大家好,又见面了,我是你们的朋友全栈君。
目录
字符串类型是 Python里面最常见的类型。我们可以简单地通过在引号间包含字符的方式创建它。Python里面单引号和双引号的作用是相同的。字符串是一种直接量或者说是一种标量,这意味着 Python解释器在处理字符串时是把它作为单一值并且不会包含其他 Python类型的。字符串是不可变类型,就是说改变一个字符串的元素需要新建一个新的字符串。字符串是由独立的字符组成的,并且这些字符可以通过切片操作顺序地访问。
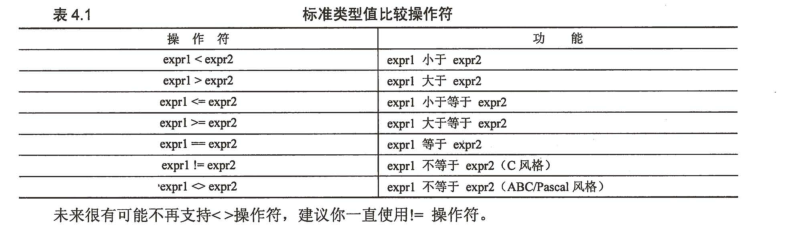
操作符
标准类型操作符
对象值的比较
所有的内建类型均支持比较运算,比较运算返回布尔值True或False。

布尔类型

在做比较的时候,字符串按照ASCII码的大小来进行比较。
序列操作符切片([]和[:])
除了索引,字符串还支持切片。索引可以得到单个字符,而切片可以获取子字符串:
print(word[0:2])
print(word[2:5])

注意切片的开始总是被包括在结果中,而结束不被包括(半开半闭)。这使得 s[:i] + s[i:] 总是等于s
print(word[:2]+word[2:])
print(word[:3]+word[3:])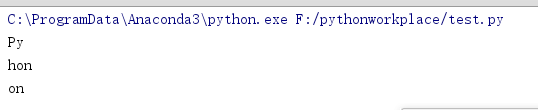
切片的索引有默认值;省略开始索引时默认为0,省略结束索引时默认为到字符串的结束:
print(word[:2])
print(word[3:])
print(word[-2:])
也可以这么理解切片:将索引视作指向字符之间,第一个字符的左侧标为0,最后一个字符的右侧标为 n ,其中 n 是字符串长度。例如:
+---+---+---+---+---+---+ | P | y | t | h | o | n | +---+---+---+---+---+---+ 0 1 2 3 4 5 6 -6 -5 -4 -3 -2 -1
第一行数标注了字符串0…6的索引的位置,第二行标注了对应的负的索引。那么从i到j的切片就包括了标有i和j的位置之间的所有字符。
对于使用非负索引的切片,如果索引不越界,那么得到的切片长度就是起止索引之差。例如,word[1:3]的长度为2。
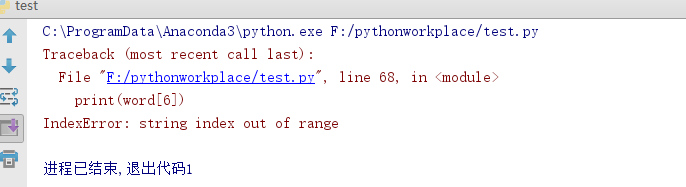
试图使用过大的索引会产生一个错误:
但是,切片中的越界索引会被自动处理:
print(word[4:52])
print(word[45:])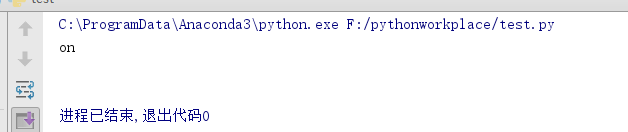
成员操作符(in,not in)
成员操作符用于判断一个字符或者一个子串(中的字符)是否出现在另一个字符串中。出现则返回True,否则返回False注意,成员操作符不是用来判断一个字符串是否包含另一个字符串的,这样的功能由find()或者 index(还有它们的兄弟:rfind()和 rindex()函数)来完成。
print('bc' in 'abcd')
print('n'in 'abcd')
print('fdf' not in 'abcd' )
print('a'not in 'abcd')
连接符(+) 运行时刻字符串连接
print('abc'+'de')
print('abc'+' '+'de')
类似于join()方法
str.join(sequence)
sequence — 要连接的元素序列。返回通过指定字符连接序列中元素后生成的新字符串。
s1 = "-"
s2 = ""
seq = ("r", "u", "n", "o", "o", "b") # 字符串序列
print (s1.join( seq ))
print (s2.join( seq ))
编译时字符串连接
在源码中把几个字符串连在一起写,以此来构建新的字符串。
foo='hello'"world"
通过这种方法,你可以把长的字符串分成几部分来写,而不用加反斜杠。
普通字符串转化为Unicode字符串
如果把一个普通字符串和一个 Unicode字符串做连接处理, Python会在连接操作前先把普通字符串化为 Unicode字符串:
str='hello'+u' '+'world'+u'!'
print(str)
重复操作符(*)
print( 3 * 'un' + 'ium')
只适用于字符串的操作符
格式化操作符(%)
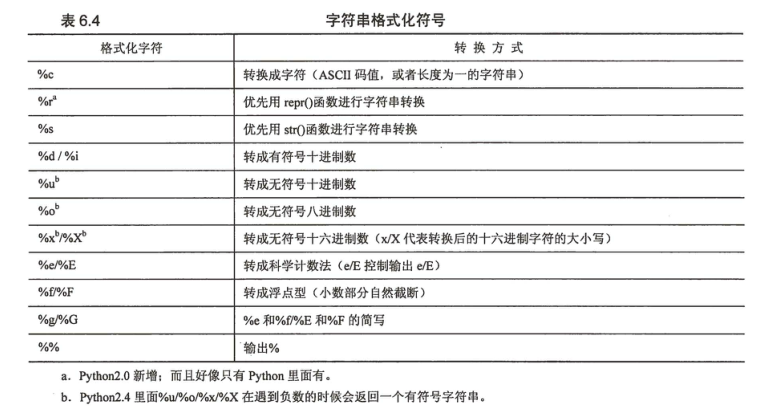

例:
十六进制输出
print('%x'%108)
print('%X'%108)
print('%#x'%108)
print('%#X'%108)
浮点型和科学计数法形式输出
print('%f'%1234.4567890)
print('%.2f'%1234.4567890)
print('%E'%1234.4567890)
print('%e'%1234.4567890)
print('%g'%1234.4567890)
print('%G'%1234.4567890)
整型和字符串输出
print('%+d'%4)
print('%+d'%-4)
print('we are at %d%%'%100)
print('Your host is:%s'%'earth')
print('Host:%s\tPort:%d'%('mars',80))
num=123
print('dec:%d/oct:%#o/hex:%#X'%(num,num,num))
print('MM/DD/YY:%02d/%02d/%d'%(2,15,67))
字符串模板:更简单的替代品
暂时先不学
原始字符串操作符(r/R)
在原始字符串中,所有的字符都是直接按照字面意思来使用,没有转义特殊或不能打印的字符。能够比较方便创建正则表达式。
print(r'%d可以显示啦')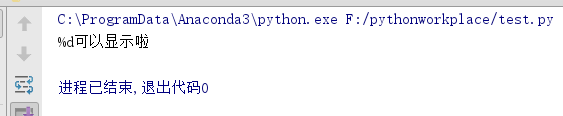
Unicode字符串操作符(u/U)
Unicode字符串操作符,大写的(U)和小写的(u)是在 Python16中和 Unicode字符串一起被引入的,它用来把标准字符串或者是包含 Unicode字符的字符串转换成完全的 Unicode字符串对象。
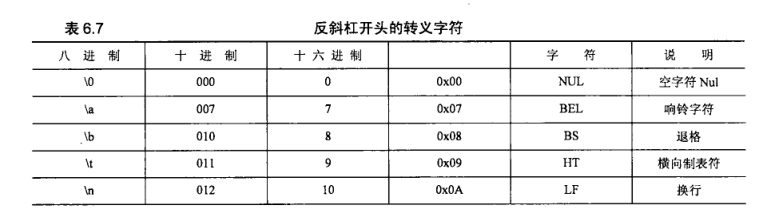
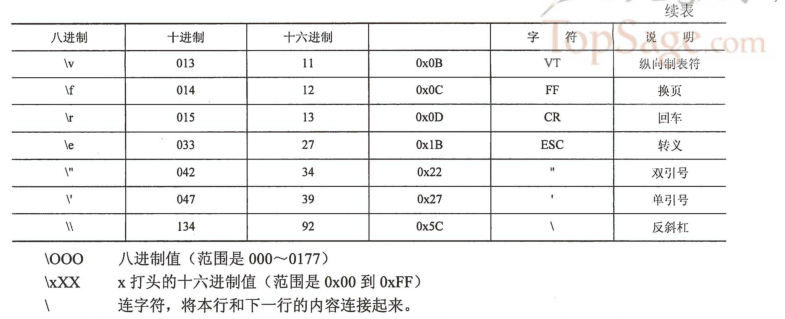
常见的转义字符
- \’ 转义,单引号
- \ 在行末时,表示续行符
- \b 退格
- \n 换行
- \r 回车
- \t 横向制表符
- \xyy 十六进制,假设yy为0a,\x0a表示换行
字符串索引
字符串是可以被索引(下标访问)的,第一个字符索引是0。单个字符并没有特殊的类型,只是一个长度为一的字符串:
word = 'Python'
print(word[0])
print(word[5])
索引也可以用负数,这种会从右边开始数:
print(word[-5])
print(word[-4])
print(word[-3])
注意-0和0是一样的,所以负数索引从-1开始。
编解码
在python3中,字符串是用Unicode编码的,在内存中,一个字符对应多个字节,当字符串用来存储和传输时,就需要将字符串转化为字节为单位的bytes
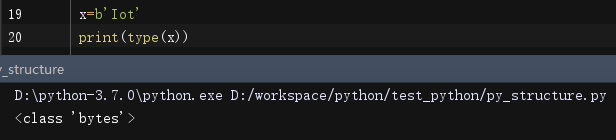
python中的bytes类型用b’xxx’表示
用Unicode编码的字符串可以使用encode()方法转化为bytes
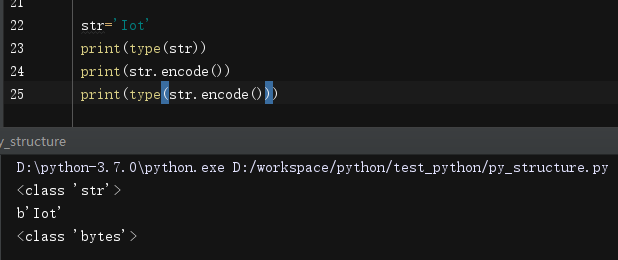
反过来,从存储介质和传输流中获取的bytes类型需要使用decode()方法转化为字符串

内建函数
序列类型函数
len()
返回对象长度
s='jfkhferhgergerugsjfbjha'
print(len(s))max()和min()
返回字符串中ASCII最大或最小的字符
enumerate()
用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。
enumerate(sequence, [start=0])
sequence — 一个序列、迭代器或其他支持迭代对象。
start — 下标起始位置。
返回 enumerate(枚举) 对象。
season=['Spring','Summer','Fall','Winter']
print(list(enumerate(season)))
print(list(enumerate(season,start=1))) #下标从1开始
普通for循环和使用enumerate的比较:
season = ['Spring', 'Summer', 'Fall', 'Winter']
i=0
for _ in season:
print(i,season[i])
i+=1
print()
for i,element in enumerate(season):
print(i,element)
zip()
用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表。
如果各个迭代器的元素个数不一致,则返回列表长度与最短的对象相同,利用 * 号操作符,可以将元组解压为列表。
zip([iterable, …])
iterabl — 一个或多个迭代器; 返回元组列表。 在 Python 3.x 中为了减少内存,zip() 返回的是一个对象。如需展示列表,需手动 list() 转换。
a=[1,2,3]
b=[4,5,6]
c=[4,5,6,7,8]
print(list(zip(a,b)))
print(list(zip(a,c)))
print(list(zip(a,b,c)))
zipped=zip(a,c)
print(list(zip(*zipped))) #与zip相反,*zipped可理解为解压,返回二维矩阵式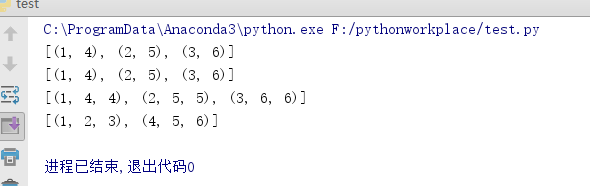
s,t='fos','jhjh'
print(list(zip(s,t)))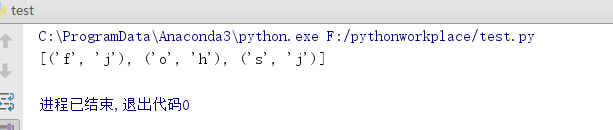
字符串类型函数
input()
Python3.x 中 input() 函数接受一个标准输入数据,返回为 string 类型。
input([prompt]) prompt: 提示信息
str()和unicode()
str()和unicode()函数都是工厂函数,就是说产生所对应的类型的对象。它们接受一个任意类型的对象,然后创建该对象的可打印的或者Unicode的字符串表示。
chr()和ord()
chr():将整数转换成该编码对应的字符串(一个字符)。
ord():将字符串(一个字符)转换成对应的编码(整数)。

字符串内建函数
字符串中字符大小写的变换:
1 str.lower() :转换str中所有大写字符为小写
2 str.upper() :转换str中所有小写字符为大写
3 str.swapcase() :翻转str中的大小写
4 str.title() :返回标题化的字符串。所有单词首字母大写,其余小写
5 str.capitalize() :把字符串的第一个字母大写,其余小写
去空格和特殊符号
1 str.strip() :去掉字符串左边和右边的空格和换行符
2 str.strip(str1) :去掉字符串左边和右边的str1
3 str.lstrip() :去掉字符串左边的空格和换行符
4 str.rstrip() :去掉字符串右边的空格和换行符
字符串对齐,填充
1 str.ljust(width) : 返回width长度的字符串,左对齐,不足的用空格补充
2 str.rjust(width) : 返回width长度的字符串,右对齐,不足的用空格补充
3 str.center(width) : 返回width长度的字符串,居中对齐,不足的用空格补充
4 str.zfill(width) :返回长度为width长度的字符串,原字符串str右对齐,前面补充0
字符串搜索、统计功能
str.find(string,beg=0,end=len(str)) : 检测string是否包含在str中,beg和end指定检测范围,如果找到则返回开始的索引,否则返回-1
str.rfind(string,beg=0,end=len(str)) : 检测string是否包含在str中,beg和end指定检测范围,如果找到则返回开始的索引,否则返回-1,类似find只不过是从右边往左边开始找。
str.count(string,beg=0,end=len(str)) : 返回string在str中出现的次数,在beg-end检测范围内出现则返回出现的次数。
str.index(string,beg=0,end=len(str)) : 和find方法一样,只不过如果string不在str中会报异常。
str.rindex(string,beg=0,end=len(str)):和index方法一样,不过是从右边开始。
字符串检测函数
str.isalnum() :如果str至少有一个字符,并且所有字符都是字母或者数字,则返回true,否则返回false
str.isalpha() : 如果str至少有一个字符,并且所有字符都是字母,则返回true,否则返回false
str.isdigit() :如果str至少有一个字符,并且所有字符都是数字,则返回true,否则返回false
str.isspace() :如果str至少有一个字符,并且所有字符都是空格,则返回true,否则返回false
str.islower() :如果str至少有一个字符,并且所有字符都是小写字母,则返回true,否则返回false
str.isupper() :如果str至少有一个字符,并且所有字符都是大写字母,则返回true,否则返回false
str.istitle(): 如果str每个单词首字母大写其它小写,则返回true,否则返回false
str.startswith(prefix[,start[,end]]) :如果str是以prefix开头,则返回true,否则返回false
str.endswith(suffix[,start[,end]]) :如果str是以prefix结尾,则返回true,否则返回false
字符串替换、分割
str.replace(str1,str2,num=str.count(str1)) //替换指定次数的str1为str2,替换次数不超过num次。
str.split(str1=”“,num=str.count(str1)) :以str1为分隔符,把str分成一个list。num表示分割的次数。默认的分割符为空白字符
str.rsplit(str1=”“,num=str.count(str1)) :和split相似,只是从右边开始分割
str.splitlines(num=str.count(“\n”’)) :把str按行分割符分为一个list,num如果指定则是分割成多少行
字符串连接
str.join(seq) :把seq代表的序列(字符串序列),用str连接起来
字符串的独特特性
特殊字符串和控制字符(转义字符)
三引号
字符串字面值可以跨行连续输入。一种方式是用三重引号:”””…”””或”’…”’。字符串中的回车换行会自动包含到字符串中,如果不想包含,在行尾添加一个\即可。如下例:
print('''Usage: thingy [OPTIONS]
-h Display this usage message
-H hostname Hostname to connect to
""")将产生如下输出(注意最开始print(“””\的换行没有包括进来):

字符串不变性
字符串不能被修改,是 immutable 的。
向字符串的某个索引位置赋值会产生一个错误:
word[0]='J'word[2:]='py'如果需要一个不同的字符串,应当新建一个:
print('J'+word[2:])print(word[2:]+'py')更多Python框架梳理,请参考: 【Python学习】Python最全总结
有问题请下方评论,转载请注明出处,并附有原文链接,谢谢!如有侵权,请及时联系。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/132966.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
