大家好,又见面了,我是你们的朋友全栈君。
如果需要完整代码可以关注下方公众号,后台回复“代码”即可获取,阿光期待着您的光临~

文章目录
✌ 多重共线性检验-方差膨胀系数(VIF)
1、✌ 原理:
方差膨胀系数是衡量多元线性回归模型中多重共线性严重程度的一种度量。
它表示回归系数估计量的方差与假设自变量间不线性相关时方差相比的比值。
2、✌ 多重共线性:
是指各特征之间存在线性相关关系,即一个特征可以是其他一个或几个特征的线性组合。如果存在多重共线性,求损失函数时矩阵会不可逆,导致求出结果会与实际不同,有所偏差。
例如:
x1=[1,2,3,4,5]
x2=[2,4,6,8,10]
x3=[2,3,4,5,6]
# x2=x1*2
# x3=x1+1
上述x2,x3都和x1成线性关系,这会进行回归时,影响系数的准确性,说白了就是多个特征存在线性关系,数据冗余,但不完全是,所以要将成线性关系的特征进行降维
3、✌ 检验方法:
✌ 方差膨胀系数(VIF):
通常情况下,当VIF<10,说明不存在多重共线性;当10<=VIF<100,存在较强的多重共线性,当VIF>=100,存在严重多重共线性
# 导入计算膨胀因子的库
from statsmodels.stats.outliers_influence import variance_inflation_factor
# get_loc(i) 返回对应列名所在的索引
vif=[variance_inflation_factor(x.values,x.columns.get_loc(i)) for i in x.columns]
list(zip(list(range(1,21)),vif))
✌ 相关性检验:
这个就不举例子,很容易的
import pandas as pd
data=pd.DataFrame([[3,4],[4,5],[1,2]])
data.corr()
4、✌ 代码测试
说明:由于只是介绍多重相关性,所以建模的参数都为默认,只是基本结构
4.1 ✌ 导入相关库
# 画图
import seaborn as sns
# 制作数据集
from sklearn.datasets import make_blobs
# VIF膨胀因子
from statsmodels.stats.outliers_influence import variance_inflation_factor
# 分割数据集
from sklearn.model_selection import train_test_split
# 逻辑回归
from sklearn.linear_model import LogisticRegression
# AUC和准确度
from sklearn.metrics import accuracy_score
from sklearn.metrics import roc_auc_score
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
4.2 ✌ 准备数据
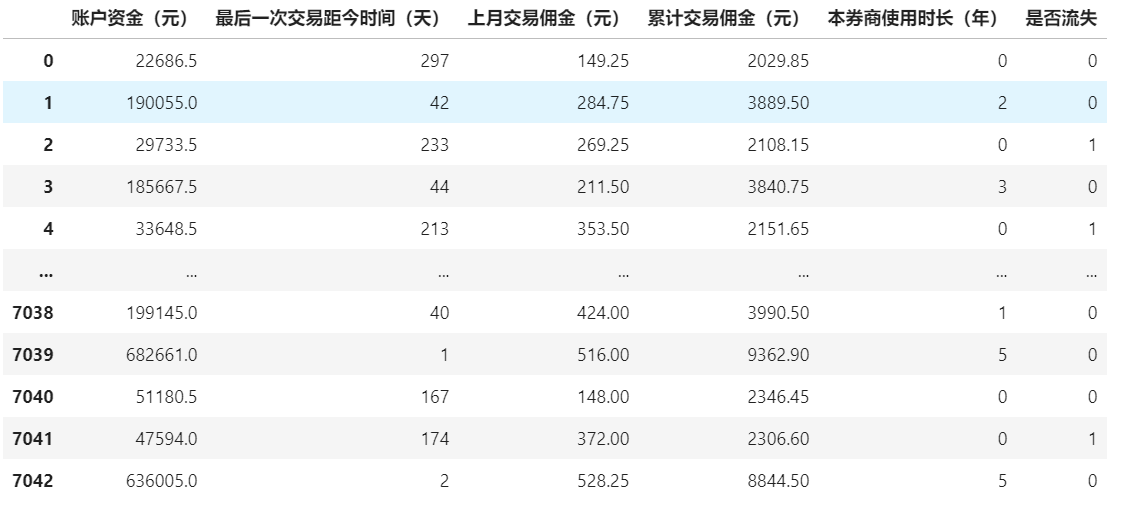

data=pd.read_excel('股票客户流失'.xlsx)
# 提取特征矩阵和标签
x=data.drop(columns=['是否流失'])
y=data['是否流失']
4.3 ✌ 计算膨胀因子

vif=[variance_inflation_factor(x.values,x.columns.get_loc(i)) for i in x.columns]
list(zip(list(range(1,21)),vif))
4.4 ✌ 计算相关系数
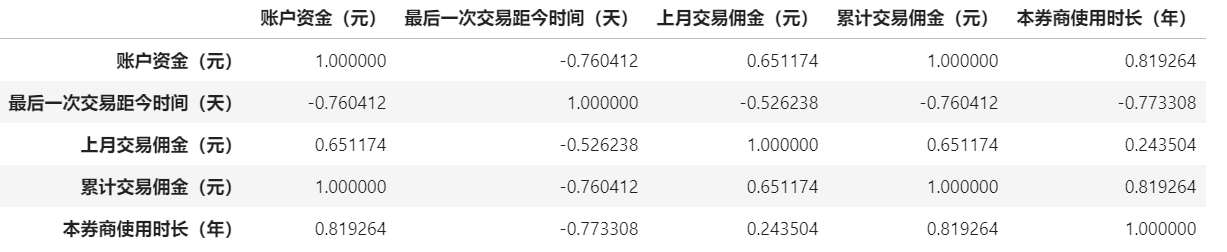
x.corr()
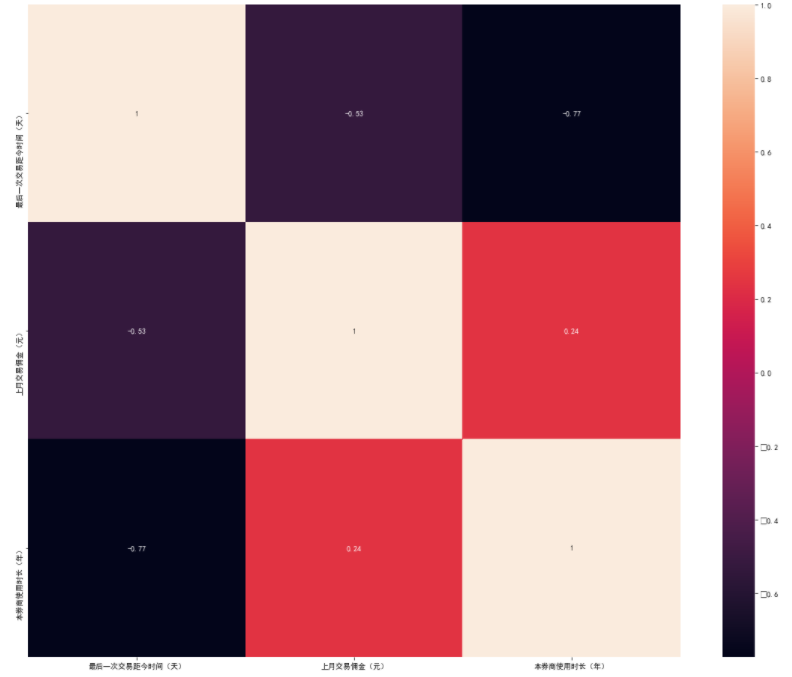
# 可以画出热力图进行展示
plt.subplots(figsize=(20,16))
ax=sns.heatmap(x.corr(),vmax=1,square=True,annot=True)
4.5 ✌ 分割测试集
x_train,x_test,y_train,y_test=train_test_split(x,
y,test_size=0.2,
random_state=2021
)
4.6 ✌ 模型选择
clf=LogisticRegression(max_iter=300)
clf.fit(x_train,y_train)
y_pred=clf.predict(x_test)
accuracy_score(y_test,y_pred)

4.7 ✌ AUC值
roc_auc_score(y_test,clf.predict_proba(x_test)[:,1])

4.8 ✌ 模型调整
由上述VIF值可以看出 累计交易佣金和账户资金有较强的多重相关性,所以考虑删除二者中的某个特征进行建模,我们分别删除两个特征进行对比
4.8.1 ✌ 删除 账户资金
x=x.drop(columns=['账户资金(元)'])
x=pd.DataFrame(x)
y=y
vif=[variance_inflation_factor(x.values,x.columns.get_loc(i)) for i in x.columns]
vif
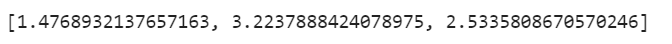
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.2,random_state=2021)
clf=LogisticRegression(max_iter=300)
clf.fit(x_train,y_train)
y_pred=clf.predict(x_test)
accuracy_score(y_test,y_pred)

roc_auc_score(y_test,clf.predict_proba(x_test)[:,1])

4.8.2 ✌ 删除 累计交易佣金
x=x.drop(columns=['累计交易佣金(元)'])
x=pd.DataFrame(x)
y=y
vif=[variance_inflation_factor(x.values,x.columns.get_loc(i)) for i in x.columns]
vif
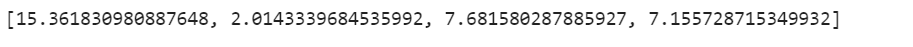
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.2,random_state=2021)
clf=LogisticRegression(max_iter=300)
clf.fit(x_train,y_train)
y_pred=clf.predict(x_test)
accuracy_score(y_test,y_pred)

roc_auc_score(y_test,clf.predict_proba(x_test)[:,1])

5、✌ 总结
| Score | AUC面积 | |
|---|---|---|
| 原始特征 | 0.7806 | 0.8194 |
| 删除账户资金 | 0.7821 | 0.8149 |
| 删除累计交易佣金 | 0.7586 | 0.7272 |
- 我们可以看出当我们删除账户资金这列特征时,分数有所上升,而AUC值下降了一点,不过影响不大,那么删除了共线性的特征是对我们模型的准确性是有作用的
- 但是我们发现删除累计交易佣金这列特征时,准确性反倒有所下降,这是为什么?不是删除共线性的特征对模型有帮助吗,这时我们就会想可能是累计交易佣金这列特征所包含的信息较多,贸然删除的化,可能会导致模型拟合不足(欠拟合)
- 而账户资金和累计交易时相关的,可以理解为账户资金的信息依靠累计交易,类似于数学里面的子集这种(不过这种理解是错误的),就是两列数据存在强烈的相关性,但累计交易佣金这列数据包含的数据相对于账户资金这列数据对模型的贡献比较高
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/133275.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
