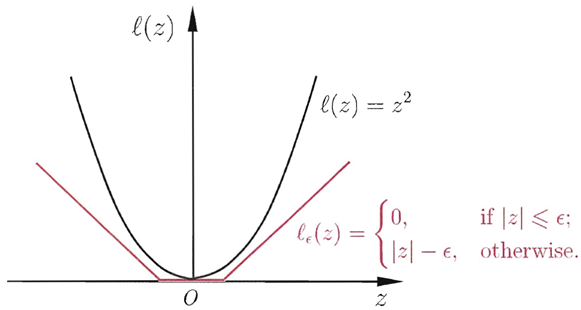
其中C为正则化常数, l ϵ l_ϵ lϵ是图中所示的ϵ -不敏感损失(ϵ -insensitive loss)函数:
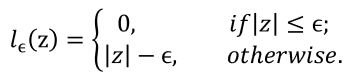
引入松弛变量 ξ i ξ_i ξi和 ( ξ i ) (ξ_i ) (ξi),可将式重写为:

引入拉格朗日乘子 μ i μ_i μi,
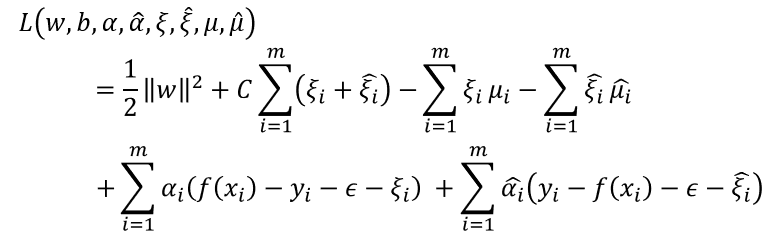
再令 L ( w , b , α , α ^ , ξ , ξ ^ , μ , μ ^ ) L(w,b,\alpha ,\hat{\alpha },\xi ,\hat{\xi },\mu ,\hat{\mu }) L(w,b,α,α^,ξ,ξ^,μ,μ^)对 w w w, b b b, ξ i ξ_i ξi, ξ i ^ \hat{ξ_i } ξi^ 的偏导为零可得:
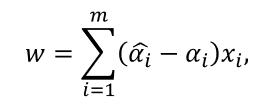
上述过程中需满足KKT条件,即要求:
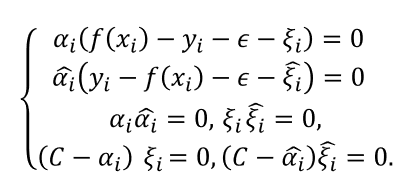
SVR的解形如
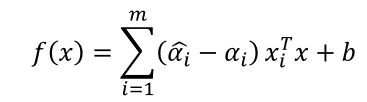
能使式中的 ( α i ^ − α i ) ≠ 0 (\hat{\alpha_i}-α_i )\neq 0 (αi^−αi)̸=0的样本即为SVR的支持向量,它付必落在ϵ-同隔带之外.显然, SVR的支持向量仅是训练样本的一部分,即其解仍具有稀疏性.
若 0 < α i < C 0<α_i<C 0<αi<C,则必有 ξ i = 0 ξ_i=0 ξi=0,
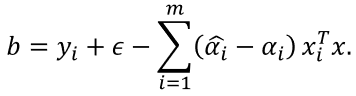
实践中常采用一中更鲁棒的办法:迭取多个满足条件 0 < α i < C 0<α_i<C 0<αi<C的样本求解b后取平均値。
若考虑特征映射形式,则:
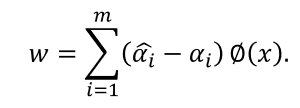
则SVR可表示为:
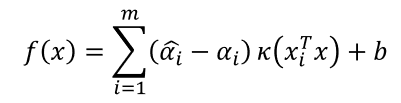
其中 K ( x i T x ) = ∅ ( x i ) T ∅ ( x j ) K(x_i^T x)=∅(x_i )^T∅(x_j ) K(xiTx)=∅(xi)T∅(xj)为核函数。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/134777.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
