大家好,又见面了,我是你们的朋友全栈君。


1、保证内存可见性
内存可见性,即线程A对volatile变量的修改,其他线程获取的volatile变量都是最新的。
说到内存可见性就必须要提到Java的内存模型,如下图所示:
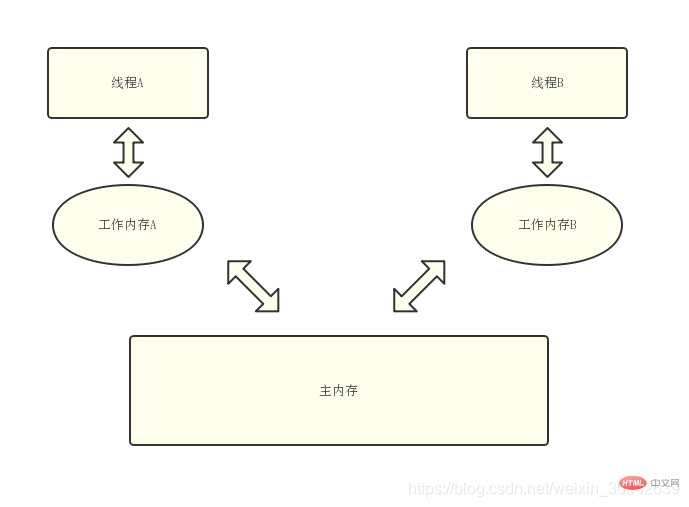
如上图所示,所有线程的共享变量都存储在主内存中,每一个线程都有一个独有的工作内存,每个线程不直接操作在主内存中的变量,而是将主内存上变量的副本放进自己的工作内存中,只操作工作内存中的数据。当修改完毕后,再把修改后的结果放回到主内存中。每个线程都只操作自己工作内存中的变量,无法直接访问对方工作内存中的变量,线程间变量值的传递需要通过主内存来完成。
上述的Java内存模型在单线程的环境下不会出现问题,但在多线程的环境下可能会出现脏数据,例如:如果有AB两个线程同时拿到变量i,进行递增操作。A线程将变量i放到自己的工作内存中,然后做+1操作,然而此时,线程A还没有将修改后的值刷回到主内存中,而此时线程B也从主内存中拿到修改前的变量i,也进行了一遍+1的操作。最后A和B线程将各自的结果分别刷回到主内存中,看到的结果就是变量i只进行了一遍+1的操作,而实际上A和B进行了两次累加的操作,于是就出现了错误。究其原因,是因为线程B读取到了变量i的脏数据的缘故。
此时如果对变量i加上volatile关键字修饰的话,它可以保证当A线程对变量i值做了变动之后,会立即刷回到主内存中,而其它线程读取到该变量的值也作废,强迫重新从主内存中读取该变量的值,这样在任何时刻,AB线程总是会看到变量i的同一个值。
1.1 MESI缓存一致性协议
volatile可见性是通过汇编加上Lock前缀指令,触发底层的MESI缓存一致性协议来实现的。当然这个协议有很多种,不过最常用的就是MESI。MESI表示四种状态,如下所示:状态描述M 修改(Modified)此时缓存行中的数据与主内存中的数据不一致,数据只存在于本工作内存中。其他线程从主内存中读取共享变量值的操作会被延迟执行,直到该缓存行将数据写回到主内存后
E 独享(Exclusive)此时缓存行中的数据与主内存中的数据一致,数据只存在于本工作内存中。此时会监听其他线程读主内存中共享变量的操作,如果发生,该缓存行需要变成共享状态
S 共享(Shared)此时缓存行中的数据与主内存中的数据一致,数据存在于很多工作内存中。此时会监听其他线程使该缓存行无效的请求,如果发生,该缓存行需要变成无效状态
I 无效(Invalid)此时该缓存行无效
假如说当前有一个cpu去主内存拿到一个变量x的值初始为1,放到自己的工作内存中。此时它的状态就是独享状态E,然后此时另外一个cpu也拿到了这个x的值,放到自己的工作内存中。此时之前那个cpu会不断地监听内存总线,发现这个x有多个cpu在获取,那么这个时候这两个cpu所获得的x的值的状态就都是共享状态S。然后第一个cpu将自己工作内存中x的值带入到自己的ALU计算单元去进行计算,返回来x的值变为2,接着会告诉给内存总线,将此时自己的x的状态置为修改状态M。而另一个cpu此时也会去不断的监听内存总线,发现这个x已经有别的cpu将其置为了修改状态,所以自己内部的x的状态会被置为无效状态I,等待第一个cpu将修改后的值刷回到主内存后,重新去获取新的值。这个谁先改变x的值可能是同一时刻进行修改的,此时cpu就会通过底层硬件在同一个指令周期内进行裁决,裁决是谁进行修改的,就置为修改状态,而另一个就置为无效状态,被丢弃或者是被覆盖(有争论)。
当然,MESI也会有失效的时候,缓存的最小单元是缓存行,如果当前的共享数据的长度超过一个缓存行的长度的时候,就会使MESI协议失败,此时的话就会触发总线加锁的机制,第一个线程cpu拿到这个x的时候,其他的线程都不允许去获取这个x的值。
2、禁止指令重排序
指令的执行顺序并不一定会像我们编写的顺序那样执行,为了保证执行上的效率,JVM(包括CPU)可能会对指令进行重排序。比方说下面的代码:int i = 1;
int j = 2;
上述的两条赋值语句在同一个线程之中,根据程序上的次序,“int i = 1;”的操作要先行发生于“int j = 2;”,但是“int j = 2;”的代码完全可能会被处理器先执行。JVM会保证在单线程的情况下,重排序后的执行结果会和重排序之前的结果一致。但是在多线程的场景下就不一定了。最典型的例子就是双重检查加锁版的单例实现,代码如下所示:public class Singleton {
private volatile static Singleton instance;
private Singleton() {}
public static Singleton getInstance() {
if (instance == null) {
synchronized (Singleton.class) {
if (instance == null) {
instance = new Singleton();
}
}
}
return instance;
}
}
由上可以看到,instance变量被volatile关键字所修饰,但是如果去掉该关键字,就不能保证该代码执行的正确性。这是因为“instance = new Singleton();”这行代码并不是原子操作,其在JVM中被分为如下三个阶段执行:为instance分配内存
初始化instance
将instance变量指向分配的内存空间
由于JVM可能存在重排序,上述的二三步骤没有依赖的关系,可能会出现先执行第三步,后执行第二步的情况。也就是说可能会出现instance变量还没初始化完成,其他线程就已经判断了该变量值不为null,结果返回了一个没有初始化完成的半成品的情况。而加上volatile关键字修饰后,可以保证instance变量的操作不会被JVM所重排序,每个线程都是按照上述一二三的步骤顺序的执行,这样就不会出现问题。
2.1 内存屏障
volatile有序性是通过内存屏障实现的。JVM和CPU都会对指令做重排优化,所以在指令间插入一个屏障点,就告诉JVM和CPU,不能进行重排优化。具体的会分为读读、读写、写读、写写屏障这四种,同时它也会有一些插入屏障点的策略,下面是JMM基于保守策略的内存屏障点插入策略:屏障点描述每个volatile写的前面插入一个store-store屏障禁止上面的普通写和下面的volatile写重排序
每个volatile写的后面插入一个store-load屏障禁止上面的volatile写与下面的volatile读/写重排序
每个volatile读的后面插入一个load-load屏障禁止下面的普通读和上面的volatile读重排序
每个volatile读的后面插入一个load-store屏障禁止下面的普通写和上面的volatile读重排序
上面的插入策略非常保守,但是它可以保证在任意处理器平台上的正确性。在实际执行时,编译器可以省略没必要的屏障点,同时在某些处理器上会做进一步的优化。
3、不保证原子性
需要重点说明的一点是,尽管volatile关键字可以保证内存可见性和有序性,但不能保证原子性。也就是说,对volatile修饰的变量进行的操作,不保证多线程安全。请看以下的例子:public class Test {
private static CountDownLatch countDownLatch = new CountDownLatch(1000);
private volatile static int num = 0;
public static void main(String[] args) {
ExecutorService executor = Executors.newCachedThreadPool();
for (int i = 0; i < 1000; i++) {
executor.execute(() -> {
try {
num++;
} catch (Exception e) {
e.printStackTrace();
} finally {
countDownLatch.countDown();
}
});
}
try {
countDownLatch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
executor.shutdown();
System.out.println(num);
}
}
静态变量num被volatile所修饰,并且同时开启1000个线程对其进行累加的操作,按道理来说,其结果应该为1000,但实际的情况是,每次运行结果可能都是一个小于1000的数字(也有结果为1000的时候,但出现几率很小),并且不固定。那么这是为什么呢?原因是因为“num++;”这行代码并不是原子操作,尽管它被volatile所修饰了也依然如此。++操作的执行过程如下面所示:首先获取变量i的值
将该变量的值+1
将该变量的值写回到对应的主内存中
虽然每次获取num值的时候,也就是执行上述第一步的时候,都拿到的是主内存的最新变量值,但是在进行第二步num+1的时候,可能其他线程在此期间已经对num做了修改,这时候就会触发MESI协议的失效动作,将该线程内部的值作废。那么该次+1的动作就会失效了,也就是少加了一次1。比如说:线程A在执行第一步的时候读取到此时num的值为3,然后在执行第二步之前,其他多个线程已经对该值进行了修改,使得num值变为了4。而线程A此时的num值就会失效,重新从主内存中读取最新值。也就是两个线程做了两次+1的动作,但实际的结果最后只加了一次1。所以这也就是最后的执行结果为什么大概率会是一个小于1000的值的原因。
所以如果要解决上面代码的多线程安全问题,可以采取加锁synchronized的方式,也可以使用JUC包下的原子类AtomicInteger,以下的代码演示了使用AtomicInteger来包装num变量的方式:public class Test {
private static CountDownLatch countDownLatch = new CountDownLatch(1000);
private static AtomicInteger num = new AtomicInteger();
public static void main(String[] args) {
ExecutorService executor = Executors.newCachedThreadPool();
for (int i = 0; i < 1000; i++) {
executor.execute(() -> {
try {
num.getAndIncrement();
} catch (Exception e) {
e.printStackTrace();
} finally {
countDownLatch.countDown();
}
});
}
try {
countDownLatch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
executor.shutdown();
System.out.println(num);
}
}
多次运行上面的代码,结果都为1000。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/133519.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
