大家好,又见面了,我是你们的朋友全栈君。
知识图谱—知识推理综述(一)
1 知识推理的概念以及分类
1.1 知识推理的基本概念
所谓的知识推理,就是在已有知识的基础之上,推断出未知的知识的过程。通过从已知的知识出发,通过已经获取的知识,从中获取到所蕴含的新的事实,或者从大量的已有的知识中进行归纳,从个体知识推广到一般性的知识。
根据上面的概念的描述,我们可以知道,对于知识推理而言,其包括的内容可以分为两种,第一种是我们已经知道的,用于进行推理的已有知识,另外一种是我们运用现有的知识推导或者归纳出来的新的知识。对于知识而言,其形式是多种多样的,可以是一个或者多个段落描述,又或者如传统的三段论的形式。继续以三段论为例,其基本结构包括大前提,小前提,结论三个部分,在这三个部分中大前提,小前提是已知的知识,而结论则是我们通过已知的知识所推理出来的新的知识。在知识表示上,还有规则推理中的规则形式,知识图谱上的三元组的形式等等。
1.2 知识推理的分类
1.2.1 逻辑推理和非逻辑推理
推理的方法大致上可以分为逻辑推理和非逻辑推理,逻辑推理的过程约束和限制都比较严格,而相对而言非逻辑推理的对于约束和限制的关注度则没有那么高。根据逻辑推理的方法进行细分,可以分成演绎推理,归纳推理。
演绎推理: 是从一般到个别的推理,这是一种自上而下的逻辑,在给定一个或者多个前提的条件下,推断出一个必然成立的结果。举一个例子来说,“如果今天是星期二,那么小明会去实验室”,我们将这样的假设性描述称为假言命题,其中前半句称为前件,后半句称为后件,并且,其中“今天是星期二”被称为是性质命题,则根据性质命题,我们可以推理出“小明会去上班”。我们将这种逻辑推理称为是假言推理,并且属于肯定前件假言推理。进一步,根据“小明不会去实验室”,可以推理出“今天不是星期二”,这种推理机制也属于假言推理,并且属于否定后件的假言推理。
在举一个例子来说,“如果小明生病了,那么小明会缺席”,“如果小明缺席,他将错过课堂讨论”,从这例子中,我们可以看出,一共给出了两个假言命题,其中第一个假言命题的后件和第二个假言命题的前件所描述的内容是一致的。根据这两个假言命题,我们可以推理出一个新的假言命题,即“如果小明生病了,他将错过课堂讨论”。这里的推理形式称为假言三段论。
无论是“假言推理”还是“假言三段论”,这些都属于演绎推理的经典方法,通过对于前件,后件,性质命题的形式化,我们可以这些假设来进行推理。
演绎推理历史悠久,其可以进一步分成自然演绎,归结原理,表演算等类别。其中自然演绎是通过数学逻辑来证明结果成立的过程。而归结原理则是采用反证法的原则,将需要推导的结果,通过反证其不成立的矛盾性来进行推导。表演算是通过通过构建规则的完全森林,每一个节点用概念集进行标记,每一条边用规则进行标记,表示节点之间存在的规则关系,然后利用扩展规则,给节点标签添加新的概念,在森林中添加新的节点等方法来进行推理。其推理过程是完全基于所构建的规则森林的。
归纳推理: 与演绎推理相反的是,归纳推理是一种自下而上的过程,即从个体到一般的过程。通过已有的一部分知识,我们可以归纳总结出这种知识的一般性原则。举个例子来说:“如果我们所见过的每一个糖尿病人都有高血压,那么我们可以大致认为,糖尿病应该会导致高血压”。
进一步,比较典型的归纳推理的方法包括归纳泛化和统计推理,其中泛化归纳是指我们通过观察部分数据,而将通过这部分数据得出的结论泛化到整体的情况上。举一个具体的例子来说,当前有二十个学生,每个学生不是硕士生,就是博士生。随机从这二十个人中抽取4个人,发现其中硕士生有3个,博士生有1个,那么我们可以推断出,这二十个人中,有15个硕士,5个博士。而统计推理是将整体的统计结果应用到个体之上。比如,当前15个硕士中,有60%的学生申请了博士,那么如果小明是这15个硕士中的一个,那么小明将有60%的概率申请博士。
相比于演绎推理,归纳推理没有进行形式化的推导。并且,归纳推理的本质是基于数据而言,数据所反馈的结论不一定是事实,也就是说即使归纳推理获得结论在当前数据上全部有效,也不能说其能够完全适应于整体。而演绎推理的前提是事实,这种推理的方法获取的结果也是一个事实,也就是在整体上也是必然成立的。
对于归纳推理而言,其也可以进行细分,其细分可以分为溯因推理和类比推理。溯因推理也是一种逻辑推理,在给定一个或者多个观察到的事实O,并且根据已有的知识T来推断出对已有观察最简单其最有可能的解释的过程。举一个例子来说,当一个病人显示出某种病症,而造成这个病症的原因有很多的时候,寻找引起整个病症最可能的原因就是溯因推理。在溯因推理中,要使基于知识T而生成的对于O的解释E是合理的,需要满足两个条件,第一个条件是E可以通过T和O推理得出。而是E和T是相关而且相容的。举一个例子来说:我们已经知道了“下雨了,马路一定会湿 (T)”,如果我们观察到马路是湿的(O),则可以通过溯因推理出大概率是下雨了(E)。
类比推理可以看做是基于对一个事务的观察而进行的对另外一个事务的归纳推理。通过寻找两个事务之间的类别信息,将已知事务上的结论进行迁移到新的事务之上。举个例子来说,小明和小红都是同龄人,其中小明和小红都喜欢歌手周杰伦,而且小明还喜欢陈奕迅,那么我们可以推理出,小红也以一定的概率喜欢陈奕迅。这种推理方法相对而言,错误率要更高一些。
1.2.2 其他推理分类
除了我们上面介绍的推理方式,一般的推理方法还包括一下几种:
- 确定性推理和非确定性推理: 确定性推理是指所利用的知识是精确的,并且推理出的结论也是确定的。在不确定性的推理中,知识都具有某种不确定性,不确定性的推理又分为似然推理和近似推理,前者是基于概率论的推理方式。而后者则是基于模糊逻辑的推理。
- 将推理方法按照推理过程中推理出的结论是否单调递增来进行划分,分为单调推理和非单调推理。在单调推理中,随着推理的方向向前推进和新的知识的加入,推理出来的结论单调递增,逐步接近最终的目标,上述多个命题的演绎推理就属于单调推理。而非单调推理是指在推理的过程中,随着新的知识的加入,非单调推理需要否定已经推理出来的结论,是推理回退到前面的某一步,重新开始。
- 将推理方法是否用与问题有关的启发性知识来划分,分为启发式推理和非启发式推理。启发式推理的过程中,会利用到一些启发式的规则,策略等等,而非启发式推理则是一般的推理过程。
1.3 总结
最后,我们用一张图来总结一下推理的分类:
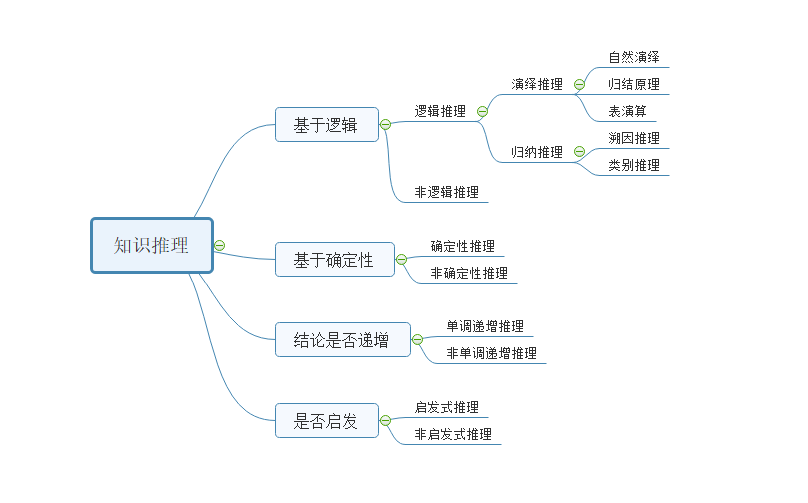

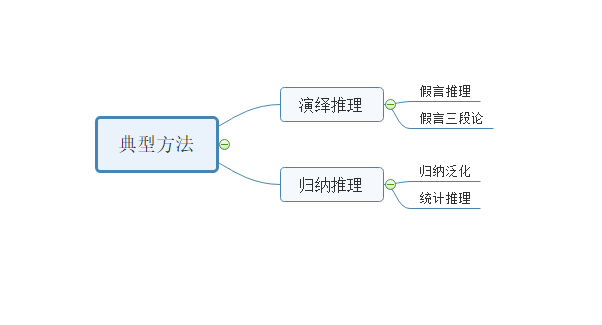
2. 面向知识图谱的知识推理
2.1 引入
对于知识图谱而言,其最为常见的表示方式是采用三元组的表示方式,通过三元组,我们可以表示不同事物之间的语义关系,已经事物与属性之间的属性关系。对于如何表示,这里不再赘述,有兴趣的读者可以参考其他文献。在获取知识图谱的表示之后,我们就拥有了一部分的事实,而知识图谱的知识推理就是在基于已有的知识图谱的事实的基础上,推理出新的知识或者识别出知识图谱上已有知识的错误。根据推理的两个作用,我们自然而然的可以想到两个下游的任务,第一个任务是知识图谱的补全,第二个任务是知识图谱的去噪,所谓知识图的去噪就是识别出知识图谱中的错误的三元组。
从知识图谱补全的角度出发,我们希望的是利用已有的完整的三元组,来为确实实体或者关系的三元组进行补全。也就是在给定两个元素的情况下,利用已有的三元组来推理出缺失的部分。比如,给定头实体和关系,利用知识图谱上的其他的三元组来推理出尾实体。再比如给定头尾实体,利用知识图谱上的三元组来推导出两者的关系。
从知识图谱去噪的角度出发,在知识图谱上存在着大量的三元组,由于数量规模巨大,并且可能是知识图谱可能是自动构建起来的,这难免会让知识图谱中的三元组存在着一定的误差。此时,我们就需要获知到当前知识图谱中的那些三元组是无效的。然后将其从整个知识图谱中进行删除。这就需要利用到知识图谱的推理技术。
总的来说,知识推理在知识图谱补全任务中关注的是扩充图谱。而在知识图谱去噪任务中关注的是缩减知识图谱的规模,增加知识图谱的准确性。实际上,相对于去噪任务而言,知识图谱补全的任务更加的常见。
在上述我们介绍的关于推理方法中,均属于传统的推理方法,这种推理方法需要依赖于规则,前提,假设等等条件。而随着神经网络等机器学习技术的发展,越来越多的基于图谱中节点和关系表示的推理方法被提出。所以,目前的推理方法可以分为传统推理和基于表示的推理,以及基于两种方式混合的混合推理。
2.2 传统推理在知识图谱上的应用
传统的知识推理由于历史悠久,所以其理论支持比较完善,并且其基于的前提和规则更容易被人理解,所以其拥有更好的可解释性。目前,传统的知识推理在本体推理上仍然发挥着重要的作用。所谓的本体,简单的理解就是位于实体之上的概念和规则。这些概念是实体获取的准则,但是其本身不是实体,也就是其不会在知识图谱上展示出来,或者其在知识图谱上仅仅是一个概念,负责和相关的实例相连接。
2.2.1 基于传统规则的推理
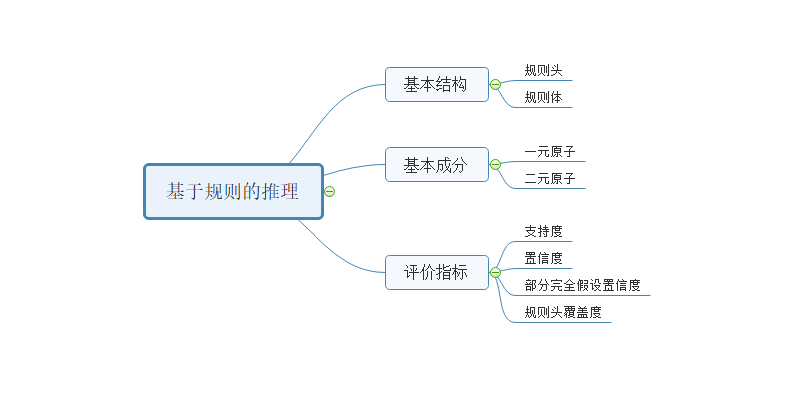
所谓的规则,指的是一定的限制和必要的约束。这种推理方法是在知识图谱上运用简单的规则或者统计特征来进行推理。一般情况下,一条规则的具体形式如下:
r u l e : h e a d < − b o d y rule:head<-body rule:head<−body
上面的形式可以理解为,我们可以根据规则的主体来推理出规则的头部。其中规则头由一个二元的原子所构成,而规则的主题则由一个或者多个一元原子或者二元原子所构成。
原子: 是指包含了变量的元祖。举一个例子来说:位置(X)是一个一元原子,表示实体变量X是一个位置实体。而“妻子(X,Y)”是一个二元原子,表示的是实体变量X的妻子是实体变量Y。二元原子中包含的实体变量可以有一个或者两个,比如“妻子(X,叶莉)”,表示实体变量X的妻子是叶莉。在规则主体中,不同的原子通过逻辑表达式组合在一起,并且规则主体中的原子可以是肯定的形式,也可以是否定的形式。举一个规则的具体形式如下:
父 亲 ( X , Z ) < − 妻 子 ( X , Y ) ∧ 孩 子 ( Y , Z ) ∧ ¬ 离 婚 ( X ) ∧ ¬ 离 婚 ( Y ) 父亲(X,Z)<-妻子(X,Y)∧孩子(Y,Z)∧¬离婚(X)∧¬离婚(Y) 父亲(X,Z)<−妻子(X,Y)∧孩子(Y,Z)∧¬离婚(X)∧¬离婚(Y)
通过右侧的规则主体,我们就可以推导出X是Z的父亲,并且构成新的三元组“<X,父亲,Z>”。上述的规则主体中,出现了否定的原子,进一步,我们可以将肯定的原子和否定的原子分开,也就是如下的表示:
父 亲 ( X , Z ) < − ( 妻 子 ( X , Y ) ∧ 孩 子 ( Y , Z ) ) + ∧ ( ¬ 离 婚 ( X ) ∧ ¬ 离 婚 ( Y ) ) − 父亲(X,Z)<-(妻子(X,Y)∧孩子(Y,Z))^+∧(¬离婚(X)∧¬离婚(Y))^- 父亲(X,Z)<−(妻子(X,Y)∧孩子(Y,Z))+∧(¬离婚(X)∧¬离婚(Y))−
即推广到一般的形式,可以表示为:
r u l e : h e a d < − b o d y + ∧ b o d y − rule:head<-body^+∧body^- rule:head<−body+∧body−
如果规则主体中仅仅包含肯定的原子,那么则称这样的规则为霍恩规则。可以表示为如下的形式:
a 0 < − a 1 ∧ a 2 ∧ . . . . . ∧ a n a_0<-a_1∧a_2∧…..∧a_n a0<−a1∧a2∧.....∧an
其中每一个 a i a_i ai是一个原子。进一步,利用霍恩规则的思想在知识图谱上推理的时候,我们利用的是三元组,也就是说一般来说是两个实体,所以可以表述为如下的形式:
r 0 ( e 1 , e n + 1 ) < − r 1 ( e 1 , e 2 ) ∧ r 2 ( e 2 , e 3 ) ∧ . . . . ∧ r n ( e n , e n + 1 ) r_0(e_1,e_{n+1})<-r_1(e_1,e_2)∧r_2(e_2,e_3)∧….∧r_n(e_n,e_{n+1}) r0(e1,en+1)<−r1(e1,e2)∧r2(e2,e3)∧....∧rn(en,en+1)
这种规则在知识图谱推理中称为路径规则。其中,规则主体中的原子均为含有两个变量的二元原子,并且在规则主体中,所有的二元原子构成一个从规则头中的两个实体之间的路径,整个规则在知识图谱中形成一个闭环的路径。
最后,我们来讨论一下基于规则推理的评价方法。对于学习到的规则,其评价方法一般包括三种,分别为支持度,置信度,规则头覆盖度。
支持度:指的是满足规则主体和规则头的实例的个数,规则的实例化是指将规则中的变量替换成知识图谱中的真实的实体后的结果。所以,支持度一般是一个大于等于0的整数。一个规则的支持度越大,说明这个规则的实例在知识图谱中存在的越多。
置信度: 置信度的计算公式为:
c o n d i d e n c e ( r u l e ) = s u p p o r t ( r u l e ) # b o d y ( r u l e ) condidence(rule)=\frac{support(rule)}{\#body(rule)} condidence(rule)=#body(rule)support(rule)
其中support(rule)是支持度。#body(rule)指的是满足规则主体的实例的个数。两者的比值可以解释为满足规则的实例和只满足规则主体的实例的个数的比值。一个规则的置信度越高,其质量也就越高。
上述置信度的计算方式中存在一个假设,其假设的是知识图谱上不存在的三元组都是错误的(不难看出,分母中的规则对应的实例化都是在知识图谱中出现的。而分母中规则主体推理出来的规则头部可能在知识图谱上出现,也可能是新的,即没有在图谱上出现。如果都出现,则比值为1,否则小于1)。显然,这种假设是错误的,为了解决这个问题,我们引入基于部分完全假设的置信度计算方法,表示为:
P C A c o n f i d e n c e ( r u l e ) = s u p p o r t ( r u l e ) # b o d y ( r u l e ) ∧ r 0 ( x , y − ) PCA\ confidence(rule)=\frac{support(rule)}{\#body(rule)∧r_0(x,y^-)} PCA confidence(rule)=#body(rule)∧r0(x,y−)support(rule)
这里,假设规则头结果为 r 0 ( x , y ) r_0(x,y) r0(x,y),根据分母可以看出,只有当实体x通过关系r链接到除了y的 y − y^- y−,才能算到分母中进行计数。
规则头覆盖度 : 规则头覆盖度的计算公式为:
H C ( r u l e ) = s u p p o r t ( r u l e ) # h e a d ( r u l e ) HC(rule)=\frac{support(rule)}{\#head(rule)} HC(rule)=#head(rule)support(rule)
即满足规则的实例数量和满足规则头部的实例数量的比值。
2.2.2 小结
在了解了基于规则的推理之后,我们用一张图来总结这个过程:
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/132911.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
