大家好,又见面了,我是你们的朋友全栈君。
Python爬虫之URL管理器:

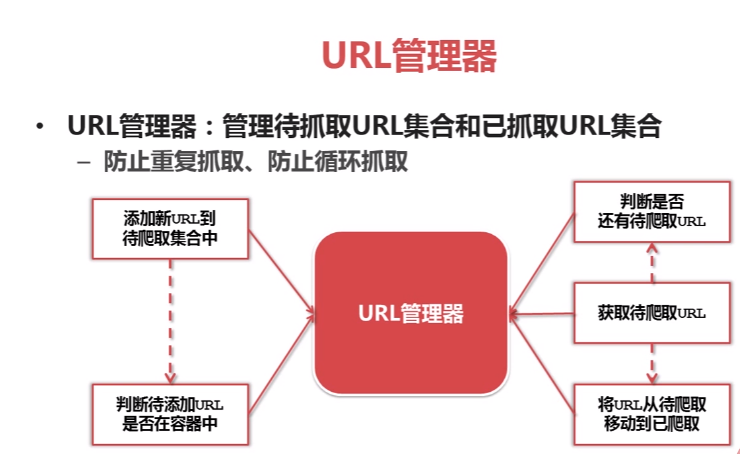
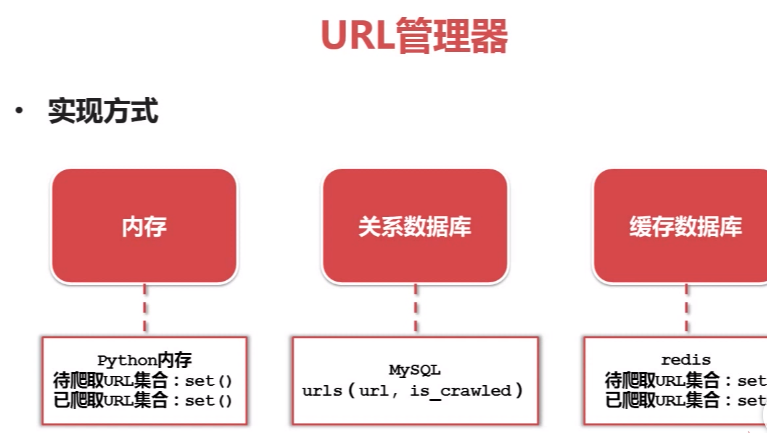
Python爬虫:URL管理器实现方式:
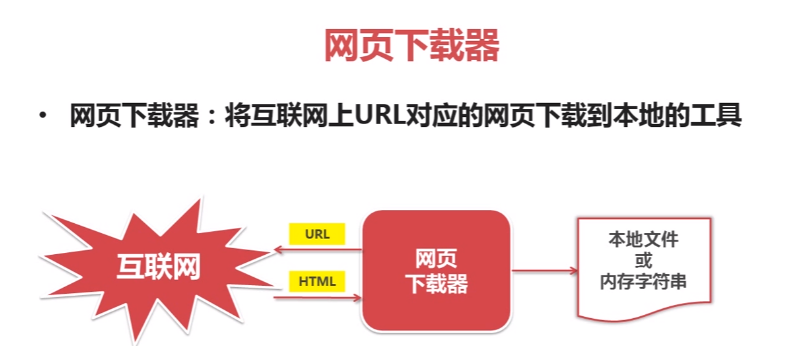
Python爬虫之网页下载器:
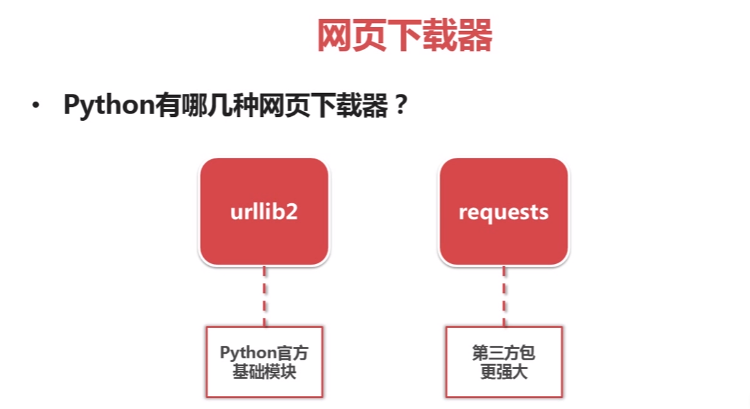
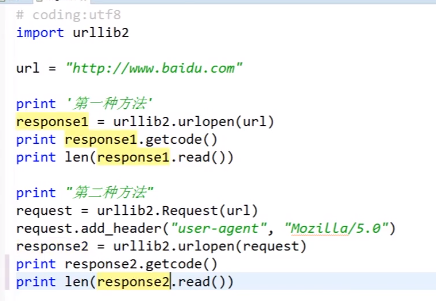
urllib2实现网页下载器的三种方法:



具体代码:

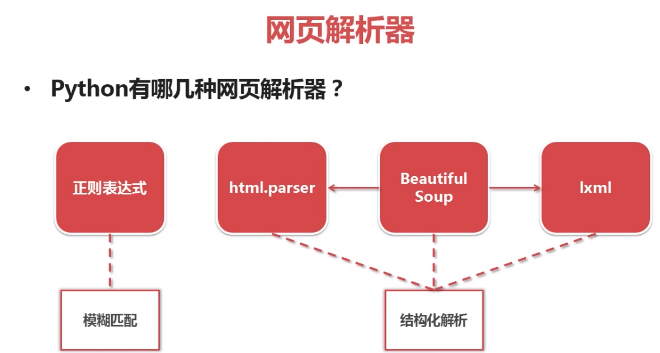
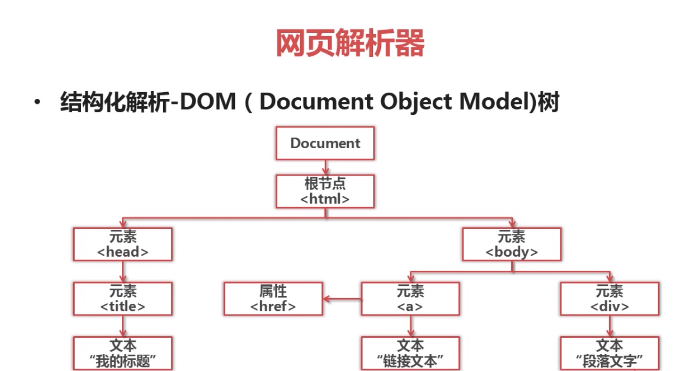
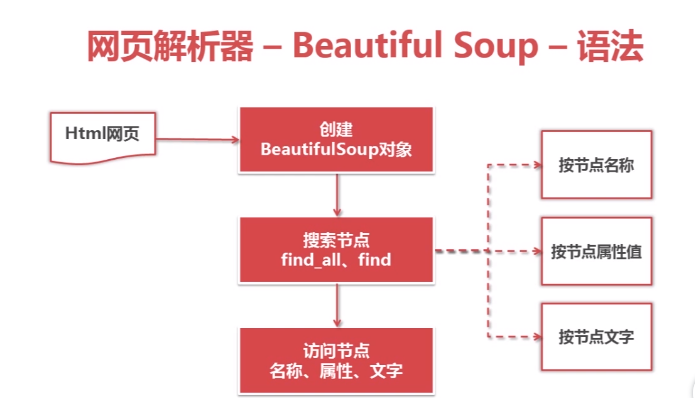
Python网页解析器:



例子:
import requests
from bs4 import BeautifulSoup
def getHTMLText(url):
try:
r = requests.get(url, timeout = 30)
r.raise_for_status()
#r.encoding = 'utf-8'
return r.text
except:
return ""
def getContent(url):
html = getHTMLText(url)
# print(html)
soup = BeautifulSoup(html, "html.parser")
title = soup.select("div.hd > h1")
print(title[0].get_text())
time = soup.select("div.a_Info > span.a_time")
print(time[0].string)
author = soup.select("div.qq_articleFt > div.qq_toolWrap > div.qq_editor")
print(author[0].get_text())
paras = soup.select("div.Cnt-Main-Article-QQ > p.text")
for para in paras:
if len(para) > 0:
print(para.get_text())
print()
#写入文件
fo = open("text.txt", "w+")
fo.writelines(title[0].get_text() + "\n")
fo.writelines(time[0].get_text() + "\n")
for para in paras:
if len(para) > 0:
fo.writelines(para.get_text() + "\n\n")
fo.writelines(author[0].get_text() + '\n')
fo.close()
#将爬取到的文章用字典格式来存
article = {
'Title' : title[0].get_text(),
'Time' : time[0].get_text(),
'Paragraph' : paras,
'Author' : author[0].get_text()
}
print(article)
def main():
url = "http://news.qq.com/a/20170504/012032.htm"
getContent(url);
main()版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/134735.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
