大家好,又见面了,我是你们的朋友全栈君。
本文有视频教程,感兴趣的朋友可以前往观看 Python入坑实战系列 Part-2 – 简单数据相关性分析
概述
在我们的工作中,会有一个这样的场景,有若干数据罗列在我们的面前,这组数据相互之间可能会存在一些联系,可能是此增彼涨,或者是负相关,也可能是没有关联,那么我们就需要一种能把这种关联性定量的工具来对数据进行分析,从而给我们的决策提供支持,本文即介绍如何使用 Python 进行数据相关性分析。
关键词 python 方差 协方差 相关系数 离散度 pandas numpy
实验数据准备
接下来,我们将使用 Anaconda 的 ipython 来演示如何使用 Python 数据相关性分析,我所使用的 Python 版本为 3.6.2 。
首先,我们将会创建两个数组,数组内含有 20 个数据,均为 [0, 100] 区间内随机生成。
a = [random.randint(0, 100) for a in range(20)]
b = [random.randint(0, 100) for a in range(20)]
print(a)
>> [35, 2, 75, 72, 55, 77, 69, 83, 3, 46, 31, 91, 72, 12, 15, 20, 39, 18, 57, 49]
print(b)
>> [25, 24, 72, 91, 27, 44, 85, 21, 0, 64, 44, 31, 6, 91, 1, 61, 5, 39, 24, 43]
期望
在进行相关性分析之前,我们需要先为最终的计算分析做好准备。我们在分析前,第一个准备的是计算数据的期望。对于期望的定义,离散变量和连续变量是不一样的,具体定义如下:
-
对于连续随机变量
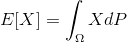

-
在离散随机变量
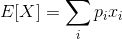
在一般情况下,我们通过实验或者调查统计获取的数据很大一部分都属于离散随机变量,那么这里的期望我们也可以简单的理解为平均数,那么既然是平均数,那么我们就可以非常简单编写一个计算离散变量的期望的函数了。
def mean(x):
return sum(x) / len(x)
mean(a)
>> 46.05
mean(b)
>> 39.9
离散度 – 方差与标准差
接下来,我们需要计算的是数据的离散程度,在统计上,我们通常会使用方差和标准差来描述。
方差和期望一样,对于连续和离散的随机变量有着不同的定义,具体定义如下:
- 对于连续随机变量
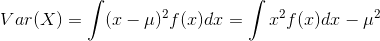
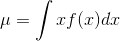
- 对于离散随机变量
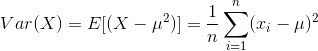
与期望类似,这里我们一般只考虑离散变量的方差。还有一点值得注意,我们上面的离散变量方差公式,最后是除以 n ,但实际上,我们计算样本方差的时候一般会使用 n-1 ,具体原因可以参考知乎 《为什么样本方差(sample variance)的分母是 n-1?》。
而标准差,就是方差的平方根。那么,我们也可以像上面计算期望一样,给方差和标准差编写函数。
# 计算每一项数据与均值的差
def de_mean(x):
x_bar = mean(x)
return [x_i - x_bar for x_i in x]
# 辅助计算函数 dot product 、sum_of_squares
def dot(v, w):
return sum(v_i * w_i for v_i, w_i in zip(v, w))
def sum_of_squares(v):
return dot(v, v)
# 方差
def variance(x):
n = len(x)
deviations = de_mean(x)
return sum_of_squares(deviations) / (n - 1)
# 标准差
import math
def standard_deviation(x):
return math.sqrt(variance(x))
variance(a)
>> 791.8394736842105
varance(b)
>> 850.5157894736841
协方差与相关系数
接下来,我们进入正题,我们开始计算两组数据的相关性。我们一般采用相关系数来描述两组数据的相关性,而相关系数则是由协方差除以两个变量的标准差而得,相关系数的取值会在 [-1, 1] 之间,-1 表示完全负相关,1 表示完全相关。接下来,我们看一下协方差和相关系数的定义:
- 协方差
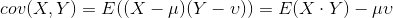
- 相关系数
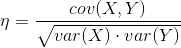
同样的,我们根据上述的公式编写函数。
# 协方差
def covariance(x, y):
n = len(x)
return dot(de_mean(x), de_mean(y)) / (n -1)
# 相关系数
def correlation(x, y):
stdev_x = standard_deviation(x)
stdev_y = standard_deviation(y)
if stdev_x > 0 and stdev_y > 0:
return covariance(x, y) / stdev_x / stdev_y
else:
return 0
covariance(a, b)
>> 150.95263157894735
correlation(a, b)
>> 0.18394200852440826
根据上面的结果,相关系数为 0.18,可以推断这两组随机数有弱正相关。当然,我们知道,这两组数据都是使用 random 函数随机生成出来的,其实并没有什么相关性,这也是在数据处理中,需要特别留意的一个地方,统计的方法可以给我们一个定量的数值可供分析,但实际的分析也需要结合实际以及更多的情况综合考虑。
使用 numpy 计算协方差矩阵 相关系数
一般我们日常工作,都不会像上面一样把什么期望、方差、协方差一类的函数都重新写一遍,上面的代码只是让我们对这些计算更加熟悉。我们通常情况下会使用 numpy 一类封装好的函数,以下将演示一下如何使用 numpy 计算协方差。
import numpy as np
# 先构造一个矩阵
ab = np.array([a, b])
# 计算协方差矩阵
np.cov(ab)
>> array([[ 791.83947368, 150.95263158],
[ 150.95263158, 850.51578947]])
这里我们可以看到,这里使用 np.cov 函数,输出的结果是一个矩阵,这就是协方差矩阵。协方差矩阵数据的看法也不难,我们可以以上面的结果为例,矩阵1行1列,表示的是 a 数据的方差,这和我们上面的计算结果一致,然后1行2列和2行1列分别是 a b 以及 b a 的协方差,所以他们的值是一样的,然后最后2行2列就是 b 数据的方差。
接下来,我们继续使用 numpy 计算相关系数
np.corrcoef(ab)
>> array([[ 1. , 0.18394201],
[ 0.18394201, 1. ]])
计算相关系数,我们使用 numpy 的 corrcoef 函数,这里的输出也是一个矩阵,这个矩阵数据的含义同上面的协方差类似,我们可以看到,这里我们的相关系数是 0.18 ,和我们上面自己编写的函数计算的结果一致。
使用 pandas 计算协方差、相关系数
除了使用 numpy,我们比较常用的 python 数据处理库还有 pandas,很多金融数据分析的框架都会使用 pandas 库,以下将演示如何使用 pandas 库计算协方差和相关系数。
import pandas as pd
# 使用 DataFrame 作为数据结构,为方便计算,我们会将 ab 矩阵转置
dfab = pd.DataFrame(ab.T, columns=['A', 'B'])
# A B 协方差
dfab.A.cov(dfab.B)
>> 150.95263157894738
# A B 相关系数
dfab.A.corr(dfab.B)
>> 0.18394200852440828
dfab
>> A B
0 35 25
1 2 24
2 75 72
3 72 91
4 55 27
5 77 44
6 69 85
7 83 21
8 3 0
9 46 64
10 31 44
11 91 31
12 72 6
13 12 91
14 15 1
15 20 61
16 39 5
17 18 39
18 57 24
19 49 43
可以看到,和 numpy 相比,pandas 对于有多组数据的协方差、相关系数的计算比 numpy 更为简便、清晰,我们可以指定计算具体的两组数据的协方差、相关系数,这样就不需要再分析结果的协方差矩阵了。
小结
本文通过创建两组随机的数组,然后通过参考定义公式编写函数,再到使用 numpy 以及 pandas 进行协方差、相关系数的计算。到这里我们应该已经了解了数据相关性分析的原理,以及简单的具体实践使用方法,日后在工作中遇到需要做数据相关性分析的时候,就可以派上用场了。
参考资料
《数据科学入门.格鲁斯 (Joel Grus).人民邮电出版社》
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/133418.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
