大家好,又见面了,我是你们的朋友全栈君。
随着越来越多的应用使用OKHttp来进行网络访问,我们有必要去深入研究OKHTTP的基石,一套更加轻巧方便高效的IO库okio.
OKIO的优点
有同学或会问,目前Java的IO已经非常成熟了,为什么还要使用新的IO库呢?笔者认为,答案有以下几点:
- 低的CPU和内存消耗。后面我们会分析到,okio采用了segment的机制进行内存共享和复用,尽可能少的去申请内存,同时也就降低了GC的频率。我们知道,过于频繁的GC会给应用程序带来性能问题。
- 使用方便。在OKIO中,提供了ByteString来处理不变的byte序列,在内存上做了优化,不管是从byte[]到String或是从String到byte[],操作都非常轻快,同时还提供了如hex字符,base64等工具。而Buffer是处理可变byte序列的利器,它可以根据使用情况自动增长,在使用过程中也不用去关心position等位置的处理。
- N合一。Java的原生IO,InputStream/OutputStream, 如果你需要读取数据,如读取一个整数,一个布尔,或是一个浮点,你需要用DataInputStream来包装,如果你是作为缓存来使用,则为了高效,你需要使用BufferedOutputStream。在OKIO中BufferedSink/BufferedSource就具有以上基本所有的功能,不需要再串上一系列的装饰类。
- 提供了一系列的方便工具,如GZip的透明处理,对数据计算md5、sha1等都提供了支持,对数据校验非常方便。
OKIO的框架设计

OKIO之所以轻量,他的代码非常清晰。最重要的两个接口分别是Source和Sink。
Source
这个接口主要用来读取数据,而数据的来源可以是磁盘,网络,内存等,同时还可以对接口进行扩展处理,比如解压,解密,去掉不需要的网络帧等。
public interface Source extends Closeable {
/** * Removes at least 1, and up to {@code byteCount} bytes from this and appends * them to {@code sink}. Returns the number of bytes read, or -1 if this * source is exhausted. */
long read(Buffer sink, long byteCount) throws IOException;
/** Returns the timeout for this source. */
Timeout timeout();
/** * Closes this source and releases the resources held by this source. It is an * error to read a closed source. It is safe to close a source more than once. */
@Override void close() throws IOException;
}对于Source的子类,我们需要重点关注BufferedSource。它同样是个接口,不过它提供了更多的操作方法。
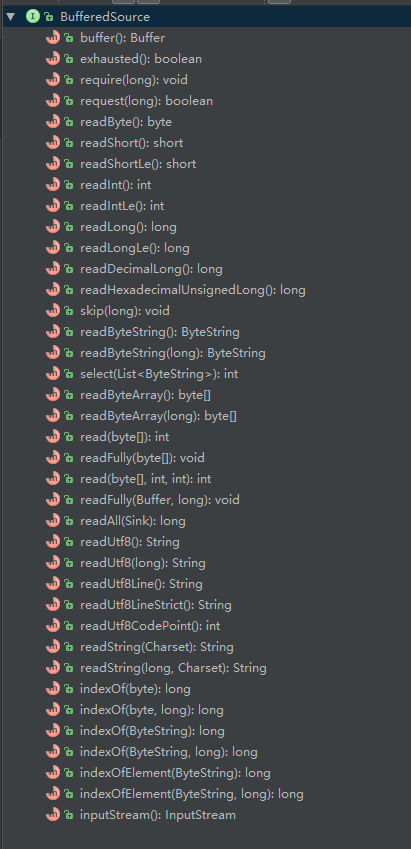
而RealBufferedSource是它的直接实现类。实现了其所有接口。它们的关系如下。
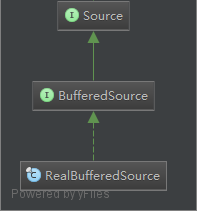
而实际上,RealBufferedSource的实现,是基于Buffer类。这个类我们后面再讲
Sink
Sink与Source相似,只不过是写数据。
public interface Sink extends Closeable, Flushable {
/** Removes {@code byteCount} bytes from {@code source} and appends them to this. */
void write(Buffer source, long byteCount) throws IOException;
/** Pushes all buffered bytes to their final destination. */
@Override void flush() throws IOException;
/** Returns the timeout for this sink. */
Timeout timeout();
/** * Pushes all buffered bytes to their final destination and releases the * resources held by this sink. It is an error to write a closed sink. It is * safe to close a sink more than once. */
@Override void close() throws IOException;
}同样,它也有个子类BufferedSink,定义了对数据的所有操作。它的直接类RealBufferedSink也同样是使用Buffer来完成。
Buffer
Buffer是okio中非常重要的一个类,是整个okio库的基石,很多的优化思想,都体现在这个类中。不多废话,我们先看这个类的继承关系。
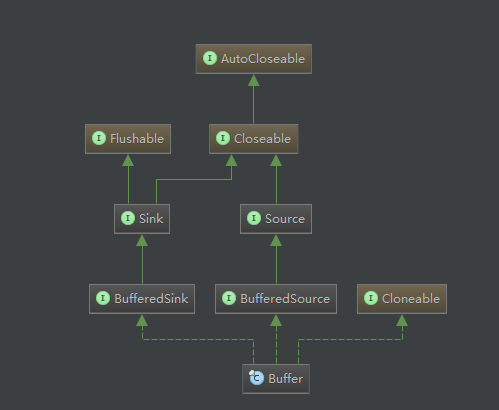
可以看到,这个Buffer是个集大成者,实现了BufferedSink和BufferedSource的接口,也就是说,即可以从中读取数据,也可以向里面写入数据,其强大之处是毋庸置疑的。在前面提到的okio的优点,如低的cpu消耗,低频的GC等,都是在这个类中做到的。后面的章节中我将详细讲述。
ByteString
byteString是相对独立的一个类,也可以看作是一个工具类。它的功能我们看一下方法就一目了然。
可以看到,有计算md5,sha1的摘要功能,也有大小写转换功能,还有十六进制字符转换功能等等。这个类我不打算细讲,因为非常简单,不过要提到一点的是它的几个字段。
final byte[] data;
transient String utf8; // Lazily computed.由于此类是不可变的(创建后之后不能修改其数据),因些它是以byte[]为基础。同时又包含了String,虽然是延时初始化,但也是包含了双倍的字符串数据,它的内存占用相对比较大,它适用于不长的字符串,又需要频繁的编码转换的,用空间换时间,可以降低CPU的消耗,毕意new String(byte[] data)这样的开销还是比较大的。
ByteString还有个子类SegmentedByteString,后面在讲Buffer再介绍。
Okio
Okio是入口类,提供一些从JavaAPI到OkioAPI的转换,其作用是一个适配器(adapter)。比如从File/Socket创建Sink/Source,从InputStream/OutputStream创建Source/Sink等,这样我们就把这套API与Java联系在一起,可以使用了。
Buffer的设计原理
接下来我们来介绍这个Buffer。

Buffer的实现,是通过一个循环双向链表来实现的。每一个链表元素是一个Segment。
Seqment
final class Segment {
/** 每一个segment所含数据的大小,固定的 */
static final int SIZE = 8192;
/** 用于共享的最小字节数,后面再解释 */
static final int SHARE_MINIMUM = 1024;
final byte[] data;
/** data数组中下一个读取的数据的位置 */
int pos;
/** data数组中下一个写入的数据的位置 */
int limit;
/** data数组被其他segsment所共享的标志 */
boolean shared;
/** 是否是自己是操作者 */
boolean owner;
/** Next segment in a linked or circularly-linked list. */
Segment next;
/** Previous segment in a circularly-linked list. */
Segment prev;
}在segment中有几个有意思的方法。
compact方法
/** * Call this when the tail and its predecessor may both be less than half * full. This will copy data so that segments can be recycled. */
public void compact() {
if (prev == this) throw new IllegalStateException();
if (!prev.owner) return; // Cannot compact: prev isn't writable.
int byteCount = limit - pos;
int availableByteCount = SIZE - prev.limit + (prev.shared ? 0 : prev.pos);
if (byteCount > availableByteCount) return; // Cannot compact: not enough writable space.
writeTo(prev, byteCount);
pop();
SegmentPool.recycle(this);
}当Segment的前一个和自身的数据量都不足一半时,会对segement进行压缩,把自身的数据写入到前一个Segment中,然后将自身进行回收。
split
将一个Segment的数据拆成两个,注意,这里有trick。如果有两个Segment相同的字节超过了SHARE_MINIMUM (1024),那么这两个Segment会共享一份数据,这样就省去了开辟内存及复制内存的开销,达到了提高性能的目的。
public Segment split(int byteCount) {
if (byteCount <= 0 || byteCount > limit - pos) throw new IllegalArgumentException();
Segment prefix;
// We have two competing performance goals:
// - Avoid copying data. We accomplish this by sharing segments.
// - Avoid short shared segments. These are bad for performance because they are readonly and
// may lead to long chains of short segments.
// To balance these goals we only share segments when the copy will be large.
if (byteCount >= SHARE_MINIMUM) {
prefix = new Segment(this);
} else {
prefix = SegmentPool.take();
System.arraycopy(data, pos, prefix.data, 0, byteCount);
}
prefix.limit = prefix.pos + byteCount;
pos += byteCount;
prev.push(prefix);
return prefix;
}SegmentPool
这是一个回收池,目前的设计是能存放64K的字节,即8个Segment。在实际使用中,建议对其进行调整。
final class SegmentPool {
/** The maximum number of bytes to pool. */
// TODO: Is 64 KiB a good maximum size? Do we ever have that many idle segments?
static final long MAX_SIZE = 64 * 1024; // 64 KiB.
/** Singly-linked list of segments. */
static Segment next;
/** Total bytes in this pool. */
static long byteCount;
...
}讲到这里,整个Buffer的实现原理也就呼之欲出了。
Buffer的写操作,实际上就是不断增加Segment的一个过程,读操作,就是不断消耗Segment中的数据,如果数据读取完,则使用SegmentPool进行回收。
当复制内存数据时,使用Segment的共享机制,多个Segment共享一份data[]。
Buffer更多的逻辑主要是跨Segment读取数据,需要把前一个Segment的尾端和后一个Segment的前端拼接在一起,因此看起来代码量相对多,但其实开销非常低。
TimeOut机制
在Okio中定义了一个类叫TimeOut,主要用于判断时间是否超过阈值,超过之后就抛出中断异常。
public void throwIfReached() throws IOException {
if (Thread.interrupted()) {
throw new InterruptedIOException("thread interrupted");
}
if (hasDeadline && deadlineNanoTime - System.nanoTime() <= 0) {
throw new InterruptedIOException("deadline reached");
}
} 有意思的是,定义了一个异步的Timeout类AsyncTimeout。在其中使用了一个WatchDog的后台线程。而AsyncTimeout本身是以有序链表的方式,按照超时的时间进行排序。在其head是一个占位的AsyncTime,主要用于启动WatchDog线程。这种异步超时主要可以用在当时间到时,就可以立即获得通知,不需要等待某阻塞方法返回时,才知道超时了。使用异步超时,timeout方法在发生超时会进行回调,需要重载timedOut()方法以处理超时事件。
小结
通过学习Okio的源代码,我们可以了解常用的应用程序优化方法及技术细节。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/133551.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
