大家好,又见面了,我是你们的朋友全栈君。
终于到了机器学习实战的第十一章了,这也是继K-均值后的第二个无监督学习算法了。同样的该算法也是在一堆数据集中寻找数据之间的某种关联,这里主要介绍的是叫做Apriori的‘一个先验’算法,通过该算法我们可以对数据集做关联分析——在大规模的数据中寻找有趣关系的任务,本文主要介绍使用Apriori算法发现数据的(频繁项集、关联规则)。
这些关系可以有两种形式:频繁项集、关联规则。
频繁项集:经常出现在一块的物品的集合
关联规则:暗示两种物品之间可能存在很强的关系
一个具体的例子:


频繁项集是指那些经常出现在一起的物品,例如上图的{葡萄酒、尿布、豆奶},从上面的数据集中也可以找到尿布->葡萄酒的关联规则,这意味着有人买了尿布,那很有可能他也会购买葡萄酒。那如何定义和表示频繁项集和关联规则呢?这里引入支持度和可信度(置信度)。
支持度:一个项集的支持度被定义为数据集中包含该项集的记录所占的比例,上图中,豆奶的支持度为4/5,(豆奶、尿布)为3/5。支持度是针对项集来说的,因此可以定义一个最小支持度,只保留最小支持度的项集。
可信度(置信度):针对如{尿布}->{葡萄酒}这样的关联规则来定义的。计算为 支持度{尿布,葡萄酒}/支持度{尿布},其中{尿布,葡萄酒}的支持度为3/5,{尿布}的支持度为4/5,所以“尿布->葡萄酒”的可行度为3/4=0.75,这意味着尿布的记录中,我们的规则有75%都适用。
有了可以量化的计算方式,我们却还不能立刻运算,这是因为如果我们直接运算所有的数据,运算量极其的大,很难实现,这里说明一下,假设我们只有 4 种商品:商品0,商品1,商品 2,商品3. 那么如何得可能被一起购买的商品的组合?
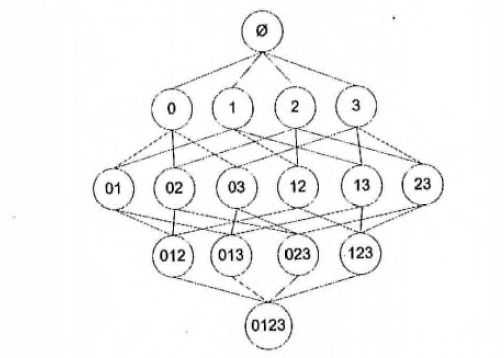
上图显示了物品之间所有可能的组合,从上往下一个集合是 Ø,表示不包含任何物品的空集,物品集合之间的连线表明两个或者更多集合可以组合形成一个更大的集合。我们的目标是找到经常在一起购买的物品集合。这里使用集合的支持度来度量其出现的频率。一个集合出现的支持度是指有多少比例的交易记录包含该集合。例如,对于上图,要计算 0,3 的支持度,直接的想法是遍历每条记录,统计包含有 0 和 3 的记录的数量,使用该数量除以总记录数,就可以得到支持度。而这只是针对单个集合 0,3. 要获得每种可能集合的支持度就需要多次重复上述过程。对于上图,虽然仅有4中物品,也需要遍历数据15次。随着物品数目的增加,遍历次数会急剧增加,对于包含 N 种物品的数据集共有 2^N−1 种项集组合。为了降低计算时间,研究人员发现了 Apriori 原理,可以帮我们减少感兴趣的频繁项集的数目。
Apriori 的原理:如果某个项集是频繁项集,那么它所有的子集也是频繁的。即如果 {0,1} 是频繁的,那么 {0}, {1} 也一定是频繁的。
这个原理直观上没有什么用,但是反过来看就有用了,也就是说如果一个项集是非频繁的,那么它的所有超集也是非频繁的。如下图所示:
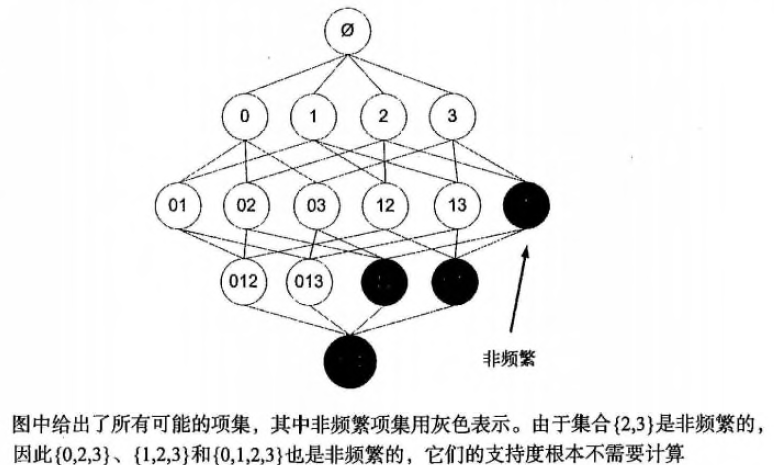
频繁项集:
主要步骤:
首先会生成所有单个物品的项集列表
扫描交易记录来查看哪些项集满足最小支持度要求,那些不满足最小支持度的集合会被去掉
对剩下的集合进行组合以生成包含两个元素的项集
接下来重新扫描交易记录,去掉不满足最小支持度的项集,重复进行直到所有项集都被去掉
代码(代码中有详细注释):
from numpy import *
# 构造数据
def loadDataSet():
return [[1, 3, 4], [2, 3, 5], [1, 2, 3, 5], [2, 5]]
# 将所有元素转换为frozenset型字典,存放到列表中
def createC1(dataSet):
C1 = []
for transaction in dataSet:
for item in transaction:
if not [item] in C1:
C1.append([item])
C1.sort()
# 使用frozenset是为了后面可以将这些值作为字典的键
return list(map(frozenset, C1)) # frozenset一种不可变的集合,set可变集合
# 过滤掉不符合支持度的集合
# 返回 频繁项集列表retList 所有元素的支持度字典
def scanD(D, Ck, minSupport):
ssCnt = {}
for tid in D:
for can in Ck:
if can.issubset(tid): # 判断can是否是tid的《子集》 (这里使用子集的方式来判断两者的关系)
if can not in ssCnt: # 统计该值在整个记录中满足子集的次数(以字典的形式记录,frozenset为键)
ssCnt[can] = 1
else:
ssCnt[can] += 1
numItems = float(len(D))
retList = [] # 重新记录满足条件的数据值(即支持度大于阈值的数据)
supportData = {} # 每个数据值的支持度
for key in ssCnt:
support = ssCnt[key] / numItems
if support >= minSupport:
retList.insert(0, key)
supportData[key] = support
return retList, supportData # 排除不符合支持度元素后的元素 每个元素支持度
# 生成所有可以组合的集合
# 频繁项集列表Lk 项集元素个数k [frozenset({2, 3}), frozenset({3, 5})] -> [frozenset({2, 3, 5})]
def aprioriGen(Lk, k):
retList = []
lenLk = len(Lk)
for i in range(lenLk): # 两层循环比较Lk中的每个元素与其它元素
for j in range(i+1, lenLk):
L1 = list(Lk[i])[:k-2] # 将集合转为list后取值
L2 = list(Lk[j])[:k-2]
L1.sort(); L2.sort() # 这里说明一下:该函数每次比较两个list的前k-2个元素,如果相同则求并集得到k个元素的集合
if L1==L2:
retList.append(Lk[i] | Lk[j]) # 求并集
return retList # 返回频繁项集列表Ck
# 封装所有步骤的函数
# 返回 所有满足大于阈值的组合 集合支持度列表
def apriori(dataSet, minSupport = 0.5):
D = list(map(set, dataSet)) # 转换列表记录为字典 [{1, 3, 4}, {2, 3, 5}, {1, 2, 3, 5}, {2, 5}]
C1 = createC1(dataSet) # 将每个元素转会为frozenset字典 [frozenset({1}), frozenset({2}), frozenset({3}), frozenset({4}), frozenset({5})]
L1, supportData = scanD(D, C1, minSupport) # 过滤数据
L = [L1]
k = 2
while (len(L[k-2]) > 0): # 若仍有满足支持度的集合则继续做关联分析
Ck = aprioriGen(L[k-2], k) # Ck候选频繁项集
Lk, supK = scanD(D, Ck, minSupport) # Lk频繁项集
supportData.update(supK) # 更新字典(把新出现的集合:支持度加入到supportData中)
L.append(Lk)
k += 1 # 每次新组合的元素都只增加了一个,所以k也+1(k表示元素个数)
return L, supportData
dataSet = loadDataSet()
L,suppData = apriori(dataSet)
print(L)
print(suppData)返回频繁项集与支持度

上面代码获取数据的频繁项集,下面通过其他函数来获得关联规则。
关联规则:
# 获取关联规则的封装函数
def generateRules(L, supportData, minConf=0.7): # supportData 是一个字典
bigRuleList = []
for i in range(1, len(L)): # 从为2个元素的集合开始
for freqSet in L[i]:
# 只包含单个元素的集合列表
H1 = [frozenset([item]) for item in freqSet] # frozenset({2, 3}) 转换为 [frozenset({2}), frozenset({3})]
# 如果集合元素大于2个,则需要处理才能获得规则
if (i > 1):
rulesFromConseq(freqSet, H1, supportData, bigRuleList, minConf) # 集合元素 集合拆分后的列表 。。。
else:
calcConf(freqSet, H1, supportData, bigRuleList, minConf)
return bigRuleList
# 对规则进行评估 获得满足最小可信度的关联规则
def calcConf(freqSet, H, supportData, brl, minConf=0.7):
prunedH = [] # 创建一个新的列表去返回
for conseq in H:
conf = supportData[freqSet]/supportData[freqSet-conseq] # 计算置信度
if conf >= minConf:
print(freqSet-conseq,'-->',conseq,'conf:',conf)
brl.append((freqSet-conseq, conseq, conf))
prunedH.append(conseq)
return prunedH
# 生成候选规则集合
def rulesFromConseq(freqSet, H, supportData, brl, minConf=0.7):
m = len(H[0])
if (len(freqSet) > (m + 1)): # 尝试进一步合并
Hmp1 = aprioriGen(H, m+1) # 将单个集合元素两两合并
Hmp1 = calcConf(freqSet, Hmp1, supportData, brl, minConf)
if (len(Hmp1) > 1): #need at least two sets to merge
rulesFromConseq(freqSet, Hmp1, supportData, brl, minConf)
dataSet = loadDataSet()
L,suppData = apriori(dataSet,minSupport=0.5)
rules = generateRules(L,suppData,minConf=0.7)
# rules = generateRules(L,suppData,minConf=0.5)
print(rules)返回关联规则:

上面的函数稍微有点复杂,因为使用的数据结构有点多,可能会搞混,所以下面说明一下函数意义。(由于我个人叙述可能不太清楚,所以这里引用作者的原话我觉得更好理解一点,稍微有点详细):


以上便是引用作者对这三个函数的详细描述,在函数中的具体代码,我也有相关的注释,慢慢来应该能够理解的。
下面对一个毒蘑菇的例子进行运算,检查一下在实际数据中的反应:
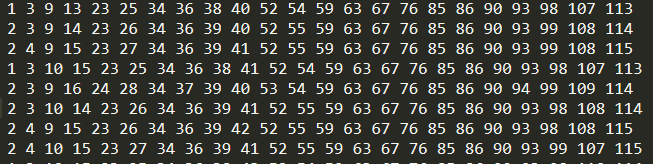
第一个特征表示有毒或者可以使用。如果有毒则为2,可以食用为1。下一个特征蘑菇形状,有3-8六种可能,下面我们找出毒蘑菇中存在的公共特征:
mushDatSet = [line.split() for line in open('mushroom.dat').readlines()]
L,suppData = apriori(mushDatSet,minSupport=0.3)
print(L)
for item in L[1]: # 只查看两个元素的集合
if(item.intersection('2')): # intersection交集(选出毒蘑菇)
print(item)输出了频繁项集和与毒蘑菇相关的特征:

以上为Apriori算法构建模型的全部内容,该算法不仅适用于零售行业,同样适用于相同技术的其他行业,如网站流量分析以及医药行业等。
参考书籍:《机器学习实战》
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/133321.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
