大家好,又见面了,我是你们的朋友全栈君。
注:以下内容为jdk8之前,学习《深入理解Java虚拟机(第二版)》的关于GC的简单总结,jdk8及之后的详细学习总结已更新至博客《学习:GC垃圾回收、JVM架构、运行时数据区》
GC(垃圾收集),那收集回收的是什么呢?是内存,所以在了解垃圾回收机制之前,要对Java内存有一个了解。
一、Java内存
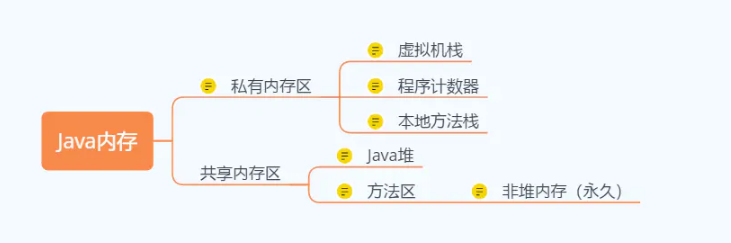

图解:
私有内存区——伴随线程的产生而产生,一旦线程终止,私有内存区也会自动消除
-
程序计数器:指示当前程序执行到了哪一行,执行Java方法时记录正在执行的虚拟机字节码指令地址;执行本地方法时,计数器值为null
-
虚拟机栈:用于执行Java方法,栈针存储布局边聊表,操作数栈,动态链接,方法返回地址和一些额外的符加信息。程序执行时入栈;执行完成后栈针出栈。
GC主要就是在Java堆中进行的。
- Java堆:Java虚拟机管理的内存中最大的一块,所有线程共享,几乎所有的对象实例和数组都在这类分配内存。
堆内存又分为:新生代和老年代,并且一般新生代的空间比老年代大。
了解了Java内存,接下来就来了解一下GC原理:
二、垃圾回收机制
一)GC的主要任务:
1.分配内存;
2.确保被引用对象的内存不被错误的回收;
3.回收不再被引用的对象的内存空间
二)垃圾回收机制的主要解决问题
1.哪些内存需要回收?
2.什么时候回收?
3.如何回收?
针对问题一,垃圾收集器会对堆进行回收前,确定对象中哪些是“存活”,哪些是”死亡“(不可能再被任何途径使用的对象)
判断方法:
1.引用计数算法
每当一个地方引用它时,计数器+1;引用失效时,计数器-1;计数值=0——不可能再被引用。
//举例:
Test test1 = new Test();
Test test2 = new Test();
test1.obj = test2;
test2.obj = test1;
//test1 ,test12能否被回收?
System.gc();
查看运行结果,会发现并没有因为两个对象互相引用就没有回收,因此引用计数算法很难解决对象之间相互矛盾循环引用的问题。
2.可达性分析算法:
向图,树图,把一系列“GC Roots”作为起始点,从节点向下搜索,路径称为引用链,当一个对象到GC Roots没有任何引用链相连,即不可达时,则证明此对象时不可用的。
举例:一颗树有很多丫枝,其中一个分支断了,跟树上没有任何联系,那就说明这个分支没有用了,就可以当垃圾回收去烧了。
注:在Java中可作为GCRoots的对象:
1).虚拟机栈(栈帧中的本地变量表)中引用的对象;
2).方法区中类静态属性引用的对象;
3).方法区中常量引用的对象;
4).本地方法栈中JNI引用的对象
针对问题2——什么时候回收?
即使是被判断不可达的对象,也要再进行筛选,当对象没有覆盖finalize()方法,或者finalize方法已经被虚拟机调用过,则没有必要执行;
如果有必要执行——放置在F-Queue的队列中——Finalizer线程执行。
注意:对象可以在被GC时可以自我拯救(this),机会只有一次,因为任何一个对象的finalize()方法都只会被系统自动调用一次。并不建议使用,应该避免。使用try_finaly或者其他方式。
问题3——如何回收,这就牵扯到垃圾收集算法和垃圾收集器
垃圾收集算法:
1.标记—清除算法
两个阶段:标记,清除;
不足:效率问题;空间问题(会产生大量不连续的内存碎片)
2.复制算法
将可用内存按容量分为大小相等的两块,每次都只使用其中一块;
不足:将内存缩小为了原来的一半
新生代
3.标记—整理算法
标记,清除(让存活的对象都向一端移动)
老年代
垃圾收集器:
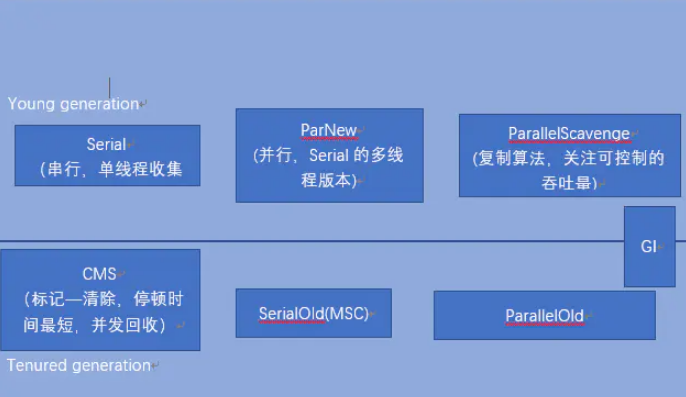
最后来讲一下流程。
新建的对象再新生代中,如果新生代内存不够,就进行Minor GC释放掉不活跃对象;如果还是不够,就把部分活跃对象复制到老年代中,如果还是不够,就进行MajorGC释放老年代,如果还是不够,JVM会抛出内存不足,发生oom,内存泄漏。
学习参考:
《深入理解Java 虚拟机(第二版)》
https://blog.csdn.net/antony9118/article/details/51375662
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/133083.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
