大家好,又见面了,我是你们的朋友全栈君。
大数据:数据采集平台之Fluentd
大数据:数据采集平台之Fluentd
-
Apache Flume
详情请看文章:《大数据:数据采集平台之Apache Flume》 -
Fluentd
详情请看文章:《大数据:数据采集平台之Fluentd》 -
Logstash
详情请看文章:《大数据:数据采集平台之Logstash》 -
Apache Chukwa
详情请看文章:《大数据:数据采集平台之Apache Chukwa 》 -
Scribe
详情请看文章:《大数据:数据采集平台之Scribe 》 -
Splunk Forwarder
详情请看文章:《大数据:数据采集平台之Splunk Forwarder》
官网: http://docs.fluentd.org/articles/quickstart
Fluentd是一个开源的数据收集框架。Fluentd使用C/Ruby开发,使用JSON文件来统一日志数据。它的可插拔架构,支持各种不同种类和格式的数据源和数据输出。最后它也同时提供了高可靠和很好的扩展性。Treasure Data, Inc 对该产品提供支持和维护。
Fluentd的部署与架构设计和Flume非常相似:
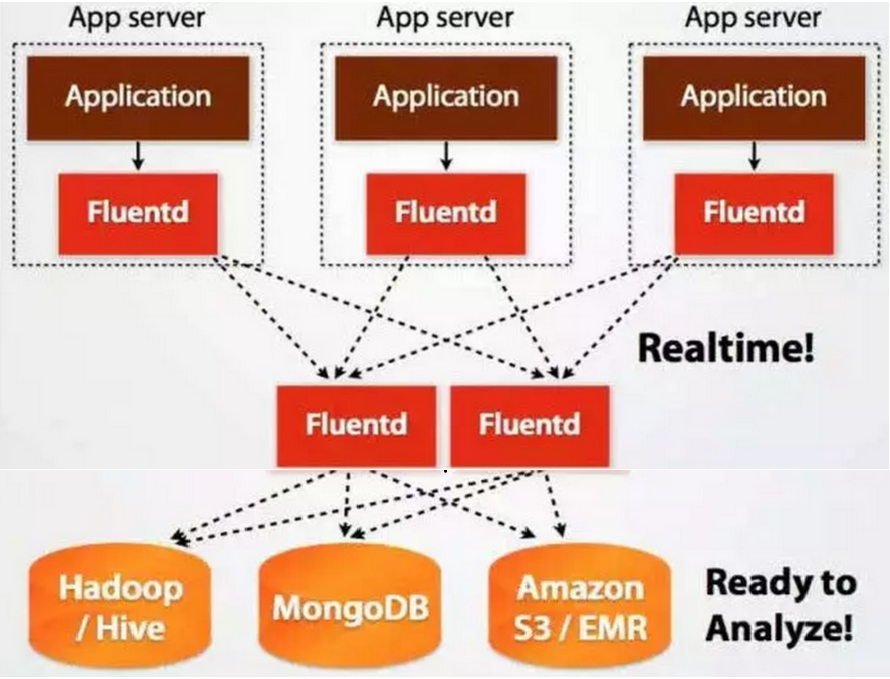

Fluentd的Input/Buffer/Output非常类似于Flume的Source/Channel/Sink。
-
Input:Input负责接收数据或者主动抓取数据。支持syslog,http,file tail等。
-
Buffer:Buffer负责数据获取的性能和可靠性,也有文件或内存等不同类型的Buffer可以配置。
-
Output:Output负责输出数据到目的地例如文件,AWS S3或者其它的Fluentd。
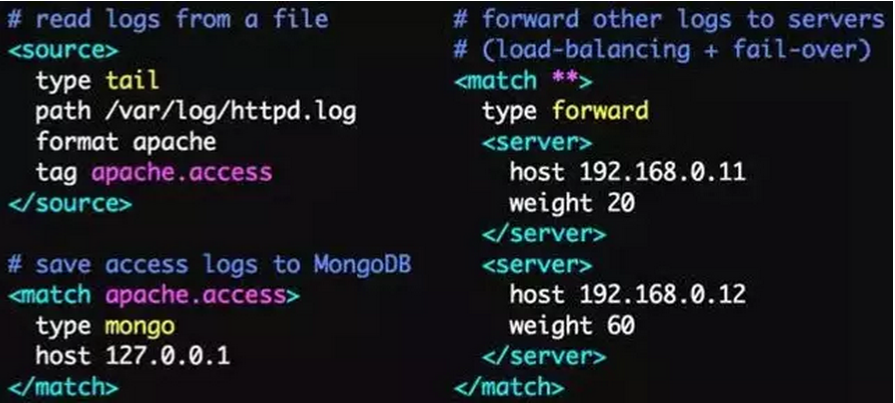
Fluentd的配置非常方便,如下图:
Fluentd的技术栈如下图:
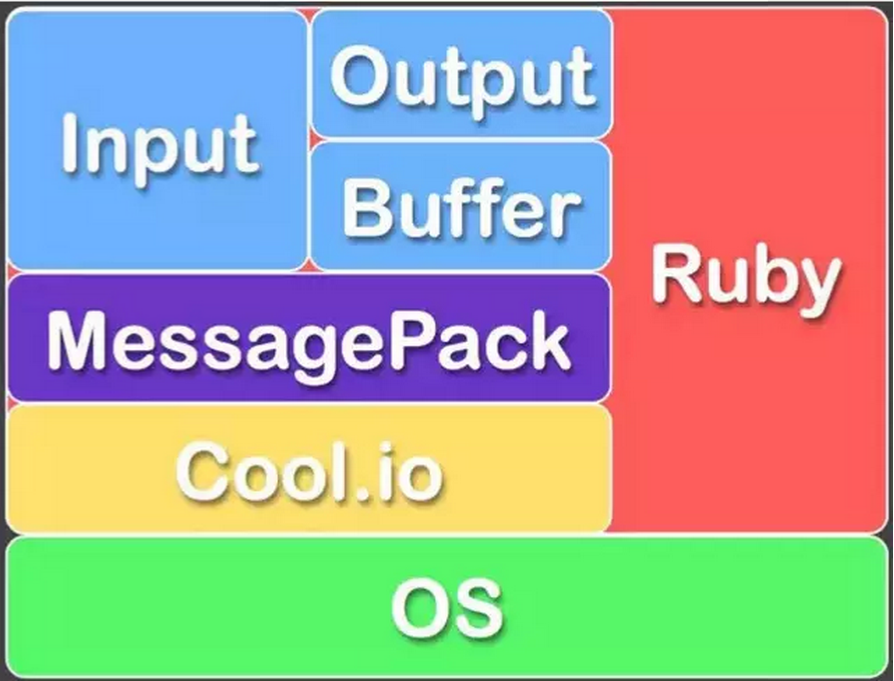
FLuentd和其插件都是由Ruby开发,MessgaePack提供了JSON的序列化和异步的并行通信RPC机制。
Cool.io是基于libev的事件驱动框架。
FLuentd的扩展性非常好,客户可以自己定制(Ruby)Input/Buffer/Output。
Fluentd从各方面看都很像Flume,区别是使用Ruby开发,Footprint会小一些,但是也带来了跨平台的问题,并不能支持Windows平台。另外采用JSON统一数据/日志格式是它的另一个特点。相对去Flumed,配置也相对简单一些。
参考:https://mp.weixin.qq.com/s/emQ_94T0_Hw3ywQc0-4Dtg
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/133401.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
