大家好,又见面了,我是你们的朋友全栈君。

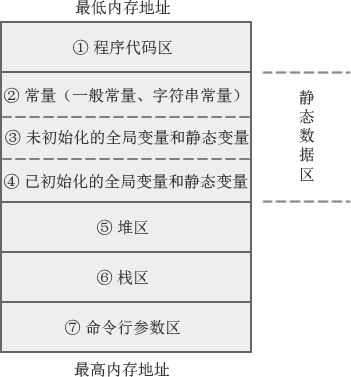
(命令行参数区其实就是在通过dos或shell脚本调用时传递的参数,比如:a.exe 123 123)
上图是C语言内存模型,其实虽然说叫C语言内存模型,其实并不是叫C语言内存模型,而是C语言根据CPU处理器搭建出来的一个模型!
在开始介绍这些之前,读者需要了解一些体系结构:
冯诺依曼体系:
把程序本身当作数据来对待,程序指令和该程序处理的数据用同样的方式储存。 冯·诺依曼体系结构的要点是:计算机的数制和指令采用二进制方式存储并且计算机应该按照程序指令顺序执行!
即自8086以来的CPU都开始遵守这个体系,并设立:专门用来保存段地址:CS(Code Segment):代码段寄存器;DS(Data Segment):数据段寄存器;SS(Stack Segment):堆栈段寄存器;ES(Extra Segment):附加段寄存器。
当一个程序要执行时,这些寄存器指向内存的位置就决定程序代码、数据和堆栈各要用到内存的哪些位置!
C语言编译过程:
C语言的编译过程分为:预编译-编译-汇编-链接
这里我们抛开其它的不谈,只谈汇编!
这里简单给大家看一下汇编程序体系:
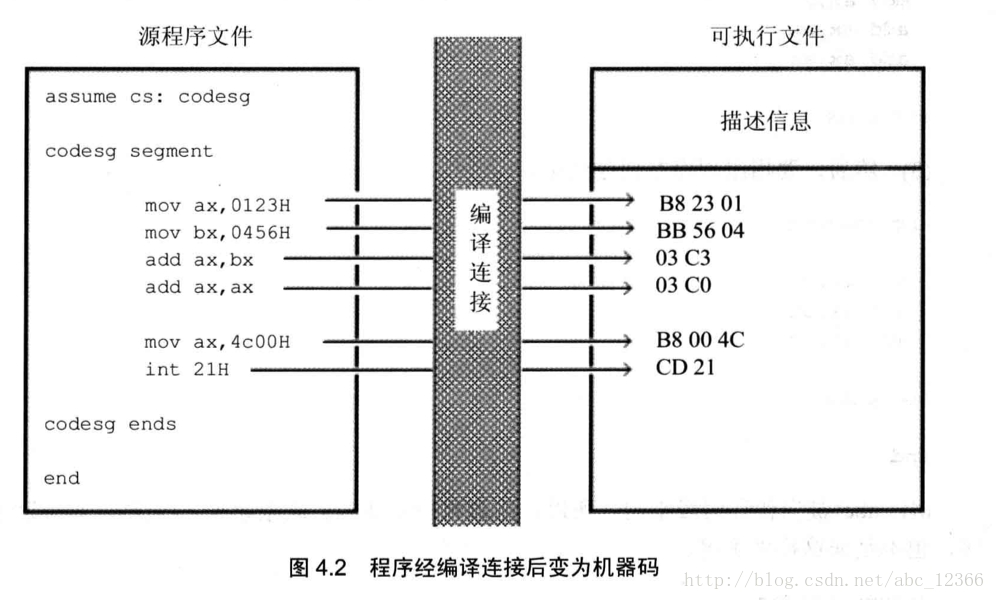
注意这里:
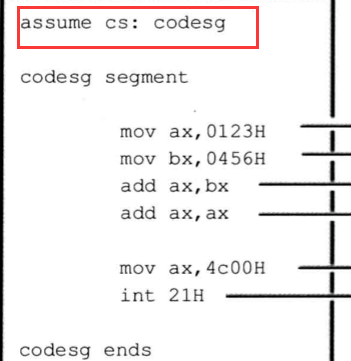
这些assume属于汇编伪指令,给汇编解释器看的,汇编解释器看到这些指令时就知道哪些区域是指令哪些区域是堆栈!
并且会修改PE头文件格式,操作系统根据PE文件头格式来将程序加载到内存,并对其进行分区,将分区后的内存首尾地址保存到PCB进程控制块里!
然后在将CPU里的段寄存器指向程序的各个区域,就形成了代码段,数据段,堆栈区域划分,CPU会按照代码段流程执行下去!
这样CPU就知道这个程序哪些是指令,哪些是数据了!
这里需要说一下数据段寄存器,数据段寄存器是无需指定的,因为数据段寄存器使用来存储立即数的,比如上方的ax就等于一个数据段寄存器,也就是说数据段寄存器是供我们用来临时存储一些操作数的!
注意这段代码没有用到任何堆栈内存,都是基本的立即数操作代码,所以无需指定堆栈地址,如果没有指定编译器会帮我们在PE文件格式里增加堆栈大小为0,所以仅占用代码段的内存大小!

codesg ends这段指令是意味着代码段的结束,用于在PE文件格式里告诉操作系统代码段的长度是多少,这样操作系统就知道代码段的范围了,end是意味着整个程序的结束,用于告诉汇编解释器到此整个汇编程序的解释工作就完成了!
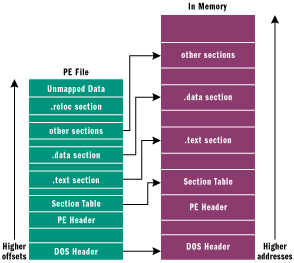
(这里的PE文件格式是按照Windows下的划分,Linux等其它操作系统均有此格式但不叫PE叫ELF文件格式,每个系统都有着自己的可运行文件格式,有兴趣可以去详细了解一下)
顺便提一下CPU的工作模式吧!
结合上面所说的知识,我们知道CPU会从CS代码段寄存器开始读取指令,并一步一步执行下去,直到代码段完结!
CS代码段寄存器只能用于保存程序代码段的首地址,其中还有CS:IP和CS:IR寄存器!
CS:IP
用于存放段地址偏移量,代码段为一个段,CS里包含着整个段的起始地址,假如一个代码段的取值范围是0x00000000H~0xFFFFFFFFH
那么CS包含着的是0x00000000H整个代码段的首地址,而IP存放着0x00000000H~0xFFFFFFFFH之间的偏移地址!
一开始CS:IP寄存器里的地址和CS代码段地址是一样的,当我们执行完一个指令时,IP寄存器里的地址会被累加+1,演变成0x00000001H!
然后CPU就知道了下一条指令的位置了,很多人都会说指令累加器PC寄存器,其实并没有这个寄存器,这只是累加的一个概念!
上面说的是在过去式了,现在基本上会累加4个字节地址,因为现在的寻址位宽最少为32位,过去式最早的是8位,一个字节!
CS:IR
IR寄存器是用来存放从内存地址中读取出来的指令二进制数!
CPU根据IP地址从内存中读取出来指令后会将其放到IR寄存器里,而译码器会将IR寄存器里的指令解析出来,把立即数解析到数据寄存器里,ax或bx等然后在将里面的指令翻译成对应的电平脉冲信号给CPU(CPU的指令集在CPU内部存储着,这个是不开放的),这样CPU就能正常驱动工作,CPU会去处理ax或bx里的立即数!
如果里面没有包含立即数那么就是另外一种指令集,即在内存中将数据取出,那么此时数据就等于立即数,不过这个立即数会在经过alu运算单元处理之后结果存放到数据寄存器然后在返回给内存里!
alu运算单元所使用的寄存器和CPU所使用的是一样的!
既然说,就要说的透彻一点!
alu运算单元为什么和CPU所使用同样的寄存器?
答:alu就是CPU的一部分,属于CPU内部算术运算单元,并且控制单元CU负责执行指令,CU就是由指令寄存器IR(Instruction Register)、指令译码器ID(Instruction Decoder)和操作控制器OC!
前两个上面说过了,最后说一下操作控制寄存器,这个是负责将译码器根据内部指令集翻译的电平脉冲信号频率转换成对应的控制信号,并根据脉冲频率而转换成的控制信号来驱动CPU各个器件工作!
就好像摩斯密码一样,眨两下眼睛是说你好,三下是说再见一样,这都是频率!
详细的说明一下:
操作控制器是最为核心的一个器件,它能将译码器翻译成的电平脉冲信号转换成对应的电路信号,来驱动总线工作,也就是说它能根据电平脉冲信号频率的不同来确定要做哪些操作,至于要做哪些操作是取决于内部已经提前设定好的电路信号(也就是CPU内部指令集)!
好言归正传,上面也说了C语言会到汇编这一步,C语言会将你写的C语言代码转化成对应的汇编代码,来确定堆栈大小,比如int a;实则上C语言编译器在编译阶段会进行语法分析,建立四张表,用于存放堆栈,代码段等信息,会把你写的代码划分到这几个区域中,最后在根据这些表里的划分,将你的代码转换成汇编代码后,在增加伪指令来告诉汇编解释器PE文件里应该怎样设定代码段以及堆栈大小区域划分!
知道了C语言内存模型的起源,下面来介绍一下内存模型中各个区域划分的作用:
静态数据区:

注意该区是不包含常量的,常量是划分在代码段区的,常量一般称为立即数,是不会为其分配任何空间的!
一般情况下代码段指令是这样的:地址码+操作码+立即数或地址码+操作码+寄存器(用于将内存中的数据读取到数据段寄存器)
上图的未初始化的全局变量和静态变量与已初始化的全局变量和静态变量区别在于:
你在全局区定义了一个变量但是没有初始化,编译器会帮你自动初始化为0,并放到此区域下
第二个就是你已经手动初始化好的显示用=来初始化的,即便赋0也会被放到此区域下!
并且此区域下的变量,会随着进程的结束,此内存才会被操作系统回收!
栈:
C语言会把一些局部变量存放此内存下,全局变量内存是不存放在此空间下的,其实说的直白一点,在内存中并没有这些概念,上面也说过,自x8086CPU以来为了更加容易的管理程序推出了段寄存器,所以C语言将根据这些段寄存器来划分自己程序空间每个空间的作用是什么!
就好比栈,在栈中开辟的内存,也就是在C语言函数体里开辟的内存,当函数结束后,操作系统会自动帮我们把位于栈中内存释放掉!
比如:int test(){
int a;
}
实则上这段代码在编译运行之后,是放在代码段的,只有当执行到int a时,操作系统才会从内存池中,帮你索要内存,并修改sp栈指针的指向,同时修改PCB进程控制块里的栈范围大小指针的指向!
当这段函数执行完成时,操作系统会立马回收这些内存,放回内存池中!
这里来说一下操作系统是怎样知道函数结束的,以及代码段的划分!
比如:
C语言编译器会检查函数的作用域,如果你在末尾没有加上return返回值,则默认到}时使用ret指令返回,如果遇到return也使用ret指令返回!
return;和return 0;是一样的结果!
栈的大小是有上限的,一般默认为4kb,这个4kb会写到PE文件格式里,操作系统在加载时通过PE文件确定此程序的栈最大大小是多少,并记录到PCB进程控制块stack_max变量里,PCB进程控制块里有一个stack_sp记录栈顶地址,也就是栈的顶部地址,当你的栈顶部大小,超出stack_max时会被操作系统自动杀掉,这也叫栈边界越界,一般发生在递归函数里!
堆:
堆是没有大小限制的,唯一的大小限制就是虚拟内存的容量,当虚拟内存里内存池用完时,操作系统会从磁盘中切割内存给你用,但是切割出来的内存速度会较慢,这个大小也是可以在操作系统的内存设置里设置的!
当我们使用malloc之类的分配内存函数时,此函数会向操作系统从内存池里索要内存,把一些零零散散的内存,通过地址映射的方式使程序看起来是连续的,并映射给程序使用!
并且分配的内存操作系统不会主动去释放,即便你是在作用域下申请的内存,那么当函数结束时操作系统也不会回收此内存,需要用户手动调用delete等释放内存函数来释放,把内存返回给操作系统的内存池里!
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/134021.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
