大家好,又见面了,我是你们的朋友全栈君。
【摘要】我们参加了“2018创客中国-国家电投大数据及智能应用创新创业大赛”中的光伏发电量预测这一赛题。在比赛中我们使用的核心模型为:XGBoost+LightGBM+LSTM。最终在初赛A榜和B榜分别获得第x名,决赛获得第x+1名。本文将介绍比赛过程中,我们队的基本思路以及使用的一些方法和技巧,希望能给和我们一样刚接触比赛的同学提供一些基本技巧和入门级的实现代码。
目录
1 数据探索与数据预处理
1.1 赛题回顾
- 赛题背景
作为世界第一大清洁能源的太阳能相对煤炭石油等能源来说是可再生、无污染的,只要有太阳就有太阳能,所以太阳能的利用被很多国家列为重点开发项目。但太阳能具有波动性和间歇性的特性,太阳能电站的输出功率受光伏板本体性能、气象条件、运行工况等多种因素影响,具有很强的随机性,由此带来的大规模并网困境严重制约着光伏发电的发展。通过对未来光伏发电功率的短期准确预测并设定调度计划是解决此问题的关键。目前,光伏发电功率预测技术多仅围绕气象条件和历史数据建模,而忽略了光伏板本体性能和实际运行工况对发电效率的影响,因此无法保障短期发电功率预测精度。- 赛题任务
在分析光伏发电原理的基础上,论证了辐照度、光伏板工作温度等影响光伏输出功率的因素,通过实时监测的光伏板运行状态参数和气象参数建立预测模型,预估光伏电站瞬时发电量,根据光伏电站DCS系统提供的实际发电量数据进行对比分析,验证模型的实际应用价值。
1.2 数据探索性分析与异常值处理
光伏电站的发电量,可以看到发电量是一个周期的连续变量,周期在180到200之间,周期大小与时令有关。总共17000个ID可以大致算出是100个周期,图1画出了发电量的若干个连续周期。根据赛题信息,我们推断训练数据集的时间跨度为三个月,那么我们可以肯定一个周期代表一天,然而,因为在北半球,所以一天的光照周期会变大,并且可以在图中可以看到,形状呈正弦函数的一半,如图2所示,形状不完整的是由于,每天的天气不一样,导致光照强度的形状改变,从而发电量形状改变。

图1 发电量的周期特性 图2 发电量单个周期
图3 光照强度随ID的变化趋势
在训练集和测试集合并后,光照强度等多个特征都是随着 ID而大致上连续变化,并且ID本身在合并后本身就连续,所以有理由相信,测试集和训练集在同一个数据集里面随机抽取形成两个集合。这张图可以看出,光照强度会随着ID的增大,峰值会随着增大,由于题目提示了这些数据是2月14后的数据,所以可以推测,赛题中光伏电站在北半球。
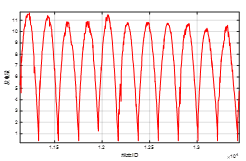
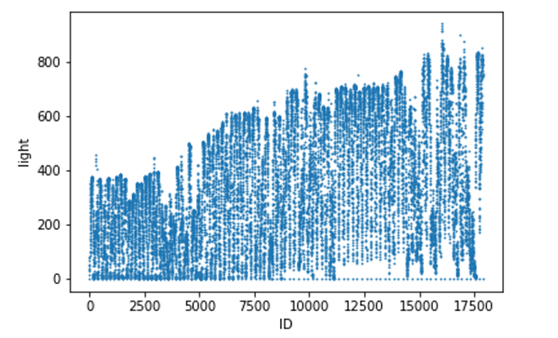
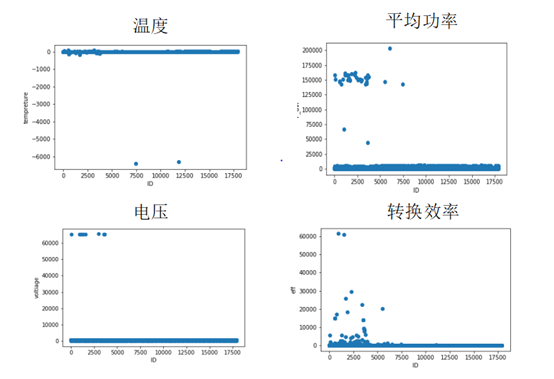
图4 温度,平均功率,电压A及转换效率的异常值
图4绘制了几个变量的散点图,我们从图中发现,这几个特征都存在异常值和离群点,例如温度是-6000,电压大于6万,平均功率大于25000,风向大于360(根据常识这个量纲肯定是360°),还有转换效率1万到3万这些离群点,发现有些异常值是几个特征同时出现。
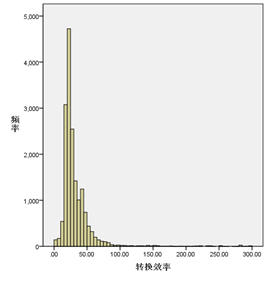
图5绘制了“平均功率”和“转换效率”这两个特征的数值分布图,分别体现了两类不同的分布:符合周期性的特征,会呈现如下图平均功率一样的双峰分布,其余特征会呈现正态分布,因此我们对于异常值的判定是数据超出平均值上下三个标准差之外部分,异常值使用本列前一个值代替,因为数据具有连续性和周期性。
另一方面,由于每天日落后光伏板不在发电,我们发现有一些停止发电的点,发电量是固定值,我们并未利用此漏洞。
图5 平均功率和转换效率的数值分布
1.3 相关性分析
首先我们观察了各特征与发电量的皮尔森相关系数,结果记录在表1中,这可以在一定程度上判断特征对于预测的作用。
通过数据可视化,我们发现光照强度/40的曲线基本和发电量的曲线一致,如图6所示。平均功率除以480的曲线基本和发电量的曲线一致,如图7。电流和发电量也基本一直,如图8所示。
图6 光照强度/40
图7 平均功率/480
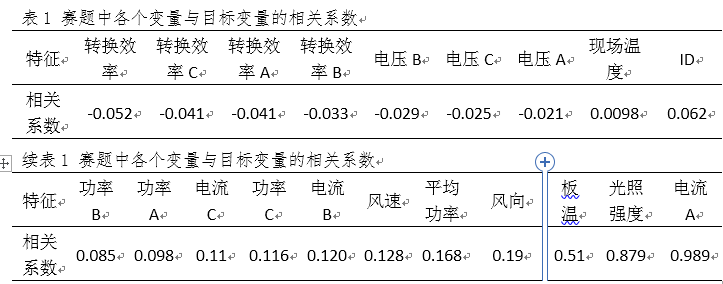
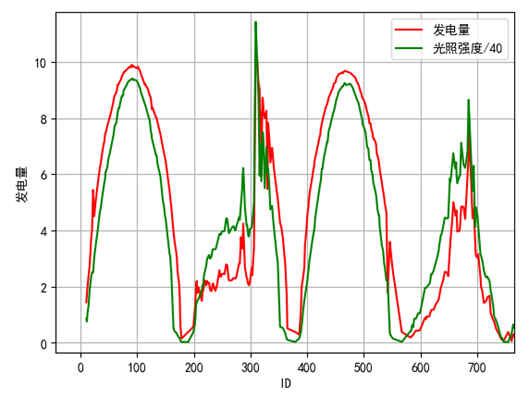
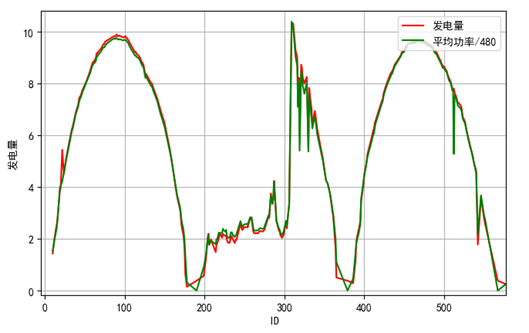
图8 电流A*1.4
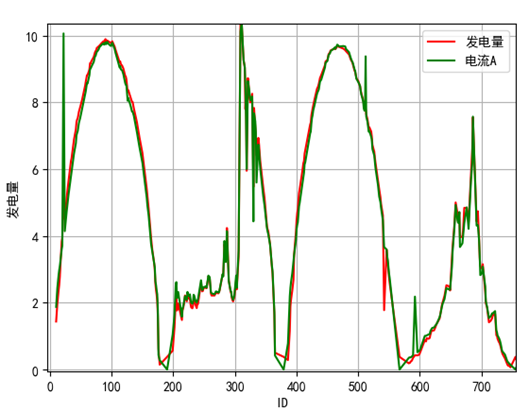
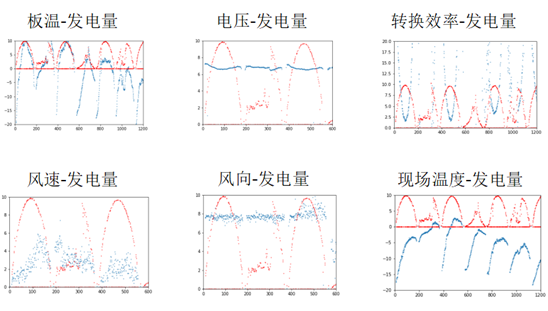
板温和现场温度与发电量的相关性虽然没强特征那么高,但趋势也是大致一样,电压基本稳定在一个范围没有呈现周期性,风向也是稳定在一个值附近,说明这三个月吹的是定向风,而风速分布没有什么规律。转换效率和发电量基本上是负相关,而发电量和光照强度相关性极高,那么可以知道,当光照强度越强,转换效率越低,查阅文献得知这是因为光照提高温度,而温度在一定范围外,升高会降低效率。图8画出了以上三个特征与发电量的对比情况。
图8 板温、电压、转换效率,风速,风向,现场温度与发电量变化趋势对比
2 特征工程
2.1 光伏发电领域特征
光伏电站利用电池板的光生伏特效应将光转化为电能。分析光伏发电系统的工作原理、功率输入输出特征后,可以对影响光电出力的因素进行建模,并且利用已有的数据产生新的特征用于光电出力预测[1]。
关键特征1:二极管正向电流 。
图9 光伏电站等效电路示意图
(1)其中, 为光伏电池二极管PN结反向饱和电流
(2)关键特征2:前一时刻功率
光照强度以及光伏电站的设备状况随时间变化较为缓慢,使用前一时刻的功率作为特征具有一定的参考价值。
关键特征3:距离周期内峰值的距离(dis2peak)、相同距离的平均功率(mean)、标准差(std)
图10 根据发电量的周期特性添加“峰值距离”特征
关键特征4:温差(板温-环境温度)
板温,现场温度会发电量影响发电量,二者的变化趋势如图11所示,它们差值和发电量也有较强的关系,如图12所示。
图11 板温、现场温度与发电量的变化趋势对比
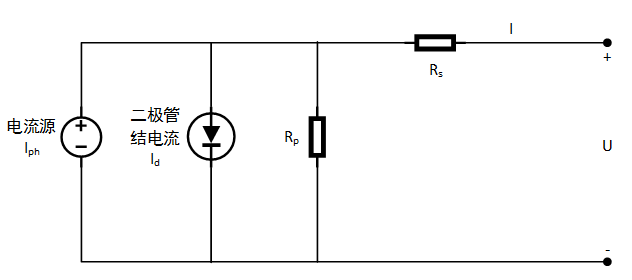
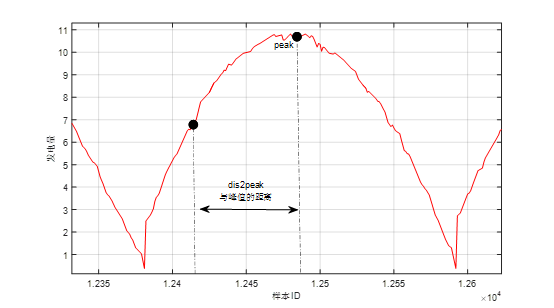
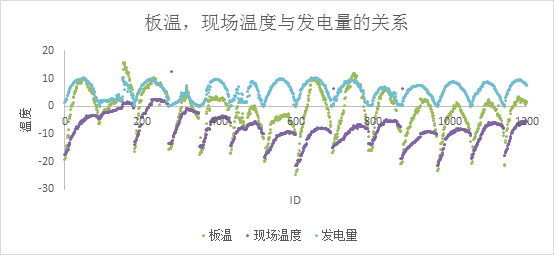
图12 温差与发电量的变化趋势对比
关键特征5: 电压A/转换效率=实际板面所受光照
由于一天中日照角度的变化,已经提供的光照强度不能直接反应板面所受光照。通过查阅有关资料,转换效率计算方法为光伏板输出功率/日照功率, 其中光伏板输出功率我们用电压A代表,已知转换效率的情况下,电压A/转换效率可以表示板面实际光光照。
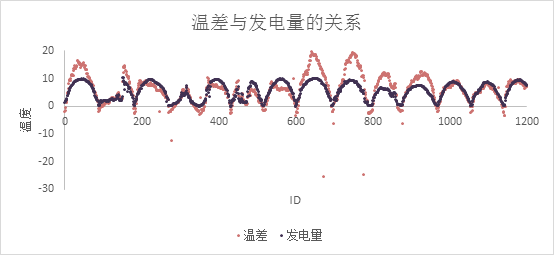
图12 温差与发电量的变化趋势对比
关键特征6: 功率/该节点的风速
通过论文《风力发电机风速、功率、功率曲线的分析》得知,风速能够影响发电机的输出功率,从而进一步的影响发电量,因此我们构造出特征每个节点的功率/该节点的风速。
2.2 高阶环境特征
特种工程中一种思想是利用已有特征的组合,计算其高阶特征, 经过特征选择我们发现 ‘板温’,‘现场温度’,‘光照强度’,‘风速’,‘风向’ 即环境因素的两两之间的2阶交互项可以提供较好的预测效果。
2.3 特征选择
在比赛中,我们的基本思路是,不同模型使用不同的特征。这是由于在比赛过程中,我们发现在某个模型上十分有效的特征在另外一个模型上并不一定能够得到很好的结果。
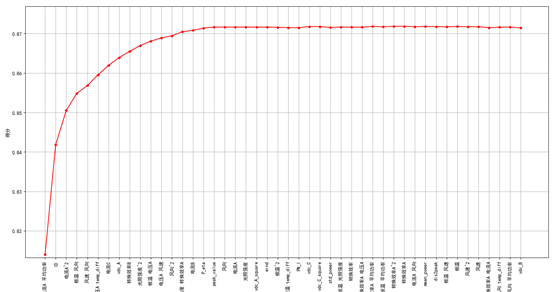
此外,我们在比赛中使用了“前向特征选择”的方法。这种方法基本的过程是,先选择一个预测性能最好参数,然后在剩下的特征中继续选择一个与已有的特征一起作为特征集,使得分最高。以此类推,直到达到预先设定的最大特征数量或者全部特征集。
图13绘制了前向特征选择过程中,陆续加入特征,模型的得分情况。测试过程使用的是LightGBM模型(详细参数见所提交的代码)。
图13 前向特征选择得分曲线
3 模型构建与调试
3.1 预测模型整体结构
这是一个连续目标变量回归预测问题,很多模型都能有效的解决此类问题。但是,不同的模型原理和所得结果之间是存在差异的。在比赛中我们借鉴了Stacking的思想,融合了LightGBM、XGBoost以及LSTM三个模型。其中前两类可以看作是树模型,LSTM为神经网络模型。这两类模型原理相差较大,产生的结果相关性较低,融合有利于提高预测准确性。具体的模型结构如图14及说明如下:
图14 预测模型整体结构
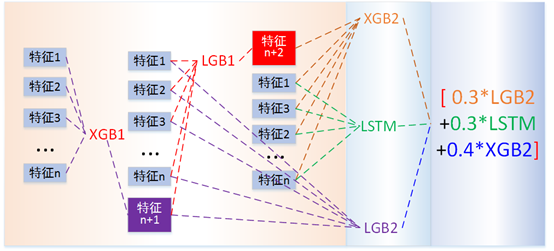
我们使用Xgboost_1对特征组合F1进行学习,得到Xgboost_1的预测结果(包括对于训练集和测试集的预测结果),该结果会作为新特征,加入特征组合F2,F3中,分别作为第二层LightGBM_1 和 LightGBM_2的输入特征,LightGBM_1的结果再次作为新特征,加入特征组合F4中,作为第三层Xgboost_2的输入特征,同时第三层包含一个LSTM模型,该模型使用特征组合F5训练,第二层LightGBM_2的结果则与第三层Xgboost_2,LSTM的预测结果进行加权融合作为最终结果。
3.2 基于LightGBM与XGBoost的构建与调试
在本问题中,一个严重的问题是过拟合,我们发现模型在训练样本中表现优越,但是在验证数据集以及测试数据集中表现不佳,在采取了特征,样本抽样进入训练,减少树深度和正则化参数后等有效方法后,我们发现和验证以下创新的方法可以进一步减少过拟合。
重复使用部分特征
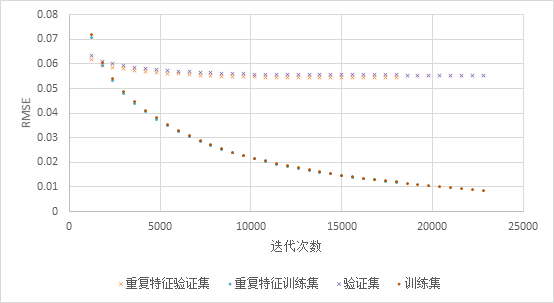
在Light GBM模型中,我们对于环境特征(板温,现场温度,光照强度,风速,风向)执行了一次复制,即这些特征会在训练中出现两次,结果显示训练集误差几乎一致,但是线上线下验证集误差都更小,也就是说,使用重复特征,减少了过拟合的程度,使得模型的泛化,预测效果更佳。
对比加入重复特征的训练集与普通训练集的训练曲线,如图15,可见使用重复特征的模型验证误差小于不使用重复特征的模型,而两者的训练误差几乎相同的。
图15 重复特征下的交叉验证误差曲线
很多文献和实验[5]表明特征选择时去除相关性高的特征是有利的,但是在本问题中我们发现重复特征虽然和已有特征的相关性很高,但是这种做法是可以提高预测准确度的,我们认为这有可能与单个树模型在抽样特征的时候,重复特征会有更大的机率被抽到有关。
关于这一点发现是否具有通用性,需要其他数据集的实验验证。
在每折交叉验证后进行预测
单模型的参数调整对于模型的表现有很大的影响,我们使用了网格搜索,交叉验证的方法,获得规定参数范围内最优的参数组合,在确定参数后,对于单模型再次在训练中使用交叉验证,一方面是可以对比不同模型的效果,一方面是我们在4折交叉验证中,每折训练结束后,都对测试集用本折交叉验证得到的模型进行一次预测。具体的说,比如对Xgboost模型,4折交叉验证,得到4个不同的“Xgboost模型”,用这4个模型分别对测试集做一次预测,最后Xgboost的预测结果是4次预测结果的平均值,这个过程可以看作是对于训练集合的一次抽样,Xgboost最终结果实际上是4个子模型结果的融合,抽样和融合可以减少过拟合,我们发现这样的处理对于本题目的预测精度有提高。
每个单模型所使用的特征都不同
每个单模型(包括LSTM),我们有90%的特征是一致的,还有大约10%特征是每个单模型独有的,通过这种方式增加模型间的差异性,摆脱对于单一特征组合的依赖,增加了模型的泛化能力,可以获得更好的融合效果。
3.3 基于LSTM的模型构建与调试
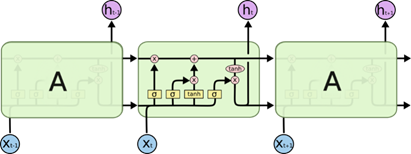
长短期记忆网络(Long Short-Term Memory, LSTM)是一种循环神经网络[6],能够处理一些由长时信息引起的问题。在LSTM中,Cell是基本的单元,图16画出了LSTM中的基本单元以及有这些基本单元连接而成的网络。
在一个Cell中,包含一个称为“门”的结构,如图17。Sigmoid( )函数输出在0到1之间,如果与上一个Cell的输出相乘,这样就决定了多少信息量可以通过。
图16 LSTM示例 图17 “门”结构
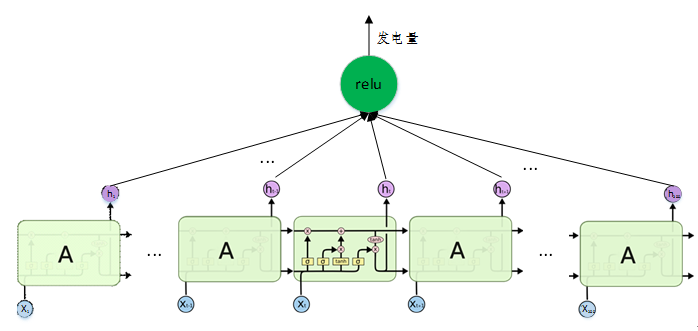
在本次比赛中,我们使用了一个包含200个单元的LSTM单层网络,结构如图18。
图18 比赛中使用的LSTM网络结构
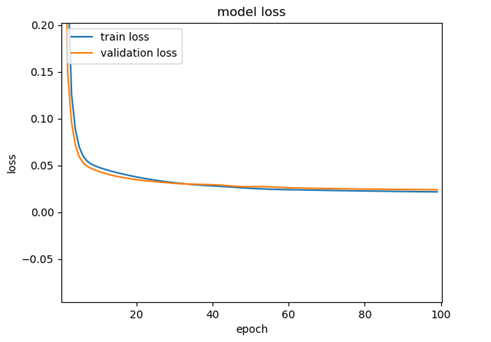
网络的训练和验证集误差曲线如图19。
图19 LSTM训练误差图
3.4 模型融合与总结
模型融合是一种非常有效的技术,可以在大部分的机器学习任务中提高回归或者分类的准确性。可以直接使用不同模型的结果文件进行融合,也可以使用一个模型的预测结果作为另一个模型的特征进行训练,然后得到新的预测结果。我们在比赛中,综合使用了这两种融合方法。
不同类型的模型学习训练的原理不同,所学到的知识也不一样。不同的模型可能在不同的方面学习能力不一样。在本赛题中,通过参赛过程中的提交可以发现,树模型(XGBoost和LightGBM)以及LSTM单模型的学习能力都较强,在对几个模型进行线性融合之后,预测能力进一步增强。融合模型取得了了比赛中最好的成绩。
4 总结与展望
非常感谢国家电投和DF平台举办这样一个比赛,在比赛中,我们收获了友谊和知识,锻炼了能力,开拓了视野。
在比赛中,我们认为以下方面的因素使得我们比赛过程中不断超越自我,获得好成绩。
从团队方面来看,我们始终彼此相互信任,勤于沟通,分工协作,不轻言放弃。这些团队因素在整个比赛中支撑着我们全程不管是落后多人或者领跑全榜,始终在查找新的文献资料,始终在思考性的突破口。正是一次又一次的尝试,让我们的特征更加强效,模型更加完善,最终产出高分结果。
从技术层面来看,有以下几个方面:
- 合理的数据预处理
我们观察到了数据中的异常点,并将训练数据和测试数据使用相同的方式进行异常值修复(前值填充)- 高效的特征构造与选择
我们通过查阅光伏发电领域文献与资料,构造了如二极管节点流,计算转换效率等强有力的特征。此外我们使用了较为科学的特征选择方法——前向特征选择。- 精心设计融合模型
基于LightGBM、XGBoost和LSTM三种模型而构造的融合模型,可以综合三种模型的互补优势,同时减小过拟合的影响。
代码地址:
链接: https://pan.baidu.com/s/1UYMqwARTi6343j5MSDOH4Q 提取码: iusx
参考文献
[1] 王坤. 考虑多重不确定性因素的光伏出力预测研究[D]. 华北电力大学, 2013.
[2] 王玉清. PN结反向饱和电流的实验研究[J]. 延安大学学报(自然科学版), 2010, 29(1):53-55.
[3] 吕学梅, 孙宗义, 曹张驰. “电池板温度及辐射量对光伏发电量影响的趋势面分析.” 创新驱动发展 提高气象灾害防御能力——S6短期气候预测理论、方法与技术 2013:922-927.
[4] 窦砚林. 风力发电机风速、功率、功率曲线的分析[J]. 科学导报, 2014(z2)
[5] Hall M A. Correlation-based feature selection for machine learning[J]. 1999.
[6] http://colah.github.io/posts/2015-08-Understanding-LSTMs/
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/133532.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
