大家好,又见面了,我是你们的朋友全栈君。
背景:
RCNN使用CNN作为特征提取器,首次使得目标检测跨入深度学习的阶段。但是在RCNN中,因为全连接层的神经元个数是固定的(权重矩阵的维数是固定的),所以采取对于每一个区域候选都需要首先将图片放缩到固定尺寸(227×227),然后为每个区域候选提取CNN特征的方案。这里存在两个瓶颈,第一重复为每个region proposal提取特征是及其费时的,Selective Search对于每幅图片产生2k左右个region proposal,也就是意味着一幅图片需要经过2k次完整的CNN计算得到最终的结果。第二对于所有的region proposal放缩到固定尺寸会导致我们不期望看到的几何形变,而且由于速度瓶颈的存在,不可能采用多尺度或者是大量的数据增强去训练模型,这就导致它的性能必然较差。
改进:
对于背景所描述的问题,既然只有全连接层需要固定的输入,那么只需在全连接层前加入一个网络层,然他对任意的输入产生固定的输出就行了。SPPnet在这个想法上继续加入SPM的思路,SPM主要的思路就是对于一幅图像分成若干尺度的一些组块,比如一幅图像分成1份,4份,8份等。然后对于每一块提取特征然后融合在一起,这样就可以兼容多个尺度的特征了。SPPnet首次将这种思想应用在CNN中,对于卷积层特征我们首先给它分成不同的尺寸,然后每个尺寸提取一个固定维度的特征,最后拼接这些特征就是一个固定维度的输入了。
模块设计:
金字塔池化层:(用一个空间金字塔池化层替换掉了最后一个池化层)
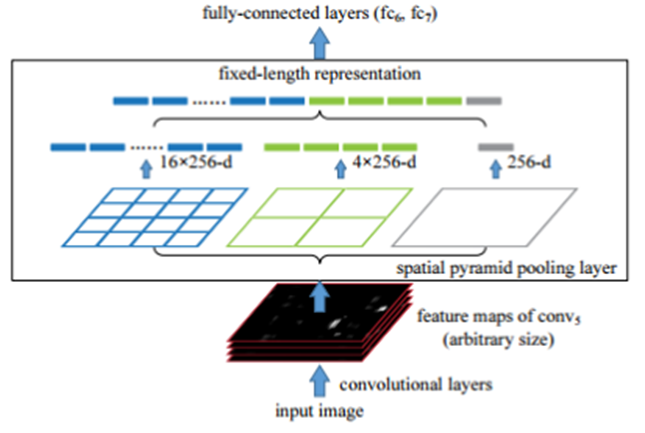

黑色图片代表卷积之后的特征图,接着我们以不同大小的块来提取特征,分别是4×4,2×2,1×1,将这三张网格放到下面这张特征图上,就可以得到16+4+1=21种不同的块(Spatial bins),我们从这21个块中,每个块提取出一个特征,这样刚好就是我们要提取的21维特征向量。这种以不同的大小格子的组合方式来池化的过程就是空间金字塔池化(SPP)。比如,要进行空间金字塔最大池化,其实就是从这21个图片块中,分别计算每个块的最大值,从而得到一个输出单元,最终得到一个21维特征的输出,若前一层卷积层使用k个卷积核,则最后的输出为21*k维的特征向量,这个固定维度的向量就是全连接层的输入。
训练阶段:
理论上讲训练时网络的输入可以是任意尺寸的图片,但是使用GPU时最好是固定尺寸的图片,所以想出来能够在保持金字塔池化层奏效的同时又能够充分利用GPU的训练方法。
单尺度训练:
例:训练时输入统一是224×224的图片,在经过conv5的卷积后是一个13×13(a×a)的特征图,我们希望把它分别池化成3×3,2×2,1×1(n×n)的bins,我们要通过类似于滑动窗口的池化操作来实现,因此我们需要定义这个滑动窗口的尺寸和步长,具体定义为:
windows_size=[a/n] 向上取整 , stride_size=[a/n]向下取整。
多尺寸训练:
带有SPP的网络可以应用于任意尺寸,为了解决不同图像尺寸的训练问题,我们考虑一些预设好的尺寸。现在考虑这两个尺寸:180×180,224×224。我们使用缩放而不是裁剪,将前述的224的区域图像变成180大小。这样,不同尺度的区域仅仅是分辨率上的不同,而不是内容和布局上的不同。对于接受180输入的网络,我们实现另一个固定尺寸的网络。本例中,conv5输出的特征图尺寸是axa=10×10。我们仍然使用win = 上取整[a/n],str = 下取整[a/n],实现每个金字塔池化层。这个180网络的空间金字塔层的输出的大小就和224网络的一样了。
这样,这个180网络就和224网络拥有一样的参数了。换句话说,训练过程中,我们通过使用共享参数的两个固定尺寸的网络实现了不同输入尺寸的SPP-net。为了降低从一个网络(比如224)向另一个网络(比如180)切换的开销,我们在每个网络上训练一个完整的epoch,然后在下一个完成的epoch再切换到另一个网络(权重保留)。最后发现多尺寸训练的收敛速度和单尺寸差不多。
多尺寸训练的主要目的是在保证已经充分利用现在被较好优化的固定尺寸网络实现的同时,模拟不同的输入尺寸。除了上述两个尺度的实现,我们也在每个epoch中测试了不同的sxs输入,s是从180到224之间均匀选取的。后面将在实验部分报告这些测试的结果。
注意,上面的单尺寸或多尺寸解析度只用于训练。在测试阶段,是直接对各种尺寸的图像应用SPP-net的。
测试阶段:
1.首先通过选择性搜索(SS),对待检测的图片进行搜索出2000个候选窗口。
2.把整张待检测的图片,输入CNN中,进行一次性特征提取,得到feature maps,然后在feature maps中找到各个候选框的区域,再对各个候选框采用金字塔空间池化,提取出固定长度的特征向量。(意思是需要将用SS生成的proposals从原图映射到特征图)
3.采用SVM算法进行特征向量分类识别。
优点:
1.最后能够形成拥有多个尺度特征的特征向量
2.它的输入是可以是不同尺寸的图片,并且不需要再用形变将proposals变为固定的尺寸了
缺点:
1.仍然用的是SS的方法提取proposals
2.仍然用的是SVM分类器,训练时极占内存
准确率:
在VOC2007上MAP能达到60.9%
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/134599.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
