大家好,又见面了,我是你们的朋友全栈君。
3.1 selenium
selenium:
Selenium 是一个自动化测试工具,利用它可以 驱动浏览器 执行特定的动作,如点击、下拉等操作(模拟浏览器操作)
同时还可以获取浏览器当前呈现的页面的源代码,做到可见即可爬
Selenium支持非常多的浏览器,如 Chrome、Firefox、PhantomJS等
浏览器对象的初始化 并将其赋值为 browser 对象。接下来,我们要做的就是调用 browser 对象,让其执行各个动作以模拟浏览器操作
eg:要使用google浏览器
——browser = webdriver.Chrome()
访问页面:get方法
eg:
from selenium import webdriver
#声明
browser = webdriver.Chrome()
#请求网页
browser.get('https://www.taobao.com')
#打印源码
print(browser.page_source)
#关闭网页
browser.close()
#效果:弹出Chrome,自动访问tb,打印源码,关闭页面
查找节点(比如 找到账号输入框):
1:单个节点
返回:WebElement 类型
find_element_by_id
find_element_by_name
find_element_by_xpath
find_element_by_link_text
find_element_by_partial_link_text
find_element_by_tag_name
find_element_by_class_name
find_element_by_css_selector
变式:
find_element(By.a,b)——参数a输入属性,参数b输入值
find_element_by_id(id)
==
find_element(By.ID, id)
2:多个节点(淘宝左边所有的导航栏条目):
如果我们用 find_element()方法,只能获取匹配的第一个节点
如果用 find_elements()方法,返回:列表类型,包含所有符合要求的节点,列表中的每个节点是 WebElement 类型
find_elements_by_id
find_elements_by_name
find_elements_by_xpath
find_elements_by_link_text
find_elements_by_partial_link_text
find_elements_by_tag_name
find_elements_by_class_name
find_elements_by_css_selector
节点交互(模拟人的操作—有特定对象):
输入文字—— send_keys()方法
清空文字—— clear()方法
点击按钮—— click()方法
动作链(模拟人的操作—无特定对象):
没有特定的执行对象,比如鼠标拖曳、键盘按键等
用另一种方式来执行——动作链
http://selenium-python.readthedocs.io/api.html#module-selenium.webdriver.common.action_chains
获取节点信息:
Selenium 提供了选择节点的方法,返回的是 WebElement 类型
它也有相关的方法和属性来直接提取节点信息,如属性、文本等。
这样的话,我们就可以不用通过解析源代码来提取信息了,方便
属性值:
get_attribute() 方法来获取节点的属性,但是其前提是先选中这个节点
通过get_attribute()方法,然后传入想要获取的属性名,就可以得到它的值
文本:
每个 WebElement 节点都有 text 属性,直接调用这个属性就可以得到节点内部的文本信息
——相当于 Beautiful Soup 的 get_text()方法
WebElement 节点还有一些其他属性
比如
id 属性可以获取节点 id
location 属性可以获取该节点在页面中的相对位置
tag_ name 属性可以获取标签名称
size 属性可以获取节点的大小,也就是宽高
繁琐一点的话,就用page_source 属性获取网页的源代码,接着使用解析库
切换Frame(子页面):
switch_to.frame()方法
Selenium在一个 页面中,完成 对这个页面 的操作。在父页面无法对子Frame操作
延时等待:
确保节点已经加载出来——在 Selenium 中,get()方法会在网页框架加载结束后
结束执行,此时可能并不是浏览器完全加载完成的页面
1:隐式
换句话说,当查找节点 而节点并没有立即出现的时候,隐式等待 将等待一段时间再查找DOM,默认的时间是0
implicitly_ wait()
2:显式
隐式等待的效果并没有那么好,因为我们只规定了一个 固定时间,而页面的加载时间会受到网络条件的影响
显式——它指定一个等待条件(要查找的节点),然后指定一个最长等待时间。
如果在规定时间内满足 等待条件(加载出来了这个节点),就返回要查找的节点;
如果到了规定时间还没有 等待条件(没有加载出该节点),则抛出超时异常
eg:
from selenium.webdriver.support import expected_conditions as EC
wait = WebDriverWait(browser, 10)
input = wait.until(EC.presence_of_element_located((By.ID, 'q')))
#首先引入WebDriverWait这个对象,指定最长等待时间,然后调用它的until()方法,传入要等待条件expected_conditions。比如,这里传入了presence_of_element_located这个条件,代表节点出现的意思,其参数是节点的定位元组,也就是ID为q的节点搜索框
更多等待条件的参数及用法,参考官方文档:http://selenium-python.readthedocs.io/api.html#module-selenium.webdriver.support.expected_conditions
前进后退:
back()方法后退,
forward()方法前进
eg:
import time
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.baidu.com/')
browser.get('https://www.taobao.com/')
browser.get('https://www.python.org/')
browser.back()
time.sleep(1)
browser.forward()
browser.close()
Cookies:
对 Cookies 进行操作
例如获取、添加、删除 Cookies 等
get_cookies() ——获取
add_cookie()——添加
delete_all_cookies() ——删除所有的 Cookies
选项卡:
execute_ script()方法
switch_ to_ window()——切换选项卡
异常处理:
try except 语句——捕获异常,放置程序遇到异常而中断
实战:selenium模拟登陆163(126)邮箱
# 登陆,打开网页页面,加载成功后,找到账号密码框,输入账号密码,点击登陆
# 对应
#访问页面。查找输入框等节点。输入cookes等信息,模拟点击(交互)
from selenium import webdriver
import time
url = 'https://www.126.com/'
def open_page(url):
browser = webdriver.Chrome()
browser.get('https://www.126.com/') #打开网页
time.sleep(2)
#以上代码OK
browser.switch_to.frame(0)#关键
#找到账号框,密码框,登陆按钮。然后输入信息
card = browser.find_element_by_name('email')#账号框
card.send_keys('dengzhanh')
password = browser.find_element_by_name('password') #密码框
password.send_keys('*******')
login = browser.find_element_by_id('dologin')#登陆按钮
login.click()
def main():
open_page(url)
if __name__=='__main__':
main()
问题:
1—browser.switch_to.frame(0) 是在同一界面选择一个子界面么?()内的参数怎么填?
2—账号密码框 在源码中,如何快捷地找到其 属性?
3.2 IP ——参考:网络爬虫开发实战
IP(代理):
网站为了防止被爬取,会有反爬机制
服务器会检测某个IP在单位时间内的请求次数,如果超过了这个阈值,就会直接拒绝服务,返回一些错误信息——可以称为封IP
应对IP被封的问题:
修改请求头,模拟浏览器(把你当做是个人)访问
采用代理IP 并轮换
设置访问时间间隔(同样是模拟人,因为人需要暂停一会)
代理:在本机 和 服务器 之间搭桥
本机不直接发送请求,通过桥(代理服务器)发送请求
web代理 通过桥 返回 响应
请求库的代理设置方法
1:requests 的代理设置:只需要构造代理字典,然后通过 proxies
数即可,而不需要重新构建 pener
proxies = {
'http': 'http ://'+ proxy,
'https': 'https://'+ proxy,
如果需要 验证,下面的代码输入两个部分即可
proxy= ‘username:password@代理 ’
使用 SOCKS5 代理(需要安装SOCKS库)
1:
proxies = {
'http':'socks5 ://'+ proxy,
'http': 'socks5: // '+ proxy
}
2:全局设置
import requests
import socks
import socket
socks.set_default_proxy(socks . 50CKS5,’127.0 .0.1 ’, 9742)
socket.socket = socks.socksocket
2:Selenium代理设置:
以Chrome为例
from selenium import webdriver
proxy= 127.0.0.1:9743
chrome_ options = webdriver.ChromeOptions ()
chrome_options.add_argument('…proxy-server=http://'+ proxy)
browser = webdriver.Chro e(chrome_options=chrome_options)
browser.get(’ http://httpbin.org/get ' )
若是 认证代理:
需要在本地创建一个 manifest.json 配置文件 和 background.js 脚本来设置认证代理
运行代码之后本地会生成一个 proxy auth __plugin.zip 文件来保存当前配置
代理池:
不是所有的代理都能用,所以要进行 筛选,提出不可用代理,保留可用代理
∴ 建立代理池
设计代理的基本思路:(代理池的目标)
1:存储模块(存代理)——负责存储抓取下来的代理。首先要保证代理不重复,要标识代理的可用情况,还要动态实时处理每个代理。
所以一种比较高效方便的存储方式就是使用 Redis的Sorted Set,即有序集合
2:获取模块(抓代理)——需要定时在各大代理网站抓取代理。代理可以是免费公开代理也可以是付费代理,代理的形式都是 IP 加端口,此模块尽量从不同来源获取,尽量抓取高匿代理,抓取成功之后将 可用代理 保存到数据库中
3:检测模块(能用否)——需要定时检测数据库中的代理。这里需要设置一个检测链接,最好是爬取哪个网站就检测哪个网站,这样更加有针对性,如果要做一个通用型的代理,那可以设置百度等链
接来检测。
另外,我们需要标识每一个代理的状态,如设置分数标识,100分代表可用,分数越少代表越不可用。——检测一次,如果代理可用,我们可以将分数标识立即设置为100分,也可以在原基础上加1分;如果代理不可用,可以将分数标识减1分,当分数减到一定阈值后,代理就直接从数据库移除。通过这样的标识分数,我们就可以辨别代理的可用情况,选用的时候会更有针对性
4:接口模块(拿出来)——需要用 API 来提供对外服务的接口。其实我们可以直接连接数据库采取对应的数据,但是这样就需要知道数据库的连接信息,并且要配置连接。
而比较安全和方便的方式就是提供一个 Web API 接口,我们通过访问接口即可拿到可用代理。另外,由于可用代理可能有多个,那么我们可以 设置一个 随机返回 某个可用代理 的接口,这样就能保证 每个可用代理都可以取到,实现 负载均衡。
根据以上,设计代理池架构
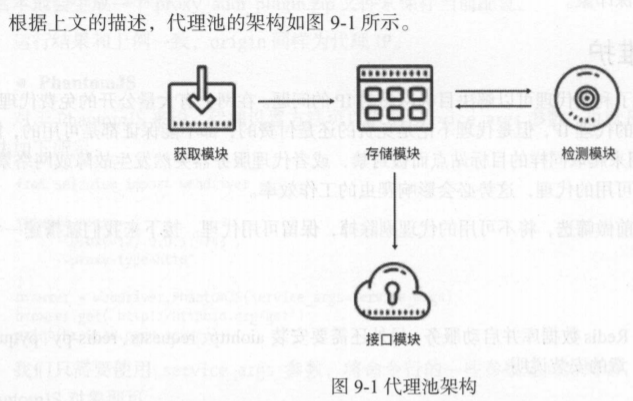

注:
存储模块——使用 Redis 有序集合,用来做代理的 去重 和 状态标识,同时它也是中心模块和基
础模块,将其他模块串联起来
获取模块——定时从代理网站获取代理,将获取的代理传递给存储模块,并保存到数据库
检测模块——定时通过存储模块获取所有代理,并对代理进行检测,根据不同的检测结果对代理
设置不同的标识
接口模块——通过 WebAPI 提供服务接口,接口通过连接数据库并通过Web 形式返回可用的代理
4个模块的实现
1:存储模块
这里我们使用 Redis 的有序集合,集合的每一个元素都是不重复的
对于代理池来说,集合的元素就变成了 个个代理,也就是 IP 加端口的形式,
eg:60.207.237.111 :8888 ,这样的一个代理就是集合的一个元素。
另外,有序集合的每一个元素都有一个分数字段,分数是可以重复的,可以是浮点数类,也可以是整数类型。
该集合会根据每一个元素的分数对集合进行排序,数值小的排在前面,数值大的排在后面,这样就可以实现集合元素的排序了。
对于代理池来说,这个分数可以作为判断一个代理是否可用的标志, 100 为最高分,代表最可用,0为最低分,代表最不可用。
如果要获取可用代理,可以从代理池中随机获取分数最高的代理,注意是随机,这样可以保证每个可用代理都会被调用到
引入分数机制
定义常量,比如:分数(最大最小初始)、Redis的连接信息(地址、端口、密码)、有序集合的键名(获取)
定义类,用于操作Redis的有序集合,其中定义一些方法,用于处理集合中的元素。
获取模块:
定义一个 Crawler 来从各大网站抓取代理
将获取代理的每个方法统一定义为以Crawl 开头,这样扩展的时候只需要添加Crawl 开头的方法即可。
这些方法都定义成了生成器,通过 yield返回代理。程序首先获取网页,然后用解析,解析出 IP加端口的形式的代理 然后返回
然后定义了一个 get_proxies ()方法,将所有以 crawl 开头的方法调用一遍,获取每个方法返回的代理 并 组合成列表形式返回
依次通过 get_proxies方法调用,得到各个方法抓取到的代理,然后再利用 Redi sClien的add方法加入数据库,这样获取模块的工作就完成了
检测模决:
使用异步请求库aiohttp
接口模块:
代理池可以作为一个独立服务运行,我们最好增加一个接口模块,并以 WebAPI的形式暴露可用代理——获取代理只需要请求接口即可
调度模块:
调度模块就是调用以上所定义的 3个模块,将这 个模块通过多进程的形式运行起来
实战:
import requests
from bs4 import BeautifulSoup
from collections import OrderedDict
from threading import Thread
from datetime import datetime
start_time = datetime.now()
def get_xici_proxy(url,headers):
response = requests.get(url, headers=headers).content
res = response.decode('utf-8')
soup = BeautifulSoup(res, 'lxml')
tag_tr_all = soup.find_all('tr')
info_names = tag_tr_all[0].get_text().strip().split('\n')
# global proxy_list
t_list = []
for tag_tr in tag_tr_all[1:]:
tag_td = tag_tr.find_all('td')#
try:
country = tag_td[0].img['alt']
except TypeError:#
country = 'None'
try:
ip_info_list = [td.get_text(strip=True) for td in tag_td[1:]]
ip_info_list.insert(0,country)
ip_info_dict = OrderedDict(zip(info_names,ip_info_list))
t = Thread(target =check_proxy,args=(ip_info_dict,))
t_list.append(t)
except Exception as e:
print("登录错误",e)
for i in range(len(tag_tr_all[1:])):
t_list[i].start()
for i in range(len(tag_tr_all[1:])):
t_list[i].join()
def check_proxy(info):
proxy = {info['类型'].lower():r"{}://{}:{}".format(info['类型'].lower(),info['IP地址'],info['端口']),}
try:
response1 = requests.get(r"http://httpbin.org/get",proxies=proxy,timeout=10)
print(response1.status_code)
if response1.status_code==200:
info['proxy'] = proxy
proxy_list.append(info)
except Exception as e:
pass#
if __name__ == "__main__":
url = r"https://www.xicidaili.com/nn"
headers = {
'User-Agent': "Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50"
}
proxy_list = []
get_xici_proxy(url,headers)
print("有效代理数:",len(proxy_list))
print("第二个代理地址:",proxy_list[1].get('proxy'))
print("第二个代理地址类型:",proxy_list[1].get('类型'))
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/134465.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
