大家好,又见面了,我是你们的朋友全栈君。
自然语言处理中一个很常见的操作就是文本分类,比如一组新闻文本,通过分类模型,将新闻文本分为政治、体育、军事、娱乐、财经等等几大类。那么分类第一步就是文本向量化,前一篇博客讲了一些,本文可以说是前文的实践版本。本文主要介绍一些常见的文本分类模型,说是介绍,其实主要以代码和结果为主,并不会详细的介绍每个算法的思想、原理、推导过程等,那样的话,估计可以写一个7、8篇的系列了,另外我也发现很多博客都是理论为主,代码非常少,给人的感觉就是这件事我弄明白了,但具体如何干不知道,讲的似乎很难、很神秘,没有相应代码,让人望而生畏。所以本文还是偏工程一些,阅读本文的同学希望已经有了这些文本分类算法的理论基础。先说说我用的数据,约20万短文本,包含8个大类,分别为:餐饮、交通、购物、娱乐、居家等,每个大类约25000条数据,文本平均20个字左右,最短的文本仅有2个字。如下面所示:
__label__1 天猫 超市 慕滋 五谷 无 添加 糖 粗粮 杂粮 消化 饼干 g 代 早餐 糕点
__label__1 天猫 超市 满 减 云南 红 提 kg 提子 葡萄 新鲜 水果
__label__1 天猫 超市 原装 进口 嘘 嘘 乐 成长 裤 纸尿裤 拉拉 裤 L19 片 Kg
__label__1 天猫 超市 卫龙 小 面筋 g 零食 辣条 辣片 麻辣 素食 豆干 制品 大刀 肉
__label__1 天猫 超市 康师傅 矿物质 水 ml 瓶 整箱 饮用水
__label__1 天猫 超市 红牛 维生素 功能 饮料 整箱 装 原味 型 ml 罐 箱
__label__1 天猫 超市 香楠 蛋羹 味 麻薯 夹心 麻 糬 糕点 休闲 零食 小吃 g
__label__1 天猫 超市 蒙牛 特仑苏 醇 纤 牛奶 ml 盒 平衡 搭档 平衡 好搭档
__label__1 天猫 超市 味全 每日 C 纯 果汁 胡萝卜 果蔬汁 ml16 截单
__label__1 天猫 超市 金 菜地 豆干 五香 茶 干 g 豆腐干 特色 休闲 零食 豆制品
__label__1 天猫 超市 新 希望 牛奶 香蕉 牛奶 ml 盒 箱 甜蜜 好 滋味
__label__1 天猫 超市 良品 铺子 爆浆 麻薯 抹 茶味 g 糕点 点心 零食 特产 小吃
__label__1 天猫 超市 森永 嗨 酸酸 哒 酸果 软糖 青 柠味 g 维 c 水果 糖果 零食
__label__1 天猫 超市 桂格 即食 纯 燕麦片 粗粮 原味 冲 饮 谷物 早餐 g 袋装
__label__1 天猫 超市 满 减 挪威 冰冻 青花鱼 柳 g 包 冷冻 海鲜 鱼肉 鲭 鱼
__label__1 天猫 超市 甘 竹牌 豆豉 鲮鱼 罐头 g 盒 下 饭菜 特产 小吃 休闲 食品
__label__1 天猫 超市 姚 太太 青口 梅 g 蜜饯 果脯 话梅 肉 梅子 青梅 酸甜 凉果
__label__1 天猫 超市 蒙牛 特仑苏 醇 纤 牛奶 ml 盒 平衡 搭档 平衡 好搭档import random
import fasttext
import numpy as np
import tensorflow as tf
from sklearn.svm import SVC
from sklearn.naive_bayes import MultinomialNB
from sklearn.neighbors import KNeighborsClassifier
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.feature_extraction.text import CountVectorizer, TfidfTransformer
# 朴素贝叶斯算法
def nb_model(train, train_label, test, test_label):
clf_model = MultinomialNB(alpha=0.01)
clf_model.fit(train, train_label)
predict_results = clf_model.predict(test)
count = 0
predict_list = predict_results.tolist()
for i, pred in enumerate(predict_list):
if (pred == test_label[i]):
count += 1
print("nb_model_precision_score: " + str(float(count) / len(predict_list)))
# K近邻算法
def knn_model(train, train_label, test, test_label):
knn_model = KNeighborsClassifier(n_neighbors=8)
knn_model.fit(train, train_label)
predict_results = knn_model.predict(test)
count = 0
predict_list = predict_results.tolist()
for i, pred in enumerate(predict_list):
if (pred == test_label[i]):
count += 1
print("knn_model_precision_score: " + str(float(count) / len(predict_list)))
# 支持向量机算法
def svm_model(train, train_label, test, test_label):
svm_clf = SVC(kernel="linear", verbose=False)
svm_clf.fit(train, train_label)
predict_results = svm_clf.predict(test)
count = 0
predict_list = predict_results.tolist()
for i, pred in enumerate(predict_list):
if (pred == test_label[i]):
count += 1
print("svm_model_precision_score: " + str(float(count) / len(predict_list)))
# 使用传统方法的文本分类
def text_classification():
count = 0
test_text_list = []
train_text_list = []
test_label_list = []
train_label_list = []
total_text_list = []
total_label_list = []
print("start loading data...")
finput = open("data/filter_total_half.txt", encoding='utf-8')
for line in finput:
count += 1
text_array = line.split("\t", 1)
if (len(text_array) != 2):
continue
# 保存全部样本
total_text_list.append(text_array[1])
total_label_list.append(text_array[0])
# 划分训练集和测试集
probability = random.random()
if (probability > 0.2):
train_text_list.append(text_array[1])
train_label_list.append(text_array[0])
else:
test_text_list.append(text_array[1])
test_label_list.append(text_array[0])
finput.close()
print("load data is finished...")
print("start building vector model...")
# 构建词典
vec_total = CountVectorizer()
vec_total.fit_transform(total_text_list)
# 基于构建的词典分别统计训练集/测试集词频, 即每个词出现1次、2次、3次等
vec_train = CountVectorizer(vocabulary=vec_total.vocabulary_)
tf_train = vec_train.fit_transform(train_text_list)
vec_test = CountVectorizer(vocabulary=vec_total.vocabulary_)
tf_test = vec_test.fit_transform(test_text_list)
# 进一步计算词频-逆文档频率
tfidftransformer = TfidfTransformer()
tfidf_train = tfidftransformer.fit(tf_train).transform(tf_train)
tfidf_test = tfidftransformer.fit(tf_test).transform(tf_test)
print("building vector model is finished...")
# 朴素贝叶斯算法
nb_model(tfidf_train, train_label_list, tfidf_test, test_label_list)
# K近邻算法
knn_model(tfidf_train, train_label_list, tfidf_test, test_label_list)
# 支持向量机算法
svm_model(tfidf_train, train_label_list, tfidf_test, test_label_list)
print("building predict model is finished...")
# 使用fastText的文本分类
def fastText_model():
foutput_test = open("data/data_test.txt", 'w', encoding='utf-8')
foutput_train = open("data/data_train.txt", 'w', encoding='utf-8')
with open("data/filter_total_half.txt", encoding='utf-8') as finput:
for line in finput:
probability = random.random()
if (probability > 0.2):
foutput_train.write(line.strip() + "\n")
else:
foutput_test.write(line.strip() + "\n")
foutput_train.flush()
foutput_train.close()
foutput_test.flush()
foutput_test.close()
classifier = fasttext.supervised("data/data_train.txt", "data/cooking_fasttext_bkk.model",
label_prefix="__label__", lr=0.25, dim=100,
silent=False, epoch=25, word_ngrams=3, loss="hs", bucket=2000000)
result = classifier.test("data/data_test.txt")
print(result.precision)
if __name__ == '__main__':
print("\n传统方法文本分类...")
text_classification()
print("\n----------------------------------------------\n")
print("FastText文本分类...")
fastText_model()程序运行结果如下:

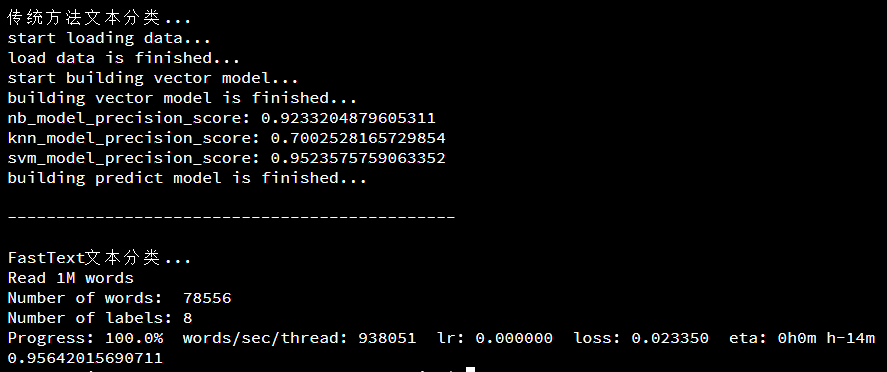
我还写了一个基于卷积神经网络的版本,修改自github,由于公司也有在用,这里就不把代码贴出来了。总体看,cnn的准确度最高,fastText次之。不过基于cnn的方法,需要事先训练词向量,训练过程也比较慢。而传统方法,如svm,准确度达0.95,已经很高了,从这一点也说明,不管是基于深度学习的卷积神经网络分类方法,还是传统的分类方法,其实模型反而是其次,最重要的是数据集的质量,模型选择和模型调参,对最终精度提升都是小幅度的,而数据集的质量高低则是精度提升的瓶颈,有时真得不怕麻烦,整理出一份高质量的数据集,才能训练出精度更准、召回更高的模型。看到这里,是不是很多同学觉得文本分类其实没什么神秘的,有现成的训练框架使用,如:sklearn,还有那么多文献资料可供查阅,唯独没有适合自己业务的训练集,整理训练集,这可能是整个模型训练过程中最花时间的事情了。当然,这里面也涉及很多模型调参细节,需要深入算法原理才能真正玩转。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/134689.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
