大家好,又见面了,我是你们的朋友全栈君。
原帖地址: http://blog.csdn.net/nsrainbow/article/details/41748863 最新课程请关注原作者博客
声明
- 本文基于Centos 6.x + CDH 5.x
Hive是什么
Hive 提供了一个让大家可以使用sql去查询数据的途径。让大家可以在hadoop上写sql语句。但是最好不要拿Hive进行实时的查询。因为Hive的实现原理是把sql语句转化为多个Map Reduce任务所以Hive非常慢,官方文档说Hive 适用于高延时性的场景而且很费资源。
举个简单的例子,可以像这样去查询
hive> select * from h_employee;
OK
1 1 peter
2 2 paul
Time taken: 9.289 seconds, Fetched: 2 row(s) 这个h_employee不一定是一个数据库表,有可能只是一个针对csv文件的元数据映射。
Hive 安装
相比起很多教程先介绍概念,我喜欢先动手装上,然后用例子来介绍概念。我们先来安装一下Hive
先确认是否已经安装了对应的yum源,如果没有照这个教程里面写的安装cdh的yum源http://blog.csdn.net/nsrainbow/article/details/36629339
hive 基本包
yum install hive -y
hive metastore
yum install hive-metastore
hive服务端
yum install hive-server2 -y如果要跟hbase通讯就安装 hive-hbase
yum install hive-hbase -y
Hive metastore 服务
3种模式
内置存储模式
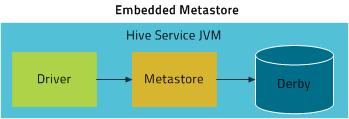

本地存储模式
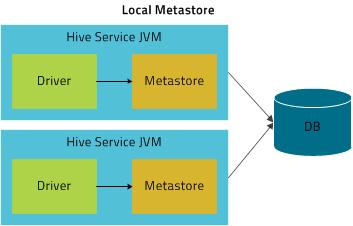
远程模式
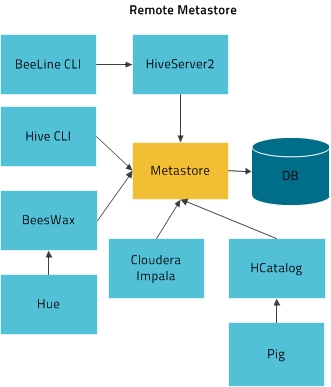
使用mysql作为metastore数据库
安装mysql
yum install mysql-server启动服务
service mysqld start添加到自启动
chkconfig mysqld on初始化mysql的一些参数,比如root用户的密码等
$ sudo /usr/bin/mysql_secure_installation
[...]
Enter current password for root (enter for none):
OK, successfully used password, moving on...
[...]
Set root password? [Y/n] y
New password:
Re-enter new password:
Remove anonymous users? [Y/n] Y
[...]
Disallow root login remotely? [Y/n] N
[...]
Remove test database and access to it [Y/n] Y
[...]
Reload privilege tables now? [Y/n] Y
All done!安装mysql JDBC驱动
$ sudo yum install mysql-connector-java
$ ln -s /usr/share/java/mysql-connector-java.jar /usr/lib/hive/lib/mysql-connector-java.jar第二步是把驱动建立一个软链到hive的lib库里面,让hive可以加载
创建metastore需要的用户和库
$ mysql -u root -p
Enter password:
mysql> CREATE DATABASE metastore;
mysql> USE metastore;
mysql> SOURCE /usr/lib/hive/scripts/metastore/upgrade/mysql/hive-schema-0.13.0.mysql.sql;创建hive用户
mysql> CREATE USER 'hive'@'metastorehost' IDENTIFIED BY 'mypassword';
...
mysql> REVOKE ALL PRIVILEGES, GRANT OPTION FROM 'hive'@'metastorehost';
mysql> GRANT ALL PRIVILEGES ON metastore.* TO 'hive'@'metastorehost';
mysql> FLUSH PRIVILEGES;
这边metastorehost换成你metastore的机器的host名字,mypassword换成你想设定的密码
在本例子中是这样
mysql> CREATE USER 'hive'@'%' IDENTIFIED BY 'hive';mysql> REVOKE ALL PRIVILEGES, GRANT OPTION FROM 'hive'@'%';mysql> GRANT ALL PRIVILEGES ON metastore.* TO 'hive'@'%';mysql> FLUSH PRIVILEGES;mysql> quit;
配置hive
- 假设你安装mysql的机器名叫host1,在 javax.jdo.option.ConnectionURL 中配置上jdbc连接
- hive.metastore.uris 这个参数必须用ip,不懂为什么
- hive.metastore.schema.verification 官方建议用true,官方说新旧版本的hive数据结构差别很大,要打开验证,免得出错
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://host1/metastore</value>
<description>the URL of the MySQL database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hive</value>
</property>
<property>
<name>datanucleus.autoCreateSchema</name>
<value>false</value>
</property>
<property>
<name>datanucleus.fixedDatastore</name>
<value>true</value>
</property>
<property>
<name>datanucleus.autoStartMechanism</name>
<value>SchemaTable</value>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://192.168.199.126:9083</value>
<description>IP address (or fully-qualified domain name) and port of the metastore host</description>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>true</value>
</property>
</configuration>
配置HiveServer2
<property>
<name>hive.support.concurrency</name>
<description>Enable Hive's Table Lock Manager Service</description>
<value>true</value>
</property>
<property>
<name>hive.zookeeper.quorum</name>
<description>Zookeeper quorum used by Hive's Table Lock Manager</description>
<value>host1,host2</value>
</property>如果你修改了zookeeper 的默认端口就增加或修改这个属性
<property> <name>hive.zookeeper.client.port</name> <value>2222</value> <description> The port at which the clients will connect. </description></property>
启动服务
service hive-metastore start
service hive-server2 start启动的时候遇到问题
Starting Hive Metastore Server
Error creating temp dir in hadoop.tmp.dir /data/hdfs/tmp due to Permission denied给 /tmp 文件夹一个写权限就好了
cd /data/hdfschmod a+rwx tmp
测试是否安装成功
$ hivehive>hive> show tables;OKTime taken: 10.345 secondsHive使用
metastore
Hive 中建立的表都叫metastore表。这些表并不真实的存储数据,而是定义真实数据跟hive之间的映射,就像传统数据库中表的meta信息,所以叫做metastore。实际存储的时候可以定义的存储模式有四种:
- 内部表(默认)
- 分区表
- 桶表
- 外部表
CREATE TABLE worker(id INT, name STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\054';这个语句的意思是建立一个worker的内部表,内部表是默认的类型,所以不用写存储的模式。并且使用逗号作为分隔符存储
建表语句支持的类型
tinyint / smalint / int /bigint
float / double
boolean
string
Array/Map/Struct
建完的表存在哪里呢?
$ hdfs dfs -ls /user/hive/warehouse
Found 11 items
drwxrwxrwt - root supergroup 0 2014-12-02 14:42 /user/hive/warehouse/h_employee
drwxrwxrwt - root supergroup 0 2014-12-02 14:42 /user/hive/warehouse/h_employee2
drwxrwxrwt - wlsuser supergroup 0 2014-12-04 17:21 /user/hive/warehouse/h_employee_export
drwxrwxrwt - root supergroup 0 2014-08-18 09:20 /user/hive/warehouse/h_http_access_logs
drwxrwxrwt - root supergroup 0 2014-06-30 10:15 /user/hive/warehouse/hbase_apache_access_log
drwxrwxrwt - username supergroup 0 2014-06-27 17:48 /user/hive/warehouse/hbase_table_1
drwxrwxrwt - username supergroup 0 2014-06-30 09:21 /user/hive/warehouse/hbase_table_2
drwxrwxrwt - username supergroup 0 2014-06-30 09:43 /user/hive/warehouse/hive_apache_accesslog
drwxrwxrwt - root supergroup 0 2014-12-02 15:12 /user/hive/warehouse/hive_employee一个文件夹对应一个metastore表
Hive 各种类型表使用
内部表
CREATE TABLE workers( id INT, name STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\054';通过这样的语句就建立了一个内部表叫 workers,并且分隔符是逗号, \054 是ASCII 码
hive> show tables;OKh_employeeh_employee2h_employee_exporth_http_access_logshive_employeeworkersTime taken: 0.371 seconds, Fetched: 6 row(s)
- 从文件读取数据
- 从别的表读出数据插入(insert from select)
$ cat workers.csv1,jack2,terry3,michael用LOAD DATA 导入到Hive的表中
hive> LOAD DATA LOCAL INPATH '/home/alex/workers.csv' INTO TABLE workers;Copying data from file:/home/alex/workers.csvCopying file: file:/home/alex/workers.csvLoading data to table default.workersTable default.workers stats: [num_partitions: 0, num_files: 1, num_rows: 0, total_size: 25, raw_data_size: 0]OKTime taken: 0.655 seconds
注意
- 不要少了那个 LOCAL , LOAD DATA LOCAL INPATH 跟 LOAD DATA INPATH 的区别是一个是从你本地磁盘上找源文件,一个是从hdfs上找文件
- 如果加上OVERWRITE可以再导入之前先清空表,比如 LOAD DATA LOCAL INPATH ‘/home/alex/workers.csv’ OVERWRITE INTO TABLE workers;
hive> select * from workers;
OK
1 jack
2 terry
3 michael
Time taken: 0.177 seconds, Fetched: 3 row(s)我们去看下导入后在hive内部表是怎么存的
# hdfs dfs -ls /user/hive/warehouse/workers/Found 1 items-rwxrwxrwt 2 root supergroup 25 2014-12-08 15:23 /user/hive/warehouse/workers/workers.csv原来就是原封不动的把文件拷贝进去啊!就是这么土!
# cat workers2.txt 4,peter5,kate6,ted导入
hive> LOAD DATA LOCAL INPATH '/home/alex/workers2.txt' INTO TABLE workers;Copying data from file:/home/alex/workers2.txtCopying file: file:/home/alex/workers2.txtLoading data to table default.workersTable default.workers stats: [num_partitions: 0, num_files: 2, num_rows: 0, total_size: 46, raw_data_size: 0]OKTime taken: 0.79 seconds去看下文件的存储结构
# hdfs dfs -ls /user/hive/warehouse/workers/Found 2 items-rwxrwxrwt 2 root supergroup 25 2014-12-08 15:23 /user/hive/warehouse/workers/workers.csv-rwxrwxrwt 2 root supergroup 21 2014-12-08 15:29 /user/hive/warehouse/workers/workers2.txt多出来一个workers2.txt
hive> select * from workers;OK1 jack2 terry3 michael4 peter5 kate6 tedTime taken: 0.144 seconds, Fetched: 6 row(s)
分区表
create table partition_employee(id int, name string)
partitioned by(daytime string)
row format delimited fields TERMINATED BY '\054';可以看到分区的属性,并不是任何一个列
# cat 2014-05-0522,kitty33,lily# cat 2014-05-0614,sami45,micky导入到分区表里面
hive> LOAD DATA LOCAL INPATH '/home/alex/2014-05-05' INTO TABLE partition_employee partition(daytime='2014-05-05');Copying data from file:/home/alex/2014-05-05Copying file: file:/home/alex/2014-05-05Loading data to table default.partition_employee partition (daytime=2014-05-05)Partition default.partition_employee{daytime=2014-05-05} stats: [num_files: 1, num_rows: 0, total_size: 21, raw_data_size: 0]Table default.partition_employee stats: [num_partitions: 1, num_files: 1, num_rows: 0, total_size: 21, raw_data_size: 0]OKTime taken: 1.154 secondshive> LOAD DATA LOCAL INPATH '/home/alex/2014-05-06' INTO TABLE partition_employee partition(daytime='2014-05-06');Copying data from file:/home/alex/2014-05-06Copying file: file:/home/alex/2014-05-06Loading data to table default.partition_employee partition (daytime=2014-05-06)Partition default.partition_employee{daytime=2014-05-06} stats: [num_files: 1, num_rows: 0, total_size: 21, raw_data_size: 0]Table default.partition_employee stats: [num_partitions: 2, num_files: 2, num_rows: 0, total_size: 42, raw_data_size: 0]OKTime taken: 0.763 seconds导入的时候通过 partition 来指定分区。
hive> select * from partition_employee where daytime='2014-05-05';OK22 kitty 2014-05-0533 lily 2014-05-05Time taken: 0.173 seconds, Fetched: 2 row(s)我的查询语句并没有什么特别的语法,hive 会自动判断你的where语句中是否包含分区的字段。而且可以使用大于小于等运算符
hive> select * from partition_employee where daytime>='2014-05-05';OK22 kitty 2014-05-0533 lily 2014-05-0514 sami 2014-05-0645 mick' 2014-05-06Time taken: 0.273 seconds, Fetched: 4 row(s)我们去看看存储的结构
# hdfs dfs -ls /user/hive/warehouse/partition_employeeFound 2 itemsdrwxrwxrwt - root supergroup 0 2014-12-08 15:57 /user/hive/warehouse/partition_employee/daytime=2014-05-05drwxrwxrwt - root supergroup 0 2014-12-08 15:57 /user/hive/warehouse/partition_employee/daytime=2014-05-06我们试试二维的分区表
create table p_student(id int, name string) partitioned by(daytime string,country string) row format delimited fields TERMINATED BY '\054'; 查入一些数据
# cat 2014-09-09-CN
1,tammy
2,eric
# cat 2014-09-10-CN
3,paul
4,jolly
# cat 2014-09-10-EN
44,ivan
66,billy导入hive
hive> LOAD DATA LOCAL INPATH '/home/alex/2014-09-09-CN' INTO TABLE p_student partition(daytime='2014-09-09',country='CN');Copying data from file:/home/alex/2014-09-09-CNCopying file: file:/home/alex/2014-09-09-CNLoading data to table default.p_student partition (daytime=2014-09-09, country=CN)Partition default.p_student{daytime=2014-09-09, country=CN} stats: [num_files: 1, num_rows: 0, total_size: 19, raw_data_size: 0]Table default.p_student stats: [num_partitions: 1, num_files: 1, num_rows: 0, total_size: 19, raw_data_size: 0]OKTime taken: 0.736 secondshive> LOAD DATA LOCAL INPATH '/home/alex/2014-09-10-CN' INTO TABLE p_student partition(daytime='2014-09-10',country='CN');Copying data from file:/home/alex/2014-09-10-CNCopying file: file:/home/alex/2014-09-10-CNLoading data to table default.p_student partition (daytime=2014-09-10, country=CN)Partition default.p_student{daytime=2014-09-10, country=CN} stats: [num_files: 1, num_rows: 0, total_size: 19, raw_data_size: 0]Table default.p_student stats: [num_partitions: 2, num_files: 2, num_rows: 0, total_size: 38, raw_data_size: 0]OKTime taken: 0.691 secondshive> LOAD DATA LOCAL INPATH '/home/alex/2014-09-10-EN' INTO TABLE p_student partition(daytime='2014-09-10',country='EN');Copying data from file:/home/alex/2014-09-10-ENCopying file: file:/home/alex/2014-09-10-ENLoading data to table default.p_student partition (daytime=2014-09-10, country=EN)Partition default.p_student{daytime=2014-09-10, country=EN} stats: [num_files: 1, num_rows: 0, total_size: 21, raw_data_size: 0]Table default.p_student stats: [num_partitions: 3, num_files: 3, num_rows: 0, total_size: 59, raw_data_size: 0]OKTime taken: 0.622 seconds看看存储结构
# hdfs dfs -ls /user/hive/warehouse/p_studentFound 2 itemsdrwxr-xr-x - root supergroup 0 2014-12-08 16:10 /user/hive/warehouse/p_student/daytime=2014-09-09drwxr-xr-x - root supergroup 0 2014-12-08 16:10 /user/hive/warehouse/p_student/daytime=2014-09-10# hdfs dfs -ls /user/hive/warehouse/p_student/daytime=2014-09-09Found 1 itemsdrwxr-xr-x - root supergroup 0 2014-12-08 16:10 /user/hive/warehouse/p_student/daytime=2014-09-09/country=CN查询一下数据
hive> select * from p_student;OK1 tammy 2014-09-09 CN2 eric 2014-09-09 CN3 paul 2014-09-10 CN4 jolly 2014-09-10 CN44 ivan 2014-09-10 EN66 billy 2014-09-10 ENTime taken: 0.228 seconds, Fetched: 6 row(s)hive> select * from p_student where daytime='2014-09-10' and country='EN';OK44 ivan 2014-09-10 EN66 billy 2014-09-10 ENTime taken: 0.224 seconds, Fetched: 2 row(s)
桶表
桶表表专门用于采样分析
CREATE TABLE b_student(id INT, name STRING)
PARTITIONED BY(dt STRING, country STRING)
CLUSTERED BY(id) SORTED BY(name) INTO 4 BUCKETS
row format delimited
fields TERMINATED BY '\054';
hive> select * from b_student;OK1 tammy 2014-09-09 CN2 eric 2014-09-09 CN3 paul 2014-09-10 CN4 jolly 2014-09-10 CN34 allen 2014-09-11 ENTime taken: 0.727 seconds, Fetched: 5 row(s)从4个桶中采样抽取一个桶的数据
hive> select * from b_student tablesample(bucket 1 out of 4 on id);Total MapReduce jobs = 1Launching Job 1 out of 1Number of reduce tasks is set to 0 since there's no reduce operatorStarting Job = job_1406097234796_0041, Tracking URL = http://hadoop01:8088/proxy/application_1406097234796_0041/Kill Command = /usr/lib/hadoop/bin/hadoop job -kill job_1406097234796_0041Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 02014-12-08 17:35:56,995 Stage-1 map = 0%, reduce = 0%2014-12-08 17:36:06,783 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 2.9 sec2014-12-08 17:36:07,845 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 2.9 secMapReduce Total cumulative CPU time: 2 seconds 900 msecEnded Job = job_1406097234796_0041MapReduce Jobs Launched: Job 0: Map: 1 Cumulative CPU: 2.9 sec HDFS Read: 482 HDFS Write: 22 SUCCESSTotal MapReduce CPU Time Spent: 2 seconds 900 msecOK4 jolly 2014-09-10 CN
外部表
hbase(main):005:0> create 'employee','info'
0 row(s) in 0.4740 seconds
=> Hbase::Table - employee
hbase(main):006:0> put 'employee',1,'info:id',1
0 row(s) in 0.2080 seconds
hbase(main):008:0> scan 'employee'
ROW COLUMN+CELL
1 column=info:id, timestamp=1417591291730, value=1
1 row(s) in 0.0610 seconds
hbase(main):009:0> put 'employee',1,'info:name','peter'
0 row(s) in 0.0220 seconds
hbase(main):010:0> scan 'employee'
ROW COLUMN+CELL
1 column=info:id, timestamp=1417591291730, value=1
1 column=info:name, timestamp=1417591321072, value=peter
1 row(s) in 0.0450 seconds
hbase(main):011:0> put 'employee',2,'info:id',2
0 row(s) in 0.0370 seconds
hbase(main):012:0> put 'employee',2,'info:name','paul'
0 row(s) in 0.0180 seconds
hbase(main):013:0> scan 'employee'
ROW COLUMN+CELL
1 column=info:id, timestamp=1417591291730, value=1
1 column=info:name, timestamp=1417591321072, value=peter
2 column=info:id, timestamp=1417591500179, value=2
2 column=info:name, timestamp=1417591512075, value=paul
2 row(s) in 0.0440 seconds 建立外部表进行映射
hive> CREATE EXTERNAL TABLE h_employee(key int, id int, name string) > STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' > WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key, info:id,info:name") > TBLPROPERTIES ("hbase.table.name" = "employee"); OK Time taken: 0.324 seconds hive> select * from h_employee; OK 1 1 peter 2 2 paul Time taken: 1.129 seconds, Fetched: 2 row(s)
查询语法
显示条数
hive> select * from h_employee limit 1
> ;
OK
1 1 peter
Time taken: 0.284 seconds, Fetched: 1 row(s)但是不支持起点,比如offset
参考资料
- http://www.cloudera.com/content/cloudera/en/documentation/core/v5-2-x/topics/cdh_ig_hiveserver2_configure.html
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/134096.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
