大家好,又见面了,我是你们的朋友全栈君。
引言
看了好几篇关于双线性插值算法的博文,解释得都不好理解,不过下面这篇博文就解释得很好,以下内容均参考这篇:
双线性插值算法
双线性插值算法是解决什么问题的(原理)?
在图像的仿射变换中,很多地方需要用到插值运算,常见的插值运算包括最邻近插值、双线性插值、双三次插值、兰索思插值等方法,OpenCV提供了很多方法,其中,双线性插值由于折中的插值效果和运算速度,运用比较广泛。
越是简单的模型越适合用来举例子,我们就举个简单的图像:3 * 3 的256级灰度图。假如图像的象素矩阵如下图所示(这个原始图把它叫做源图,Source):
234 38 22
67 44 12
89 65 63
这 个矩阵中,元素坐标(x,y)是这样确定的,x从左到右,从0开始,y从上到下,也是从零开始,这是图象处理中最常用的坐标系。
如果想把这副图放大为 4 * 4大小的图像,那么该怎么做呢? 那么第一步肯定想到的是先把4 * 4的矩阵先画出来再说,好了矩阵画出来了,如下所示,当然,矩阵的每个像素都是未知数,等待着我们去填充(这个将要被填充的图的叫做目标图,Destination):
? ? ? ?
? ? ? ?
? ? ? ?
? ? ? ?
然后要往这个空的矩阵里面填值了,要填的值从哪里来来呢? 是从源图中来,好,先填写目标图最左上角的象素,坐标为(0,0),那么该坐标对应源图中的坐标可以由如下公式得出
srcX = dstX * (srcWidth/dstWidth) (括号里srcWidth/dstWidth是两个图的比例关系)
srcY = dstY * (srcHeight/dstHeight)
好了,套用公式,就可以找到对应的原图的坐标了(0 * (3/4),0 * (3/4))=>(0 * 0.75, 0 * 0.75)=>(0,0),找到了源图的对应坐标,就可以把源图中坐标为(0,0)处的234象素值填进去目标图的(0,0)这个位置了。
接下来,如法炮制,寻找目标图中坐标为(1,0)的象素对应源图中的坐标,套用公式:
(1 * 0.75,0 * 0.75)=>(0.75,0) 结果发现,得到的坐标里面竟然有小数,这可怎么办?计算机里的图像可是数字图像,像素就是最小单位了,像素的坐标都是整数,从来没有小数坐标 。
这时候采用的一种策略就是采用四舍五入的方法(也可以采用直接舍掉小数位的方法),把非整数坐标转换成整数,好,那么按照四舍五入的方法就得到坐标(1,0),完整的运算过程就是这样的:(1 * 0.75,0 * 0.75)=>(0.75,0)=>(1,0) 那么就可以再填一个象素到目标矩阵中了,同样是把源图中坐标为(1,0)处的像素值38填入目标图中的坐标。
依次填完每个象素,一幅放大后的图像就诞生了,像素矩阵如下所示:
234 38 22 22
67 44 12 12
89 65 63 63
89 65 63 63
这种放大图像的方法叫做最临近插值算法,这是一种最基本、最简单的图像缩放算法,效果也是最不好的,放大后的图像有很严重的马赛克,缩小后的图像有很严重的失真;效果不好的根源就是其简单的最临近插值方法引入了严重的图像失真,比如,当由目标图的坐标反推得到的源图的的坐标是一个浮点数的时候,采用了四舍五入的方法,直接采用了和这个浮点数最接近的象素的值,这种方法是很不科学的,当推得坐标值为 0.75的时候,不应该就简单的取为1,既然是0.75,比1要小0.25 ,比0要大0.75 ,那么目标象素值其实应该根据这个源图中虚拟的点四周的四个真实的点来按照一定的规律计算出来的,这样才能达到更好的缩放效果。
双线型内插值算法就是一种比较好的图像缩放算法,它充分的利用了源图中虚拟点四周的四个真实存在的像素值来共同决定目标图中的一个像素值,因此缩放效果比简单的最邻近插值要好很多。
双线性内插值算法描述如下:
对于一个目的像素,设置坐标通过反向变换得到的浮点坐标为(i+u,j+v) (其中i、j均为浮点坐标的整数部分,u、v为浮点坐标的小数部分,是取值[0,1)区间的浮点数),则这个像素得值 f(i+u,j+v) 可由原图像中坐标为 (i,j)、(i+1,j)、(i,j+1)、(i+1,j+1) 所对应的周围四个像素的值决定,即:f(i+u,j+v) = (1-u)(1-v)f(i,j) + (1-u)vf(i,j+1) + u(1-v)f(i+1,j) + uvf(i+1,j+1)。其中f(i,j)表示源图像(i,j)处的的像素值,以此类推。
注:比如坐标(1.3,1.4)=> (1+0.3,1+0.4),那么可由原图像中的坐标为(1,1)、(2,1),(1,2),(2,2)所对应的周围四个像素的值决定
双线性插值算法是怎么解决问题的(计算方法)?
什么是单线性插值
已知数据 (x0, y0) 与 (x1, y1),要计算 [x0, x1] 区间内某一位置 x 在直线上的y值。
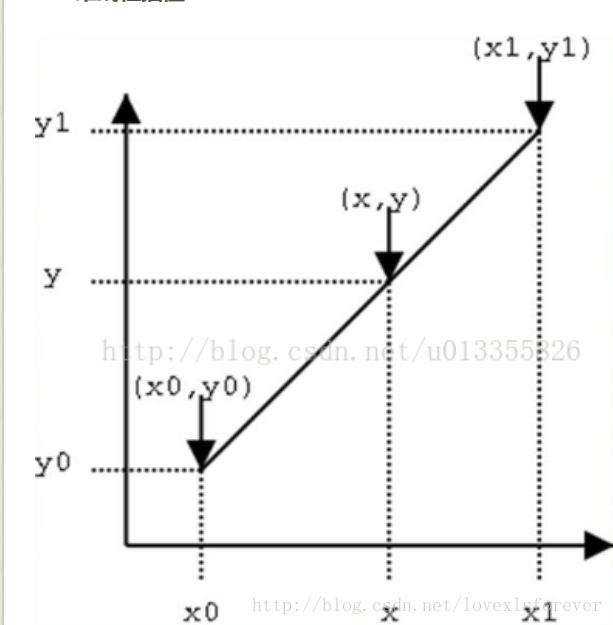

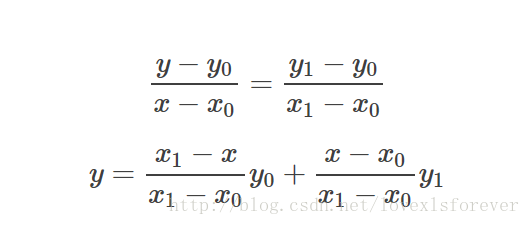
上面比较好理解吧,仔细看就是用x和x0,x1的距离作为一个权重,用于y0和y1的加权。双线性插值本质上就是在两个方向上做线性插值。(其实就是有两个点确定的一次函数,然后在函数上去值呗)
双线性插值法
在数学上,双线性插值是有两个变量的插值函数的线性插值扩展,其核心思想是在两个方向分别进行一次线性插值。见下图:
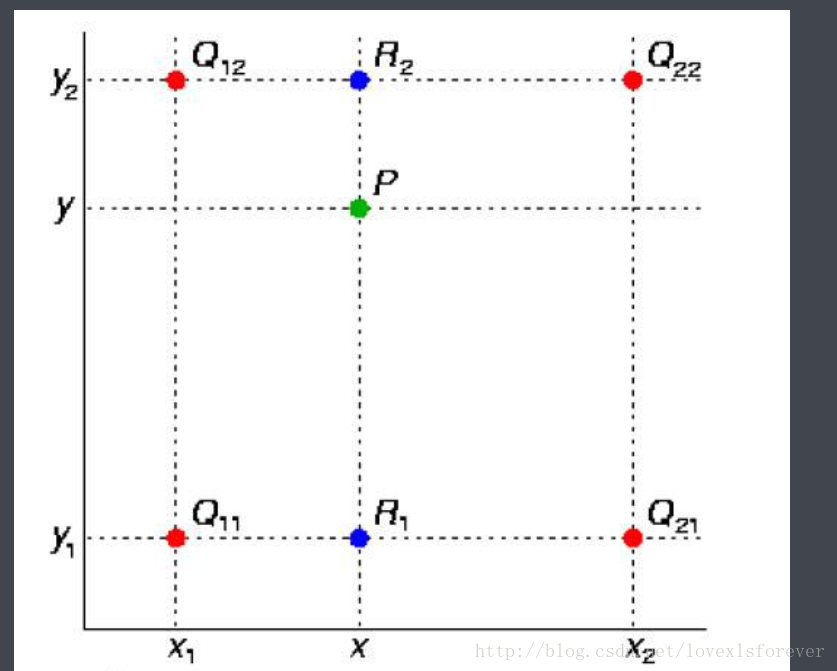
假如我们想得到未知函数 f 在点 P = (x, y) 的值,假设我们已知函数 f 在 Q11 = (x1, y1)、Q12 = (x1, y2), Q21 = (x2, y1) 以及 Q22 = (x2, y2) 四个点的值。最常见的情况,f就是一个像素点的像素值。首先在 x 方向进行线性插值,得到
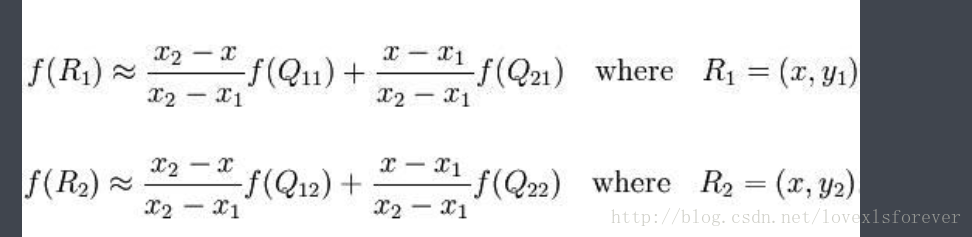
然后在 y 方向进行线性插值,得到
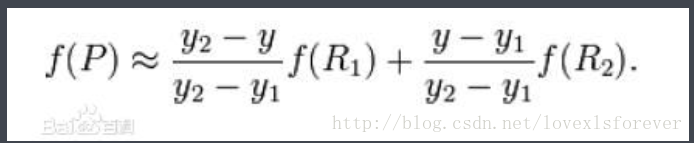
综合起来就是双线性插值最后的结果:
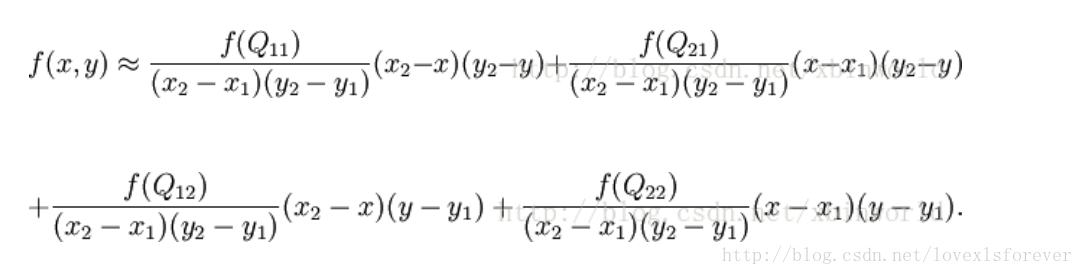
由于图像双线性插值只会用相邻的4个点,因此上述公式的分母都是1。
使用双线性插值时要注意什么(存在的问题)?
这部分的前提是,你已经明白什么是双线性插值并且在给定源图像和目标图像尺寸的情况下,可以用笔计算出目标图像某个像素点的值。当然,最好的情况是你已经用某种语言实现了网上一大堆博客上原创或转载的双线性插值算法,然后发现计算出来的结果和matlab、openCV对应的resize()函数得到的结果完全不一样。
那这个究竟是怎么回事呢?
其实答案很简单,就是坐标系的选择问题,或者说源图像和目标图像之间的对应问题。
按照网上一些博客上写的,源图像和目标图像的原点(0,0)均选择左上角,然后根据插值公式计算目标图像每点像素,假设你需要将一幅5×5的图像缩小成3×3,那么源图像和目标图像各个像素之间的对应关系如下:
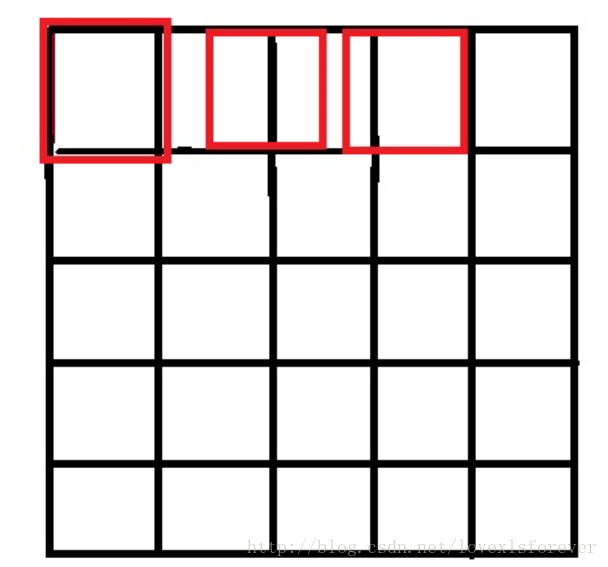
只画了一行,用做示意,从图中可以很明显的看到,如果选择右上角为原点(0,0),那么最右边和最下边的像素实际上并没有参与计算,而且目标图像的每个像素点计算出的灰度值也相对于源图像偏左偏上。
那么,让坐标加1或者选择右下角为原点怎么样呢?很不幸,还是一样的效果,不过这次得到的图像将偏右偏下。
最好的方法就是,两个图像的几何中心重合(也就是下面要讲的优化策略),并且目标图像的每个像素之间都是等间隔的,并且都和两边有一定的边距,这也是matlab和openCV的做法。如下图:
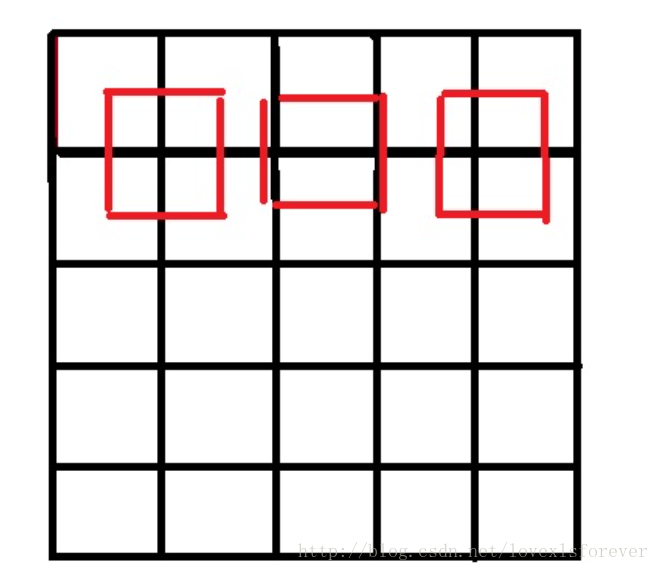
如果你不懂我上面说的什么,没关系,只要在计算对应坐标的时候改为以下公式即可,
int x=(i+0.5)*m/a-0.5
int y=(j+0.5)*n/b-0.5
instead of
int x=im/a
int y=jn/b
利用上述公式,将得到正确的双线性插值结果
加速及优化策略
单纯按照上文实现的插值算法只能勉强完成插值的功能,速度和效果都不会理想,在具体代码实现的时候有些小技巧。参考OpenCV源码以及网上博客整理如下两点:
源图像和目标图像几何中心的对齐
将浮点运算转换成整数运算
源图像和目标图像几何中心的对齐
方法:在计算源图像的虚拟浮点坐标的时候,一般情况:
srcX=dstX* (srcWidth/dstWidth) ,
srcY = dstY * (srcHeight/dstHeight)
中心对齐:
SrcX=(dstX+0.5)* (srcWidth/dstWidth) -0.5
SrcY=(dstY+0.5) * (srcHeight/dstHeight)-0.5
原理:
双线性插值算法及需要注意事项这篇博客解释说“如果选择右上角为原点(0,0),那么最右边和最下边的像素实际上并没有参与计算,而且目标图像的每个像素点计算出的灰度值也相对于源图像偏左偏上。”我有点保持疑问。
将公式变形:
srcX=dstX * (srcWidth/dstWidth)+0.5 * (srcWidth/dstWidth-1)
相当于我们在原始的浮点坐标上加上了0.5 * (srcWidth/dstWidth-1)这样一个控制因子,这项的符号可正可负,与srcWidth/dstWidth的比值也就是当前插值是扩大还是缩小图像有关,有什么作用呢?看一个例子:假设源图像是33,中心点坐标(1,1)目标图像是99,中心点坐标(4,4),我们在进行插值映射的时候,尽可能希望均匀的用到源图像的像素信息,最直观的就是(4,4)映射到(1,1)现在直接计算srcX=4 * 3/9=1.3333!=1,也就是我们在插值的时候所利用的像素集中在图像的右下方,而不是均匀分布整个图像。现在考虑中心点对齐,srcX=(4+0.5) * 3/9-0.5=1,刚好满足我们的要求。
将浮点运算转换成整数运算
参考图像处理界双线性插值算法的优化
直接进行计算的话,由于计算的srcX和srcY 都是浮点数,后续会进行大量的乘法,而图像数据量又大,速度不会理想,解决思路是:
浮点运算→→整数运算→→”<<左右移按位运算”。
放大的主要对象是u,v这些浮点数,OpenCV选择的放大倍数是2048“如何取这个合适的放大倍数呢,要从三个方面考虑,
第一:精度问题,如果这个数取得过小,那么经过计算后可能会导致结果出现较大的误差。
第二,这个数不能太大,太大会导致计算过程超过长整形所能表达的范围。
第三:速度考虑。假如放大倍数取为12,那么算式在最后的结果中应该需要除以12 * 12=144,但是如果取为16,则最后的除数为16 * 16=256,这个数字好,我们可以用右移来实现,而右移要比普通的整除快多了。”我们利用左移11位操作就可以达到放大目的。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/134352.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
