大家好,又见面了,我是你们的朋友全栈君。
Python新手写出漂亮的爬虫代码1
初到大数据学习圈子的同学可能对爬虫都有所耳闻,会觉得是一个高大上的东西,仿佛九阳神功和乾坤大挪移一样,和别人说“老子会爬虫”,就感觉特别有逼格,但是又不知从何入手,这里,博主给大家纠正一个误区:爬虫并不神秘,也不高级,是一个非常好上手和掌握的东西(当然,里面也有很多坑,也有很多细节,展开说的话其实也蛮复杂的,不过它的模式和套路就摆在那里,看了小编的博客,保证你能爬下你想要的内容)。
一般情况下,爬虫分为两种,一种是静态爬虫,一种是动态爬虫,所谓静态爬虫,就是大部分信息(至少你所需要的那些信息)是写在html代码中的,而动态爬虫一般都是写在一个json文档中,这么说可能不太标准,不过初学者这样理解即可,这篇博客将会带大家领略静态爬虫,下一篇将会讲解动态爬虫。
补充一句,博主曾是忠实的Python2用户,不过现在也改到Python3了,曾经新的库会在Python2中首先兼容,然后要过好久才在Python3中集成,现在完全不用担心,Python2有了,Python3不日就会集成,Python3也会在编码方面提供更多遍历,推荐新手直接从Python3入手,当然,二者没有什么太大区别,遇到问题问问度娘就可以了了,废话不多说,我们开始爬虫的第一课!
本篇博文将从以下几个方面进行讲解
– 啥是Html代码?
– 怎么从Html代码中定位到我要的东西?
– BeautifulSoup神器
– 案例:爱卡汽车
啥是Html代码
所谓的html代码,浏览博客的你右手一定在鼠标上,好的,跟着我左手右手一个慢动作,点击右键,找到“查看网页源代码”,不同浏览器可能这个描述不太一样,博主是Chrome,不过都差不太多,是不是有看到类似下面这个图的一堆不知道是什么鬼的代码?


其实,你可以按键盘上的F12或者右键选择“检查元素”(不同浏览器不同),这时,浏览器的右侧(如果你是360浏览器,可能是在下方)弹出一个东东,类似下面红色框中的区域
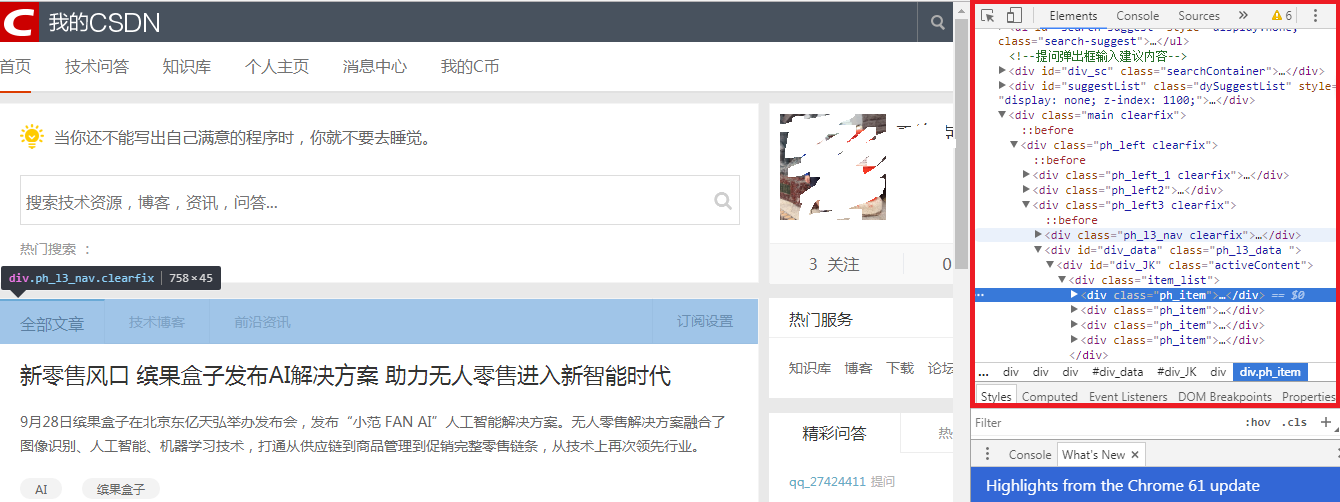
这个东西就是刚才我们看的那个不知道是什么鬼的东西的树状结构,看上去会整齐一些。这就是html代码,html代码其实就是用许多个"<Y yy='aaa'>xxxx</Y>"是的结构将想要输出在页面上的内容包含起来的一种语言。下一个小节将详细介绍这个结构,总而言之,我们肉眼所看到的东西大部分都来自于html代码,html代码的作用简单来说就是程序员用一堆html代码,将需要展示的信息放在指定的位置上的一种东西,有了html代码,才有了你眼前页面上的很多元素;当然,还有其他方式来将元素展示在页面上,如css、js等渲染方式,这些我们下一篇会介绍。
知道我们所需要的信息位于html中,那么只需要找到我们需要的具体内容在哪里,然后下载下来,就大功告成了,逻辑就是这么个逻辑,所以静态爬虫的关键问题是要准确的解析html代码,一般使用BeautifulSoup这个库或者正则表达式。
怎么从Html代码中定位到我要的东西
标签
上一节中提到,html代码中都是"<Y yy='aaa'>xxxx</Y>"结构,一对”<>”我们称之为标签,这对标签中通常会有一些内容,可能是一个数字,一段字符串,一个网页链接,或者一个图片链接等等,总之,就是我们在网页上看到的内容。”Y”称之为标签名,”yy”为其属性名,”aaa”是其属性值,”xxxx”是这个标签的内容,也就是对应于页面上的信息。一般情况下我们要获取的就是”xxxx”,有时我们可能也需要获取标签的属性值”aaa”。标签可能是唯一的,也可能是有重复的,回看刚才那张树状的标签结构,有一种分明的层次感,同一层的标签我们称他们互为兄弟标签,而一个标签和包含他的标签互为父子标签,如果a包含b,b包含c,d,则c是a的后代标签,是b的子标签,是d的兄弟标签,这个名字无所谓的,了解一下就好,一般标签名可能会重复,但标签属性名(yy)和属性值“aaa”很少重复,不过兄弟标签之间可能会出现标签名、属性名、属性值完全相同的情况,后面会介绍(就是find方法和findAll方法的区别)。
好,上实例,打开一个网址把:http://newcar.xcar.com.cn/257/review/0.htm,是爱卡汽车中比亚迪F3的口碑页面,鼠标右键选择“检查元素”或者之间按键盘上的F12,选择那个鼠标的按钮(红色框1),然后将鼠标放到评论框附近(红色框2),如下图所示,看到检查元素界面中有一段代码背景色变成了深色(如红色框3)
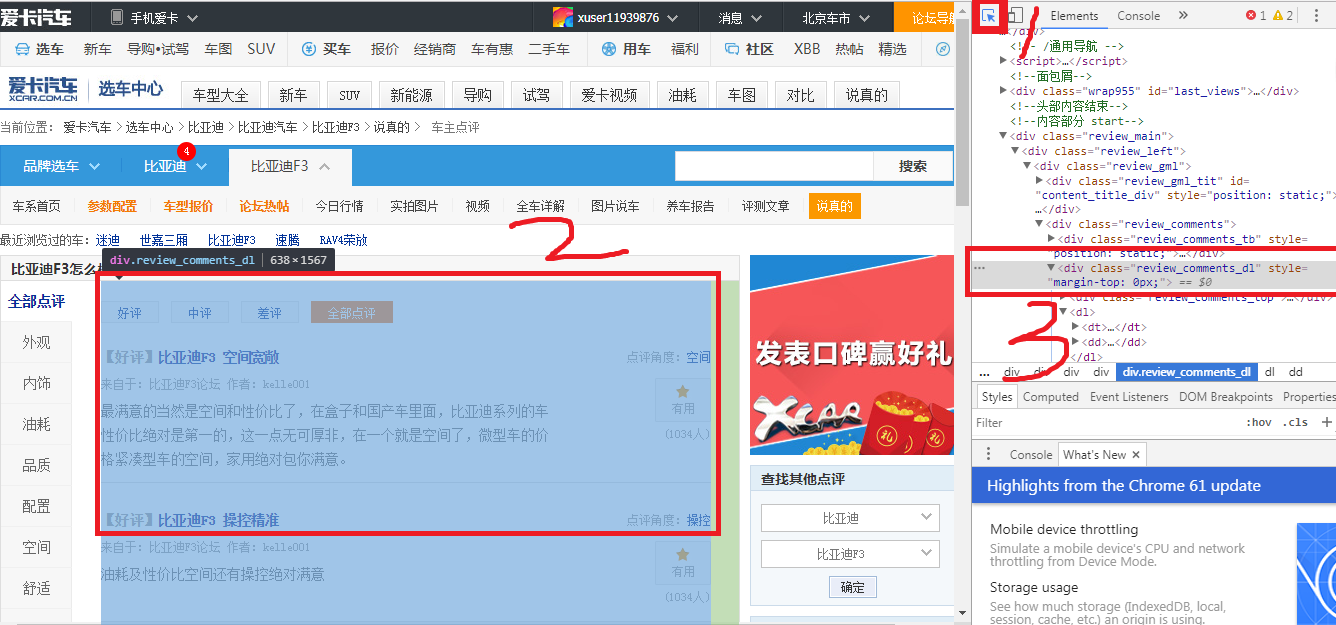
每个页面有10条口碑,可见这10条口碑均存储在属性名为’class’,属性值为’review_comments_dl’的’div’标签中,当然,这个标签不是一个“叶节点”,也就是说这个标签内部还有其他标签,我们进一步看看。看下面的图片。
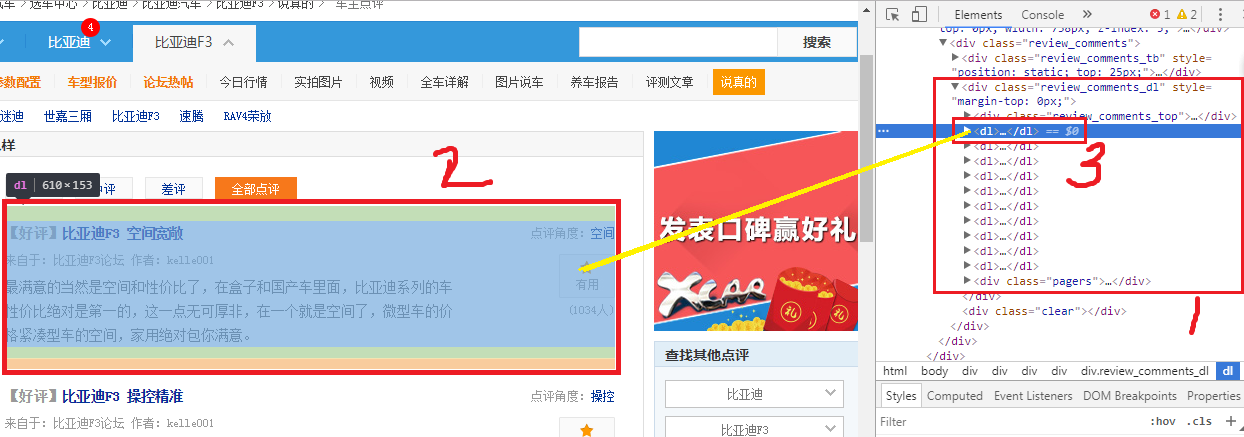
我们可以看到红框3中有很多相同的标签<dl>...</dl>,他们都是属性名为’class’,属性值为’review_comments_dl’的’div’标签的子标签,他们之间互为兄弟标签,我们把鼠标放在红框3的位置并选中,这时左侧网页的第一条口碑的位置就会变成深色背景,也就是说,红框3这个标签实际上对应着红框2这个区域中的内容,那么我们把红框3再具体的看一看。如下图所示。
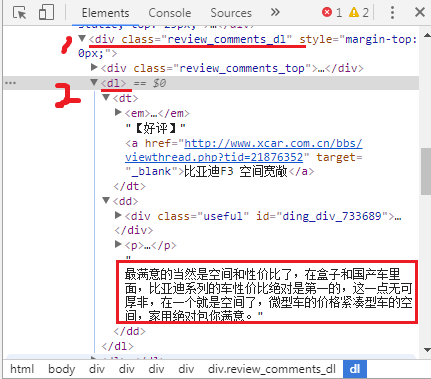
可以看到,第一条口碑(红框中的内容)在第一个’dl’标签中(红色下划线2),同理可以看到第二条口碑在第二个’dl’标签中。再来看看这个’dl’标签,他有两个子标签,’dt’和’dd’子标签,口碑数据位于dd子标签下;好的,再来看’dd’标签,将’dd’标签展开,如下图所示。
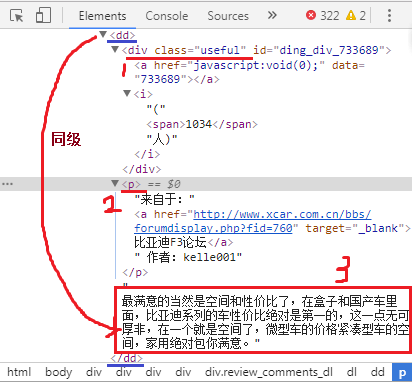
红框3是该车的第一页的第一条口碑,位于dd标签中,及图中蓝色下划线<dd>...</dd> 中的内容,图中从开头的dd指向红框3,标注了“同级”,意思是红框3的内容是dd标签的内容,而dd标签下还有子标签,比如属性为class,属性值为useful的div标签,里面的内容1034是有多少人觉得这个口碑有用;还有一个子标签p,p标签的内容是口碑的作者;p中有一个子标签a,a标签的内容是评论来源,如图中的“比亚迪F3论坛”。
好了,现在想必读者已经对通过标签定位信息有所了解了,我们再来练习一下,我们将口碑页切换到第2页,可以看到地址变成了http://newcar.xcar.com.cn/257/review/0/0_2.htm,多了一个’0_2’。将’0_2’改成’0_1’就跳回了第一页(实际上第一页的真实url是http://newcar.xcar.com.cn/257/review/0/0_1.htm),而改成’0_3’就到了第三页。那么我们应该怎么获取该车型的口碑一共有几页呢?看下面的图。
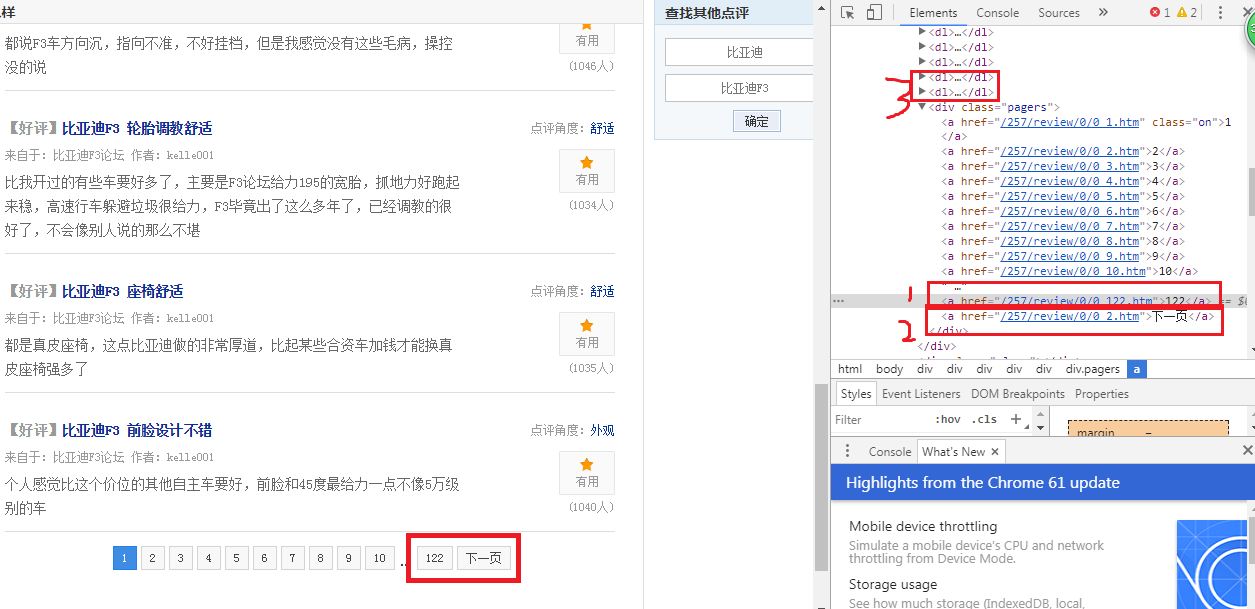
依然是在开发者工具视角(及按F12弹出的窗口这个视角),将鼠标放在尾页(这里是122)或者‘下一页’上,右侧的框中会出现如图所示的画面,可以看到尾页122所在的位于属性为class,属性值为’pagers’的div标签的倒数第二个子标签中,如红框1所示;而’下一页’则位于属性为class,属性值为’pagers’的div标签的最后一个子标签中,如红框2所示。在仔细贯彻一下会发现属性为class,属性值为’pagers’的div标签与我们之前寻找口碑的标签dl是兄弟标签,位于全部的dl标签的再后面一个,也就是说,该标签的父标签与dl标签相同,即属性名为’class’,属性值为’review_comments_dl’的’div’标签。
为什么要确定尾页呢?因为构造代码时,我们要知道代码的起止位置,使用for循环良好的控制代码的开始与完结。
这个爬虫的逻辑是这样的:找到目标的车型,即其url,实际上,不同车型的url只有id不同,比如比亚迪F3的url是http://newcar.xcar.com.cn/257/,其车子id是257,当id更改为258时,车型就变成了比亚迪F0;然后查看html代码,明确要爬取的内容的所在位置,明确换页规律,明确爬虫的起止位置(获取尾页信息的html位置),然后构造代码。
BeautifulSoup神器
Python一个第三方库bs4中有一个BeautifulSoup库,是用于解析html代码的,换句话说就是可以帮助你更方便的通过标签定位你需要的信息。这里只介绍两个比较关键的方法:
1、find方法和findAll方法:
首先,BeautifulSoup会先将整个html或者你所指定的html代码编程一个BeautifulSoup对象的实例(不懂对象和实例不要紧,你只要把它当作是一套你使用F12看到的树形html代码代码就好),这个实例可以使用很多方法,最常用的就是find和findAll,二者的功能是相同的,通过find( )的参数,即find( )括号中指定的标签名,属性名,属性值去搜索对应的标签,并获取它,不过find只获取搜索到的第一个标签,而findAll将会获取搜索到的所有符合条件的标签,放入一个迭代器(实际上是将所有符合条件的标签放入一个list),findAll常用于兄弟标签的定位,如刚才定位口碑信息,口碑都在dl标签下,而同一页的10条口碑对应于10个dl标签,这时候用find方法只能获取第一个,而findAll会获取全部的10个标签,存入一个列表,想要获取每个标签的内容,只需对这个列表使用一个for循环遍历一遍即可。
2、get_text()方法:
使用find获取的内容不仅仅是我们需要的内容,而且包括标签名、属性名、属性值等,比如使用find方法获取"<Y yy='aaa'>xxxx</Y>" 的内容xxxx,使用find后,我们会得到整个"<Y yy='aaa'>xxxx</Y>",十分冗长,实际我们想要的仅仅是这个标签的内容xxxx,因此,对使用find方法后的对象再使用get_text( )方法,就可以得到标签的内容了,对应到这里,我们通过get_text( )方法就可以得到xxxx了。
好了,铺垫做的差不多了,上代码咯~~~
案例:爱卡汽车
使用Python3,需要提前安装bs4库,博主的环境是win7+Python3+Pycharm(有时候也用Ubuntu16.04+Python3+Pycharm),很多时候都有人问博主,什么ide好用呢?jupyter notebook?spyder?Pycharm?这里只能和大家说各个ide各有千秋,做工程(如爬虫)使用pycharm肯定是首选,如果只是平时的练习,写个小程序,使用jupyter notebook和spyder就不错,总之,如果涉及到频繁打印输出结果的东西,最好还是用pycharm,不要用jupyter notebook,不然会很卡。
言归正传,上代码!
两点说明:爬虫代码中,html代码经常会出现’class’这个属性名,而class是python中“类”的关键字,而爬虫的find方法对于属性名而言,是不需要加引号的,如果直接输入class是会出现问题的,所以需要注意,每次输入class时应当输入为class_,即class后加一个下划线;
第二就是下方代码一开始有一个add_header的过程,为的是将代码伪装成浏览器。很多网站是反对爬虫程序对其信息进行爬取的,所以会禁止一些程序访问他们的网站,通过add_header将你的爬虫程序伪装成了浏览器,故在网站看来,访问它的就不是一个程序,而是一个浏览器,或者说是一个人类用户了。
import urllib
import urllib.request
from bs4 import BeautifulSoup
import re
import random
import time
# 设置目标url,使用urllib.request.Request创建请求
url0 = "http://newcar.xcar.com.cn/257/review/0.htm"
req0 = urllib.request.Request(url0)
# 使用add_header设置请求头,将代码伪装成浏览器
req0.add_header("User-Agent","Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36")
# 使用urllib.request.urlopen打开页面,使用read方法保存html代码
html0 = urllib.request.urlopen(req0).read()
# 使用BeautifulSoup创建html代码的BeautifulSoup实例,存为soup0
soup0 = BeautifulSoup(html0)
# 获取尾页(对照前一小节获取尾页的内容看你就明白了)
total_page = int(soup0.find("div",class_= "pagers").findAll("a")[-2].get_text())
myfile = open("aika_qc_gn_1_1_1.txt","a")
print("user","来源","认为有用人数","类型","评论时间","comment",sep="|",file=myfile)
for i in list(range(1,total_page+1)):
# 设置随机暂停时间
stop = random.uniform(1, 3)
url = "http://newcar.xcar.com.cn/257/review/0/0_" + str(i) + ".htm"
req = urllib.request.Request(url)
req.add_header("User-Agent","Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36")
html = urllib.request.urlopen(req).read()
soup = BeautifulSoup(html)
contents = soup.find('div', class_="review_comments").findAll("dl")
l = len(contents)
for content in contents:
tiaoshu = contents.index(content)
try:
ss = "正在爬取第%d页的第%d的评论,网址为%s" % (i, tiaoshu + 1, url)
print(ss)
try:
comment_jiaodu = content.find("dt").find("em").find("a").get_text().strip().replace("\n","").replace("\t","").replace("\r","")
except:
comment_jiaodu = ""
try:
comment_type0 = content.find("dt").get_text().strip().replace("\n","").replace("\t","").replace("\r","")
comment_type1 = comment_type0.split("【")[1]
comment_type = comment_type1.split("】")[0]
except:
comment_type = "好评"
# 认为该条评价有用的人数
try:
useful = int(content.find("dd").find("div",class_ = "useful").find("i").find("span").get_text().strip().replace("\n","").replace("\t","").replace("\r",""))
except:
useful = ""
# 评论来源
try:
comment_region = content.find("dd").find("p").find("a").get_text().strip().replace("\n","").replace("\t","").replace("\r","")
except:
comment_region = ""
# 评论者名称
try:
user = content.find("dd").find("p").get_text().strip().replace("\n","").replace("\t","").replace("\r","").split(":")[-1]
except:
user = ""
# 评论内容
try:
comment_url = content.find('dt').findAll('a')[-1]['href']
urlc = comment_url
reqc = urllib.request.Request(urlc)
reqc.add_header("User-Agent",
"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36")
htmlc = urllib.request.urlopen(reqc).read()
soupc = BeautifulSoup(htmlc)
comment0 = \
soupc.find('div', id='mainNew').find('div', class_='maintable').findAll('form')[1].find('table',class_='t_msg').findAll('tr')[1]
try:
comment = comment0.find('font').get_text().strip().replace("\n", "").replace("\t", "")
except:
comment = ""
try:
comment_time = soupc.find('div', id='mainNew').find('div', class_='maintable').findAll('form')[1].find('table', class_='t_msg').\
find('div', style='padding-top: 4px;float:left').get_text().strip().replace("\n","").replace( "\t", "")[4:]
except:
comment_time = ""
except:
try:
comment = content.find("dd").get_text().split("\n")[-1].split('\r')[-1].strip().replace("\n", "").replace("\t","").replace("\r", "").split(":")[-1]
except:
comment = ""
# time.sleep(stop)
print(user,comment_region,useful,comment_type,comment_time,comment, sep="|", file=myfile)
except:
s = "爬取第%d页的第%d的评论失败,网址为%s" % (i, tiaoshu + 1, url)
print(s)
pass
myfile.close()补充说明一下:try——except这个结构(看起来有点像if——else的结构)是一个非常重要的过程,为了使爬虫代码可以良好的运行,不至于刚开始爬几分钟就报错这种恶心人的情况,需要很好的利用try——except过程。程序会先执行try下的语句,如果发生失败,就会执行except下的语句,你也可以使用多个try——except嵌套的结构完成复杂的情况的覆盖,最好要保证你的try——except过程包含了程序会遇到的所有情况,那么你的代码就是趋于完美的。
讲到这里,第一节爬虫课程也就到这里了,不久之后会介绍动态爬虫,如果之后还有时间,还会介绍一下selenium这个模拟浏览的库,以及爬虫框架还有反爬虫的知识,给自己打个广告,除了爬虫可,近期也会分享一些关于word2vec和fastText文本分类算法的内容,读者有什么其他想交流的可以留言~我也是个正在学习路上的仔,希望能和各路朋友以及大牛交流。
目录
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/134192.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
