大家好,又见面了,我是你们的朋友全栈君。
1、简述对大数据组件的理解?
- Yarn:大数据组件运行的job的管理器
- Spark:分布式的利用内存进行分布式运算的大数据组件
- Hbase:基于Hadoop的大数据常用数据库
- Hive:基于Hadoop的大数据数据仓库,操作和关系型数据库(MySQL)类似
2、hdfs文件系统中NameNode和DataNode的区别和联系?
NameNode存储了元数据,并且调度,协调整个集群
DataNode主要用来存储数据
3、讲述一下HDFS上传文件的流程
① 由客户端 向 NameNode节点节点 发出请求;
②NameNode 向Client返回可以可以存数据的 DataNode 这里遵循机架感应原则;
③客户端 首先 根据返回的信息 先将 文件分块(Hadoop2.X版本 每一个block为 128M 而之前的版本为 64M;
④然后通过NameNode返回的DataNode信息 直接发送给DataNode 并且是 流式写入同时会复制到其他两台机器;
⑤dataNode 向 Client通信 表示已经传完 数据块 同时向NameNode报告
⑥依照上面(④到⑤)的原理将 所有的数据块都上传结束 向 NameNode 报告 表明 已经传完所有的数据块 。
4、了解zookeeper吗?介绍一下它,它的选举机制和集群的搭建。
ZooKeeper 是一个开源的分布式协调服务,是 Google Chubby 的开源实现。
分布式应用程序可以基于 ZooKeeper 实现诸如数据发布/订阅、负载均衡、命名服务、分布式协调/通知、集群管理、Master 选举、分布式锁和分布式队列等功能。公司使用的flume集群,Kafka集群等等,都离不开ZooKeeper。每个节点上都要搭建ZooKeeper服务。首先我们要在每台pc上配置zookeeper环境变量,在cd到zookeeper下的conf文件夹下在zoo_simjle.cfg文件中添加datadir路径,再到zookeeper下新建data文件夹,创建myid,在文件里添加上server的ip地址。在启动zkserver.sh start。
5、分布式引发的问题
- 死锁:至少有一个线程占用了资源,但是不占用CPU
- 活锁:所有线程都没有把持资源,但是线程却是在不断地调度占用CPU
- 需要引入一个管理节点
- 为了防止入口的单点问题,需要引入管理节点的集群
- 需要在管理阶段中选举出一个主节点
- 需要确定一套选举算法
- 主节点和从节点之间要保证数据的一致
6、Avro的介绍?
是序列化和RPC的框架。Avro一开始是Apache Hadoop的子件之一,但是后来发现Avro不只可以用于Hadoop而是可以用于多个场景下的序列化,所以单立出来形成一个新的组件。
7、flume的介绍?
Flume最早是Cloudera提供的日志收集系统,后贡献给Apache。所以目前是Apache下的项目,Flume支持在日志系统中定制各类数据发送方,用于收集数据。
Flume是一个高可用的,高可靠的 鲁棒性(robust 健壮性),分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据(source);同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力(sink)。
8、Hbase的表的设计原则?
1、列族的数量及列族的势
建议将HBase列族的数量设置的越少越好。当强,对于两个或两个以上的列族HBase并不能处理的很好。这是由于HBase的Flushing和压缩是基于Region的。当一个列族所存储的数据达到Flushing的阈值时,该表中所有列族将同时进行Flushing操作。这将带来不必要的I/O开销,列族越多,该特性带来的影响越大。
此外,还要考虑到同一个表中不同列族所存储的记录数量的差别,即列族的势(Cardinality)。当两个列族数量差别过大时会使包含记录数量较少列族的数据分散在多个Region上,而Region有可能存储在不同的RegionServer上。这样,当进行查询或scan操作的时候,系统效率将会受到影响。
2、行键(RowKey)的设计
首先应该避免使用时序或单调(递减/递增)行键。因为当数据到来的时候,HBase首先需要根据记录的行键来确定存储的位置,即Region的位置,如果使用时序或单调行键,那么连续到来的数据将被分配到同一个Region中,而此时系统的其他Region/RegionServer处于空闲状态,这是分布式最不希望看到的状态。
3、尽量最小化行键和列族的大小
在HBase中,一个具体的值由存储该值的行键、对应的列(列族:列)以及该值的时间戳决定。HBase中索引是为了加速随即访问的速度,索引的创建是基于“行键+列族:列+时间戳+值”的,如果行键和列族的大小过大,甚至超过值本身的大小,纳闷将会增加索引的大小。并且在HBase中数据记录往往非常之多,重复的行键、列将不但使索引的大小过大,也将加重系统的负担
4、版本的数量
默认情况下为3个,可以通过HColumnDescriptor进行设置,建议不要设置的过大
9、Hadoop的文件读流程和写流程?
1、读流程:
- 客户端发起RPC请求访问NameNode
- NameNode查询元数据,找到这个文件的存储位置对应数据块的信息
- NameNode将文件对应的数据块的节点地址的全部或者部分放入一个队列中然后返回
- client收到这个数据块对应的节点地址
- client会从队列中取出第一个数据块对应的节点地址,会从这些节点地址中选取一个最近的节点进行读取
- 将Block读取之后,对Block进行shecksum的验证,如果验证失败,说明数据块产生损坏,那么client会向NameNode发送信息说明该节点上的数据块损坏,然后从其他节点中再次读取这个数据块
- 验证成功,则从队列中取出下一个Block的地址,然后继续读取
- 当把这一次的文件快全部读取完成之后,client会向NameNode要下一批Block的地址
- 当把文件全部读取完成之后,从client会向NameNode发送一个读取完毕的信号,,NameNode就会关闭对应的文件
2、写流程:
- client发送RPC请求给NameNode
- NameNode接收到请求之后,对请求进行验证,例如这个请求中的文件是否存在,再例如权限验证
- 如果验证通过,NameNode确定文件的大小以及分块的数量,确定对应的节点(会去找磁盘空间相对空闲的节点来使用),将节点地址放入队列中返回
- 客户端收到地址以后,从队列中依次取出节点地址,然后数据块依次放入对应的节点地址上
- 客户端在写完之后就会向NameNode发送写完数据的信号,NameNode会给客户端一个关闭文件的信号
- DataNode之间将会通过管道进行自动备份,保证复本数量
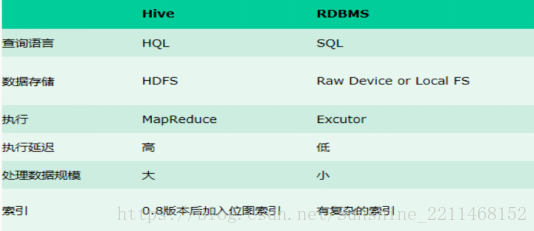
10、hive与mysql(传统数据库)的区别?
- 查询语言不同:hive是hql语言,mysql是sql语言
- 数据存储位置不同:hive是把数据存储在hdfs上,mysql数据是存储在自己的系统中
- 数据格式:hive数据格式用户可以自定义,mysql有自己的系统定义格式
- 数据更新:hive不支持数据更新,只可以读,不可以写,而sql支持数据更新
- 索引:hive没有索引,因此查询数据的时候是通过mapreduce很暴力的把数据都查询一遍,也造成了hive查询数据速度很慢的原因,而mysql有索引;
- 延迟性:hive延迟性高,原因就是上边一点所说的,而mysql延迟性低;
- 数据规模:hive存储的数据量超级大,而mysql只是存储一些少量的业务数据;
- 底层执行原理:hive底层是用的mapreduce,而mysql是excutor执行器;

发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/134613.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
