大家好,又见面了,我是你们的朋友全栈君。
文章目录
国际权威的学术组织the IEEE International Conference on Data Mining (ICDM) 2006年12月评选出了数据挖掘领域的十大经典算法:C4.5, k-Means, SVM, Apriori, EM, PageRank, AdaBoost, kNN, Naive Bayes, CART
这十个算法涵盖了分类、聚类、统计学习、关联分析和链接分析等重要的数据挖掘研究和发展主题
本节主要研究Apriori算法
1. “啤酒与尿布”的案例


“啤酒与尿布”的故事产生于20世纪90年代的美国沃尔玛超市中,沃尔玛的超市管理人员分析销售数据时发现了一个令人难于理解的现象:在某些特定的情况下,“啤酒”与“尿布”两件看上去毫无关系的商品会经常出现在同一个购物篮中,这种独特的销售现象引起了管理人员的注意,经过后续调查发现,这种现象出现在年轻的父亲身上。
在美国有婴儿的家庭中,一般是母亲在家中照看婴儿,年轻的父亲前去超市购买尿布。父亲在购买尿布的同时,往往会顺便为自己购买啤酒,这样就会出现啤酒与尿布这两件看上去不相干的商品经常会出现在同一个购物篮的现象。如果这个年轻的父亲在卖场只能买到两件商品之一,则他很有可能会放弃购物而到另一家商店,直到可以一次同时买到啤酒与尿布为止。沃尔玛发现了这一独特的现象,开始在卖场尝试将啤酒与尿布摆放在相同的区域,让年轻的父亲可以同时找到这两件商品,并很快地完成购物;而沃尔玛超市也可以让这些客户一次购买两件商品、而不是一件,从而获得了很好的商品销售收入,这就是“啤酒与尿布”故事的由来。
当然“啤酒与尿布”的故事必须具有技术方面的支持。1993年美国学者Agrawal 提出通过分析购物篮中的商品集合,从而找出商品之间关联关系的关联算法,并根据商品之间的关系,找出客户的购买行为。艾格拉沃从数学及计算机算法角度提出了商品关联关系的计算方法——Aprior算法。沃尔玛从上个世纪90年代尝试将Aprior算法引入到POS机数据分析中,并获得了成功,于是产生了“啤酒与尿布”的故事。
什么是关联规则挖掘?
简单的来讲关联规则挖掘就是用于发现数据库中属性之间的有趣联系。
如:顾客在购买牛奶时,是否也可能同时购买面包?
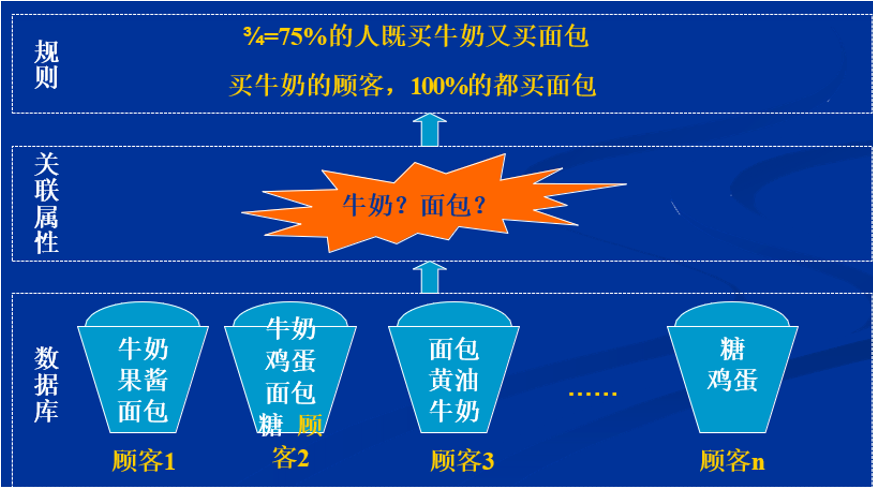
根据关联规则,我们能够做什么?
例如上面的栗子,我们可以得出结论购买牛奶的人一定会购买面包,所以我们可以:
- 帮助商家进行有针对性的促销
- 进行合理的货架摆放

2. Aprior算法核心术语
“啤酒与尿布”是通过人工观察并发现事物规律的典型栗子,这也引出数据挖掘十大算法之一的Aprior算法——关联规则挖掘算法,这个算法其实并不像其他算法这么难,甚至算法本身也并没有提出什么新的概念
我们先规定一个商品表单,用来理解下面出现的一些术语
| 单号 | 商品 |
|---|---|
| 1 | ABCD |
| 2 | ABCE |
| 3 | BDEF |
| 4 | BCDE |
| 5 | ACDF |
| 6 | ABC |
| 7 | ABE |
事物集
如上面的表格,{ABCD,ABCE,BDEF….},所有的流水记录构成的集合
记录(事务)
如上面的表格,我们把ABCD叫做一条记录(事物)
项目(项)
一条记录中A、B、C … 叫做一个项目(项)
项目集(项集)
由项组成的集合,如{A,B,E,F},{A,B,C}就是一个项集
K项集
项集中元素的个数为K,如{A,B,E,F}就是4项集
支持度(Support)
sup(x) = 某个项集X在事物集中出现的次数 / 事物集中记录的总个数
如X = {A,C} 则Sup(X)= 4 / 7 = 0.57
置信度(Confidence)
置信度其实就是某个项集的条件概率。Con(x=>y) = sup(xy) / sup(x) , 对应条件概率的算法:P(y | x) = P(xy) / p(x)
例如:X = {A}, Y = {C} 则Con(X=>Y)= Sup(??) = 4/7 / 5/7 = 4 / 5 = 0.8
最小支持度(min_support)
人为规定的一个支持度
最小置信度(min_confidence)
人为规定的一个置信度
提升度
Life(A -> B) = Con(A -> B) / Sup(B),理解为B在A发生的基础上再发生的概率与B单独发生概率的比值
频繁K项(目)集
如果k项集的支持度大于最小支持度,则称为频繁K项集
候选K项(目)集
用来生成频繁K项集的K项集。(不等价与所有K项集)
例如:最小支持度为0.5 , X = {A,C} 则Sup(X)= 4 / 7 = 0.57 ≥ 0.5 , 称 ?, ? 是一个频繁2项集
举个栗子贯穿一下上面的概念
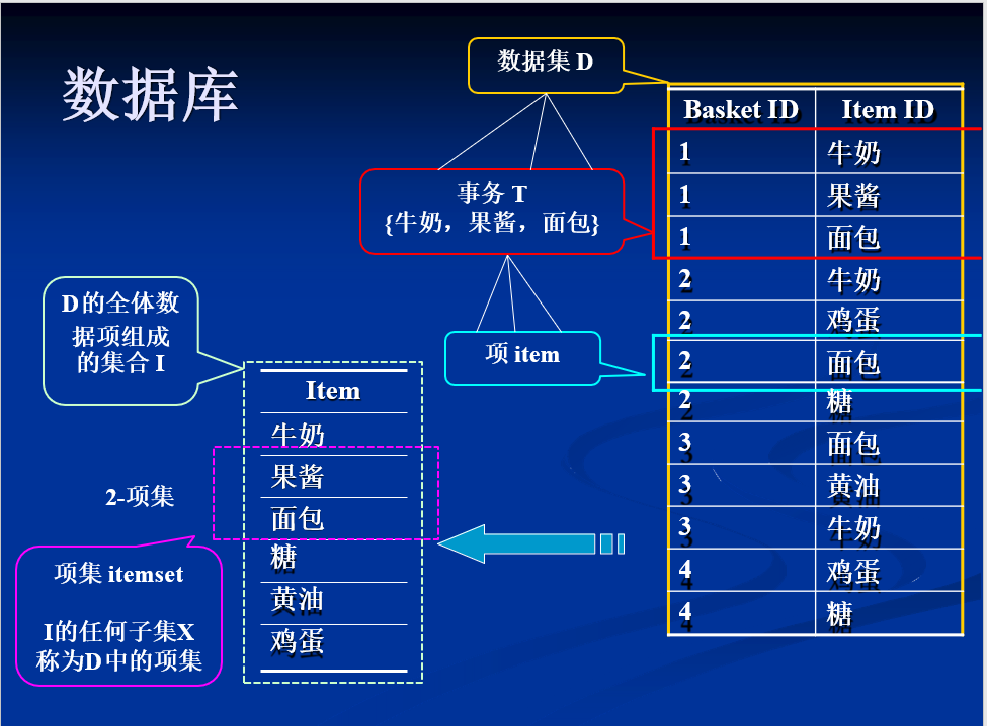
可以看到右边的所有记录组成数据集,其中的一个子集我们称为记录/事务,其中最小单位组成的称为项,由多个项组成k项集,
3. Aprior算法的三大性质(关联规则的三大性质)
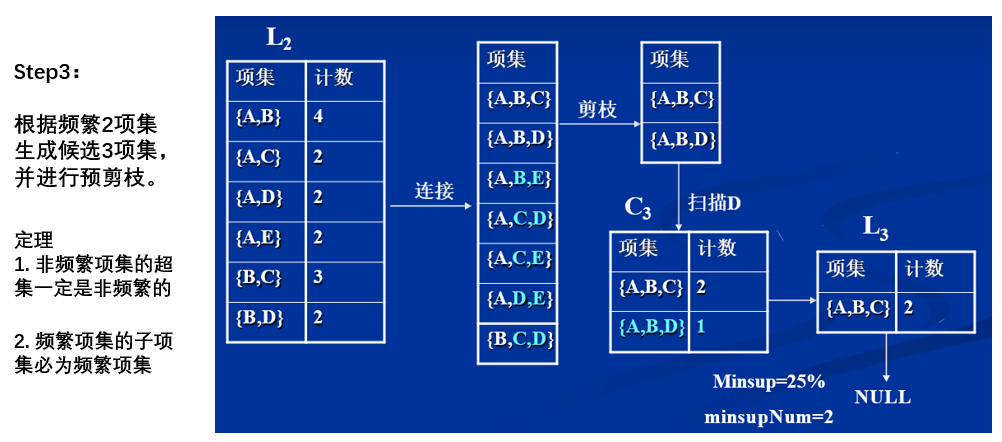
- 性质一:如果x是一个频繁K项集,则其非空子集也一定是频繁K项集
- 性质二:非频繁K项集的超集一定是非频繁的
- 性质三:任何一个项集的支持度不小于其超集的支持度
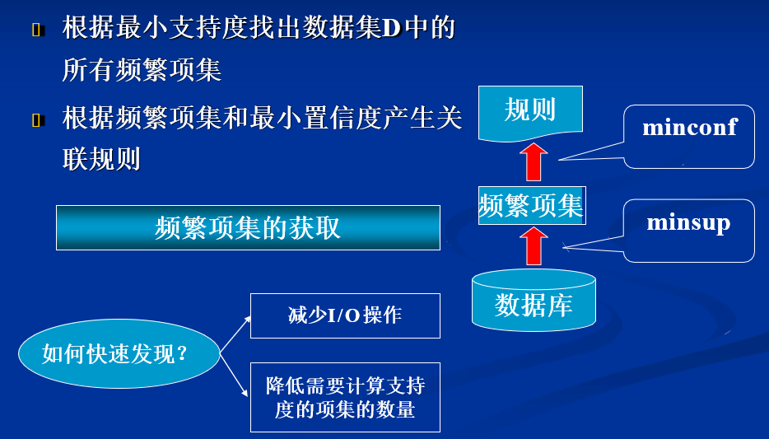
4. Aprior算法实现过程
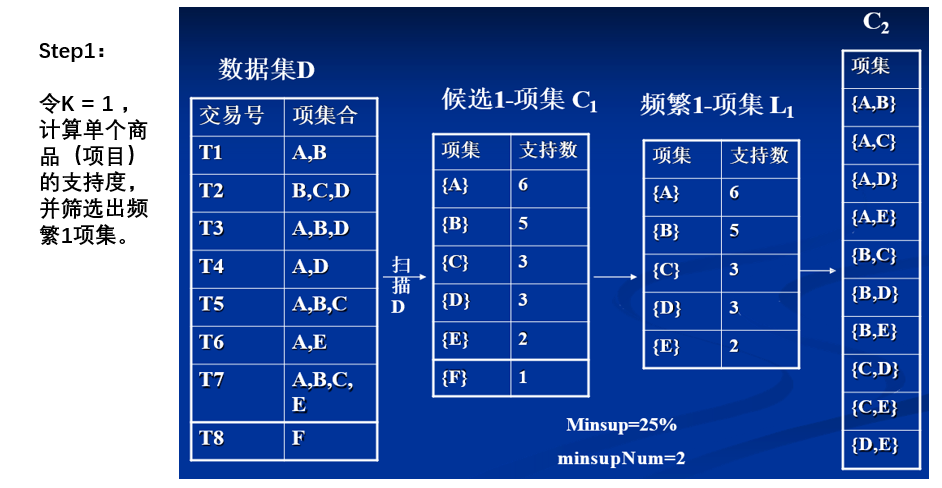
Step1:令K = 1 ,计算单个商品(项目)的支持度,并筛选出频繁1项集(大于最小支持度 )
Step2:(从K=2开始)根据K-1项的频繁项目集生成候选K项目集,并进行预剪枝(预剪枝的概念后面栗子再提?)
Step3:由候选K项目集生成频繁K项集(筛选出满足最小支持度的k项集)
重复步骤2和3,直到无法筛选出满足最小支持度的集合。(第一阶段结束)
Step4:将获得的最终的频繁K项集,依次取出。同时计算该次取出的这个K项集 的所有真子集,然后以排列组合的方式形成关联规则,并计算规则的置信度以及提升度,将符合要求的关联规则生成提出。(算法结束)
5. 数据挖掘
如何进行数据挖掘?我们要从数据中寻找
关联属性生成关联规则
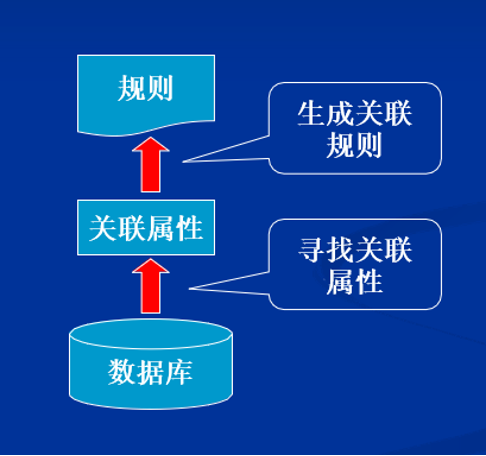
5.1 寻找关联属性
继续上面的栗子,例如我们要分析顾客购买的商品之间有什么关系

我们按照第四点中的挖掘步骤进行挖掘:
在图的右边用不同颜色将事物标记出来了,可以看出这里有四个事物
第一步:令k = 1,计算出一项集的支持度,并筛选出频繁一项集(
这里我们规定最小支持度为50%)我们可以用
支持数/总事物数来计算二项集的支持度,例如:
- 牛奶这个
项在所有事物中出现了3次,所以其支持度为:3/4 = 75% > 50%,所以是频繁一项集- 果酱为1/4 = 25% < 50%,所以不是
频繁一项集- 以此类推,我们可以算出后面的
频繁一项集还有面包
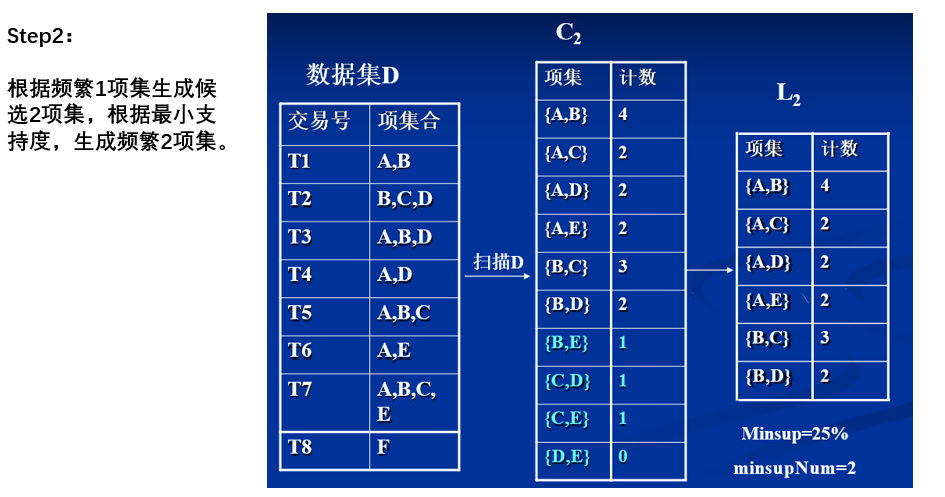
第二步:令k = 2,计算出二项集的支持度,并筛选出频繁二项集(
这里我们规定最小支持度为50%)我们可以用
支持数/总事物数来计算二项集的支持度,例如:
- 牛奶和果酱只在事物1里面出现了一次,那么这个二项集的支持度为:1/4 = 25% < 50%,所以不是频繁二项集
- 牛奶和面包在事物1、2、3中各出现了一次,所以其支持度为 3/4 = 75% > 50%,所以是
频繁二项集- 以此类推,后面的二项集都不是频繁二项集
当然这里可以先进行
预剪枝,也就是k=1时,由于果酱已经不是频繁项了,根据性质二,其超集一定不是频繁项集,所以我们可以先把包含果酱的二项集都去除,这个过程就叫做预剪枝
第三步:重复上述过程求k-1项目
第四步:根据上面计算的结果,我们可以得出结论,牛奶和面包之间的支持度为75%
5.2 生成关联规则
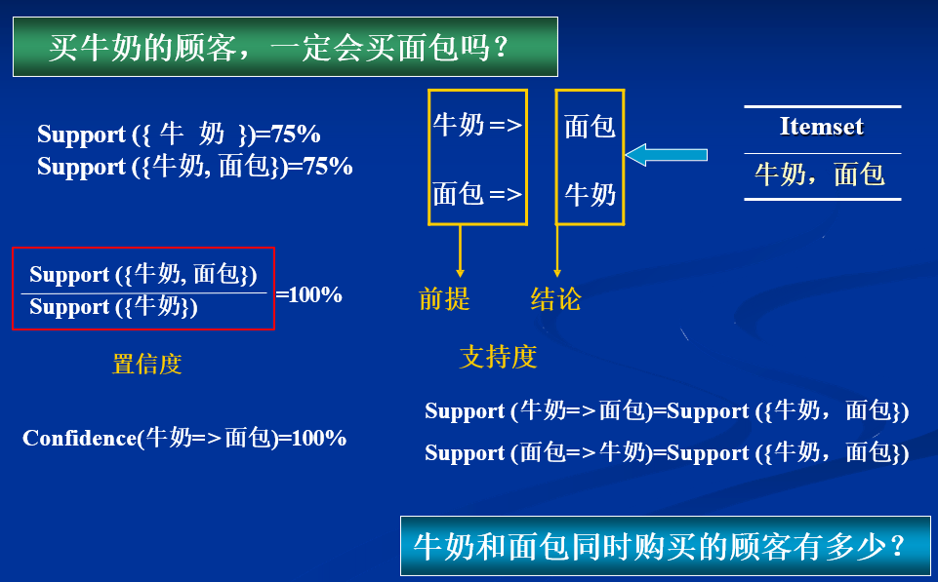
因为我们想要判断买牛奶和买面包之间的关系,所以现在我们需要求频繁二项集的置信度,也就是条件概率
图上面其实已经非常清楚了,我们在购买牛奶条件下求购买面包的概率:
Con(牛奶 => 面包) = Sup({牛奶,面包}) / Sup({牛奶}) = 75% / 75% = 100%
所以有: 前提 => 结论[支持度 ,置信度]
牛奶 => 面包[75% , 100% ]
关联规则 —–> 支持度 > minSup / 置信度 > minConf = 1 ——–> 判断出其关联规则(强关联)
所以我们可以得出关联规则:购买牛奶的人一定会购买面包,同理可得购买面包的也一定会购买牛奶
这个过程就是根据关联属性生成关联规则的的过程

5.3 更加严谨的栗子
当然上面以商品作为栗子还不够严谨,下面以纯数学的方式举个栗子再来演示一下
Aprior算法进行数据挖掘的过程
重复步骤2和3,直到无法筛选出满足最小支持度的集合。(第一阶段结束)

6. Aprior算法的优缺点
优点:
- Aprioi算法采用逐层搜索的迭代方法,算法简单明了,没有复杂的理论推导,也易于实现。
- 数据采用水平组织方式
- 适合事务数据库的关联规则挖掘。
- 适合稀疏数据集:根据以往的研究,该算法只能适合稀疏数据集的关联规则挖掘,也就是频繁项目集的长度稍小的数据集。
缺点:
-
对数据库的扫描次数过多(用来计算候选集的支持度)
-
Apion算法可能产生大量的候选项集
例如,如果有10^4 个频繁1项集,需要产生10^7个候选 2项集,为发现长度为100的频繁模式,须产生2^100~10^30 个候选集
-
在频繁项目集长度变大的情况下,运算时间显著增加
-
采用唯一支持度,没有考虑各个属性重要程度的不同
-
算法的适应面窄
6.1 改进Aprior算法
怎么改进Aprior算法并提高Aprior算法的有效性呢?
常用的有四种方法:
- 事务压缩
- 划分
- 选样
- 动态项集计数
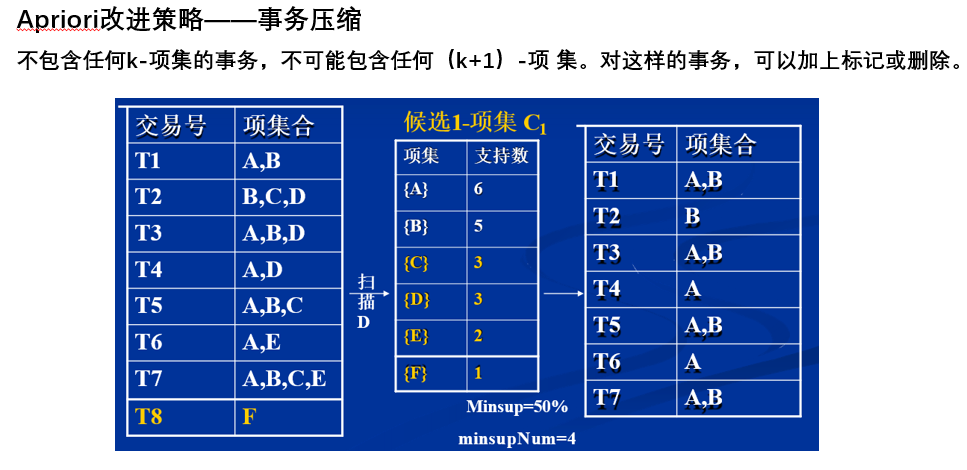
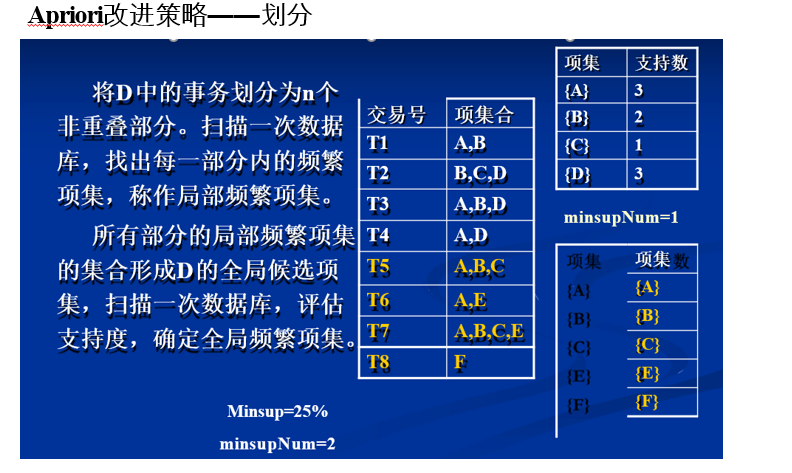
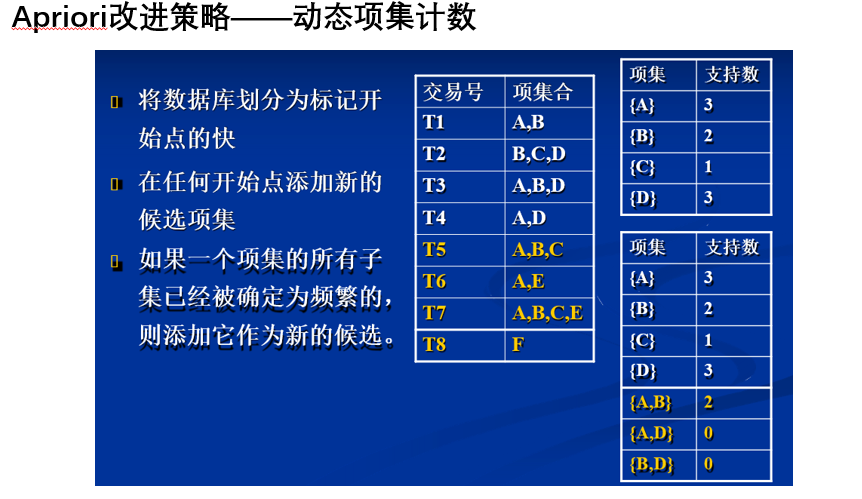
6.2 FP-growth算法
针对Aprior算法需要大量扫描数据库的问题,韩家炜等提出了一种不产生候选项集的FP-Growth 算法,只需扫描两次数据库。
这里有一些预备知识,例如什么是FR树,可以看百度百科:FP-growth算法

6.3 FP-growth算法实例
这里直接用一个栗子来研究一下
FP-growth算法的工作过程

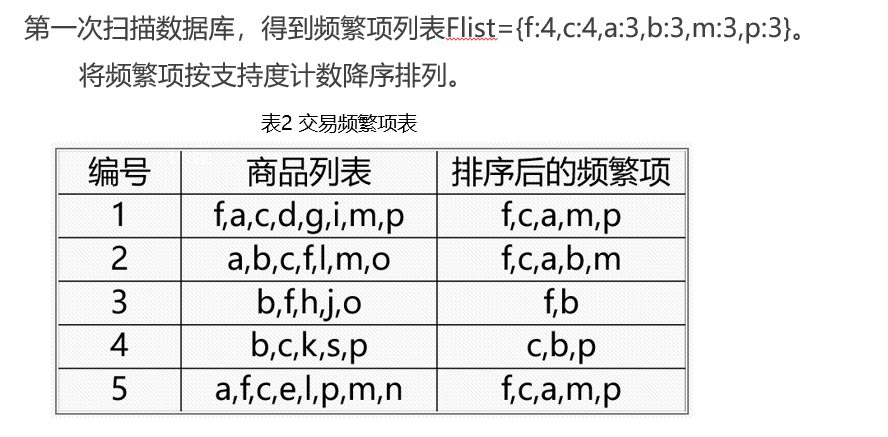
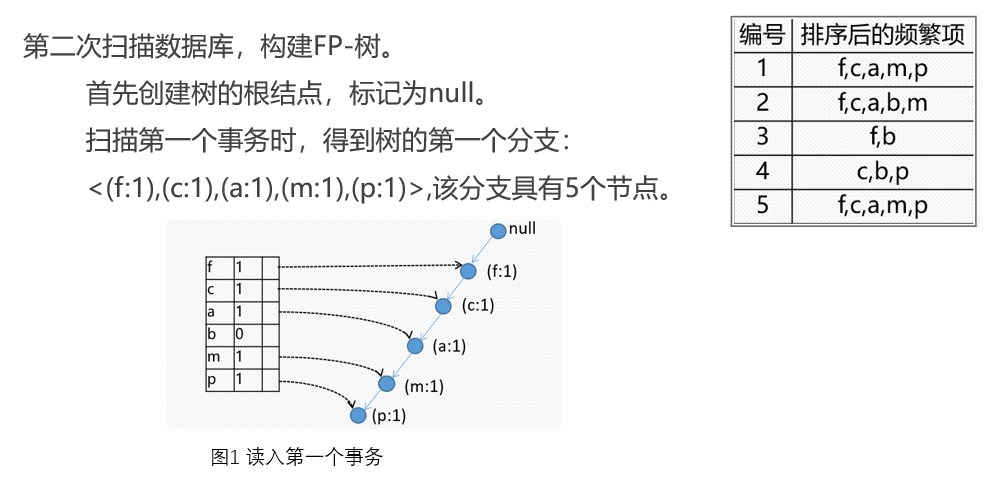
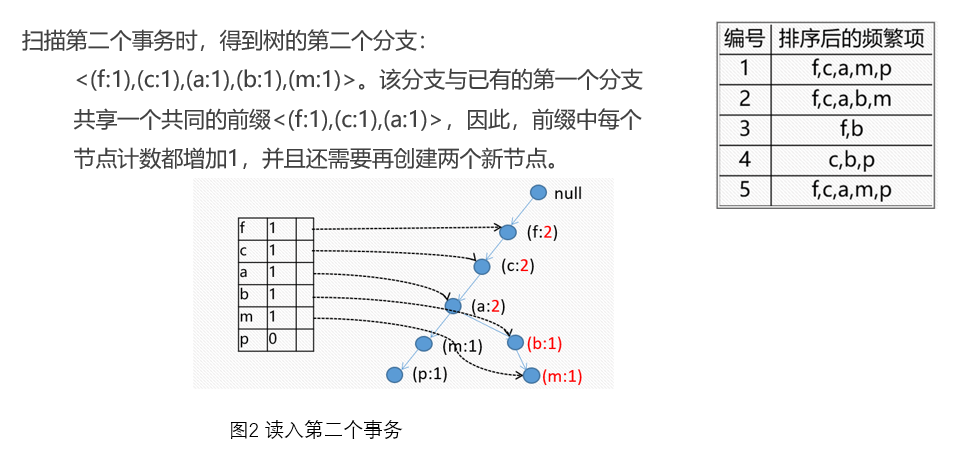
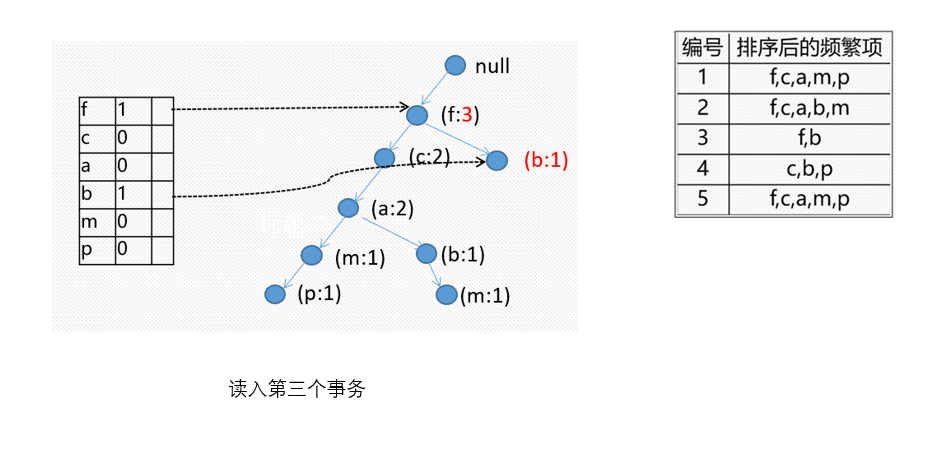
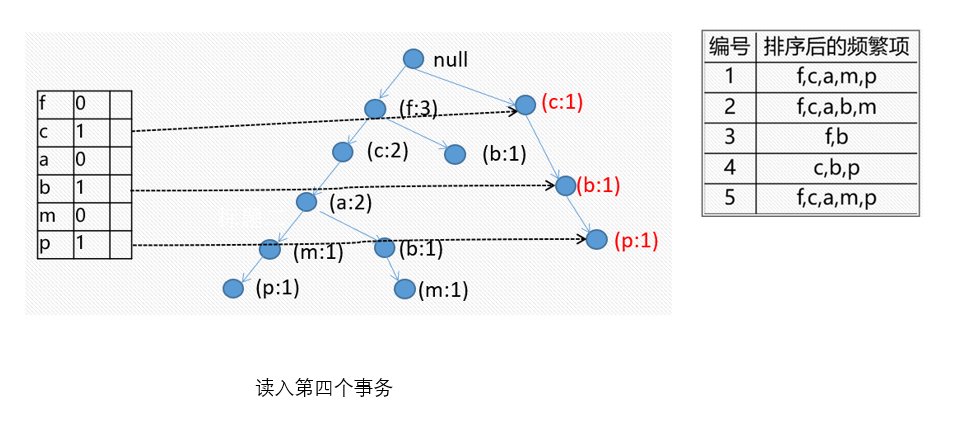
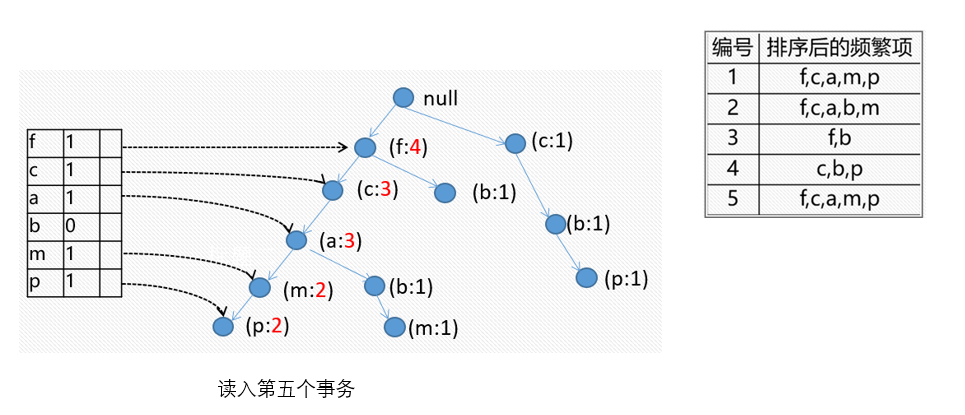
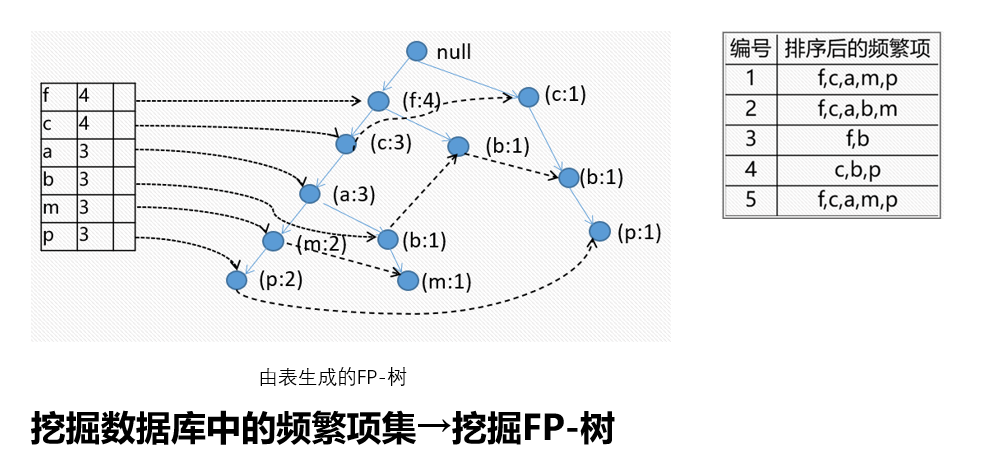
小结一下
FR树的挖掘过程:由长度为1的频繁模式(初始后缀模式)开始,构造它的条件模式基。条件模式基是一个子数据库,由FP-树中与该后缀模式一起出现的前缀路径集组成。然后由此构造频繁模式的条件FP-树,并递归地在该树上进行挖掘
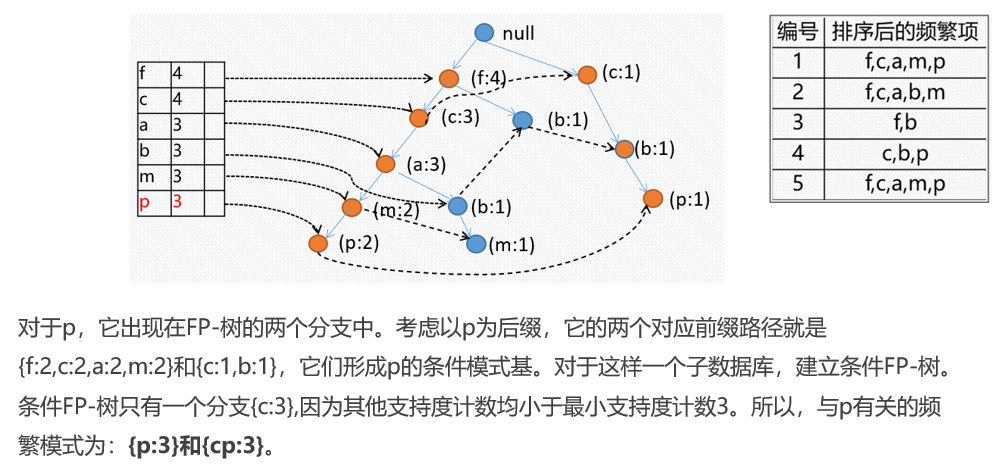
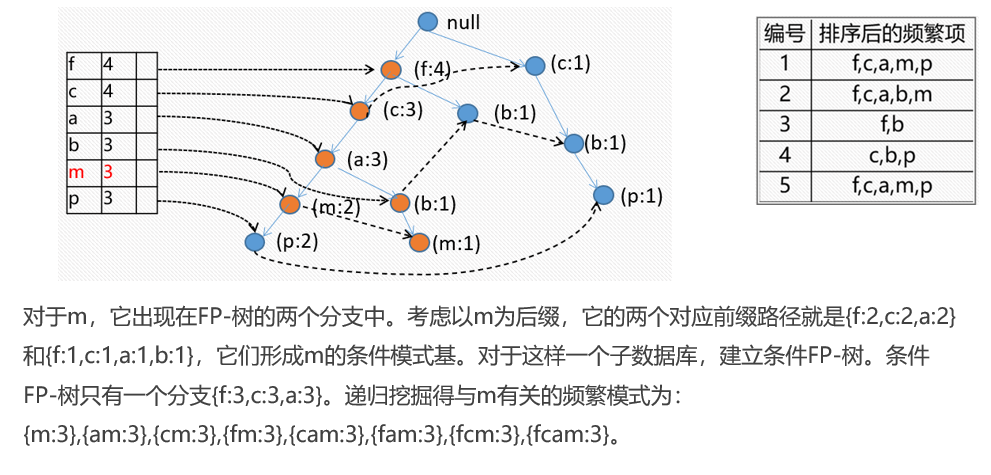
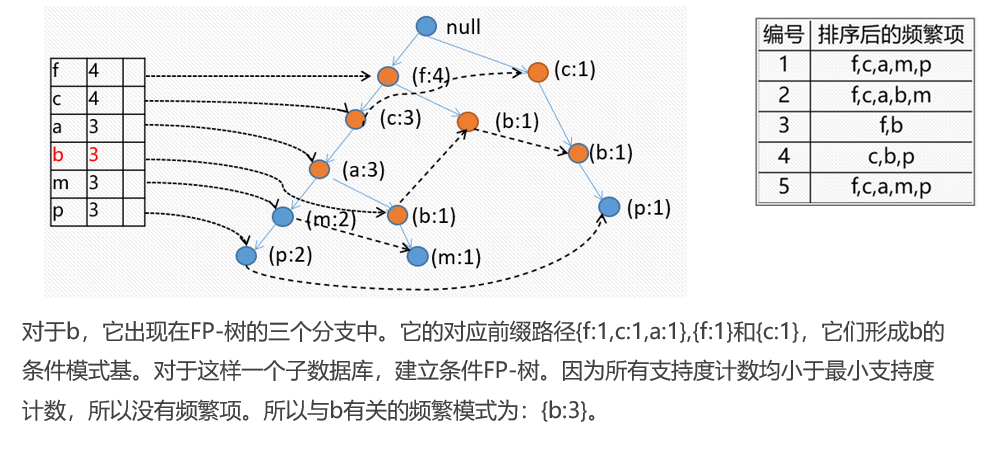
最后我们可以的出下表

6.4 FP-growth算法优缺点
优点:
1、FP-growth算法仅仅遍历了2次数据库,大大节省了扫描数据库的时间。
2、选用了分治策略,把挖掘的长频繁模式转换成递归挖掘短模式问题,再与后缀相连
缺点:
树的子节点过多,例如生成了只包含前缀的树,那么也会导致算法效率大幅度下降。FP-Growth算法需要递归生成条件数据库和条件FP-tree,所以内存开销大,而且只能用于挖掘单维的布尔关联规则
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/132984.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
