大家好,又见面了,我是你们的朋友全栈君。
原文链接
数据是建模的基础,也是研究事物发展规律的材料。数据本身的可信度和处理的方式将直接决定模型的天花板在何处。一个太过杂乱的数据,无论用多么精炼的模型都无法解决数据的本质问题,也就造成了模型的效果不理想的效果。这也是我们目前所要攻克的壁垒。但是,目前我们市场对的数据或者科研的数据并不是完全杂乱无章的,基本都是有规律可循的,因此,用模型算法去进行科学的分析,可以主观情绪对决策的影响。所以数据是非常重要的一部分。那么,接下来我们就详细说一下数据的处理与分析。
一.数据的基本特征
当看到数据的时候,首要做的并不是进行清洗或者特征工程,而是要观察数据所呈现的基本状态,以及进行数据与任务的匹配,这就需要我们之前所提到的业务常识与数据敏感度的能力了,只有数据完整的分析完整,才能够更为精准的做符合需求的特征工程(数据处理)的工作。数据的基本特征分析主要从以下几个方面进行:
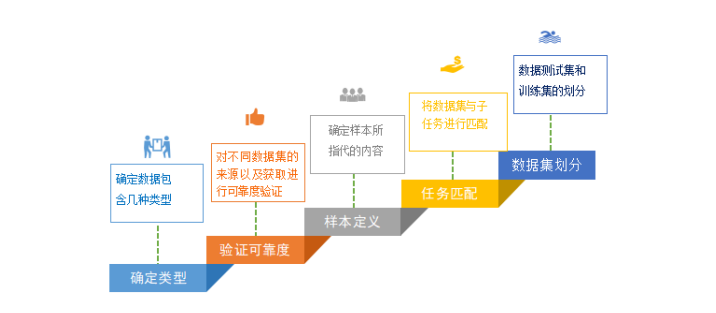

1.确定类型:数据集的类型包括文本,音频,视频,图像,数值等多种形式交织而成,但是传入模型中的都是以数值形式呈现的,所以确定数据的类型,才可以确定用什么方法进行量化处理。
2.验证可靠度:由于数据的收集的方式不尽相同,数据来源的途径多种多样。所以数据的可信度判断也显得尤为重要。而数据可靠性校验得方法非常多。例如:根据收集途径判断,如果调查问卷也可根据问卷设计得可靠度进行判断,当然转化为数值后也可辅助一些模型进行精细校验等。采用何种方式,取决于获取数据得方式,数据类型以及项目得需求。
3.样本定义:需要确定样本得对应得每一个特征属性的内容是什么。例如:样本的容量,样本的具体内容,样本所包含的基本信息等。
4.任务匹配:在任务分析中我们把项目拆分成了小的子问题,这些问题有分类,回归,关联关系等。也就是每个问题的所达成的目标是不一样的,那么我们要从数据集中筛选出符合子问题的数据,也就是选好解决问题的原料,很多情况下是靠你的数据敏感度和业务常识进行判断的。
5.数据集的划分:由于模型搭建完成之后有一个训练与验证评估的过程,而目前最为简单的一种验证手段就是就是交叉验证,因此我们需要将数据集拆分成训练集和测试集,这一步仅仅确定训练集和测试集的比例关系,例如:70%的数据用于训练,30%的数据用于测试。
二. 数据的清洗与处理
数据的清洗是一件非常繁琐且耗费时间的事情,基本可以占到一个工程的30%到50%的时间。并且数据的清洗很难有规律可循,基本上依托于你对数据的基本分析与数据敏感度。当然,当你看的数据够多,数据的清洗的经验也就越多,会为你今后哦搭建模型提供很多遍历,我们这里提供一些常见的清洗的点。
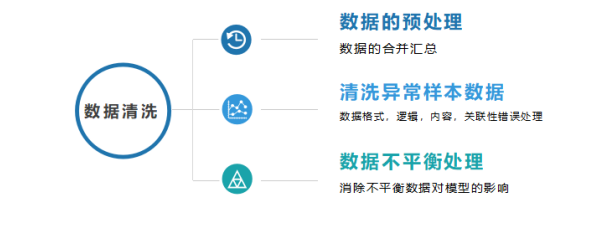
A. 数据的预处理:
1.由于数据的来源大多数是来源于多个途径,因此需要对数据进行合并;
2.选择数据处理工具:数据库或者python,spss等。
3.通过人工的方式去观察数据可能出现的问题。
B.清洗异常样本数据
清洗异常数据样本需要考虑到方方面面,通常情况下我们从以下方面:
1.处理格式或者内容错误:
首先,观察时间,日期,数值等是否出现格式不一致,进行修改整理;其次,注意开头,或者中间部分是否存在异常值;最后,看字段和内容是否一致。例如,姓名的内容是男,女。
2.逻辑错误清洗:
去重:通常我们收集的数据集中有一些数据是重复的,重复的数据会直接影响我们模型的结果,因此需要进行去重操作;
去除或者替换不合理的值:例如年龄突然某一个值是-1,这就属于不合理值,可用正常值进行替换或者去除;
修改矛盾内容:例如身份证号是91年的,年龄35岁,显然不合理,进行修改或者删除。
3.去除不要的数据:根据业务需求和业务常识去掉不需要的字段
4.关联性错误验证:由于数据来源是多个途径,所以存在一个id,进行不同的数据收集,可通过,id或者姓名进行匹配合并。
C.数据不平衡处理:改问题主要出现在分类模型中,由于正例与负例之间样本数量差别较大,造成分类结果样本量比较少的类别会大部分分错。因此需要进行数据不平衡处理。常用的方法有:上采样,下采样,数据权重复制,异常点检测等。不在一一阐述了。

发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/133439.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
