大家好,又见面了,我是你们的朋友全栈君。
CNN卷积神经网络及图像识别
前言
神经网络(neual networks)是人工智能研究领域的一部分,当前最流行的神经网络是深度卷积神经网络(deep convolutional neural networks, CNNs),虽然卷积网络也存在浅层结构,但是因为准确度和表现力等原因很少使用。目前提到CNNs和卷积神经网络,学术界和工业界不再进行特意区分,一般都指深层结构的卷积神经网络,层数从”几层“到”几十上百“不定。
CNNs目前在很多很多研究领域取得了巨大的成功,例如: 语音识别,图像识别,图像分割,自然语言处理等。虽然这些领域中解决的问题并不相同,但是这些应用方法都可以被归纳为:
CNNs可以自动从(通常是大规模)数据中学习特征,并把结果向同类型未知数据泛化。
卷积神经网络-CNN 的基本原理
网络结构
基础的CNN由 卷积(convolution), 激活(activation), and 池化(pooling)三种结构组成。CNN输出的结果是每幅图像的特定特征空间。当处理图像分类任务时,我们会把CNN输出的特征空间作为全连接层或全连接神经网络(fully connected neural network, FCN)的输入,用全连接层来完成从输入图像到标签集的映射,即分类。当然,整个过程最重要的工作就是如何通过训练数据迭代调整网络权重,也就是后向传播算法。目前主流的卷积神经网络(CNNs),比如VGG, ResNet都是由简单的CNN调整,组合而来。
典型的 CNN 由3个部分构成:
- 卷积层:卷积层负责提取图像中的局部特征;
- 池化层:池化层用来大幅降低参数量级(降维);
- 全连接层:全连接层类似传统神经网络的部分,用来输出想要的结果。
卷积
在CNN中,卷积可以近似地看作一个特征提取算子,简单来说就是,提取图片纹理、边缘等特征信息的滤波器。下面,举个简单的例子,解释一下特征提取算子是怎么工作的:


比如有一张猫图片,人类在理解这张图片的时候,可能观察到圆圆的眼睛,可爱的耳朵,于是,判断这是一只猫。但是,机器怎么处理这个问题呢?传统的计算机视觉方法,通常设计一些算子(特征提取滤波器),来找到比如眼睛的边界,耳朵的边界,等信息,然后综合这些特征,得出结论——这是一只猫。
卷积神经网络,做了类似的事情,所谓卷积,就是把一个算子在原图上不断滑动,得出滤波结果——这个结果,我们叫做“特征图”(Feature Map),这些算子被称为“卷积核”(Convolution Kernel)。不同的是,我们不必人工设计这些算子,而是使用随机初始化,来得到很多卷积核(算子),然后通过反向传播,优化这些卷积核,以期望得到更好的识别结果。
卷积的运算过程可以用下图来表示:

我们可以发现,卷积运算之后,数据变少了,可想而知,如果经过很多层卷积的话,输出尺寸会变的很小,同时图像边缘信息,会迅速流失,这对模型的性能,有着不可忽视的影响。为了减少卷积操作导致的,边缘信息丢失,我们需要进行填充(Padding),即在原图周围,添加一圈值为“0”的像素点(zero padding),这样的话,输出维度就和输入维度一致了。
上面的卷积过程,没有考虑彩色图片有rgb三维通道(Channel),如果考虑rgb通道,那么,每个通道,都需要一个卷积核:
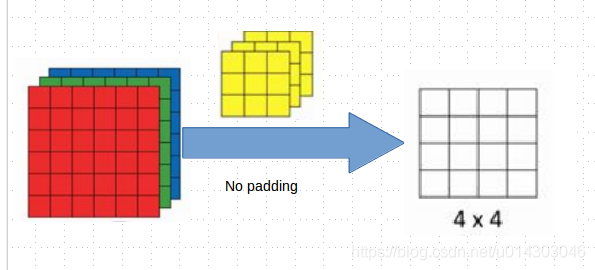
当输入有多个通道时,我们的卷积核也需要有同样数量的通道。以上图为例,输入有RGB三个通道,我们的就卷积核,也有三个通道,只不过计算的时候,卷积核的每个通道,在对应通道滑动(卷积核最前面的通道在输入图片的红色通道滑动,卷积核中间的通道在输入图片的绿色通道滑动,卷积核最后面的通道在输入图片的蓝色通道滑动),如果我们想将三个通道的信息合并,可以将三个通道的计算结果相加得到输出。注意,输出只有一个通道。
卷积层的作用:
- 提取图像的特征,并且卷积核的权重是可以学习的,卷积操作能突破传统滤波器的限制,根据目标函数提取出想要的特征;
- 参数共享,降低了网络参数,提升训练效率。
池化
池化(Pooling),有的地方也称汇聚,实际是一个下采样(Down-sample)过程。由于输入的图片尺寸可能比较大,这时候,我们需要下采样,减小图片尺寸。池化层可以减小模型规模,提高运算速度,同时提高所提取特征的鲁棒性。
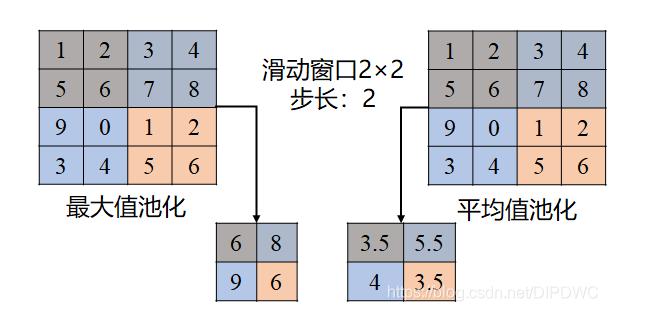
本文主要介绍最大池化(Max Pooling)和平均池化(Average Pooling)。
所谓最大池化,就是选取一定区域中数值最大的那个保留下来。比如区域大小为2*2,步长为2的池化过程如下(左边是池化前,右边是池化后),对于每个池化区域都取最大值:
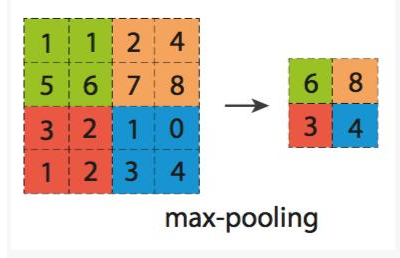
最大池化最为常用,并且一般都取2*2的区域大小且步长为2。
平均池化则是取每个区域的均值,下图展示了两种池化的对比
全连接层
全连接层就是把卷积层和池化层的输出展开成一维形式,在后面接上与普通网络结构相同的回归网络或者分类网络,一般接在池化层后面,这一层的输出即为我们神经网络运行的结果。
代码示例
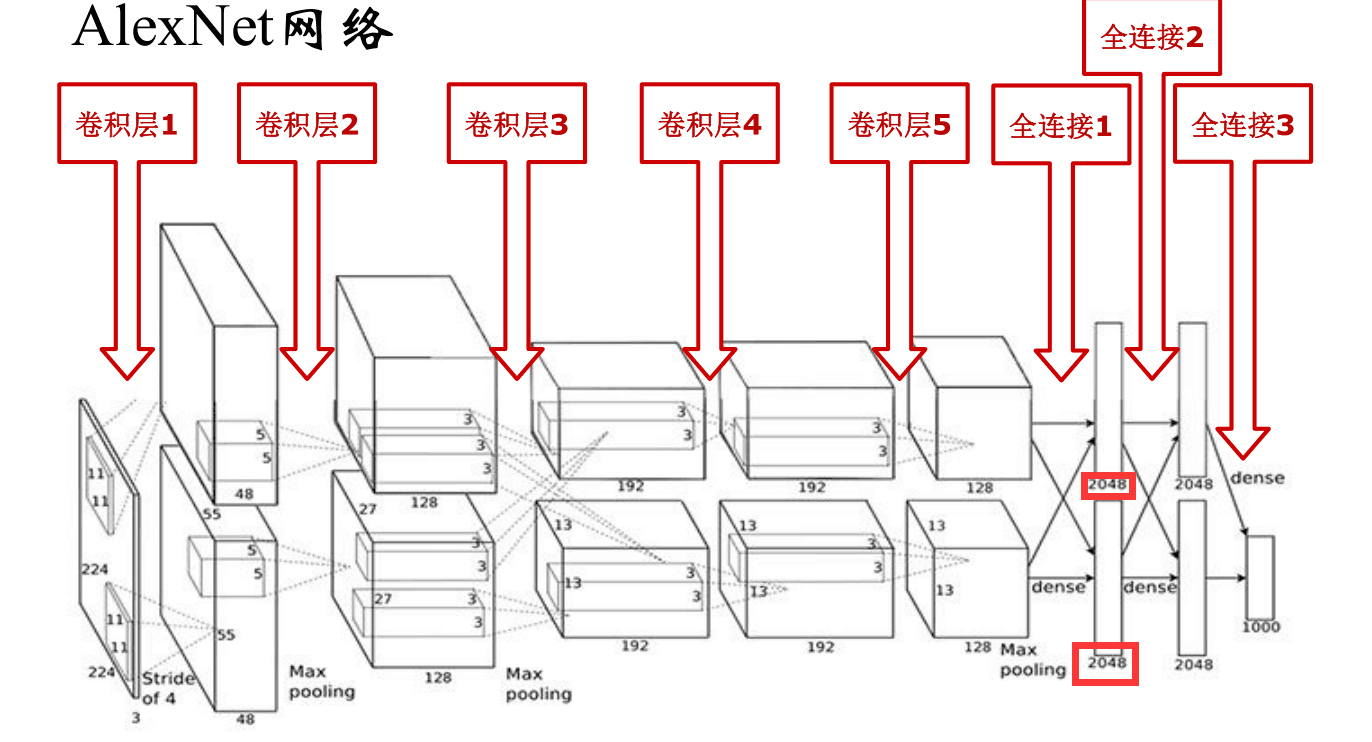
下面以AlexNet为例子,给出一个详细的卷积神经网络架构,首先AlexNet架构如下图所示:
代码如下:
import tensorflow as tf
import numpy as np
# 定义各层功能
# 最大池化层
def maxPoolLayer(x, kHeight, kWidth, strideX, strideY, name, padding = "SAME"):
"""max-pooling"""
return tf.nn.max_pool(x, ksize = [1, kHeight, kWidth, 1],
strides = [1, strideX, strideY, 1], padding = padding, name = name)
# dropout
def dropout(x, keepPro, name = None):
"""dropout"""
return tf.nn.dropout(x, keepPro, name)
# 归一化层
def LRN(x, R, alpha, beta, name = None, bias = 1.0):
"""LRN"""
return tf.nn.local_response_normalization(x, depth_radius = R, alpha = alpha,
beta = beta, bias = bias, name = name)
# 全连接层
def fcLayer(x, inputD, outputD, reluFlag, name):
"""fully-connect"""
with tf.variable_scope(name) as scope:
w = tf.get_variable("w", shape = [inputD, outputD], dtype = "float")
b = tf.get_variable("b", [outputD], dtype = "float")
out = tf.nn.xw_plus_b(x, w, b, name = scope.name)
if reluFlag:
return tf.nn.relu(out)
else:
return out
# 卷积层
def convLayer(x, kHeight, kWidth, strideX, strideY,
featureNum, name, padding = "SAME", groups = 1):
"""convolution"""
channel = int(x.get_shape()[-1])
conv = lambda a, b: tf.nn.conv2d(a, b, strides = [1, strideY, strideX, 1], padding = padding)
with tf.variable_scope(name) as scope:
w = tf.get_variable("w", shape = [kHeight, kWidth, channel/groups, featureNum])
b = tf.get_variable("b", shape = [featureNum])
xNew = tf.split(value = x, num_or_size_splits = groups, axis = 3)
wNew = tf.split(value = w, num_or_size_splits = groups, axis = 3)
featureMap = [conv(t1, t2) for t1, t2 in zip(xNew, wNew)]
mergeFeatureMap = tf.concat(axis = 3, values = featureMap)
# print mergeFeatureMap.shape
out = tf.nn.bias_add(mergeFeatureMap, b)
return tf.nn.relu(tf.reshape(out, mergeFeatureMap.get_shape().as_list()), name = scope.name)
class alexNet(object):
"""alexNet model"""
def __init__(self, x, keepPro, classNum, skip, modelPath = "bvlc_alexnet.npy"):
self.X = x
self.KEEPPRO = keepPro
self.CLASSNUM = classNum
self.SKIP = skip
self.MODELPATH = modelPath
#build CNN
self.buildCNN()
# 构建AlexNet
def buildCNN(self):
"""build model"""
conv1 = convLayer(self.X, 11, 11, 4, 4, 96, "conv1", "VALID")
lrn1 = LRN(conv1, 2, 2e-05, 0.75, "norm1")
pool1 = maxPoolLayer(lrn1, 3, 3, 2, 2, "pool1", "VALID")
conv2 = convLayer(pool1, 5, 5, 1, 1, 256, "conv2", groups = 2)
lrn2 = LRN(conv2, 2, 2e-05, 0.75, "lrn2")
pool2 = maxPoolLayer(lrn2, 3, 3, 2, 2, "pool2", "VALID")
conv3 = convLayer(pool2, 3, 3, 1, 1, 384, "conv3")
conv4 = convLayer(conv3, 3, 3, 1, 1, 384, "conv4", groups = 2)
conv5 = convLayer(conv4, 3, 3, 1, 1, 256, "conv5", groups = 2)
pool5 = maxPoolLayer(conv5, 3, 3, 2, 2, "pool5", "VALID")
fcIn = tf.reshape(pool5, [-1, 256 * 6 * 6])
fc1 = fcLayer(fcIn, 256 * 6 * 6, 4096, True, "fc6")
dropout1 = dropout(fc1, self.KEEPPRO)
fc2 = fcLayer(dropout1, 4096, 4096, True, "fc7")
dropout2 = dropout(fc2, self.KEEPPRO)
self.fc3 = fcLayer(dropout2, 4096, self.CLASSNUM, True, "fc8")
def loadModel(self, sess):
"""load model"""
wDict = np.load(self.MODELPATH, encoding = "bytes").item()
#for layers in model
for name in wDict:
if name not in self.SKIP:
with tf.variable_scope(name, reuse = True):
for p in wDict[name]:
if len(p.shape) == 1:
#bias
sess.run(tf.get_variable('b', trainable = False).assign(p))
else:
#weights
sess.run(tf.get_variable('w', trainable = False).assign(p))
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/134340.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
