大家好,又见面了,我是你们的朋友全栈君。
说明:安装elasticsearch之前必须安装好jdk运行环境
- 1.首先下载安装包:
这是官网最新安装包:https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.5.1-windows-x86_64.zip
- 2.直接解压到想要安装的目录即可
- 3.配置文件
打开config下的elasticsearch.yml文件进行配置
# ======================== Elasticsearch Configuration =========================
#
# NOTE: Elasticsearch comes with reasonable defaults for most settings.
# Before you set out to tweak and tune the configuration, make sure you
# understand what are you trying to accomplish and the consequences.
#
# The primary way of configuring a node is via this file. This template lists
# the most important settings you may want to configure for a production cluster.
#
# Please consult the documentation for further information on configuration options:
# https://www.elastic.co/guide/en/elasticsearch/reference/index.html
#
# ---------------------------------- Cluster -----------------------------------
#
# Use a descriptive name for your cluster:
#
#集群名称
cluster.name: my-es
#
# ------------------------------------ Node ------------------------------------
#
# Use a descriptive name for the node:
#
#当前节点名称
node.name: node-1
#
# Add custom attributes to the node:
#
#node.attr.rack: r1
#
# ----------------------------------- Paths ------------------------------------
#
# Path to directory where to store the data (separate multiple locations by comma):
#
#数据存储位置
path.data: E:/elasticsearch/elasticsearch-6.8.3/data-es/data/
#
# Path to log files:
#
#日志存储位置
path.logs: E:/elasticsearch/elasticsearch-6.8.3/data-es/logs/
#
# ----------------------------------- Memory -----------------------------------
#
# Lock the memory on startup:
#
#如果是单节点将其配置为false
bootstrap.memory_lock: false
#
# Make sure that the heap size is set to about half the memory available
# on the system and that the owner of the process is allowed to use this
# limit.
#
# Elasticsearch performs poorly when the system is swapping the memory.
#
# ---------------------------------- Network -----------------------------------
#
# Set the bind address to a specific IP (IPv4 or IPv6):
#
#可访问的主机
network.host: 192.168.1.211
#
# Set a custom port for HTTP:
#
#端口
http.port: 9200
#
# For more information, consult the network module documentation.
#
# --------------------------------- Discovery ----------------------------------
#
# Pass an initial list of hosts to perform discovery when new node is started:
# The default list of hosts is ["127.0.0.1", "[::1]"]
#
#集群的节点,多个这样配置["192.168.1.211","192.168.1.212"]
discovery.zen.ping.unicast.hosts: ["192.168.1.211"]
#
# Prevent the "split brain" by configuring the majority of nodes (total number of master-eligible nodes / 2 + 1):
#
discovery.zen.minimum_master_nodes: 0
#
# For more information, consult the zen discovery module documentation.
#
# ---------------------------------- Gateway -----------------------------------
#
# Block initial recovery after a full cluster restart until N nodes are started:
#
gateway.recover_after_nodes: 1
#
# For more information, consult the gateway module documentation.
#
# ---------------------------------- Various -----------------------------------
#
# Require explicit names when deleting indices:
#
action.destructive_requires_name: true
- 4.配置数据模板
将其名字配置成consumer_statistics.mapping
{"template":"consumer_statistics","order":2,"version":60001,"index_patterns":["consumer_statistics"],"settings":{"index":{"refresh_interval":"5s","max_result_window":"2147483647"}},"mappings":{"_default_":{"dynamic_templates":[{"message_field":{"path_match":"message","mapping":{"norms":false,"type":"text"},"match_mapping_type":"string"}},{"string_fields":{"mapping":{"norms":false,"type":"text","fields":{"keyword":{"ignore_above":1024,"type":"keyword"}}},"match_mapping_type":"string","match":"*"}}],"properties":{"@timestamp":{"type":"date"},"geoip":{"dynamic":true,"properties":{"ip":{"type":"ip"},"latitude":{"type":"half_float"},"location":{"type":"geo_point"},"longitude":{"type":"half_float"}}},"@version":{"type":"keyword"}}}},"aliases":{}}- 5.安装curl插件
链接:https://pan.baidu.com/s/1dQS4UfuagovhcXTCNehztw
提取码:ntxv
- 6.给curb配置环境变量
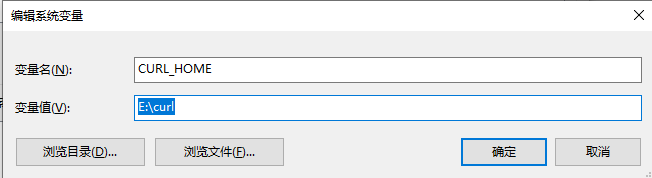

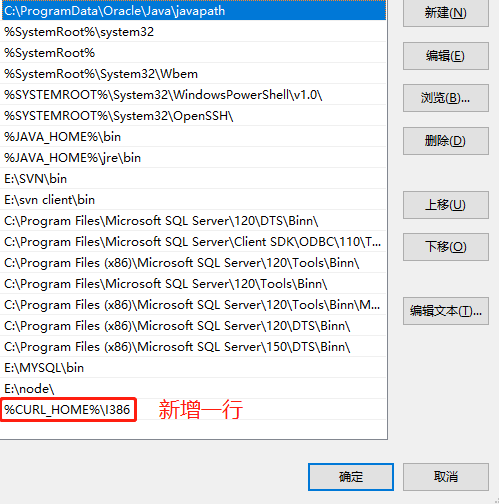
- 7.执行模板ip改为数据库es数据库的ip 模板名称也要对应,然后所在位置
curl -H "Content-Type: application/json" -XPUT http://192.168.1.211:9200/_template/consumer_statistics -d "@E:\consumer_statistics.mapping"到此es数据库安装完成,下一步进行导入数据的操作:
安装logstash:https://mp.csdn.net/postedit/103905006
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/133998.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
