大家好,又见面了,我是你们的朋友全栈君。
卷积神经网络实现图像识别及过程可视化
本博文提供经典的卷积神经网络实现代码,将CNN的工具类等代码分别封装,并提供接口自行替换使用的模型(可以换成自己的神经网络及图片样本),代码中提供模型保存和读取,并对卷积层的计算结果反卷积还原成图片输出到tensorboard中,最后可以在tensorboard中观察CNN训练的过程和结果数据,并查看过程中卷积核提取的具体特征。
实验环境 i7-8750 + GTX 1066, tensorflow-gpu 1.80 + cuda 9 + cudnn 7 + anaconda3(python3.6.5)
一、样本文件存储形式
样本按照不同类别保存在不同文件夹中,每个文件夹代表一个类别,然后这些文件夹放在同一文件夹中,该文件夹和脚本同一目录下。

样本读取后记得要转换成 numpy.array 的格式,其中注意,为了能够输入tensorflow网络中,样本数据需要满足格式符合 tf.float32 格式,标签数据需要满足 tf.int32格式,这两个格式和numpy是兼容的,所以注意格式否则输入网络会报错。
''' 从path中读取图片文件 文件存储方式:path - class1 - pic1.jpg ... - class2 - picn.jpg ... '''
def load_data(path,imgw,imgh):
# 如果把文件夹目录下为文件下的路径加入集合
classes = [path+x for x in os.listdir(path) if os.path.isdir(path+x)]
imgs = []
labels = []
for label, folder in enumerate(classes):
# 读取xxx/*.jpg
for img in glob.glob(folder + '/*jpg'):
img = io.imread(img)
img = transform.resize(img,(imgw,imgh))
imgs.append(img)
labels.append(label)
return np.asarray(imgs, dtype=np.float32), np.array(labels, dtype=np.int32) #记住labels一定要转换成int32形式二、其他样本处理
''' 样本打乱顺序 '''
def disrupt_order(data, labels):
total_num = data.shape[0]
order_arrlist = np.arange(total_num)
random.shuffle(order_arrlist)
data = data[order_arrlist]
labels = labels[order_arrlist]
return data , labels
''' 分割测试训练集 '''
def get_train_test_data(data, labels, percent):
seg_point = int(data.shape[0] * percent)
x_train = data[0:seg_point, :]
x_test = data[seg_point:, :]
y_train = labels[0:seg_point]
y_test = labels[seg_point:]
return x_train, y_train, x_test, y_test
#定义一个函数,按批次取数据
def minibatches(inputs=None, targets=None, batch_size=None, shuffle=False):
assert len(inputs) == len(targets)
if shuffle:
indices = np.arange(len(inputs))
np.random.shuffle(indices)
for start_idx in range(0, len(inputs) - batch_size + 1, batch_size):
if shuffle:
excerpt = indices[start_idx:start_idx + batch_size]
else:
excerpt = slice(start_idx, start_idx + batch_size)
yield inputs[excerpt], targets[excerpt]三、CNN模型代码
def inference(input_tensor, train, regularizer):
with tf.variable_scope('layer1-conv1'):
conv1_weights = tf.get_variable("weight",[5,5,3,32],initializer=tf.truncated_normal_initializer(stddev=0.1))
conv1_biases = tf.get_variable("bias", [32], initializer=tf.constant_initializer(0.0))
conv1 = tf.nn.conv2d(input_tensor, conv1_weights, strides=[1, 1, 1, 1], padding='SAME')
relu1 = tf.nn.relu(tf.nn.bias_add(conv1, conv1_biases))
with tf.name_scope("layer2-pool1"):
pool1 = tf.nn.max_pool(relu1, ksize = [1,2,2,1],strides=[1,2,2,1],padding="VALID")
with tf.variable_scope("layer3-conv2"):
conv2_weights = tf.get_variable("weight",[5,5,32,64],initializer=tf.truncated_normal_initializer(stddev=0.1))
conv2_biases = tf.get_variable("bias", [64], initializer=tf.constant_initializer(0.0))
conv2 = tf.nn.conv2d(pool1, conv2_weights, strides=[1, 1, 1, 1], padding='SAME')
relu2 = tf.nn.relu(tf.nn.bias_add(conv2, conv2_biases))
with tf.name_scope("layer4-pool2"):
pool2 = tf.nn.max_pool(relu2, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='VALID')
with tf.variable_scope("layer5-conv3"):
conv3_weights = tf.get_variable("weight",[3,3,64,128],initializer=tf.truncated_normal_initializer(stddev=0.1))
conv3_biases = tf.get_variable("bias", [128], initializer=tf.constant_initializer(0.0))
conv3 = tf.nn.conv2d(pool2, conv3_weights, strides=[1, 1, 1, 1], padding='SAME')
relu3 = tf.nn.relu(tf.nn.bias_add(conv3, conv3_biases))
with tf.name_scope("layer6-pool3"):
pool3 = tf.nn.max_pool(relu3, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='VALID')
with tf.variable_scope("layer7-conv4"):
conv4_weights = tf.get_variable("weight",[3,3,128,128],initializer=tf.truncated_normal_initializer(stddev=0.1))
conv4_biases = tf.get_variable("bias", [128], initializer=tf.constant_initializer(0.0))
conv4 = tf.nn.conv2d(pool3, conv4_weights, strides=[1, 1, 1, 1], padding='SAME')
relu4 = tf.nn.relu(tf.nn.bias_add(conv4, conv4_biases))
with tf.name_scope("layer8-pool4"):
pool4 = tf.nn.max_pool(relu4, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='VALID')
nodes = 6*6*128
reshaped = tf.reshape(pool4,[-1,nodes])
with tf.variable_scope('layer9-fc1'):
fc1_weights = tf.get_variable("weight", [nodes, 1024],
initializer=tf.truncated_normal_initializer(stddev=0.1))
if regularizer != None: tf.add_to_collection('losses', regularizer(fc1_weights))
fc1_biases = tf.get_variable("bias", [1024], initializer=tf.constant_initializer(0.1))
fc1 = tf.nn.relu(tf.matmul(reshaped, fc1_weights) + fc1_biases)
if train: fc1 = tf.nn.dropout(fc1, 0.5)
with tf.variable_scope('layer10-fc2'):
fc2_weights = tf.get_variable("weight", [1024, 512],
initializer=tf.truncated_normal_initializer(stddev=0.1))
if regularizer != None: tf.add_to_collection('losses', regularizer(fc2_weights))
fc2_biases = tf.get_variable("bias", [512], initializer=tf.constant_initializer(0.1))
fc2 = tf.nn.relu(tf.matmul(fc1, fc2_weights) + fc2_biases)
if train: fc2 = tf.nn.dropout(fc2, 0.5)
with tf.variable_scope('layer11-fc3'):
fc3_weights = tf.get_variable("weight", [512, 5],
initializer=tf.truncated_normal_initializer(stddev=0.1))
if regularizer != None: tf.add_to_collection('losses', regularizer(fc3_weights))
fc3_biases = tf.get_variable("bias", [5], initializer=tf.constant_initializer(0.1))
logit = tf.matmul(fc2, fc3_weights) + fc3_biases
return logit
注意这里需要手动计算卷积层到全连接层的数据维度,即计算reshape的参数。
reshaped = tf.reshape(pool4,[-1,nodes])
这里-1表示tensorflow自动计算数据维度,实际上-1处计算结果是样本总数,因此另一个参数是每个样本图像被多次卷积、池化后的结果数据拉长成一维之后总元素数目。例如计算得出每个样本图像为宽w高h深度d,这里就要填w*h*d。
这里w,h,d在经过每个卷积层和池化层时都会发生变化。
四、建立session训练模型
为了方便训练和测试更换数据,使用feed_dict的字典方式。
''' author : Fangtao 该脚本读取path目录下的图片样本,处理后输入神经网络 神经网络来源于脚本models.py,可以多个模型中选一个 样本预处理函数保存在helpFunctions.py中 过程中保存acc和卷积后的图片等信息,可以通过tensorboard可视化 '''
from skimage import io,transform
# glob用于查找符合特定规则的路径名
import glob
import os
import tensorflow as tf
import numpy as np
import time
from helpFunctions import *
from models import *
path = 'flower_photos/'
model_saved_path = 'ckpt/model.ckpt'
w = 100
h = 100
print("loading files...")
data, labels = load_data(path, w ,h)
print('files loaded')
total_num = data.shape[0]
'''打乱样本,分散不同样本顺序'''
data , labels = disrupt_order(data , labels)
'''分割数据集'''
x_train, y_train, x_test, y_test = get_train_test_data(data, labels, 0.8)
print('train data size:',x_train.shape)
print('train label size:',y_train.shape)
#
x = tf.placeholder(dtype=tf.float32, shape=[None, w, h, 3],name='x')
y = tf.placeholder(dtype=tf.int32, shape=[None,],name='y')
regulizer = tf.contrib.layers.l2_regularizer(0.0001)
# 数据流一遍通过网络计算输出
# output = AlexNet(x, True, regulizer, 5)
output = inference(x, True, regulizer)
#(小处理)将logits乘以1赋值给logits_eval,定义name,方便在后续调用模型时通过tensor名字调用输出tensor
b = tf.constant(value=1,dtype=tf.float32)
logits_eval = tf.multiply(output,b,name='logits_eval')
# 计算损失(多分类softmax)
loss = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=output, labels=y)
#
''' 使用优化器减小损失 如果acc一直上不去,很可能是lr设置太大,导致无法收敛到合理的最优解 '''
optimizer = tf.train.AdamOptimizer(learning_rate=0.001).minimize(loss)
''' 计算正确率 先计算出每行output最大值,也就是最可能的预测label,用arg_max 为了和y比较,要cast成相同类型数据,tf.int32 然后和y比较相同数据,用equals 最后reduce_meam计算下平均对了几个,在这之前还要cast成float32类型才能计算平均值 '''
with tf.name_scope('loss'):
acc = tf.reduce_mean(tf.cast(tf.equal(tf.cast(tf.arg_max(output,1),dtype=tf.int32),y),tf.float32))
tf.summary.scalar('accuracy',acc) # tfboard一维常量可以放进summary显示图表
n_epoch = 1
batch_size=64
saver = tf.train.Saver()
sess = tf.Session()
'''tensorboard 可视化'''
merged = tf.summary.merge_all()
writer = tf.summary.FileWriter('DeskTop/',sess.graph)
''' 如果加载以前的网络 '''
saver = tf.train.import_meta_graph('ckpt/model.ckpt.meta') # 加载网络结构
saver.restore(sess, tf.train.latest_checkpoint("ckpt/")) # 加载检查点
''' 不加载就随机初始化'''
# sess.run(tf.global_variables_initializer())
''' 每批次都先训练,再测试 训练和测试都分成小批次 每批训练完后都保存 '''
for epoch in range(n_epoch):
start_time = time.time()
#training
train_loss, train_acc, n_batch = 0, 0, 0
for x_train_batch, y_train_batch in minibatches(x_train, y_train, batch_size, shuffle=True):
_,err,ac=sess.run([optimizer,loss,acc], feed_dict={x: x_train_batch, y: y_train_batch}) # 注意这里一定要一批一批的放!!!放多了维度不对conv2d他妈的竟然报错我日老子找了俩小时
train_loss += err
train_acc += ac
n_batch += 1
print(" train loss: %f" % (np.sum(train_loss) / n_batch))
print(" train acc: %f" % (np.sum(train_acc) / n_batch))
test_acc, test_loss, n_batch = 0, 0, 0
for x_test_batch, y_test_batch in minibatches(x_test , y_test, batch_size,shuffle=False): # 测试时不需要打乱
err, ac = sess.run([loss, acc], feed_dict={x : x_test_batch, y : y_test_batch })
test_loss += err
test_acc += ac
n_batch += 1
''' 这两句是绘制折线图等图表的 把每次训练过程中的变量数值加到summary当中最后绘制 如果训练中一个变量都不加进来的话就会报错:None '''
result = sess.run(merged, feed_dict={x: x_train_batch, y: y_train_batch}) # merged也是需要run的
writer.add_summary(result,epoch) # result是summary类型的,需要放入writer中,i步数(x轴)
print(" test loss: %f" % (np.sum(test_loss) / n_batch))
print(" test acc: %f" % (np.sum(test_acc) / n_batch))
saver.save(sess,model_saved_path)
sess.close()
'''可视化comda prompt里面调用这句:tensorboard --logdir D:\代码\BaoyanLearn\Desktop '''笔者一开始训练的时候发现同样的模型下我的正确率一直徘徊在26%左右,而他人的则是60~70%左右,后来发现是learning_rate少打了个0 。=-=因此学习率设置的足够小才能够保证结果不在最优解过远处徘徊(无法收敛到最优解),但过小的正确率又会导致训练速度过慢的问题。
此外输入网络模型的时候一定要注意好数据shape的问题,有问题过程中把shape打印出来有利于快速定位哪里的张量出了问题。另外注意样本最好一批一批的放进去。如果输入feed_dict中的x和y样本数目不符合要求,可能会在loss = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=output, labels=y) 这一句报错。
另外训练之前要注意,初次训练需要调用sess.run(tf.global_variables_initializer())函数初始化所有weight和bias的数据(随机初始化),然后才能进行接下来的训练。当训练几十次后保存checkpoint,下次想要接着训练或直接用于分类任务时,只需要调用
saver = tf.train.import_meta_graph('ckpt/model.ckpt.meta') # 加载网络结构
saver.restore(sess, tf.train.latest_checkpoint("ckpt/")) # 加载检查点
两句话加载网络结构和内部权重即可,不需要再调用初始化语句sess.run(tf.global_variables_initializer())(这句话在调用就相当于没有加载以前训练好的权重数据了)。权重数据被保存在ckpt文件夹下。
然后模型的保存:
五、训练中tensorboard可视化
训练过程中调整参数调整模型时,我们需要对训练中的accuracy、loss、weights等参数的变化有个整体的把握,最好能够把模型的整体框架绘成图,把每一步卷积核的效果可视化,方便找出难以提升准确率等的问题所在。这里用tensorflow自带的tensorboard做可视化。
(1) 对过程中的weights等变量保存,用于绘制图表:
tf.summary.histogram('convolution1' + "/weight", conv1_weight)
tf.summary.histogram('convolution1' + "/bias", conv1_bias)这两句话执行在第一层卷积计算过后
(2)对过程中训练后的accuracy保存绘制图表:
tf.summary.scalar('accuracy',acc) # tfboard一维常量可以放进summary显示图表这里注意要放进去的向量好像不能是张量,因为她要用来绘制折线图等。
(3)可视化过程输出
对过程中卷积计算的结果不能直接绘制成二维图像,要经历一个反卷积的过程才能输出一个原图像卷积后的图像,具体就是对当前数据反池化(如果有经过池化层的话,就需要补零),反激活(relu不怎么需要反激活),反卷积(把原先的卷积核再乘一遍),最终回到原始图像大小即可。
第一层卷积层的输出反卷积:
deconv = tf.nn.conv2d_transpose(relu1, conv1_weights, [64, 100, 100, 3],strides=[1, 1, 1, 1], padding='SAME')
tf.summary.image('conv1_out', deconv, 10)第二层卷积层的输出反卷积(注意需要先经历第二层的卷积核的反卷积,在经历第一层的卷积核的反卷积才能得到和输入图像一直尺寸的输出):
deconv2 = tf.nn.conv2d_transpose(relu2, conv2_weights, [64, 50, 50, 32],strides=[1, 1, 1, 1], padding='SAME')
deconv2_ = tf.nn.conv2d_transpose(deconv2, conv1_weights, [64, 50, 50, 3], strides=[1, 1, 1, 1], padding='SAME')
tf.summary.image('conv2_out', deconv2_, 10)
最终可以在tensorboard中查看这些图表。查看时需要在anaconda prompt窗口下输入
tensorboard --logdir 你的保存路径
然后在命令行窗口中会返回一个网址,直接输入浏览器就能打开:
原图效果:
两层卷积后效果:
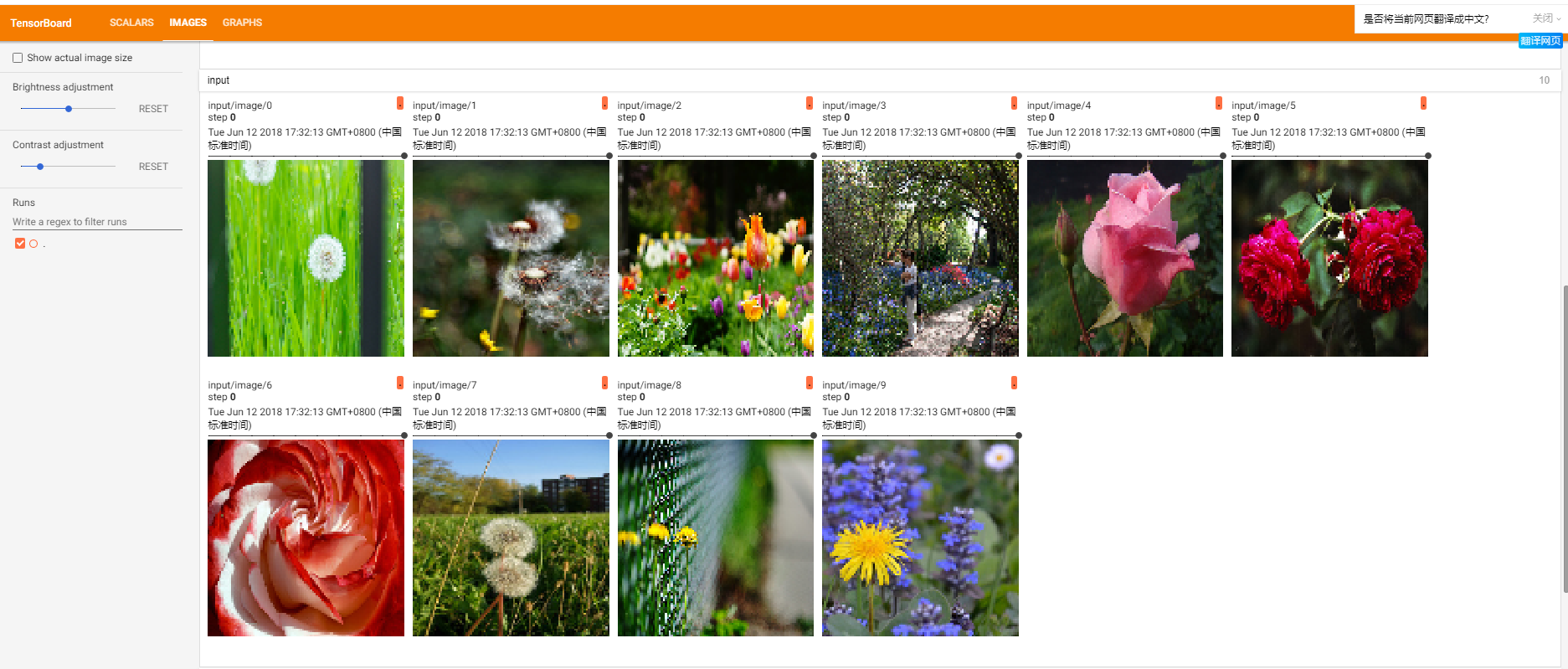
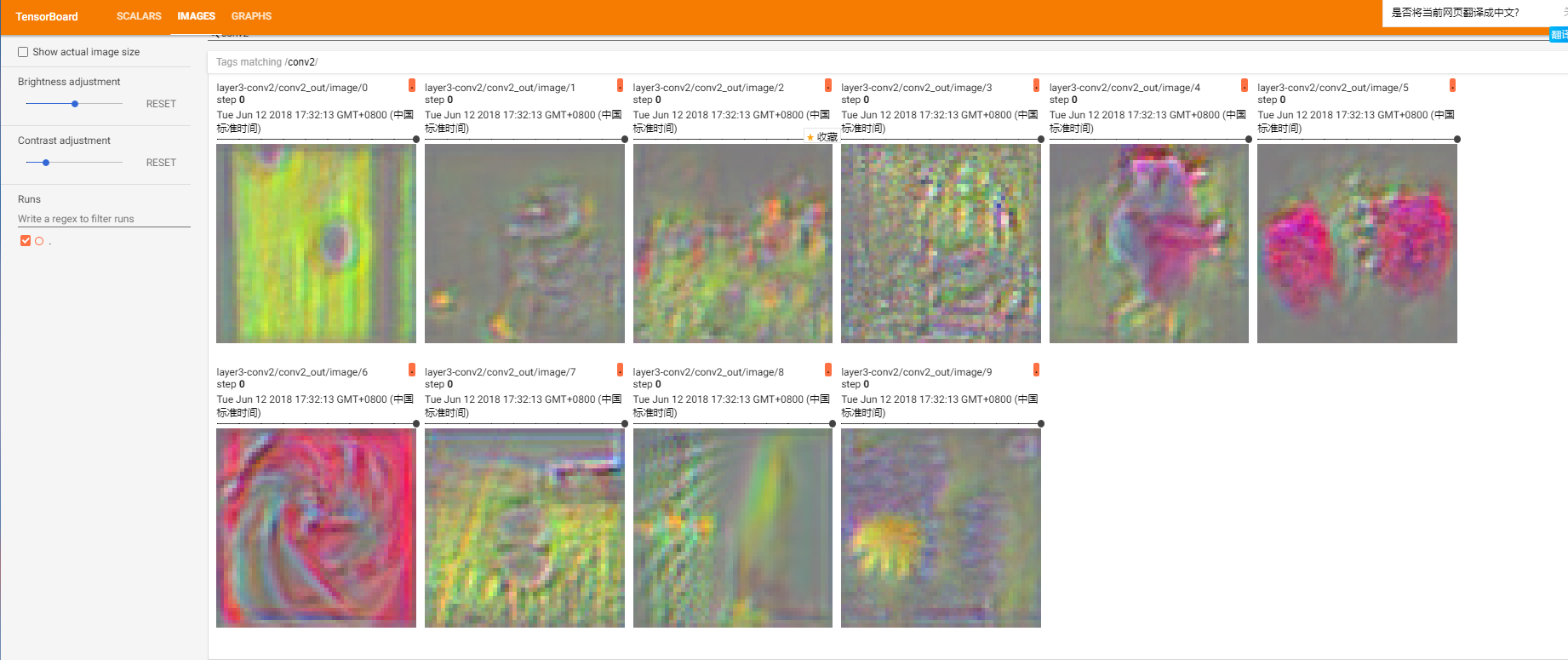
六、测试脚本
这个测试脚本可以用于测试数据集分类效果,也可以直接上线使用(比如让用户上传图片然后返回分类结果)。
from skimage import io,transform
# glob用于查找符合特定规则的路径名
import glob
import os
import tensorflow as tf
import numpy as np
import time
from helpFunctions import *
from models import *
path = 'test_pics/'
model_saved_path = 'ckpt/model.ckpt.meta'
w = 100
h = 100
print("loading files...")
data, labels = load_data(path, w ,h)
print('files loaded')
total_num = data.shape[0]
'''打乱样本,分散不同样本顺序'''
data , labels = disrupt_order(data , labels)
print('train data size:',data.shape)
print('train label size:',labels.shape)
#
x = tf.placeholder(dtype=tf.float32, shape=[None, w, h, 3],name='x')
y = tf.placeholder(dtype=tf.int32, shape=[None,],name='y')
regulizer = tf.contrib.layers.l2_regularizer(0.0001)
# 数据流一遍通过网络计算输出
# output = AlexNet(x, True, regulizer, 5)
output = inference(x, True, regulizer)
#(小处理)将logits乘以1赋值给logits_eval,定义name,方便在后续调用模型时通过tensor名字调用输出tensor
b = tf.constant(value=1,dtype=tf.float32)
logits_eval = tf.multiply(output,b,name='logits_eval')
# 计算损失(多分类softmax)
loss = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=output, labels=y)
#
''' 使用优化器减小损失 如果acc一直上不去,很可能是lr设置太大,导致无法收敛到合理的最优解 '''
optimizer = tf.train.AdamOptimizer(learning_rate=0.001).minimize(loss)
''' 计算正确率 先计算出每行output最大值,也就是最可能的预测label,用arg_max 为了和y比较,要cast成相同类型数据,tf.int32 然后和y比较相同数据,用equals 最后reduce_meam计算下平均对了几个,在这之前还要cast成float32类型才能计算平均值 '''
with tf.name_scope('loss'):
acc = tf.reduce_mean(tf.cast(tf.equal(tf.cast(tf.arg_max(output,1),dtype=tf.int32),y),tf.float32))
tf.summary.scalar('accuracy1',acc) # tfboard一维常量可以放进summary显示图表
n_epoch = 1
batch_size=1
saver = tf.train.Saver()
sess = tf.Session()
saver = tf.train.import_meta_graph(model_saved_path) # 加载网络结构
saver.restore(sess, tf.train.latest_checkpoint("ckpt/")) # 加载检查点
'''tensorboard 可视化'''
merged = tf.summary.merge_all()
writer = tf.summary.FileWriter('DeskTop/',sess.graph)
''' 每批次都先训练,再测试 训练和测试都分成小批次 每批训练完后都保存 '''
for epoch in range(n_epoch):
out , err, ac = sess.run([output, loss, acc], feed_dict={x : data, y : labels })
print('predicted:', out)
sess.close()本文借鉴的博文有:
tensorboard可视化
TensorFlow之CNN图像分类及模型保存与调用
tensorflow 1.0 学习:用CNN进行图像分类
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/133658.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
