大家好,又见面了,我是你们的朋友全栈君。
原帖地址: http://blog.csdn.net/nsrainbow/article/details/36629741
接上一个教程:http://blog.csdn.net/nsrainbow/article/details/36629339
本教程是在 Centos6 下使用yum来安装 CDH5 版本号的 hadoop 的教程。 假设没有加入yum源的请參考上一个教程:http://blog.csdn.net/nsrainbow/article/details/36629339
Hadoop架构图
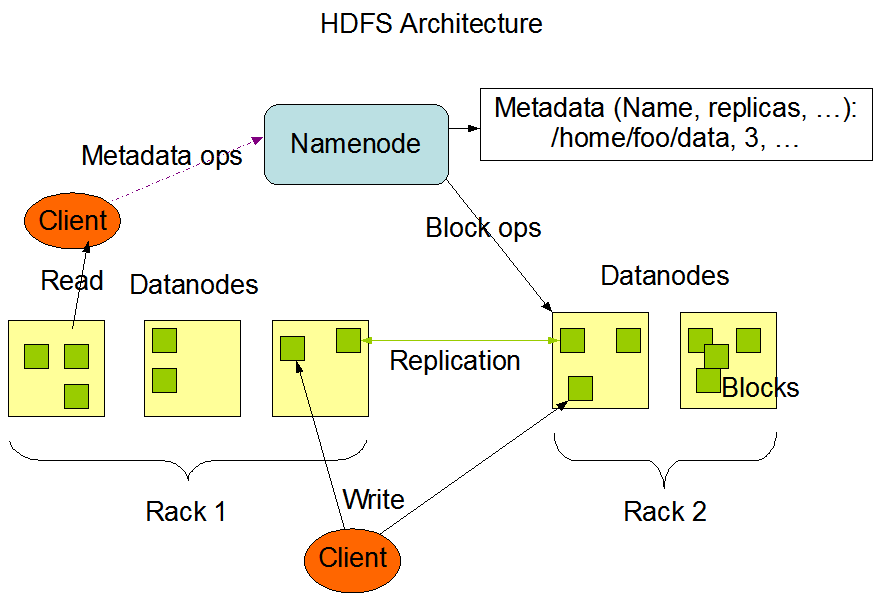

- NameNode、DataNode和Client
NameNode能够看作是分布式文件系统中的管理者,主要负责管理文件系统的命名空间、集群配置信息和存储块的复制等。NameNode会将文件系统的Meta-data存储在内存中,这些信息主要包含了文件信息、每个文件相应的文件块的信息和每个文件块在DataNode的信息等。
DataNode是文件存储的基本单元,它将Block存储在本地文件系统中,保存了Block的Meta-data,同一时候周期性地将全部存在的Block信息发送给NameNode。Client就是须要获取分布式文件系统文件的应用程序。
- 文件写入
Client向NameNode发起文件写入的请求。NameNode依据文件大小和文件块配置情况。返回给Client它所管理部分DataNode的信息。
Client将文件划分为多个Block,依据DataNode的地址信息。按顺序写入到每个DataNode块中。 - 文件读取
Client向NameNode发起文件读取的请求
NameNode返回文件存储的DataNode的信息。
Client读取文件信息。
開始安装非HA模式
1. 加入库key
$ sudo rpm --import http://archive.cloudera.com/cdh5/redhat/6/x86_64/cdh/RPM-GPG-KEY-cloudera2. 安装CDH5
2.1 安装Resource Manager host
$ sudo yum clean all
$ sudo yum install hadoop-yarn-resourcemanager -y2.2 安装 NameNode host
$ sudo yum clean all
$ sudo yum install hadoop-hdfs-namenode -y2.3 安装 Secondary NameNode host
$ sudo yum clean all
$ sudo yum install hadoop-hdfs-secondarynamenode -y2.4 安装 nodemanager , datanode, mapreduce (官方说明是在除了 Resource Manager以外的机子上装这些,可是我们如今就一台机子。所以就在这台机子上装)
$ sudo yum clean all
$ sudo yum install hadoop-yarn-nodemanager hadoop-hdfs-datanode hadoop-mapreduce -y2.5 安装 hadoop-mapreduce-historyserver hadoop-yarn-proxyserver (官方说是在cluster中挑一台做host,可是我们就一台,就直接在这台上装)
$ sudo yum clean all
$ sudo yum install hadoop-mapreduce-historyserver hadoop-yarn-proxyserver -y2.6 安装 hadoop-client (用户连接hadoop的client,官方说在client装,我们就直接在这台上装)
$ sudo yum clean all
$ sudo yum install hadoop-client -y3. 部署CDH
3.1 配置计算机名(默认是localhost)
先看看自己的hostname有没有设置
$ sudo vim /etc/sysconfig/network
HOSTNAME=localhost.localdomain 假设HOSTNAME是 localhost.localdomain的话就改一下
HOSTNAME=myhost.mydomain.com
然后再执行下,保证马上生效
$ sudo hostname myhost.mydomain.com 检查一下是否设置生效
$ sudo uname -a3.2 改动配置文件
先切换到root用户。免得每行命令之前都加一个sudo,所以下面教程都是用root角度写的
$ sudo su -
$ cd /etc/hadoop/conf
$ vim core-site.xml 在 <configuration>…</configuration> 中添加
<property>
<name>fs.defaultFS</name>
<value>hdfs://myhost.mydomain.com:8020</value>
</property>编辑hdfs-site.xml
$ vim hdfs-site.xml 在 <configuration>…</configuration> 中加入
<property>
<name>dfs.permissions.superusergroup</name>
<value>hadoop</value>
</property>3.3 配置存储目录
在 namenode 机子上配置 hdfs.xml 用来存储name元数据(我们仅仅有一台机,所以既是namenode又是datanode)
$ vim hdfs-site.xml 改动dfs.name.dir 为 dfs.namenode.name.dir(dfs.name.dir已经过时),并改动属性值,一般来说我们的 /data 或者 /home/data 都是挂载大硬盘数据用的,所以把存储目录指向这个路径里面的目录比較较好
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///data/hadoop-hdfs/1/dfs/nn</value>
</property>
在 datanode上配置 hdfs.xml 用来存储实际数据(我们仅仅有一台机,所以既是namenode又是datanode)
$ vim hdfs-site.xml 添加dfs.datanode.data.dir(dfs.data.dir已经过时)配置
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///data/hadoop-hdfs/1/dfs/dn,file:///data/hadoop-hdfs/2/dfs/dn</value>
</property> 建立这些目录
$ mkdir -p /data/hadoop-hdfs/1/dfs/nn
$ mkdir -p /data/hadoop-hdfs/1/dfs/dn
$ mkdir -p /data/hadoop-hdfs/2/dfs/dn 改动目录用户
$ chown -R hdfs:hdfs /data/hadoop-hdfs/1/dfs/nn /data/hadoop-hdfs/1/dfs/dn /data/hadoop-hdfs/2/dfs/dn 改动目录权限
$ chmod 700 /data/hadoop-hdfs/1/dfs/nn3.4 格式化namenode
$ sudo -u hdfs hdfs namenode -format3.5 配置 Secondary NameNode
在hdfs-site.xml中加入
<property>
<name>dfs.namenode.http-address</name>
<value>0.0.0.0:50070</value>
<description>
The address and the base port on which the dfs NameNode Web UI will listen.
</description>
</property>3.6 启动hadoop
$ for x in `cd /etc/init.d ; ls hadoop-*` ; do sudo service $x start ; done
Starting Hadoop nodemanager: [ OK ]
starting nodemanager, logging to /var/log/hadoop-yarn/yarn-yarn-nodemanager-xmseapp03.ehealthinsurance.com.out
Starting Hadoop proxyserver: [ OK ]
starting proxyserver, logging to /var/log/hadoop-yarn/yarn-yarn-proxyserver-xmseapp03.ehealthinsurance.com.out
Starting Hadoop resourcemanager: [ OK ]
starting resourcemanager, logging to /var/log/hadoop-yarn/yarn-yarn-resourcemanager-xmseapp03.ehealthinsurance.com.out
Starting Hadoop datanode: [ OK ]
starting datanode, logging to /var/log/hadoop-hdfs/hadoop-hdfs-datanode-xmseapp03.ehealthinsurance.com.out
Starting Hadoop namenode: [ OK ]
starting namenode, logging to /var/log/hadoop-hdfs/hadoop-hdfs-namenode-xmseapp03.ehealthinsurance.com.out
Starting Hadoop secondarynamenode: [ OK ]
starting secondarynamenode, logging to /var/log/hadoop-hdfs/hadoop-hdfs-secondarynamenode-xmseapp03.ehealthinsurance.com.out
... 都成功后用jps看下
$jps
17033 NodeManager
16469 DataNode
17235 ResourceManager
17522 JobHistoryServer
16565 NameNode
16680 SecondaryNameNode
17593 Jps
4 client測试
打开你的浏览器输入 http://<hadoop server ip>:50070
假设看到
Hadoop Administration
DFS Health/Status
这种字样就成功进入了hadoop的命令控制台
转载于:https://www.cnblogs.com/mqxnongmin/p/10603965.html
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/133357.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
