大家好,又见面了,我是你们的朋友全栈君。
html页面导出pdf,本来是一件很简单的事情,在浏览器直接打印(Mac快捷键为⌘+p;Windows快捷键为ctrl+p),就可以把页面另存为pdf文件,但对于要经常把页面导出为pdf的用户来说并不友好,一个合格程序员的标准就是:做出来的软件猪都要会用,否则你就是猪。
调研了几种html导出pdf的实现方式,这里把要点记录下来分享下。
| 调研对象 | 优点 | 缺点 | 分页 | 图片 | 表格 | 链接 | 中文 | 特殊字符、样式 | 导出样例 | 备注 |
|---|---|---|---|---|---|---|---|---|---|---|
| jsPDF | 1、整个过程在客户端执行(不需要服务器参与),调用简单 | 1、生成的pdf为图片形式,且内容失真 | 支持 | 支持 | 支持 | 不支持 | 支持 | 支持 | ||
| iText | 1、功能基本可以实现,比较灵活2、生成pdf质量较高 | 1、对html标签严;格,少一个结束标签就会报错;2、后端实现复杂,服务器需要安装字体;3、图片渲染比较复杂(暂时还没解决) | 支持 | 支持 | 支持 | 支持 | 支持 | 支持 | ||
| wkhtmltopdf | 1、调用方式简单(只需执行一行脚本);2、生成pdf质量较高 | 1、服务器需要安装wkhtmltopdf环境;2、根据网址生成pdf,对于有权限控制的页面需要在拦截器进行处理 | 支持 | 支持 | 支持 | 支持 | 支持 | 支持 |
上面三种是着重调研的三种方式,下面进行简单介绍。
一、html2canvas+jsPDF
这种方式的原理是利用html2canvas遍历页面中的dom节点,渲染成canvas image,再用jsPDF把canvas image转化为pdf,最后转化的pdf的内容都是图片形式,类似于把整个网页截图、切割,再一页一页拼接成一个完整的pdf。
代码样例
html:
<button id="exportToPdf">导出为PDF</button>
<div id="export_content">
这里是要导出为pdf中的内容
</div>
javascript(需要依赖jspdf和html2canvas相关js):
<script src="js/jspdf.debug.js"></script>
<script src="js/html2canvas.js"></script>
<script type="text/javascript">
var downPdf = document.getElementById("exportToPdf");
downPdf.onclick = function () {
html2canvas(
document.getElementById("export_content"),
{
dpi: 172,//导出pdf清晰度
onrendered: function (canvas) {
var contentWidth = canvas.width;
var contentHeight = canvas.height;
//一页pdf显示html页面生成的canvas高度;
var pageHeight = contentWidth / 592.28 * 841.89;
//未生成pdf的html页面高度
var leftHeight = contentHeight;
//pdf页面偏移
var position = 0;
//html页面生成的canvas在pdf中图片的宽高(a4纸的尺寸[595.28,841.89])
var imgWidth = 595.28;
var imgHeight = 592.28 / contentWidth * contentHeight;
var pageData = canvas.toDataURL('image/jpeg', 1.0);
var pdf = new jsPDF('', 'pt', 'a4');
//有两个高度需要区分,一个是html页面的实际高度,和生成pdf的页面高度(841.89)
//当内容未超过pdf一页显示的范围,无需分页
if (leftHeight < pageHeight) {
pdf.addImage(pageData, 'JPEG', 0, 0, imgWidth, imgHeight);
} else {
while (leftHeight > 0) {
pdf.addImage(pageData, 'JPEG', 0, position, imgWidth, imgHeight)
leftHeight -= pageHeight;
position -= 841.89;
//避免添加空白页
if (leftHeight > 0) {
pdf.addPage();
}
}
}
pdf.save('content.pdf');
},
//背景设为白色(默认为黑色)
background: "#fff"
})
}
</script>
这种方法的优点是所有的过程都由js在客户端完成,不需要依赖服务器。
目前发现的两个比较明显的缺点:
1、生成的pdf质量不高,失真比较严重(不过在github上这个方法可以适当提高下生成pdf的清晰度https://github.com/niklasvh/html2canvas/pull/1087);
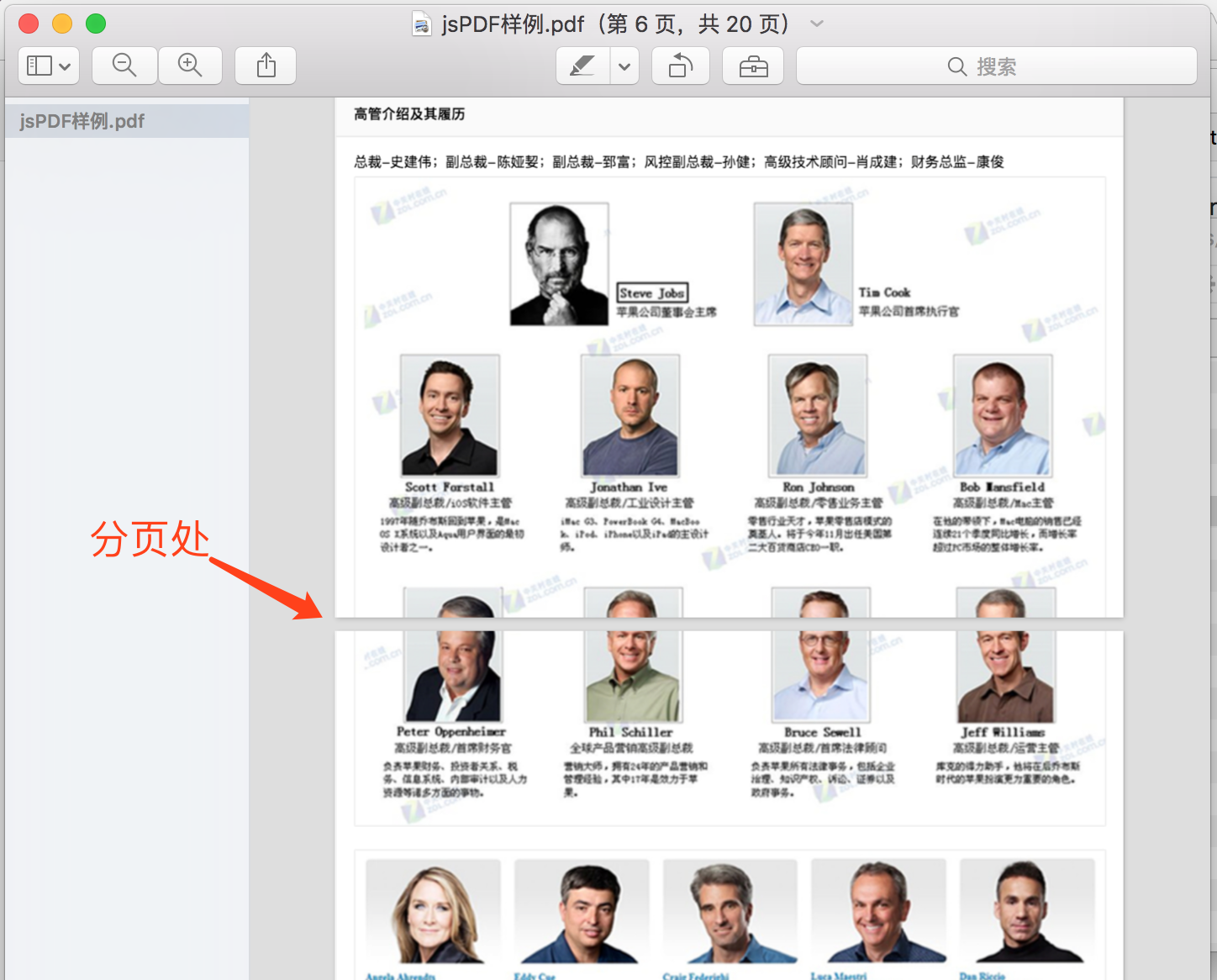
2、在分页处如果有图片的话,不会自动识别隔页处理(甚至一行文字也能给你上下一分为二),而是无情地把图片一分为二,满满的违和感~如下图:

github上有一篇文章说明比较详细,还有具体的demo:https://github.com/linwalker/render-html-to-pdf
二、iText
iText是一个第三方报表java插件,可以在后端利用java随意生成、转化pdf文件,提供了很多api,比较灵活。
代码样例
pom依赖:
<dependency>
<groupId>org.eclipse.birt.runtime.3_7_1</groupId>
<artifactId>com.lowagie.text</artifactId>
<version>2.1.7</version>
</dependency>
<dependency>
<groupId>org.xhtmlrenderer</groupId>
<artifactId>flying-saucer-pdf</artifactId>
<version>9.0.8</version>
</dependency>
<dependency>
<groupId>com.itextpdf</groupId>
<artifactId>itextpdf</artifactId>
<version>5.4.2</version>
</dependency>
java实现:
ITextRenderer renderer = new ITextRenderer();
ITextFontResolver fontResolver = renderer.getFontResolver();
fontResolver.addFont("/Users/hehe/share/Fonts/simsun.ttc", BaseFont.IDENTITY_H, BaseFont.NOT_EMBEDDED);
OutputStream os = new FileOutputStream("/Users/hehe/Desktop/iTextPDF.pdf");
String htmlstr = HttpHandler.sendGet("http://localhost:10086/test/iTextPDF.html");//HttpHandler.sendGet只是单纯获得指定网页的html字符串内容
renderer.setDocumentFromString(htmlstr);
renderer.layout();
renderer.createPDF(os);
以上只是简单利用html字符串来生成pdf,需要注意的是:
1、如果页面中有中文,服务器端需要下载字体库simsun.ttc,在后台进行引用,同时在页面的样式中加入对应字体的定义,如:body{font-family: SimSun;},否则中文无法渲染(中文处渲染出来的效果是空白);
2、页面中如果有图片,如果图片引用是绝对路径或者base64则不用考虑,如果是相对路径,需要在后台用renderer.getSharedContext().setBaseURL("图片绝对路径目录");来指定图片路径,否则图片无法渲染。
3、要转化的页面必须是标准的XHTML页面,有一处不符合规范就会报错,小编再试的时候就经常报诸如org.xml.sax.SAXParseException;lineNumber: 24; columnNumber: 6;元素类型 "span" 必须由匹配的结束标记 "</span> 终止"之类的错误,所以如果要用iText来大量爬取网络中的页面的话,还是放弃吧,毕竟网上很多页面都是不标准的~
三、wkhtmltopdf
wkhtmltopdf是一个可以把html转为pdf的插件,有windows、linux等平台的版本,最大的特点就是使用简单,语言无关性。
1、下载:官网下载 https://wkhtmltopdf.org/downloads.html
2、执行:该插件是“绿色版”,无需编译安装,下载解压后,在bin目录下有wkhtmltoimage和wkhtmltopdf两个文件,生成pdf可以直接运行wkhtmltopdf(也可以把bin目录配置到环境变量),执行wkhtmltopdf -V查看是否可以执行。
执行的时候可能会报错wkhtmltopdf: error while loading shared libraries: libXrender.so.1 或者 ./wkhtmltopdf: error while loading shared libraries: libfontconfig.so.1: cannot open shared object file: No such file or directory 具体解决方法可参考https://www.svennd.be/wkhtmltopdf-error-while-loading-shared-libraries-libxrender-so-1/
如果执行完打印出wkhtmltopdf的版本号,则说明OK了,下面来一个打印html页面的例子试试看,就把本页面转化成pdf吧:
wkhtmltopdf --disable-smart-shrinking https://blog.csdn.net/huyuyang6688/article/details/79710704 myBlog.pdf
执行完之后,就会在当前目录生成一个pdf(当然生成pdf的目录可以指定),--disable-smart-shrinking 这个参数是关闭缩放,如果不加的话,生成的pdf内容会特别“瘦”,不造为啥这个命令在mac环境下不是很有效,不敢在linux环境生成的PDF是正常的。具体更详细的用法可以参考如下文章:
1、HTML 转 PDF 之 wkhtmltopdf 工具简介
2、HTML 转 PDF 之 wkhtmltopdf 工具精讲
3、wkhtmltopdf参数详解
4、解决wkhtmltopdf支持中文和缩放问题:wkhtmltopdf折腾记
与之类似的还有一个叫Phantomjs的插件,效果差不多,还没深入研究。
**注意:**以上是小编在调研过程中的一些记录,分享给大家作参考,希望对您有所帮助,如果有其他疑问,欢迎交流沟通。【 转载请注明出处——胡玉洋《html页面导出为pdf(jsPDF、iText、wkhtmltopdf)》】
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/133456.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
