大家好,又见面了,我是你们的朋友全栈君。
发现一篇写的很好的关于学习率的文章
本文转载自卢明冬的博客-梯度下降学习率的设定策略
1.学习率的重要性
1)学习率设置太小,需要花费过多的时间来收敛
2)学习率设置较大,在最小值附近震荡却无法收敛到最小值
3)进入局部极值点就收敛,没有真正找到的最优解
4)停在鞍点处,不能够在另一维度继续下降
梯度下降算法有两个重要的控制因子:一个是步长,由学习率控制;一个是方向,由梯度指定。
2.学习率的设定类型
1)固定学习率
每次迭代每个参数都使用同样的学习率。找到一个比较好的固定学习率非常关键,否则会导致收敛太慢或者不收敛。
2)不同的参数使用不同的学习率
如果数据是稀疏的且特征分布不均,似乎我们更应该给予较少出现的特征一个大的更新。这时可能需要对不同特征对应的参数设定不同的学习率。深度学习的梯度下降算法中Adagrad 和Adam方法都针对每个参数设置了相应的学习率,这部分内容详见《梯度下降算法总结》,本篇不作讨论。
3)动态调整学习率
动态调整就是我们根据应用场景,在不同的优化阶段能够动态改变学习率,以得到更好的结果。动态调整学习率是本篇的重点内容,为了解决梯度学习在一些复杂问题时出现的挑战,数据科学家们在动态调整学习率的策略上做了很多研究和尝试。
4)自适应学习率
自适应学习率从某种程度上讲也算是动态调整学习率的范畴,不过更偏向于通过某种算法来根据实时情况计算出最优学习率,而不是人为固定一个简单策略让梯度下降按部就班地实行。
3.学习率的设定策略
3.1 固定学习率
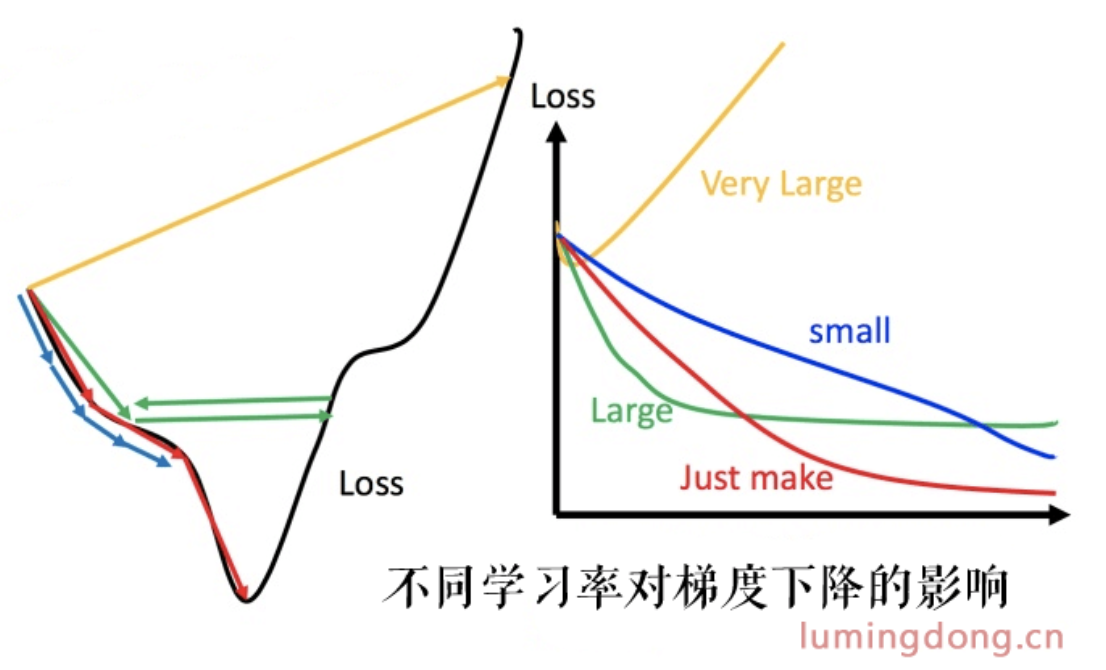
固定学习率适用于那些目标函数是凸函数的模型,通常为了保证收敛会选一个稍微小的数值,如0.01、0.001。固定学习率的选择对梯度下降影响非常大,下图展示了不同学习率对梯度下降的影响。

3.2学习率衰减
一般情况下,初始参数所得目标值与要求的最小值距离比较远,随着迭代次数增加,会越来越靠近最小值。学习率衰减的基本思想是学习率随着训练的进行逐渐衰减,即在开始的时候使用较大的学习率,加快靠近最小值的速度,在后来些时候用较小的学习率,提高稳定性,避免因学习率太大跳过最小值,保证能够收敛到最小值。
1)learning rate在每迭代stepsize次后减少gamma倍
2)learning rate呈多项式曲线下降
L R ( t ) = b a s e l r ∗ ( t T ) p o w e r LR(t) = baselr * (\frac{t}{T})^{power} LR(t)=baselr∗(Tt)power
3)learning rate随迭代次数增加而下降。
L R ( t ) = b a s e l r ∗ ( 1 + g a m m a ∗ i t e r ) p o w e r LR(t) = baselr * (1+gamma*iter)^{power} LR(t)=baselr∗(1+gamma∗iter)power
3.3找到合适的学习率
Leslie N. Smith在一篇《Cyclical Learning Rates for Training Neural Networks》论文中提出一个非常简单的寻找最佳学习率的方法。这种方法可以用来确定最优的初始学习率,也可以界定适合的学习率的取值范围。
在这种方法中,我们尝试使用较低学习率来训练神经网络,但是在每个批次中以指数形式增加(或线性增加)。
目前,该方法在 Fast.ai 包中已经作为一个函数可直接进行使用。Fast.ai 包是由 Jeremy Howard 开发的一种高级 pytorch 包(就像 Keras 之于 Tensorflow)。
#run on learn object where learning rate is increased exponentially
learn.lr_find()
#plot graph of learning rate against iterations
learn.sched.plot_lr()
每次迭代后学习率以指数形式增长:
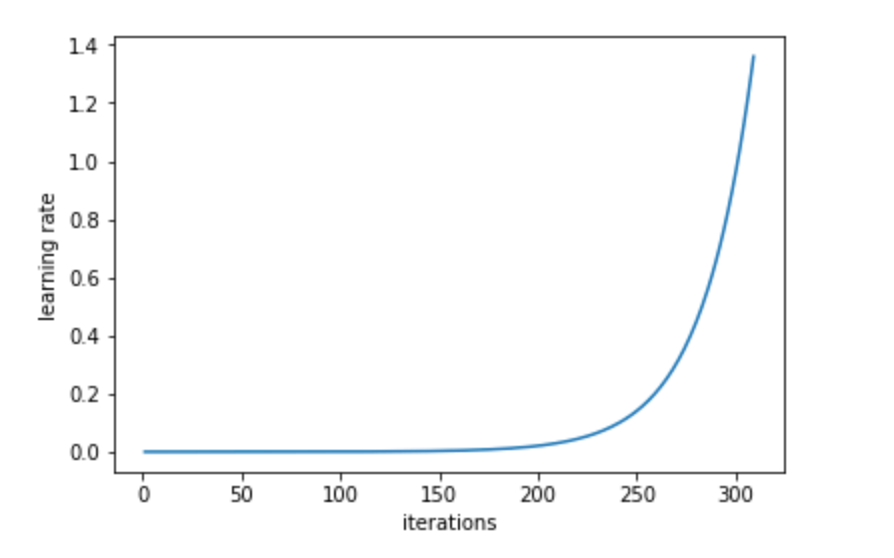
同时,记录每个学习率对应的Loss值,然后画出学习率和Loss值的关系图:
learn.sched.plot()

通过找出学习率最高且Loss值仍在下降的值来确定最佳学习率。在上述情况中,该值将为0.01。
3.4基于Armijo准则的线性回溯搜索算法
既然是计算学习率,我们就需要转换视角,将学习率?看作是未知量,因当前点??、当前搜索方向??都是已知的,故有下面的关于?的函数:
h ( α ) = f ( x k + α ∗ d k ) h(\alpha)=f(x_k+\alpha*d_k) h(α)=f(xk+α∗dk)
梯度下降寻找f(x)最小值,那么在??和??给定的前提下,即寻找函数?(??+???)的最小值,可以证明存在?使得h(x)的导数为0,则?就是要寻找的学习率。
1)二分线性搜索
二分线性搜索是最简单的处理方式,不断将区间[α1,α2]分成两半,选择端点异号的一侧,直到区间足够小或者找到当前最优学习率。
2)回溯线性搜索
基于Armijo准则计算搜素方向上的最大步长,其基本思想是沿着搜索方向移动一个较大的步长估计值,然后以迭代形式不断缩减步长,直到该步长使得函数值?(??+α??)相对与当前函数值?(??)的减小程度大于预设的期望值(即满足Armijo准则)为止。
(1)二分线性搜索的目标是求得满足 ℎ′(?)≈0 的最优步长近似值,而回溯线性搜索放松了对步长的约束,只要步长能使函数值有足够大的变化即可。
(2)二分线性搜索可以减少下降次数,但在计算最优步长上花费了不少代价;回溯线性搜索找到一个差不多的步长即可。
3)二次插值法
二次插值法是回溯线性搜索的继续优化,利用了多项式插值(Interpolation) 方法。多项式插值的思想是通过多项式插值法拟合简单函数,然后根据该简单函数估计原函数的极值点,这里我们使用二次函数来拟合。
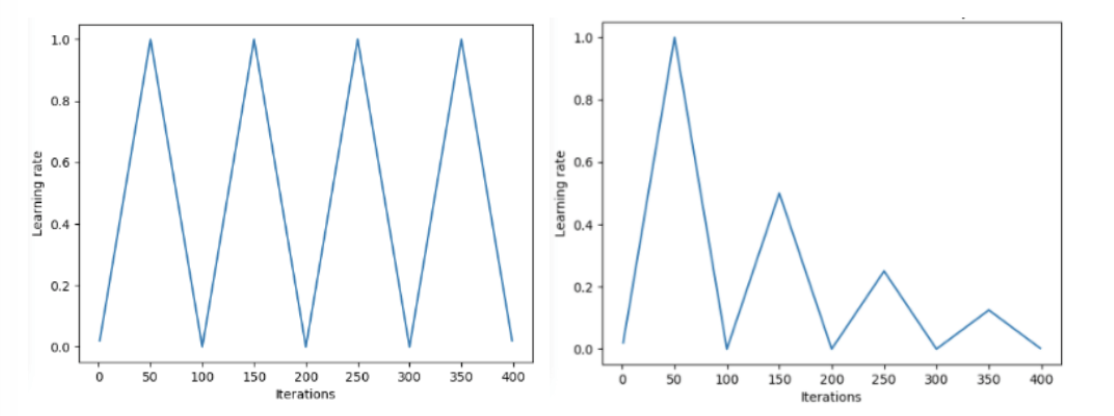
3.5.循环学习率
使用较快的学习率也有助于我们在训练中更早地跳过一些局部极小值。
人们也把早停和学习率衰减结合起来,在迭代 10 次后损失函数没有改善的情况下学习率开始衰减,最终在学习率低于某个确定的阈值时停止。
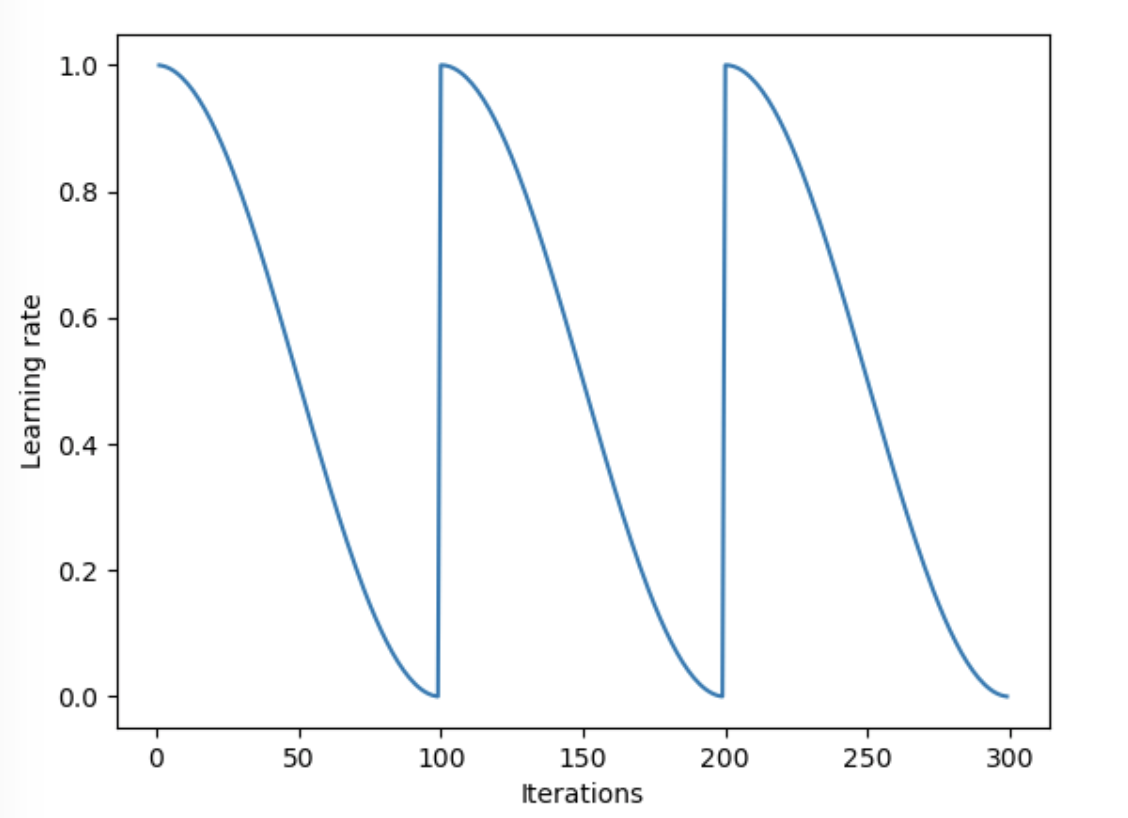
近年来,循环学习率变得流行起来,在循环学习率中,学习率是缓慢增加的,然后缓慢减小,以一种循环的形式持续着。
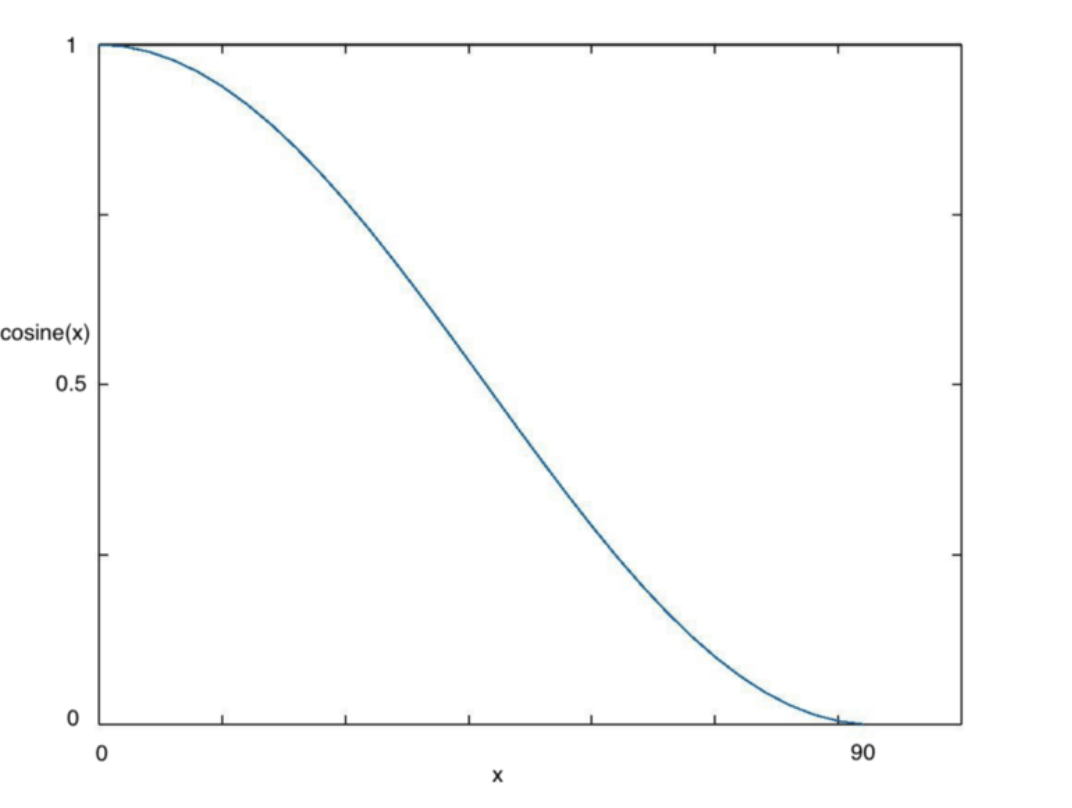
3.6余弦退火
余弦退火可以当做是学习率衰减的一种方式,早些时候都是使用指数衰减或者线性衰减,现在余弦衰减也被普遍使用[2]。
在采用小批量随机梯度下降(MBGD/SGD)算法时,神经网络应该越来越接近Loss值的全局最小值。当它逐渐接近这个最小值时,学习率应该变得更小来使得模型不会超调且尽可能接近这一点。
从下图可以看出,随着x的增加,余弦值首先缓慢下降,然后加速下降,再次缓慢下降。这种下降模式能和学习率配合,以一种十分有效的计算方式来产生很好的效果。
3.7热重启随机梯度下降(SGDR)
在训练时,梯度下降算法可能陷入局部最小值,而不是全局最小值。下图展示了陷入局部最小值的梯度下降算法。
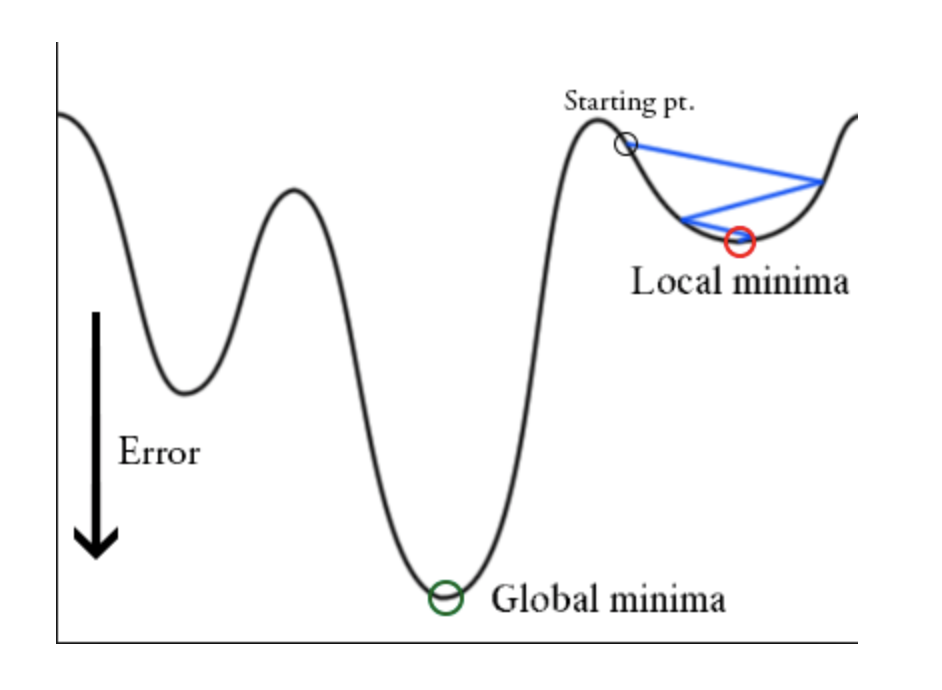
梯度下降算法可以通过突然提高学习率,来“跳出”局部最小值并找到通向全局最小值的路径。Loshchilov和Hutter在《SGDR: Stochastic Gradient Descent with Warm Restarts》论文中提出了热重启随机梯度下降(Stochastic Gradient Descent with Warm Restarts, SGDR)方法,这种方法将余弦退火与热重启相结合,使用余弦函数作为周期函数,并在每个周期最大值时重新开始学习速率。“热重启”是因为学习率重新开始时并不是从头开始的,而是由模型在最后一步收敛的参数决定的。
用Fast.ai库可以快速导入SGDR算法。当调用learn.fit(learning_rate, epochs)函数时,学习率在每个周期开始时重置为参数输入时的初始值,然后像上面余弦退火部分描述的那样,逐渐减小。
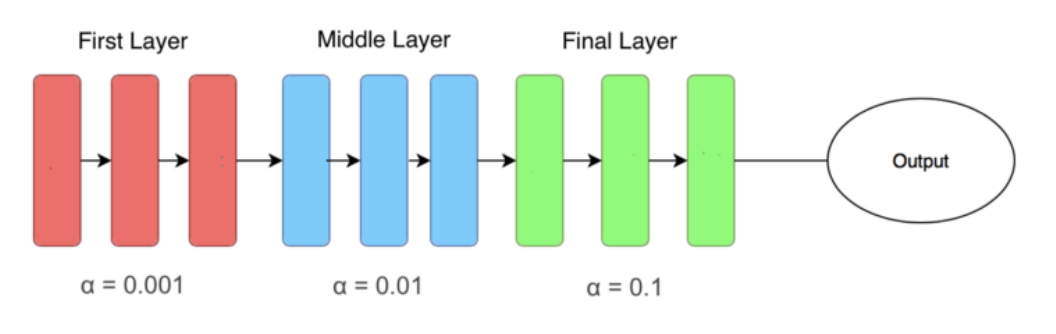
3.8不同网络层使用不同学习率
一般情况下,在训练时通过优化网络层会比提高网络深度要更重要,在网络中使用有差别的学习率(Differential Learning rates),可以很好的提高模型性能。
3.9快照集成和随机加权平均
最后将要提到的策略可以说是多个优化方法综合应用的策略,可能已经超出了“学习率的设定”主题的范围了,不过,我觉得下面的方法是最近一段时间研究出来的一些非常好的优化方法,因此也包括了进来,权当做是学习率优化的综合应用了。
本小节主要涉及三个优化策略:快照集成(Snapshot Ensembling)、快速几何集成(Fast Geometric Ensembling,FGE)、随机加权平均(Stochastic Weight Averaging,SWA)。
在经典机器学习中,集成学习(Ensemble learning)是非常重要的思想,很多情况下都能带来非常好的性能,因此几乎是机器学习比赛中必用的“神兵利器”。
集成学习算法本身不算一种单独的机器学习算法,而是通过构建并结合多个机器学习器来完成学习任务。可以说是“集百家之所长”,完美的诠释了“三个臭皮匠赛过诸葛亮”。集成学习在机器学习算法中拥有较高的准确率,不足之处就是模型的训练过程可能比较复杂,效率不是很高。
强力的集成学习算法主要有2种:基于Bagging的算法和基于Boosting的算法,基于Bagging的代表算法有随机森林,而基于Boosting的代表算法则有Adaboost、GBDT、XGBOOST等,这部分内容我们后面会单独讲到。
集成学习的思路就是组合若干不同的模型,让它们基于相同的输入做出预测,接着通过某种平均化方法决定集成模型的最终预测。这个决定过程可能是通过简单的投票或取均值,也可能是通过另一个模型,该模型能够基于集成学习中众多模型的预测结果,学习并预测出更加准确的最终结果。岭回归是一种可以组合若干个不同预测的结果的方法,Kaggle 上卫星数据识别热带雨林竞赛的冠军就使用过这一方法。
集成学习的思想同样适用于深度学习,集成应用于深度学习时,组合若干网络的预测以得到一个最终的预测。通常,使用多个不同架构的神经网络得到的性能会更好,因为不同架构的网络一般会在不同的训练样本上犯错,因而集成学习带来的收益会更大。
当然,你也可以集成同一架构的模型,也许效果会出乎意料的好。就好比本小节将要提到的快照集成方法,在训练同一个网络的过程中保存了不同的权值快照,然后在训练之后创建了同一架构、不同权值的集成网络。这么做可以提升测试的表现,同时也超省事,因为你只需要训练一个模型、训练一次就好,只要记得随时保存权值就行。
快照集成应用了我们刚才提到的热重启随机梯度下降(Stochastic Gradient Descent with Warm Restarts, SGDR),这种循环学习率几乎为快照集成量身打造,利用热重启随机梯度下降法的特点,每次收敛到局部极值点的时候就可以缓存一个权重快照,缓存那么几个就可以做集成学习了。
无论是经典机器学习中的集成学习,还是深度学习里面的集成学习,抑或是改良过的快照集成方法,都是模型空间内的集成,它们均是组合若干模型,接着使用这些模型的预测以得到最终的预测结果。而一些数据科学家还提出了一种全新的权值空间内的集成,这就是随机加权平均法,该方法通过组合同一网络在训练的不同阶段的权值得到一个集成,接着使用组合后的权值做出预测。这种方法有两个好处:
- 组合权重后,我们最终仍然得到一个模型,这有利于加速预测。
- 事实证明,这种方法胜过当前最先进的快照集成。
在了解其实现原理之前,我们首先需要理解损失平面(loss surface)和泛化解(generalizable solution)。
权值空间的解
第一个不得不提到的是,经过训练的网络是高维权值空间中的一个点。对给定的架构而言,每个不同的网络权值组合都代表了一个不同的模型。任何给定架构都有无穷的权重组合,因而有无穷多的解。训练神经网络的目标是找到一个特定的解(权值空间中的点),使得训练数据集和测试数据集上的损失函数的值都比较低。
在训练期间,训练算法通过改变权值来改变网络并在权值空间中漫游。梯度下降算法在一个损失平面上漫游,该平面的海拔为损失函数的值。
窄极值和宽极值
坦白的讲,可视化并理解高维权值空间的几何特性非常困难,但我们又不得不去了解它。因为随机梯度下降的本质是,在训练时穿过这一高维空间中的损失平面,试图找到一个良好的解——损失平面上的一个损失值较低的“点”。不过后来我们发现,这一平面有很多局部极值。但这些局部极值并不都有一样好的性质。
一般极值点会有宽的极值和窄的极值,如下图所示:
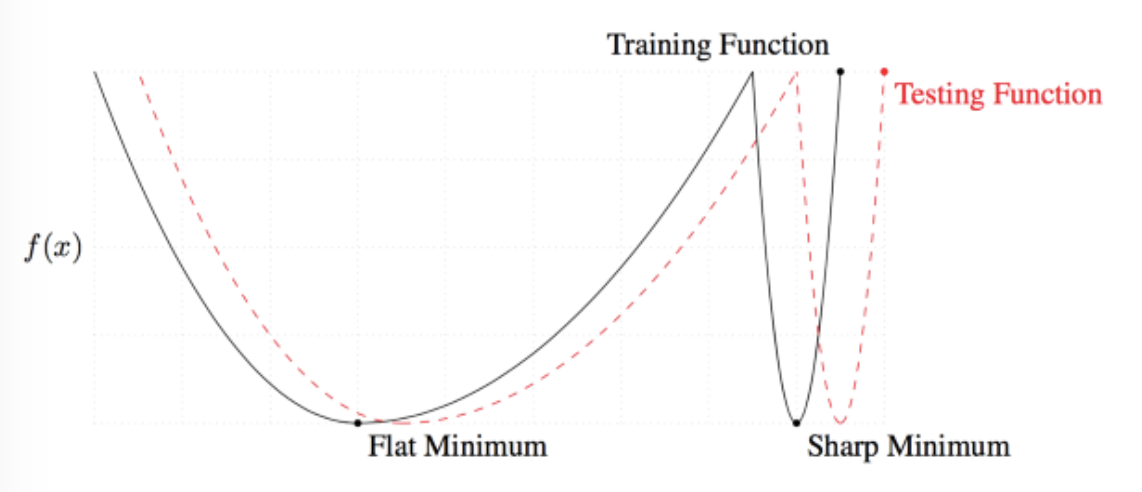
数据科学家研究试验后发现:宽的局部极小值在训练和测试过程中产生类似的损失;但对于窄的局部极小值而言,训练和测试中产生的损失就会有很大区别。这意味着,宽的极值比窄的极值有更好的泛化性。
平坦度可以用来衡量一个解的优劣。其中的原理是,训练数据集和测试数据集会产生相似但不尽相同的损失平面。你可以将其想象为测试平面相对训练平面而言平移了一点。对窄的解来说,一个在测试的时候损失较低的点可能因为这一平移产生变为损失较高的点。这意味着窄的(尖锐的)解的泛化性不好——训练损失低,测试损失高。另一方面,对于宽的(平坦的)解而言,这一平移造成的训练损失和测试损失间的差异较小。
之所以提到窄极值和宽极值,是因为随机加权平均(SWA)就能带来讨人喜欢的、宽的(平坦的)解。
快照集成(Snapshot Ensembling)
快照集成应用了应用了热重启随机梯度下降(SGDR),最初,SGD会在权值空间中跳出一大步。接着,由于余弦退火,学习率会逐渐降低,SGD逐步收敛到局部极小值,缓存权重作为一个模型的“快照”,把它加入集成模型。然后将学习率恢复到更高的值,这种更高的学习率将算法从局部极小值推到损失面中的随机点,然后使算法再次收敛到另一个局部极小值。重复几次,最后,他们对所有缓存权重集的预测进行平均,以产生最终预测。
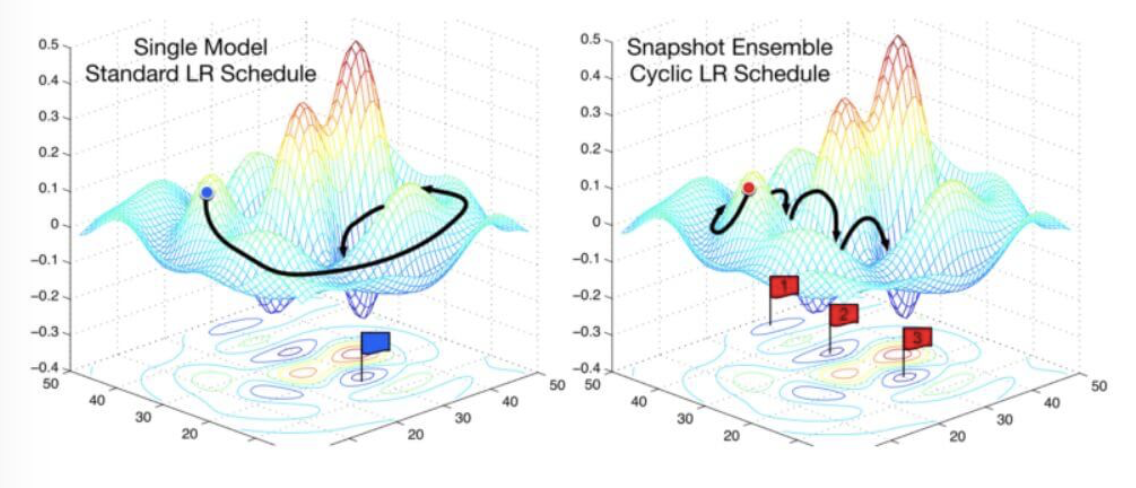
上图对比了使用固定学习率的单个模型与使用循环学习率的快照集成的收敛过程,快照集成是在每次学习率周期末尾保存模型,然后在预测时使用。
快照集成的周期长度为 20 到 40 个 epoch。较长的学习率周期是为了在权值空间中找到足够具有差异化的模型,以发挥集成的优势。如果模型太相似,那么集成模型中不同网络的预测将会过于接近,以至于集成并不会带来多大益处了。
快照集成表现优异,提升了模型的表现,但快速几何集成效果更好。
快速几何集成
《Loss Surfaces, Mode Connectivity, and Fast Ensembling of DNNs》中提出的快速几何集成 FGE 和快照集成非常像,但是也有一些独特的特点。它们的不同主要有两点。第一,快速几何集成使用线性分段周期学习率规划,而不是余弦变化。第二,FGE 的周期长度要短得多——2 到 4 个 epoch。乍一看大家肯定直觉上觉得这么短的周期是不对的,因为每个周期结束的时候的得到的模型互相之间离得太近了,这样得到的集成模型没有什么优势。然而作者们发现,在足够不同的模型之间,存在着损失较低的连通路径。我们有机会沿着这些路径用较小的步长行进,同时这些模型也能够有足够大的差异,足够发挥集成的优势。因此,相比快照集成, FGE 表现更好,搜寻模型的步长更小(这也使其训练更快)。
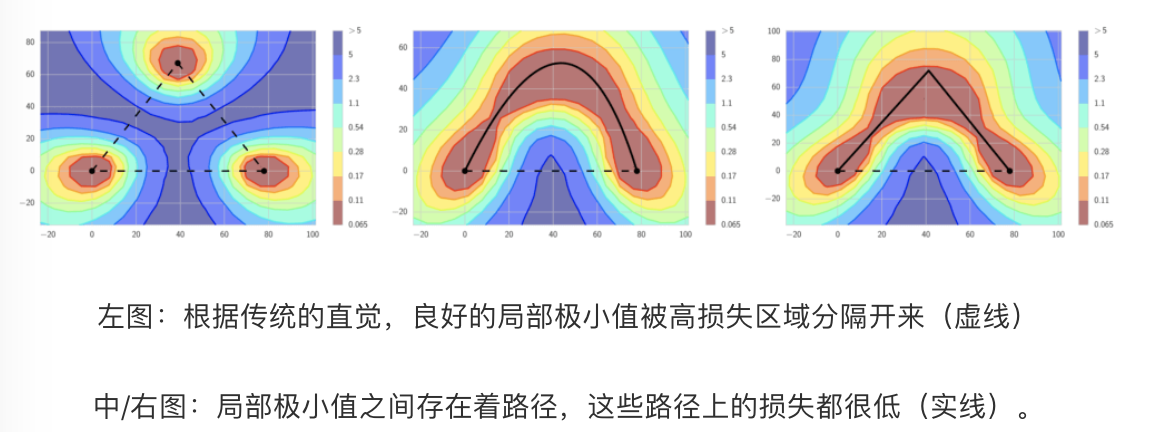
随机加权平均(Stochastic Weight Averaging,SWA)
随机加权平均只需快速几何集成的一小部分算力,就可以接近其表现。SWA 可以用在任意架构和数据集上,都会有不错的表现。根据论文中的实验,SWA 可以得到我之前提到过的更宽的极小值。在经典认知下,SWA 不算集成,因为在训练的最终阶段你只得到一个模型,但它的表现超过了快照集成,接近 FGE。
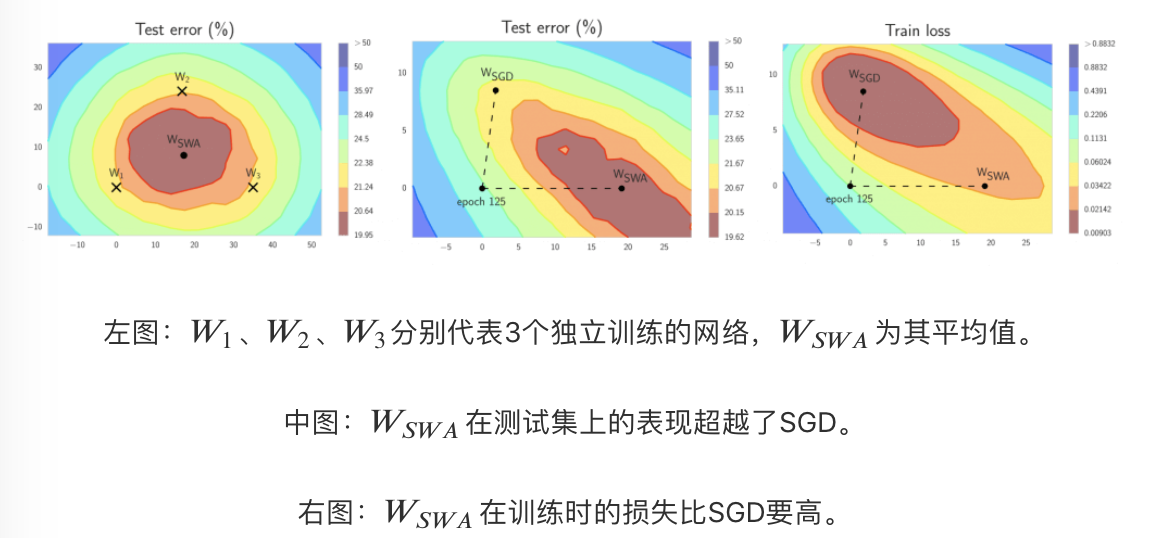
结合????在测试集上优于 SGD 的表现,这意味着尽管????训练时的损失较高,它的泛化性更好。
SWA 的直觉来自以下由经验得到的观察:每个学习率周期得到的局部极小值倾向于堆积在损失平面的低损失值区域的边缘(上图左侧的图形中,褐色区域误差较低,点?1、?2、?3分别表示3个独立训练的网络,位于褐色区域的边缘)。对这些点取平均值,可能得到一个宽阔的泛化解,其损失更低(上图左侧图形中的????)。
下面是 SWA 的工作原理。它只保存两个模型,而不是许多模型的集成:
- 第一个模型保存模型权值的平均值(????)。在训练结束后,它将是用于预测的最终模型。
- 第二个模型(?)将穿过权值空间,基于周期性学习率规划探索权重空间。
SWA权重更新公式
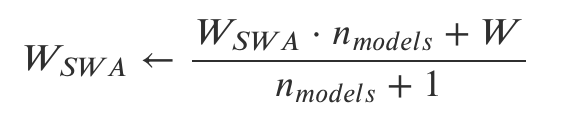
在每个学习率周期的末尾,第二个模型的当前权重将用来更新第一个模型的权重。因此,在训练阶段,只需训练一个模型,并在内存中储存两个模型。预测时只需要平均模型,基于其进行预测将比之前描述的集成快很多,因为在那种集成中,你需要使用多个模型进行预测,最后再进行平均。
4.小结
本文主要介绍了几种梯度下降学习率的设定策略,其中“固定学习率”、“学习率衰减”适用于简单不太复杂的应用场景,“基于Armijo准则的线性回溯搜索算法”可以当做一种自适应学习率调整,不过由于计算复杂且无法有效解决陷入局部极小值点和鞍点处的问题,使用的人并不多。在“找到合适的学习率”一小节中,我们介绍了一种简单有效的方法,可以快速找到一个适合的学习率,同时这种方法也可以界定学习率设定的合理范围,推荐使用。“热重启随机梯度下降”是“循环学习率”和“余弦退火”的结合,可以非常有效的解决梯度下降容易陷入局部极值点和鞍点等问题,它正在成为当前效果最好的、也是最标准的做法,它简单易上手,计算量很轻,可以说事半功倍,尤其在深度学习中表现非常好,推荐使用。最后介绍了“分层学习率”、“快照集成”,“随机加权平均”,是近段时间比较好的研究成果,也是不错的综合优化方法。
梯度下降是机器学习和深度学习中非常重要的优化算法,而学习率是用好梯度下降法的关键。除了一些其他客观的原因,学习率的设定是影响模型性能好坏的非常重要的因素,所以应该给予足够的重视。最后,还记得上面提到过的“梯度下降算法有两个重要的控制因子:一个是步长,由学习率控制;一个是方向,由梯度指定。”吗?我们已经在学习率上有了深入的探索和研究,那在方向上是否还有可以优化的方法?如果搜索方向不是严格的梯度方向是否也可行?这里就涉及使用二阶导数的牛顿法和拟牛顿法了。不过个人觉得它们远不及梯度下降重要,如果有时间再更新这方面的内容吧。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/134593.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
