大家好,又见面了,我是你们的朋友全栈君。
Python爬虫实战之通过ajax获得图片地址实现全站图片下载(三)
一.获得图片地址 和 图片名称

 1.进入网址之后
1.进入网址之后
按F12 打开开发人员工具点击elemnts

2.点击下图的小箭头 选择主图中的任意一个图片 那我们这里点击第一个 图片
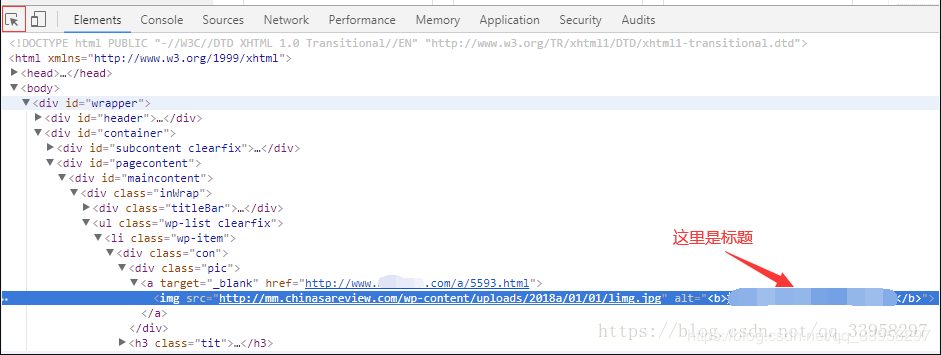
3.显示控制台 为了验证xpath是否正确
4.通过xpath获得a的href 和 title.

(请放大看)我们看到 他提示的是有10个 我们回到网站中看一下 在主页上数一下 他确实是10个 也就是说 我们获得的href 和title是没有任何问题的 那么留着为我们后面使用.
5.我们还需要访问这个链接的请求头的信息 以备后面操作的时候来使用

这里可以看到 没有什么特别的请求头
6.获得每套图里的 所有图片.这也是我们的目的所在 不然前面那么多工序不是浪费吗。
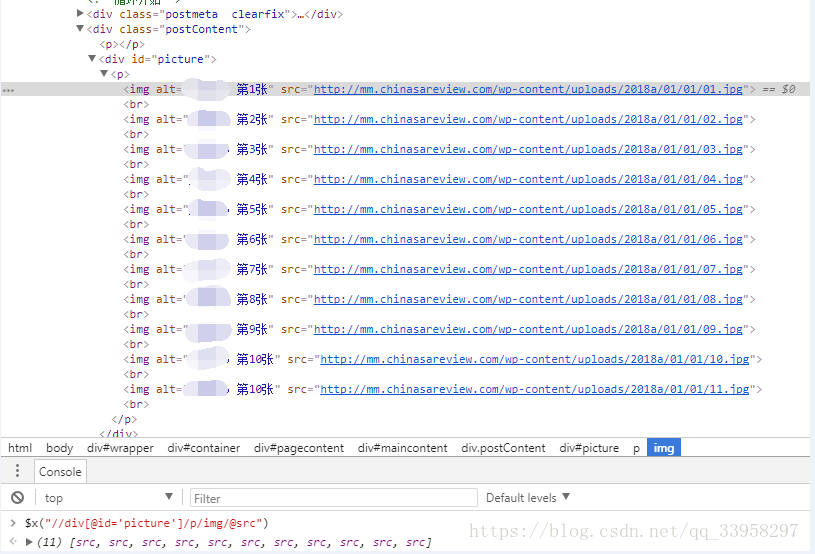
可以看到 我们获得了11个链接地址 不要被源码中的文字所迷惑
7.获得相应的请求头

可以发现 需要注意的只有一个字段Referer 这里的地址就是我们访问这个页面进来的时候的那个地址 只要把那个地址给上就行了
8.对于404的处理 如果出现了404那就只有重新请求了
二.编写python代码实现爬取.
1.需要用到的库有:
Requests lxml
2.IDE : pycharm
3.python 版本: 2.7.15
下载地址: https://download.csdn.net/download/qq_33958297/12195656
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/132928.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
