大家好,又见面了,我是你们的朋友全栈君。
文章目录
前言
本文针对《Python语言程序设计基础 (第2版)》——嵩天 礼欣 黄天羽,此书进行简单知识总结。
本文总结了华农python期末部分常见考点,对信息学院的同学帮助不大,适合其他学院同学参考。
本人只是单纯的想进行分享,并没有炫耀自己的意思,如果让您心情不悦我感到很抱歉。
本文可能对编程编写有所帮助,但是理论知识还需要大家多刷题,多看定义。
因本人精力、能力有限,文章不足之处还请指正。
此外,大家可以将需求、遗漏的地方或疑问写在评论区,后期会及时进行补充,解答疑问。
码字不易,大家如果本文感觉有帮助的话,不胜感激!
注:欢迎富婆、小哥哥打赏!
推荐的学习资料
建议参考B站小甲鱼视频辅助学习点击这里跳转跳转。
书籍的话,其实觉得没必要,网上都有电子版的,很想买的话建议选购《疯狂Python讲义》,内容想详实,不建议买《Python编程 从入门到实践》,我觉得它不太适合新手学,虽然在京东销量第一(难道是刷上去的?),等学了一遍之后可以康康
课程配套实验题点击跳转
最后,欢迎将问题打在评论区,我看到会及时回复。
复习要点
-缩进、注释、命名、变量、保留字
-数据类型、字符串、 整数、浮点数、列表、字典
-赋值语句、分支语句、函数
-input( )、print( )、eval( )、 print( )及其格式化
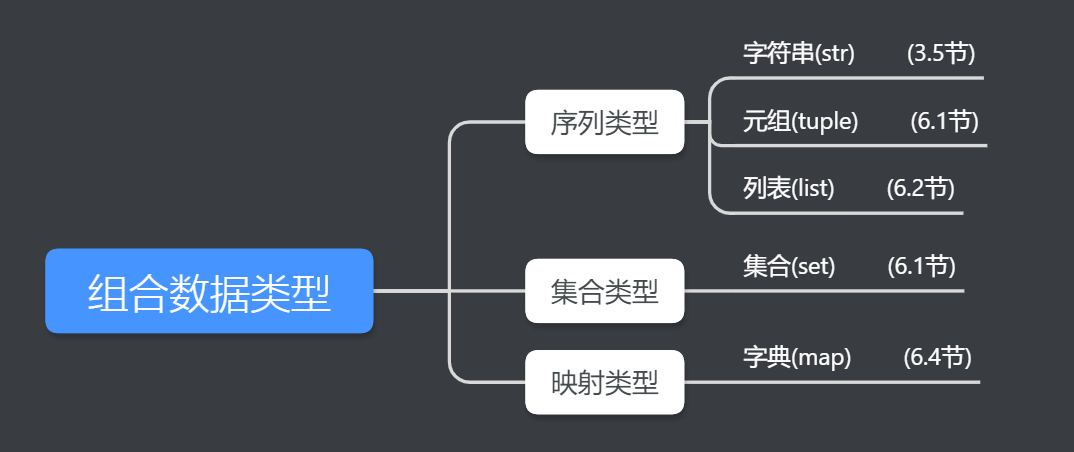
组合数据类型
注: 详细内容请看后面几段

序列类型通用操作符和函数
| 操作符 | 描述 |
|---|---|
| x in s | 如果x是s的元素,返回True,否则返回False |
| x not in s | 如果x不是s的元素,返回True,否则返回False |
| s + t | 连接 s 和 t |
| s * n 或 n * s | 将序列 s 复制 n 次 |
| s[i] | 索引,返回序列第 i + 1个元素 |
| s[i : j] | 切片,不包括第 j 位元素 |
| s[i : j : k] | 步骤切片,k表示步长,不写默认为1 |
| len(s) | 序列 s 的长度 |
| min(s) | 序列 s 的最小元素 |
| max(s) | 序列 s 的最大元素 |
| sum(s) | 序列 s 的求和(列表只含数字) |
| s.index(x) | 序列 s 中从左往右第一次出现 x 的索引 |
| s.rindex(x) | 序列 s 中从右往左第一次出现 x 的索引 |
| s.count(x) | 序列 s 中出现 x 的总次数 |
注: 序列类型是可迭代对象,可以直接使用for循环操作。
a=[1,2,3,4,5]
for i in a:
print(i,end='**') #end是可选参数,不写默认为换行符'\n'
#得到1**2**3**4**5**
集合类型
类似数学上的集合概念元素具有单一性,集合并没有自动升序排列的性质,可能是元素少的时候碰巧,可以使用sorted()函数来排序哦!
(集合是具有确定性、互异性、无序性的,不要混淆了)
常用于: 去除列表中的相同元素
list1=[5,1,3,7,9,9,2]
list1=list(set(list1))
print(list1) #得到[1, 2, 3, 5, 7, 9]
# 大家看呀,这个自动升序了,但仅仅是碰巧。
print(set([1,3,8,-2,99,98,77,1,5,3,77,12])) # 得到{1, 98, 3, 99, 5, 8, 12, 77, -2}
# 大家看这个,就不会自动给你升序了,一定要注意,集合并没有自动升序排列的性质
映射类型
需要了解:
①怎样增删键值对
②怎样得到字典中键,值,键值对应的元组
③一个键只能对应一个值
注: 键(key)就是冒号左侧的值。值(value)就是冒号右面的数值。
数值操作
运算符
| 算数运算符 | 描述 |
|---|---|
| x%y | 求得商的余数。例如:5%2结果为1 |
| x//y | 求得x除y商的整数位,简称整除。例如x//y结果为2 |
| x**y | 求得x的y次幂。例如4**(1/2)结果为2,3**2结果为9 |
| 比较运算符 | 描述 |
|---|---|
| x==y、x!=y | 判断x是否相等或者不相等,符合条件返回True,否则返回False |
| x>y、x<y | 判断x是否大于或小于y,符合条件返回True,否则返回False |
| x<=y、x>=y | 判断x是否大于等于或小于等于y,同样返回布尔值 |
| 赋值运算符 | 描述 |
|---|---|
| x=y | 将y的值赋值给x,注意:当y是复杂数据类型时要使用.copy()的方法 |
| x+=1 | 等价于x=x+1 |
| x-=1 | 等价于x=x-1 |
| x*=2 | 等价于x=x*2 |
| x/=2 | 等价于x=x/2 |
| 逻辑运算符 | 描述 |
|---|---|
| and | 布尔运算“与” |
| or | 布尔运算“或” |
| not | 布尔运算“非” |
即得到优先级关系:or<and<not,同一优先级默认从左往右计算。
| 成员运算符 | 描述 |
|---|---|
| a in b | 如果a在b就返回True |
| a not in b | 如果a不在b就返回True |
字符串操作
字符串切片
基本切片操作
格式:<需要处理的字符串>[M:N]。
M缺失表示至开头,N缺失表示至结尾。
注意:①两种索引方式可以混用;②切片得到的结果不包含N索引的值。
a='〇一二三四五六七八九'
print(a[1:3])#得到 一二
print(a[1:-1])#得到 一二三四五六七八
print(a[-3:-1])#得到 七八
print(a[:3])#得到 〇一二
print(a[4:])#得到 四五六七八九
高级切片操作
格式:<需要处理的字符串>[M:N:K]。
根据步长K对字符串切片。不写K时默认为1,与[M:N]等价。
a='〇一二三四五六七八九'
print(a[1:8:2])#得到 一三五七
#分析过程:在一~七中,索引从1开始,依次加2,即a[1],a[3],a[5],a[7],将其拼接在一起得到一三五七
''' —————————————————————————————————美丽的分隔线—————————————————————————————————————— '''
print(a[::-1])#得到 九八七六五四三二一〇
#得到逆序字符串,格式固定。可简单理解为从右至左操作选定的字符串片段[M:N]。
''' —————————————————————————————————美丽的分隔线—————————————————————————————————————— '''
操作、相关函数、相关使用方法
| 操作符 | 描述 |
|---|---|
| x+y | 连接两个字符串 |
| x*n | 复制n次字符串x |
| x in s | 返回布尔值,如果字符串x在s内,则返回True,否则返回False |
| 相关函数 | 描述 |
|---|---|
| len(x) | 返回字符串的长度。例如:len(‘我爱帅帅龙’)结果为5 |
| str(x) | 将任意类型数据转为字符串。例如:str(123)结果为字符串”123″,str([1,2])结果为字符串”[1,2]” |
| chr(x) | 返回Unicode编码的单字符。例如:chr(65)得到字母”A” |
| ord(x) | 返回单字符对应的Unicode编码。例如:ord(“a”)得到数字97 |
| 相关方法 | 描述 |
|---|---|
| str.lower() 、str.upper() | 返回将字符串全部变成小写或大写的副本。 例:‘abc’.upper()的结果为:‘ABC’ |
| str.isalpha() | 返回布尔值,判断字符串str是否全部为字母 |
| str.islower()、str.isnumeruic() | 返回布尔值,判断字符串str是否全部为小写或数字 如果记不住函数名。建议用循环和比较大小的方式判断每个字符是否符合标准 |
| str.split(sep) | 将字符串按sep进行分割,当sep不填的时候默认以空格分割。 例:‘A,B,C’.split(’,’)结果为:[‘A’,‘B’,‘C’] |
| str.strip() | 将字符串左右两边的空字符去掉,\n,\t,空格等。 例:’ \n我爱帅帅龙’.strip()结果为:‘我爱帅帅龙’ |
| str.replace(old,new) | 返回副本,将字符串str中old字符替换为new字符。 例:详细讲解在下面 |
字符串格式化(不需要花费太多时间)
| 类型 | 格式规则 |
|---|---|
| f | 格式化为浮点数 |
| d | 格式化为十进制整数 |
| s | 格式化为字符串 |
format{}格式化
订正:对齐方式默认为左对齐

a=1.666
print('{0:-^20.1f}'.format(a)) # 得到--------1.7---------
0表示索引
:是引导符号
-是填充字符
^表示居中
20是输出总长度
.1表示保留一位小数
%格式化
参考c语言格式化方法,书上使用的是format格式化方法,%格式化在此不做过多介绍

a=1.555
print('%10.2f'%a) # 得到 1.55
%表示引导符号
10表示宽度
.2表示保留两位小数
f表示转为浮点型
列表
注: 在文章开头已经介绍了通用函数了,大家记得爬楼。
| 函数 | 描述 |
|---|---|
| ls[i]=x | 将列表索引为 i 的元素更新为 x |
| ls.append(x) | 在列表最后添加 x |
| ls.insert(i,x) | 在列表的第 i 位添加元素x |
| del ls[i] | 删除列表索引为 i 的元素 |
| ls.remove(x) | 删除列表中从左到右第一次出现的元素 x |
| ls.copy() | 得到列表的副本,对其操作不会影响原数据 |
| ls.sort() | 将列表从小到大排序 |
| ls.reverse() | 将列表反转 |
| mylist=sorted(ls) | 将列表的副本从小到大排序,不会影响原顺序 |
一些要注意的地方
列表中可以存放任意数据类型,但是不建议将其它数据类型强转为列表,而应该使用ls.append()的方法
print(list('我爱阿龙')) # 得到['我', '爱', '阿', '龙']
ls=[]
ls.append('我爱阿龙')
print(ls) # 得到['我爱阿龙']
将列表排序和反转,实际上是调用了sort()方法和reverse()方法,它是没有返回值的,如果输入会得到None。
a=[1,3,2,6]
print(a.sort()) # 得到None
a.sort()
print(a) # 得到[1,2,3,6]
# reverse同理
列表推导式:(有能力就掌握一下)
ls=[i for i in range(11)] # 得到[0,1,2,3,4,5,6,7,8,9,10]
ls=[i for i in range(11) if i%5==0] # 得到[5,10]
ls=[(i , j) for i in range(3) for j in range(11,13)]
# 得到[(0, 11), (0, 12), (1, 11), (1, 12), (2, 11), (2, 12)]
字典
dict1={
'张瑞龙':'帅','刘浩':'丑'}
如上所示,冒号左边的为键,冒号右边的是键所对应的值。例如,张瑞龙对应的是帅,刘浩对应丑。
注意: ①键的存在是单一的,即一个字典一个键只能出现一次。
②值的类型可以是任意类型,键不能是字典和集合,其他类型都可,但键和值通常为字符型
③在字典中添加元素时,键与值出现是成对出现的。
| 函数 | 描述 |
|---|---|
| dict1[key]=value | 在字典中添加元素,如果key存在,则覆盖原来对应的值 |
| list(dict1.keys()) | 得到字典所有键的列表 |
| list(dict1.values()) | 得到字典所有值的列表 |
| list(dict1.items()) | 得到字典所有元组类型键,值的列表 |
| dict1.get(key,default) | 如果键存在则返回对应的值,不存在则赋值为default |
| del dict1[key] | 删除这个键值对 |
| key in dict1 | 如果键在字典中则返回True,否则为False |
一些要注意的地方
字典作为可迭代对象,其实是它的键值
dict1={
'张瑞龙':'帅','刘浩':'丑'}
for i in dict1:
print(i)
# 得到:张瑞龙,刘浩
统计出现次数并从大到小输出
可以说是最经典的一种考题了,下面分块操作。
①统计出现次数
法一
list1=[1,1,1,2,5,3,3,10,5,6,8,9,9,11]
dict1={
} #创建一个空字典
for i in list1:
dict1[i]=dict1.get(i,0)+1 # dict1.get(i,0)表示如果有键为i则返回对应的值,否则返回0
print(dict1)
法二
list1=[1,1,1,2,5,3,3,10,5,6,8,9,9,11]
dict1={
} #创建一个空字典
for i in list1:
if i in dict1: # 如果字典中有键为i
dict1[i]+=1 # 对应的值加一
else: # 如果字典中没有键为i
dict1[i]=1 # 创建键值对,值为1,因为这是第一次出现
print(dict1)
②lambda表达式排序
mylist=list(dict1.items())
mylist.sort(key=lambda x:(-x[1],x[0]))
# 当写成mylist.sort(key=lambda x:(x[1],x[0]))是根据值从小到大排序
# 当写成mylist.sort()是根据键从小到大排序
print(mylist) # 在此处可以直接根据需求进行其他操作,而不一定要转为字典
dict1=dict(mylist) # 将列表转为字典
print(dict1)
mylist.sort(key=lambda x:(-x[1],x[0])),这里为什么要加一个负号呢?
因为sort函数是从小到大排序的,当最大的正数加了负号就会变成最小的负数,可以使用这个特性来达到我们的需求
其实,sort里面有个可选参数reverse,默认为Forse,可以尝试一下在sort里面添加参数reverse=True看看效果。
当你写成mylist.sort(key=lambda x:(x[1],x[0]),reverse=True)这样也能达到根据次数从大到小输出的。
因为介绍起来很繁琐,大家记住这个格式就好了,有问题可以直接私信我。
③综上,代码汇总
list1=[1,1,1,2,5,3,3,10,5,6,8,9,9,11]
dict1={
} #创建一个空字典
for i in list1:
dict1[i]=dict1.get(i,0)+1 # dict1.get(i,0)表示如果有键为i则返回对应的值,否则返回0
mylist=list(dict1.items())
mylist.sort(key=lambda x:(-x[1],x[0]))
dict1=dict(mylist) # 将列表转为字典
print(dict1)
元组、集合
不是重点,但是需要简单了解。
元组: 可以被列表所代替,操作与列表操作相似,唯一不同的是元组不能修改,即不能增删元素,但可以使用切片和加法进行更新。
集合: 常用于清除相同元素,但是不具备自动排序的功能。
(但是集合是具有确定性、互异性、无序性的,不要混淆了)
list1=[5,1,3,7,9,9,2]
list1=list(set(list1))
print(list1) #得到[1, 2, 3, 5, 7, 9]
# 大家看呀,这个自动升序了,但仅仅是碰巧。
print(set([1,3,8,-2,99,98,77,1,5,3,77,12])) # 得到{1, 98, 3, 99, 5, 8, 12, 77, -2}
# 大家看这个,就不会自动给你升序了,一定要注意,集合并没有自动升序排列的性质
选择结构
运行过程
这个判断到底是怎么个流程呢?我来简单说一下。
其实判断的标准是布尔值,即是False还是True,例如下面这个程序。
if '龙' in '帅帅龙':
print('good')
#运行结果是good
print('龙' in '帅帅龙') # 输出的结果是True
程序执行过程中,会先判断后面的条件代表的是True还是False
‘龙’ in ‘帅帅龙’会返回True,因此执行下面的程序
在python中,一些其他的东西也可以等价为布尔值
| 等价为True | 等价为False |
|---|---|
| 数字 1 | 数字 0 |
| 非空字符串 | 空字符串 |
| 非空列表 | 空列表 |
| 非空元组 | 空元组 |
| 非空字典(集合) | 空字典(集合) |
| None |
if 1:
print('帅帅龙')
#运行结果是帅帅龙
if – elif – else分支
编译器从上往下寻找符合条件的分支,当进入此分支后便不会再进入其他分支。
多个判断条件是,要写 if – elif – else分支语句,if 和 elif 后面要加条件,else后面不需要加条件。
如果不写成多分支而写成多个if,有时会出错,如下:
a=1
if a==1:
print('a是1')
a+=1
if a==2:
print('a是2')
# 运行结果是a是1 a是2
a=1
if a==1:
print('a是1')
a+=1
elif a==2:
print('a是2')
# 运行结果是a是1
大家可以思考一下问题出在哪里
逻辑运算符
| a and b | 当 a 和 b 都为真,才返回真。任意一个为假就返回假 |
| a or b | 当 a 和 b 任意一个为真,就返回真。全为才返回假 |
| not a | 返回和a相反的布尔值,如果a表示真,则返回假 |
循环结构
continue与break
continue:终止本层循环,继续下一层循环
break:终止循环,直接退出
for i in range(3):
if i==1:
continue
print(i)
# 结果为0 2
###########################
for i in range(3):
if i==1:
break
print(i)
# 结果为0
for 循环:常用于已知循环次数
①for i in range(x):
for 循环其实是while循环的简化形式,for循环可以做到的while也能做到。
range是一个迭代器,可以得到可迭代对象,大家可以输出这句话看看print(list ( range(10) ) )
for i in range(10):# 循环10次
print(i)
mylist=[0,1,2,3,4]
for i in range(len(mylist)):
print(mylist[i])
②for i in x:
mystr='我爱帅帅龙'
for i in mystr:
print(i)
while循环:常用于满足某个条件
形式为while + 条件判断语句。当条件返回True,则继续循环,否则结束循环。与if语句判断过程相似。
while 1: 和 while True:可以表示死循环,需要用 break 跳出循环
x=0
while x<=5:
print(x)
x+=1
#结果为0 1 2 3 4 5
while – else语句(了解一下就行)
当while语句执行完没有被中断,则会进入else语句。
如果while语句中途被中断了,则不会进入else语句。
x=0
while x<=5:
print(x)
x+=1
else:
print('进入else啦')
# 输出结果为0 1 2 3 4 5 进入else啦
###########################
x=0
while x<=5:
if x==1:
print(i)
break
print(x)
x+=1
else:
print('进入else啦')
# 输出结果为0 1
函数
函数就是把代码放在一起了,提高了代码可读性,让代码可以复用,其实很简单,不要有畏难情绪。
函数一般定义在调用之前,通常放在程序头顶
return 与 print
函数常常将结果通过return返回,当执行到函数的return语句后,函数其他部分将不会再执行。
但是函数可以没有return语句,可以直接执行输出语句,但如果想输出return的值需要用print,说的可能有点蒙了,看代码吧。
def test():
return '我爱阿龙'
print(test()) #会输出我爱阿龙
test() #啥也不会输出
###########################
def test():
print('我爱阿龙')
print(test()) #会输出我爱阿龙 和 None #因为函数并没有传递值给函数外print,所以为None
test() #会输出我爱阿龙
函数的参数
简单数据类型作为参数
def test(x):
x='我爱帅帅龙'
return x
a='富婆'
a=test(a)
print(a) # 输出为我爱帅帅龙
复杂数据类型作为参数
这里需要注意,因为复杂数据类型作为参数时是以地址进行传递的(就是C/C++的那个地址,没听说过没关系),对函数里的复杂数据类型进行操作,会直接影响原数据,应该使用ls.copy()方法(详情见下文)
def test(x):
x.append('帅哥')
return x
a=['富婆']
a=test(a)
print(a) # 输出为['富婆', '帅哥']
########################### 也可以像下面一样
def test(x):
x.append('帅哥')
a=['富婆']
test(a)
print(a) # 输出为['富婆', '帅哥']
可缺省参数
参数分为形参与实参,形参就是在定义函数是括号内的参数,实参就是调用函数的参数。
但有时候实参是不定长的,这是因为在定义函数的时候对应的形参有默认值,当你调用函数的时候省略该参数,则执行过程中该参数为默认值,这就是传说的可缺省参数。
print()中其实有end这个参数,当你不写则默认为’\n’,即输出完之后会自动输出一个换行。
def test(x='帅哥',y='富婆'):
for i in [x,y]:
print(i,end='---')
test() # 得到结果为 帅哥---富婆---,因为你不写,他就有默认值
test('帅帅') # 得到结果为 帅帅---富婆---
test('帅帅','美美') # 得到结果为 帅帅---美美---
test(y='帅帅',x='美美') # 得到结果为 美美---帅帅---,可以指定对应参数
注: 可缺省参数应放在最右面,函数调用时,参数是从左往右调用的。
global语句(了解一下)
在函数中引入全局变量,可以直接对其进行修改。
全局变量:在主程序中定义的变量,既能在一个函数中使用,也能在其他的函数中使用
局部变量:只能在一部分代码中使用,例如for i in range(3)的 i 就是局部变量
def test():
global a
a='富婆' #将a变为'富婆',这里的a,其实是主函数的a
a='我爱' # 这里的a就是全局变量
test()
print(a) # 输出为富婆
###########################
def test():
a='富婆'
a='我爱'
test()
print(a) # 输出为我爱
递归(了解一下)
递归其实就是重复调用函数的过程,递归需要可以设置结束递归的条件,有默认最大递归深度(自己可以重新设置),当你未设置时,超出最大深度会报错。递归的作用可以使用循环来达到。
下面是一个求阶乘的递归
def jiecheng(n):
if n==1:
return 1
else:
return n*jiecheng(n-1)
print(jiecheng(5)) # 得到的结果为120
当你调用这个函数时,会进入这个函数,首先判断n的值是否为1,如果为1就返回1,
不是则返回n*jiecheng(n-1),即继续往下调用函数。
本次调试中,n为5,即结果为5*jiecheng(4),而jiecheng(4)代表的是4*jiecheng(3),
即此时返回的结果由5*jiecheng(4)变为5*4*jiecheng(3),同理依次往下调用,直到结束递归,即n==1,
最后结果为5*4*3*2*1
txt文件读写
文件操作我们没考编程题,大家还是最好弄清楚考试范围(虽然一般情况老师会说学的都考)
这里其实并不难,只涉及文件的读和写,记得要用close()方法释放文件的使用权(忘了也没啥事)。
| 打开模式 | 描述 |
|---|---|
| r | 以只读的方式打开(常用) |
| w | 覆盖写,文件不存在则会创建,存在则直接覆盖(常用) |
| a | 追加写,文件不存在会创建,存在则在文档末尾追加写 |
| 读文件的方法 | 描述 |
|---|---|
| f.read() | 返回一个字符串,内容是文件全部内容 |
| f.readlines() | 返回一个列表,每一行的内容为每个元素(常用) |
| 写文件的方法 | 描述 |
|---|---|
| f.write(x) | 将字符串x写入,\n即为在文件中换行(常用) |
注: 写入的只能是字符串
写的示范
f=open('data.txt','w') # 别忘了写文件后缀名
# 如果读入的数据和看到的数据不一样,那就这样写f=open('data.txt','w',encoding='utf-8')
data=['春眠不觉晓,','处处蚊子咬。','夜来大狗熊,','看你往哪跑。']
for i in data:
f.write(i+'\n') #不加\n就全都写在一行了
f.close()
读的示范
为了读取方便,我直接使用上方代码创建名为data.txt的文件
f=open('data.txt','r') # 别忘了写文件后缀名
# 如果读入的数据和看到的数据不一样,那就这样写f=open('data.txt','r',encoding='utf-8')
data=f.readlines()
data=[i.strip() for i in data] #使用列表推导式更新data的内容,目的是为了去除换行符
for i in data:
print(i)
f.close()
# 不使用f.read()是因为返回的是一坨字符串,不方便操作
注: 文件读写主要是分析文本结构,记得把\n和\t放在写入的字符串内,否则可能不会达到你的预期效果。
一些函数
后期可以根据大家需求再添加,大家可以私戳我或者评论区留言。
.copy()浅复制(可以不做了解)
def test(x):
y=x
y+='我爱帅帅龙'
a='富婆'
test(a)
print(a) # a仍然为'富婆'
将a变为复杂数据类型(列表、字典…)的话,结果就不一样了。
def test(x):
y=x
y+=['我爱帅帅龙']
a=['富婆']
test(a)
print(a) # a变成了['富婆','我爱帅帅龙']
这是为什么呢?
原因是编译器为了节省内存,当简单数据类型传递时,只是传递的数值。但是复杂数据类型占用空间大,传递的是地址,这样节省了内存的使用,但是对复杂数据类型操作会直接改变原数据内容。
问题的解决就需要使用.copy()函数。
它会将复杂数据类型的数据复制一份给对应变量,从而达到不改变原数据的目的。
def test(x):
x=x.copy()
y=x
y+=['我爱帅帅龙']
a=['富婆']
test(a)
print(a) # a仍为['富婆']
字符串的replace方法
str.replace(old,new[,count]),返回副本,把old字符串替换为new字符串,count表示替换前几次,不写count默认为全部替换。
万能方法:mystr=mystr.replace(old,new,1)
对后面内容感兴趣的同学可以看看,不感兴趣可以跳过了
mystr='112'
mystr.replace('1','2')
print(mysrt) # 得到的结果仍为112
为什么失效了呢?其实只是我们的使用方法不对,因为replace返回的是原字符串副本,
上面已经说过副本这个概念了,即不会对原数据造成影响,因此直接写mystr.replace并不会修改原字符串
修改后的代码如下:
mystr='112'
mystr=mystr.replace('1','2')
print(mysrt) # 得到的结果为222
题目要求: 将字符串中字母替换为空格
a='df23A?45cde0@a' # 这个测试数据有没有感觉很熟悉?? 没有当我没说哈。
for i in a:
if not ('a'<=i<='z' or 'A'<=i<='Z'):
a=a.replace(i,' ')
print(a) # 结果为df A cde a
直接傻用replace会不会把数据弄脏呢,会也不会,来看代码。(强烈建议大家不要看,记住万能公式就好了)
# 把2替换为1
a='21122'
for i in a: # 因为字符串是简单数据类型,其实这里等价于for i in '21122':
print(i)
if i=='2':
print(a)
a=a.replace('2','1') #因为我没写count,因此,他会把所有的2都替换掉
# i依次输出为2 1 1 2 2
# a依次输出为21122 11111 11111
# 因为循环的时候,其实程序已经确定好i依次代表什么了,因此更新a,不会影响程序
isinstance()判断数据格式
type判断一个变量是什么类型不太方便,于是就有了isinstance()这个函数,它会返回布尔值。
a=1
print(isinstance(a,int)) # 输出结果为True
注:也可以使用type(x) is xxx
a=1
print(type(a) is int) #或者写成type(a)==int
Python标准库
引入方式
import math
引入数学库,可以调用数学库的函数
import math
print(math.pow(2,3)) # 得到8.0
from math import pow
从数学库中引入pow函数,不引入其他函数
from math import pow
print(pow(2,3)) # 得到8.0。注意,少了math.
#但是使用其他函数会报错
print(abs(-3)) # 会报错
import random as ra
有的时候函数或库的名字太长,我们可以给它重新起个名字
从数学库引入pow函数,并且改名为p,在使用的时候
import random as ra
print(ra.randint(10,100)) # 产生10到100的随机整数
类似的写法还有from random import randint as rant
即,引入randint函数,名且重命名为rant…
from math import *
从数学库中引入所有函数
import math
print(pow(2,3)) # 得到8.0。注意,少了math.
print(abs(-3)) # 得到3
math库
首先要在程序开头引入数学库。使用方法:import math
| 常用函数 | 描述 |
|---|---|
| abs(x) | 得到x的绝对值 |
| pow(x,y) | 得到x的y次幂,返回浮点型 |
| sqrt(x) | 将x开平方,也可以直接x**(1/2) |
| pi、e | 得到精确数值π、e |
random库
| 常用函数 | 描述 |
|---|---|
| seed(x) | 当x确定时,产生随机数的顺序其实已经确定了 |
| randint(a,b) | 生成[a,b]之间的随机整数(这里是两个闭区间!) |
| choice(seq) | 从序列类型seq中随机选取一个元素 |
| shuffle(seq) | 将序列类型seq随机打乱 |
| random() | 生成[0.0,1.0)之间的随机小数 |
| uniform(a,b) | 生成[a,b]之间的随机小数(这里是两个闭区间!) |

from random import *
seed(10) #当seed一定时,产生随机数的顺序就一定了!
a=int(input('n:'))
mylist=[]
for i in range(a):
mylist.append(randint(100,200))
mylist.sort()
for i in mylist:
print(i)
关于seed,大家有兴趣可以去百度详细了解一下编程语言中seed到底是个啥子东西。
可以简单理解为:每个人的长相不同,就比如我,可能就有几分姿色,但是有个叫刘浩的就可能不如我有魅力,即不同的人颜值不同,但是只要你选定了这个人,它的颜值就是一定的。
在随机数中,当seed确定了,随机数的顺序也就随之确定了,就像你选中一个人时,他的颜值就已经确定了。
严谨点来说:计算机的随机数都是由伪随机数(即不是严格意义上的随机),是由小M多项式序列生成的,其中产生每个小序列都有一个初始值,即随机种子:小M多项式序列,当初始值确定了,生成的序列就确定了!
jieba库(不作重点)
| 常用函数 | 描述 |
|---|---|
| jieba.lcut(s) | 将字符串分词,返回一个列表 |
| jieba.lcut(s , cut_all=True) | 全模式,返回字符串中字可能组成的所有词 |
| jieba.add(s) | 在词库中添加词语 s |
time库
| 常用函数 | 描述 |
|---|---|
| sleep(x) | 程序暂停x秒,常用在循环里 |
一些编程技巧
IDE的选择
好的IDE是成功的一半,大部分下载的IDE都有代码自动补全的功能、错误警告、会自动联想对应的函数和变量的功能,十分方便。
大家如果还在使用python自带的IDE,不妨输入’pr’再按一下键盘的Tab键,你可能会有新发现哦。
建议一:使用spyder编译器。
理由一:下载方便,直接百度搜索Anaconda进入官网即可下载。
理由二:不需要配置自己编译器
理由三:许多第三方库都是Anaconda自带的,不需要额外安装
建议二:使用pycharm编译器。
理由一:长的好看
理由二:无
理由三:无
注: 如果只是为了考试,可以去官网下载社区版,这个足够用了。如果想体验专业版何以去官网用学生邮箱注册,还可以去微信公众号:软件安装管家处白嫖破解版。
判断一个字符串中有几个小写字母
有的时候记不住字符串那么多判断方法怎么办?没关系,其实可以直接进行比较。
a='aAfSSaDhQoTn'
count=0
for i in a:
if 'a'<=i<='z': # 因为比较的时候比较的是ASCII码(小写字母比大写字母大,可以输入ord('a')查看)
count+=1
print(count) # 结果为6
判断一个数是不是素数
def sushu(n):
for i in range(2,n): # 这是无脑的写法,大家也可写成for i in range(2,int(n**(1/2))+1):
if n%i==0:
return False
return True
a=int(input('输入一个数:'))
print(sushu(a))
flag的小应用
有时候,通过可以设置flag来达到条件判断的目的。
问题描述: 判断一个字符串中有没有数字
flag=False
mystr='fahu57486sge'
for i in mystr:
if '0'<=i<='9':
flag=True
if flag:
print('有')
else:
print('没有')
还可以通过设置多个flag来达到判断密码强度的作用。
广阔天地,大有作为,我在这里抛砖引玉,快发动你的小脑筋吧。
两套编程考试题
点击这里 下载,压缩包的内容包括:
2019冬python期末考试(非信院)——>三道编程题,一道程序填空(本来考试是两道的,但我找不到另外一个了)
2020春python期末考试(非信院)——>五道编程题,附加参考代码
结语
预祝大家期末好成绩✔
??????????????????????????????????????????????
我爱你
帅帅龙
??????????????????????????????????????????????
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/134337.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
