大家好,又见面了,我是你们的朋友全栈君。
作者简介
Darren Shepherd,Rancher Labs联合创始人及首席架构师。在加入Rancher之前,Darren是Citrix的高级首席工程师,他在那里从事CloudStack、OpenStack、Docker的工作,并构建下一代基础设施编排技术。在加入Citrix之前,Darren曾在GoDaddy工作,他设计并领导一个团队实施公有和私有IaaS云。
本文转自Rancher Labs
2020年年初,Rancher开源了海量集群管理项目Fleet,为大量的Kubernetes集群提供集中的GitOps式管理。Fleet最重要的目标是能够管理100万个分布于不同地理位置的集群。当我们设计Fleet架构时,我们希望使用标准的Kubernetes controller架构。这意味着我们可以扩展Kubernetes的数量比之前要多很多。在本文中,我将介绍Fleet的架构、我们用于测试扩展规模的方法和我们的发现。
为什么是100万个集群?
随着K3s用户量爆发式增长(目前Github Star已经超过15,000),边缘Kubernetes也开始迅猛发展。一些企业已经采用了边缘部署模型,其中每个设备都是单节点集群。或者你可能会看到使用3个节点的集群来提供高可用性(HA)。关键点在于我们需要处理的是大量小型集群,而不是一个有很多节点的大型集群。现如今,几乎任何地方的工程师都在使用Linux,他们都希望使用Kubernetes来管理工作负载。虽然大多数K3s的边缘部署少于10,000个节点,但达到100万个节点并非不可能。而Fleet将满足你的规模扩展要求。
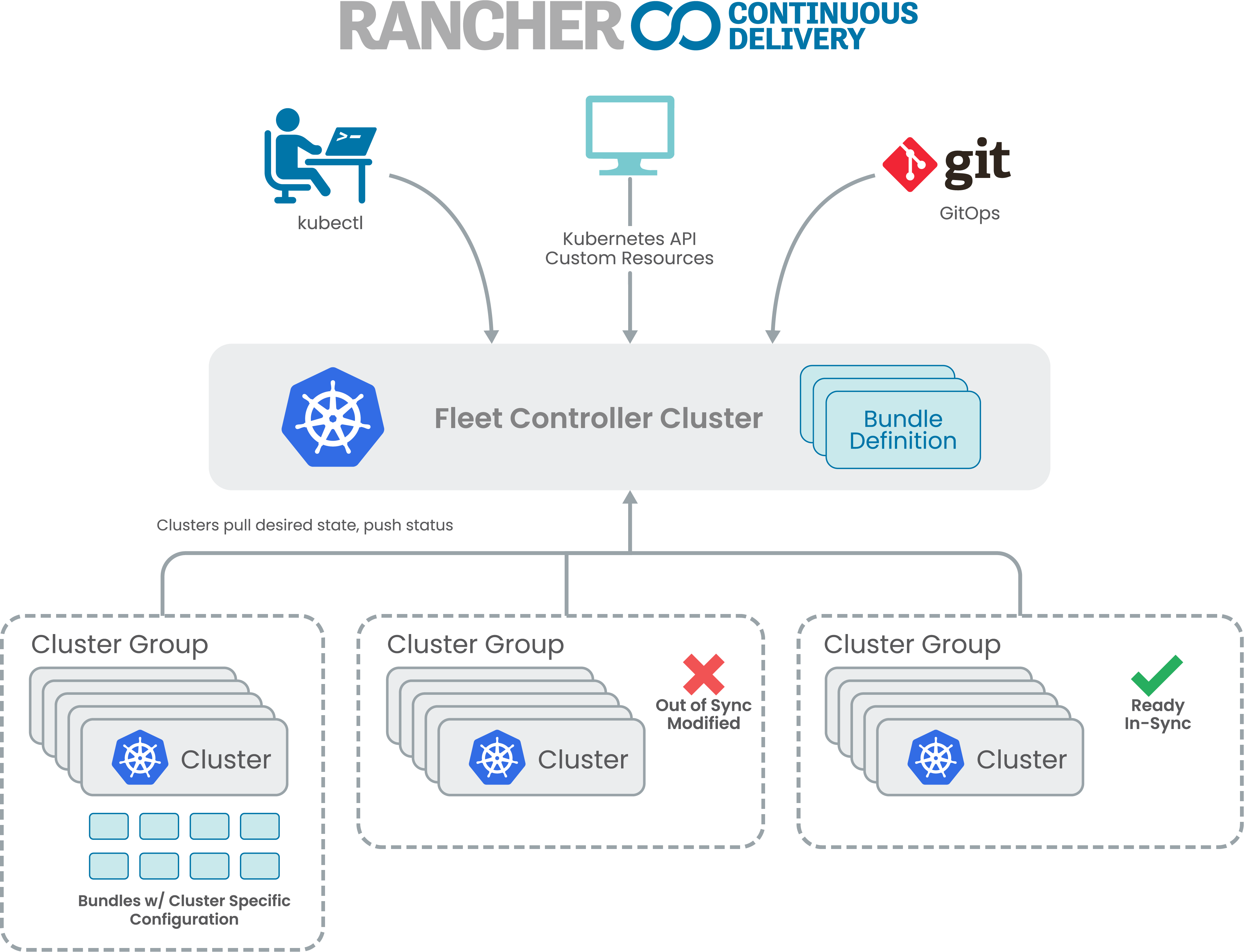
Fleet架构
Fleet架构的关键部分如下:
-
Fleet使用两阶段pull方法
-
Fleet是一组由标准K8S API交互驱动的K8S Controller
-
Fleet agent不需要一直保持连接
-
Fleet agent本身是另一组Kubernetes controller
要从git中进行部署,Fleet Manager首先要复制并存储git中的内容,然后Fleet manager决定需要使用git中的内容更新哪个集群,并创建部署记录供agent读取。当agent可以读取时,agent将check in以读取部署集群,部署新的资源并报告状态。

扩展规模测试方法
我们使用两种方法来模拟100万个集群。首先,我们部署了一组大型VM(m5ad.24xlarge – 384 GiB RAM)。每个VM使用k3d运行10个K3s集群。然后这10个集群每个都运行750个agent,每个agent都代表着一个下游的集群。总的来说,每个VM模拟7500个集群。平均来看,部署一个VM、在Fleet注册所有集群并达到稳定状态大约需要花费40分钟。在两天的时间里,我们以这种方式启动虚拟机,直到达到10万个集群。在最初的10万个集群中,我们发现了大部分的扩展问题。在解决了这些问题之后,扩展变得相当可预测。以这一速度,模拟剩下的90万个集群将会花费很长的时间以及相当可观的资金。
然后,我们采用第二种方法:运行一个模拟器,它可以执行100万个集群会进行的所有API调用,而不需要下游的Kubernetes集群或部署Kubernetes资源。取而代之的是,模拟器进行API调用以注册新集群、发现新部署并报告它们的成功状态。使用这种方法,我们在一天内实现了从0到100万个模拟集群。
Fleet manager是一个运行在Kubernetes集群上的controller,运行在3个大型虚拟机(m5ad.24xlarge – 384 GiB RAM)和一个RDS(db.m5.24xlarge)实例上。实际上,我们使用K3s来运行Fleet Manager集群。我们这样做是因为Kine已经在其中集成了。我将在后面解释什么是Kine以及为什么使用它。尽管K3s针对的是小规模的集群,但它可能是最容易大规模运行的Kubernetes发行版,我们使用它是因为其简单易用。值得注意的是,在EKS这样的托管提供商上,我们无法大规模运行Fleet,稍后我会解释这一点。
发现1:调整服务账户和费率限制
我们遇到的第一个问题完全出乎意料。当一个Fleet agent注册到Fleet Manager时,它会使用一个临时的集群注册令牌(token)。然后,该令牌被用来为该集群/agent创建新的身份和凭证。集群注册令牌和该agent的凭证都是服务账户。我们注册集群的速度受到controller-manager为服务账户创建令牌的速度的限制。经过研究,我们发现我们可以修改controller-manager的默认设置来提高我们创建服务账户的速度(-concurrent-serviceaccount-token-syncs=100)和每秒API请求的总体数量(-kube-api-qps=10000)。
发现2:etcd不能在此规模下运行
Fleet是作为Kubernetes Controller编写的。因此,将Fleet扩展到100万个集群意味着要在Kubernetes中管理数千万个对象。正如我们所了解的,etcd并没有能力管理这么大的数据量。Etcd的主要空间有8GB的限制,默认设置为2GB。关键空间包括当前的值和它们之前尚未被垃圾收集的值。在Fleet中,一个简单的集群对象大约需要6KB。对于100万个集群,我们至少需要6GB。但是一个集群一般包含10个左右的Kubernetes对象,加上每个部署一个对象。所以在实际操作中,我们更有可能需要超过100万个集群10倍的内存空间。
为了绕过etcd的限制,我们使用了Kine,这使得使用传统的RDBMS运行任何Kubernetes发行版成为可能。在这个规模测试中,我们运行了RDS db.m5.24xlarge实例。我们没有尝试对数据库进行适当的大小调整,而是从最大的m5实例开始。在测试结束时,我们在Kine中拥有大约2000万个对象。这意味着以这种规模运行Fleet不能在EKS这样的托管提供商上进行,因为它是基于etcd的,也不会为我们的需求提供足够可扩展的数据存储。
这个测试似乎并没有把数据库push得很厉害。诚然,我们使用了一个非常大的数据库,但很明显我们还有很多垂直扩展的空间。单条记录的插入和查找继续以可接受的速度进行。我们注意到,随机列出大量对象(最多一万个)将会花费30秒到一分钟的时间。但一般来说,这些查询会在不到1秒的时间内完成,或者在非常粗暴的测试下5秒也可以完成。因为这些耗时很长的查询发生在缓存重载期间,所以对系统整体影响不大,我们将在后面讨论。尽管这些缓慢的查询并没有对Fleet造成明显的影响,但我们还是需要进一步调查为什么会出现这种情况。
发现3:增加监控缓存大小
当controller加载缓存时,首先会列出所有对象,然后从列表的修订版开始监控。如果有非常高的变化率并且列出对象花费了很长的时间,那么你很容易陷入这样的情况:你完成了列表但无法启动监控,因为API Server的监控缓存中没有这个修订版,或者已经在etcd中被压缩了。作为一个变通办法,我们将监控缓存设置为一个非常高的值(–default-watch-cache-size=10000000)。理论上,我们认为我们会遇到Kine的压实问题(compact),但我们没有,这需要进一步调查。一般来说,Kine在压实(compact)的频率上要低很多。但在这种情况下,我们怀疑我们添加记录的速度超过了Kine压实的速度。这并不糟糕。我们并不希望坚持要保持一致的变化率,这只是因为我们正在快速注册集群。
发现4:加载缓慢的缓存
Kubernetes controller的标准实现是将你正在处理的所有对象缓存在内存中。对于Fleet,这意味着我们需要加载数百万个对象来建立缓存。对象列表的默认分页大小为500。加载100万个对象需要2000个API请求。如果你假设我们可以每秒钟进行一次列表调用、处理对象并开启下一页,这意味着加载缓存需要30分钟左右。不幸的是,如果这2000个API请求中的任何一个失败,这个过程就会重新开始。我们尝试将页面大小增加到10,000个对象,但看到整体加载时间并没有明显加快。我们开始一次列出1万个对象之后,我们就遇到了一个问题,Kine会随机花费超过1分钟的时间来返回所有对象。然后Kubernetes API Server会取消请求,导致整个加载操作失败,不得不重新启动。我们通过增加API请求超时(-request-timeout=30m)来解决这个问题,但这不是一个可接受的解决方案。保持较小的页面大小可以确保请求的速度更快,但请求的数量增加了失败几率,并导致整个操作重启。
重启Fleet controller将需要花费45分钟的时间。这一重启时间同样适用于kube-apiserver和kube-controller-manager。这意味着你需要非常小心。这也是我们发现运行K3s不如运行RKE等传统发行版的一点。K3s将api-server和controller-manager结合到同一个进程中,这使得重启api-server或controller-manager的速度比原本应有的速度慢,而且更容易出错。模拟一场灾难性的故障,需要完全重启所有服务,包括Kubernetes,这一切花了几个小时才恢复上线。
加载缓存所需的时间和失败的几率是迄今为止我们发现的扩展Fleet的最大问题。今后,这是我们要解决的首要问题。
结 论
通过测试,我们证明了Fleet的架构可以扩展到100万个集群,更重要的是,Kubernetes可以作为一个平台来管理更多的数据。Fleet本身与容器没有任何直接的关系,可以看成只是一个简单的应用,在Kubernetes中管理数据。这些发现为我们开启了一个可能性,即把Kubernetes更多的当作一个通用的编排平台来写代码。当考虑到你可以很容易地将一套controller与K3s捆绑在一起,Kubernetes就变成了一个很好的自成一体的应用server。
在扩展规模方面,重新加载缓存所需的时间令人担忧,但绝对是可控的。我们将继续在这方面进行改进,使运行100万个集群不仅是可行的,而且是简单的。因为在Rancher Labs,我们喜欢简单。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/134442.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
