大家好,又见面了,我是你们的朋友全栈君。
LEfse分析定义 LEfse分析即LDA Effect Size分析,可以实现多个分组之间的比较,还进行分组比较的内部进行亚组比较分析,从而找到组间在丰度上有显著差异的物种(即biomaker);
主要是通过非参数因子Kruskal-Wallis秩和检验来实现的。
运行LEfSe软件主要分三大步骤:第一步:需要把普通的物种、基因等等的丰度信息的表格转化成LEfSe识别的格式。这一步会生成.in结尾的文件
第二步:这一步也是最关键的一步,统计显著差异的biomarker、统计子组组间差异、统计effect sizes(LDA score),会生成.res格式的文件。如下图所示Step1:两组或两组以上的样本中采用的非参数因子Kruskal-Wallis秩和检验检测出biomarker。
Step2:基于上步的显著差异物种基因,进行两两组之间的Wilcoxon秩和检验,检测出组间差异。
Step3:线性判别分析(LDA)对biomarker进行评估差异显著的物种的影响力(即LDA score),最终获得biomarker。第三步:基于第二大步的数据,绘制各种图片。如下图所示

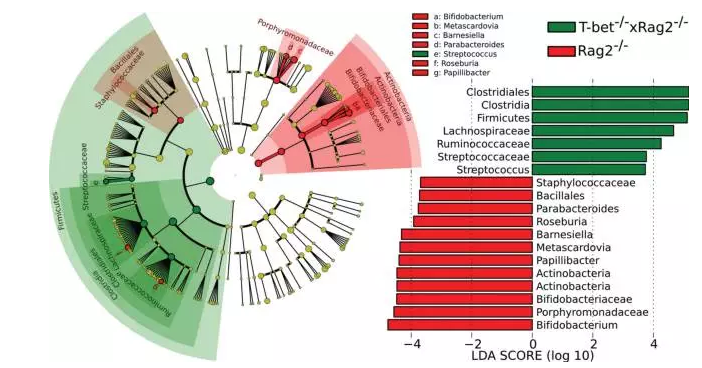
LDA值分布柱状图:
展示了LDA score大于设定值有差异的物种,即具有统计学差异的biomaker。展现不同组中丰度有显著差异的物种,柱状图的长度代表显著差异物种的影响大小;
进化分支图:
由内至外辐射的圆圈代表了由门至属(或种)的分类级别。在不同分类级别上的每一个小圆圈代表该水平下的一个分类,小圆圈直径大小与相对丰度大小呈正比。
着色原则:无显著差异的物种统一着色为黄色,差异物种 Biomarker跟随组进行着色,红色节点表示在红色组别中起到重要作用的微生物类群,绿色节点表示在绿色组别中起到重要作用的微生物类群,其它圈颜色意义类同。图中英文字母表示的物种名称在右侧图例中进行展示。
biomaker在不同组各样本中的丰度比较图:
将biomaker丰度最高的样本的丰度设定为1,其他样品中该 biomarker 的丰度为相对于丰度最高样品的相对值。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/134089.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
