大家好,又见面了,我是你们的朋友全栈君。
误差反向传播算法误差
反向传播算法(back propagation,简称BP模型)是1986年由Rumelhart和McClelland为首的科学家提出的概念,是一种按照误差逆向传播算法训练的多层前馈神经网络,是目前应用最广泛的神经网络。
误差反向传播算法系统的解决了多层神经网络隐含层连接权学习问题,人们把采用这种算法进行误差校正的多层前馈网络称为BP网。BP神经网络具有任意复杂的模式分类能力和优良的多维函数映射能力,解决了简单感知器不能解决的异或(Exclusive OR,XOR)和一些其他问题。
从结构上讲,BP网络具有输入层、隐藏层和输出层;
从本质上讲,BP算法就是以网络误差平方为目标函数、采用梯度下降法来计算目标函数的最小值。
因此学习误差反向传播算法对于深度学习的深造起到非常重要的作用,这也是本篇博客的主题。
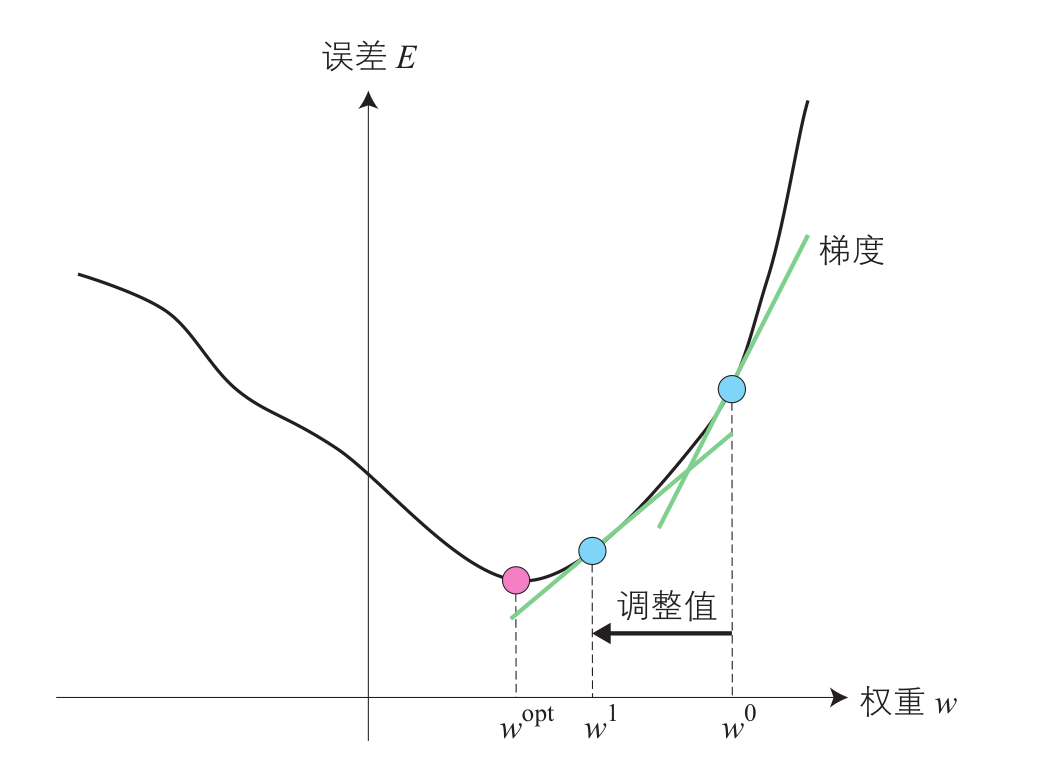

由于梯度下降法需要求解相邻层的梯度,这就要求网络中需要处处可导,也就是需要激活函数也必须支持可导性。M-P模型中使用step函数作为激活函数,只能输出0或1,不连续所以不可导。为了使误差能够顺利传播,科学家们提出了可导函数sigmoid作为激活函数 f ( u ) f(u) f(u),但是在后期的使用中发现sigmoid函数也存在一定的问题(梯度饱和问题),于是发展出了ReLU函数及其变形激活函数,想深入了解激活函数的小伙伴可以查看下这篇博客:https://blog.csdn.net/ViatorSun/article/details/82418578。
1) 以单层感知器入
反向传播算法便于大家理解,下面先解释下单层感知器的梯度下降法。由复合函数求导法则可以知道,误差函数求导如下所示:
∂ E ∂ w i = ∂ E ∂ y ∂ y ∂ w i \frac{\partial E}{\partial w_i} = \frac{\partial E}{\partial y}\frac{\partial y}{\partial w_i} ∂wi∂E=∂y∂E∂wi∂y
设 y = f ( u ) y=f(u) y=f(u),求误差函数 E E E 对 w i w_i wi 的导数为:
∂ E ∂ w i = − ( r − y ) ∂ y ∂ w i = − ( r − y ) ∂ f ( u ) ∂ w i \frac{\partial E}{\partial w_i} = -(r-y)\frac{\partial y}{\partial w_i} = -(r-y)\frac{\partial f(u)}{\partial w_i} ∂wi∂E=−(r−y)∂wi∂y=−(r−y)∂wi∂f(u)
f ( u ) f(u) f(u)的导数就是对复合函数求导
∂ E ∂ w i = − ( r − y ) ∂ f ( u ) ∂ u ∂ u ∂ w i \frac{\partial E}{\partial w_i} = -(r-y)\frac{\partial f(u)}{\partial u} \frac{\partial u}{\partial w_i} ∂wi∂E=−(r−y)∂u∂f(u)∂wi∂u
u u u对 w i w_i wi求导的结果只和 x i x_i xi相关: ∂ u ∂ w i = x i \frac{\partial u}{\partial w_i} = x_i ∂wi∂u=xi 整理下上面两个式子,得到:
∂ E ∂ w i = − ( r − y ) x i ∂ f ( u ) ∂ u \frac{\partial E}{\partial w_i} = -(r-y)x_i\frac{\partial f(u)}{\partial u} ∂wi∂E=−(r−y)xi∂u∂f(u)
在此,我们对激活函数 S i g m o i d Sigmoid Sigmoid : σ ( x ) = 1 1 + e − x \sigma(x) = \frac {1}{1+e^{-x}} σ(x)=1+e−x1函数求导:
∂ σ ( x ) ∂ x = e − x ( 1 + e − x ) 2 \frac{\partial \sigma(x)}{\partial x} = \frac {e^{-x}}{(1+e^{-x})^2} ∂x∂σ(x)=(1+e−x)2e−x
令 e − x = u e^{-x} = u e−x=u 则导函数为:
∂ f ( u ) ∂ u = f ( u ) ( 1 − f ( u ) ) \frac{\partial f(u)}{\partial u} = f(u)(1-f(u)) ∂u∂f(u)=f(u)(1−f(u))
将激活函数的导数代入上面整理结果得到:
∂ E ∂ w i = − ( r − y ) x i f ( u ) ( 1 − f ( u ) ) \frac{\partial E}{\partial w_i} = -(r-y)x_i f(u)(1-f(u)) ∂wi∂E=−(r−y)xif(u)(1−f(u))
由于输出结果 y = f ( u ) y=f(u) y=f(u),所以单层感知器的权重调整值为(其中 η \eta η为学习率):
Δ w i = − η ∂ E ∂ w i = η ( r − y ) y ( 1 − y ) x i \Delta w_i = – \eta\frac{\partial E}{\partial w_i} = \eta(r-y)y(1-y)x_i Δwi=−η∂wi∂E=η(r−y)y(1−y)xi
至此,这就是单层感知器权重的调节量。
2)多层感知器的反传传播算法
接下来,我们再分析下多层感知器。多层感知器的误差函数 E E E等于个输出单元的误差总和。 E = 1 2 ∑ j = 1 q ( r j − y j ) 2 E = \frac{1}{2} \sum_{j=1}^q (r_j – y_j)^2 E=21j=1∑q(rj−yj)2
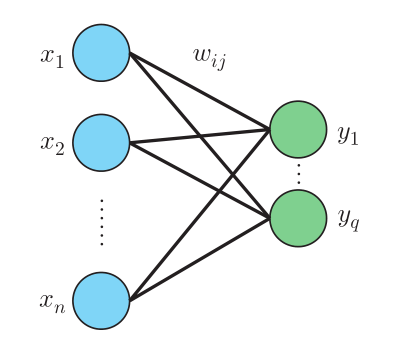
对误差函数求导得:
∂ E ∂ w i j = ∂ E ∂ y j ∂ y j ∂ w i j \frac{\partial E}{\partial w_{ij}} = \frac{\partial E}{\partial y_j} \frac{\partial y_j}{\partial w_{ij}} ∂wij∂E=∂yj∂E∂wij∂yj
其中, w i j w_{ij} wij代表 x i x_i xi和 y j y_j yj之间的连接权重,对 E E E求导的结果只和 y j y_j yj相关,如下所示:
∂ E ∂ w i j = − ( r j − y j ) ∂ y j ∂ w i j \frac{\partial E}{\partial w_{ij}} = -(r_j – y_j) \frac{\partial y_j}{\partial w_{ij}} ∂wij∂E=−(rj−yj)∂wij∂yj
与单层感知相同,对上式展开后对复合函数求导:
∂ E ∂ w i j = − ( r j − y j ) ∂ y j ∂ u j ∂ u j ∂ w i j \frac{\partial E}{\partial w_{ij}} = -(r_j – y_j) \frac{\partial y_j}{\partial u_j} \frac{\partial u_j}{\partial w_{ij}} ∂wij∂E=−(rj−yj)∂uj∂yj∂wij∂uj
下面与单层感知器一样,对误差函数求导得:
∂ E ∂ w i j = − ( r j − y j ) y j ( 1 − y j ) x i \frac{\partial E}{\partial w_{ij}} = -(r_j – y_j) y_j (1-y_j)x_i ∂wij∂E=−(rj−yj)yj(1−yj)xi
则权重的调节值为(其中 η \eta η为学习率):
Δ w i j = η ( r j − y j ) y j ( 1 − y j ) x i \Delta w_{ij} = \eta(r_j – y_j )y_j (1-y_j)x_i Δwij=η(rj−yj)yj(1−yj)xi
由此可见,多层感知器中,只需要使用与连接权重 w i j w_{ij} wij相关的输入 x i x_i xi和输出 y j y_j yj,即可计算出连接权重的调节值。

将神经网络分解开可以更清晰的分析,再将最后一列各变量之间的偏导数累成就是整个链式法则的体现。
3) 带中间层的多层感知器的反向传播算法
最后我们再解释下带中间层的多层感知器的梯度下降法。由于中间层的加入,层之间的权重下标我们增加到三个,其中 i i i表示输入层单元, j j j表示中间层单元, k k k表示输出层单元 。如下图所
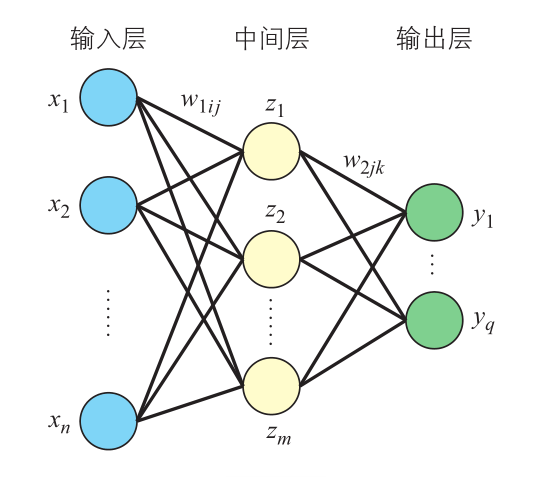
首先考虑输出层与中间层之间的连接权重 w 2 j k w_{2jk} w2jk的调整。对权重 w 2 j k w_{2jk} w2jk求导:
∂ E ∂ w 2 j k = ∂ E ∂ y k ∂ y k ∂ u 2 k ∂ u 2 k ∂ w 2 j k \frac{\partial E}{\partial w_{2jk}} = \frac{\partial E}{\partial y_k} \frac{\partial y_k}{\partial u_{2k}} \frac{\partial u_{2k}}{\partial w_{2jk}} ∂w2jk∂E=∂yk∂E∂u2k∂yk∂w2jk∂u2k
经过误差函数 E E E对输出 y k y_k yk求导,输出 y k y_k yk求导,输出 y k y_k yk对激活值 u 2 k u_{2k} u2k求导,激活值 u 2 k u_{2k} u2k对连接权重 w 2 j k w_{2jk} w2jk求导之后,得到:
∂ E ∂ w 2 j k = − ( r k − y k ) y k ( 1 − y k ) z j \frac{\partial E}{\partial w_{2jk}} = -(r_k – y_k) y_k ( 1-y_k) z_j ∂w2jk∂E=−(rk−yk)yk(1−yk)zj
所以,即便是输出层有多个单元,只要对每个输出单元分别求导后,也能得到误差函数对中间层权重的偏导数接下来计算输入层和中间层之间的连接权重 w 1 i j w_{1ij} w1ij的偏导数:
∂ E ∂ w 1 i j = ∑ k = 1 q [ ∂ E ∂ y k ∂ y k ∂ u 2 k ∂ u 2 k ∂ w 1 i j ] \frac{\partial E}{\partial w_{1ij}} = \sum_{k=1}^q[ \frac{\partial E}{\partial y_k} \frac{\partial y_k}{\partial u_{2k}} \frac{\partial u_{2k}}{\partial w_{1ij}}] ∂w1ij∂E=k=1∑q[∂yk∂E∂u2k∂yk∂w1ij∂u2k]
中间层的单元 j j j和输出层的所有单元相连,所以如上式所示,误差函数 E E E对连接权重 W 1 i j W_{1ij} W1ij求偏导,就是对所有输出单元的导数进行加权和,实际使用的是所有输出单元连接权重的总和。将 s i g m o i d sigmoid sigmoid函数的导数和误差函数代入到上式,得:
∂ E ∂ w 1 i j = − ∑ k = 1 q [ ( r k − y k ) y k ( 1 − y k ) ∂ u 2 k ∂ w 1 i j ] \frac{\partial E}{\partial w_{1ij}} = -\sum_{k=1}^q[ (r_k – y_k)y_k(1-y_k) \frac{\partial u_{2k}}{\partial w_{1ij}}] ∂w1ij∂E=−k=1∑q[(rk−yk)yk(1−yk)∂w1ij∂u2k]
由于连接权重 w 1 i j w_{1ij} w1ij只对中间层 z j z_j zj的状态产生影响,所以上式中剩余部分求导后的结果如下:
∂ u 2 k ∂ w 1 i j = ∂ u 2 k ∂ z j ∂ z j ∂ w 1 i j \frac{\partial u_{2k}}{\partial w_{1ij}} = \frac{\partial u_{2k}}{\partial z_j } \frac{\partial z_j}{\partial w_{1ij}} ∂w1ij∂u2k=∂zj∂u2k∂w1ij∂zj
激活值 u 2 k u_{2k} u2k对 z j z_j zj求导得到连接权重 w 2 j k w_{2jk} w2jk,结合下式就可以求出输入层与中间层之间的连接权重 w 1 i j w_{1ij} w1ij的调整值:
∂ z j ∂ w 1 i j = ∂ z j ∂ u 1 j ∂ u 1 j ∂ w 1 i j = z j ( 1 − z j ) x i \frac{\partial z_j}{\partial w_{1ij}} = \frac{\partial z_j}{\partial u_{1j}} \frac{\partial u_{1j}}{\partial w_{1ij}} = z_j ( 1- z_j) x_i ∂w1ij∂zj=∂u1j∂zj∂w1ij∂u1j=zj(1−zj)xi Δ w 1 i j = η ∑ k = 1 q [ ( r k − y k ) y k ( 1 − y k ) w 2 j k ] z j ( 1 − z j ) x i \Delta w_{1ij} = \eta \sum_{k=1}^q [ (r_k – y_k) y_k ( 1- y_k) w_{2jk} ] z_j (1-z_j) x_i Δw1ij=ηk=1∑q[(rk−yk)yk(1−yk)w2jk]zj(1−zj)xi
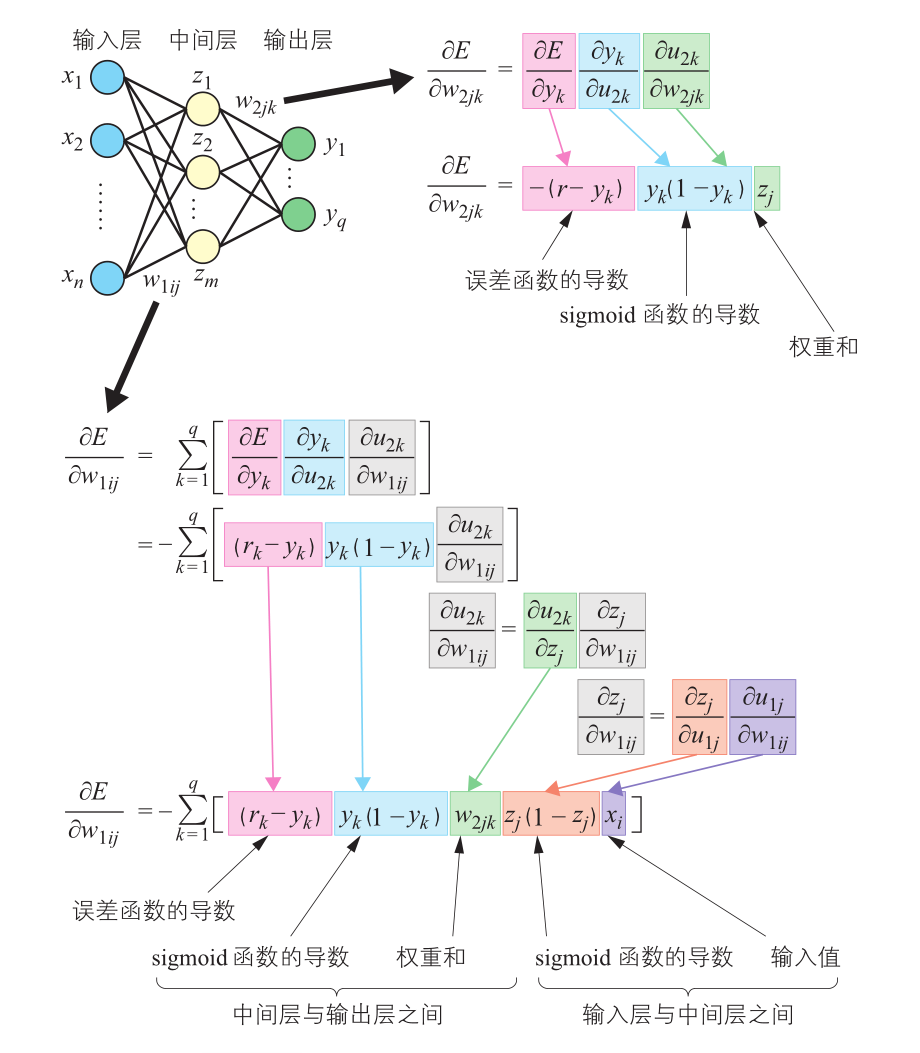
具体推导过程可以参考下列公式
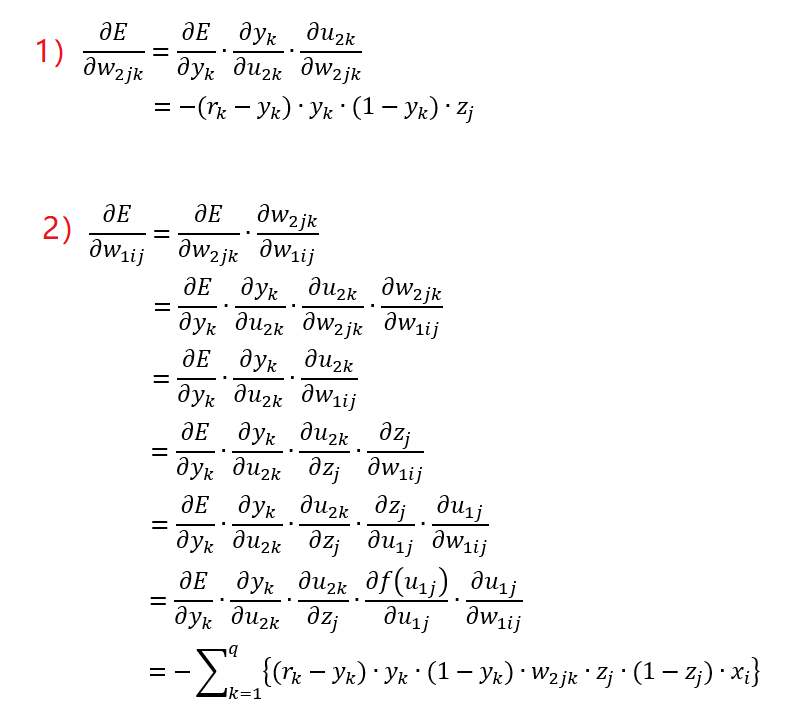
在此需要注意 z j = f ( u j ) z_j=f(u_j) zj=f(uj),输入层与中间层之间的权重调整值是相关单元在中间层与输出层之间的权重调整值的总和。
4)小结
至此,误差反向传播算法的讲解就全部结束了,其中包含了大量的公式,理解起来可能会有一些难度,但是这是必过的槛。如果实在不理解过程的话,只记住最后那张图也可以,那张图便是整个算法的精髓所在。除此之外,在实际应用过程中可能还会遇到一个问题,那就是激活函数使用 S i g m o i d Sigmoid Sigmoid或者 t a n h tanh tanh函数的时候,如果 x x x趋向正负无穷的时候,会出现偏导数为零的情况,见下图,左侧为 S i g m o i d Sigmoid Sigmoid函数图像,右侧为其导函数的图像。这时候,由于权重调整值趋近于0,所以无法调整连接权重,权重所在的单元也就不再起作用。
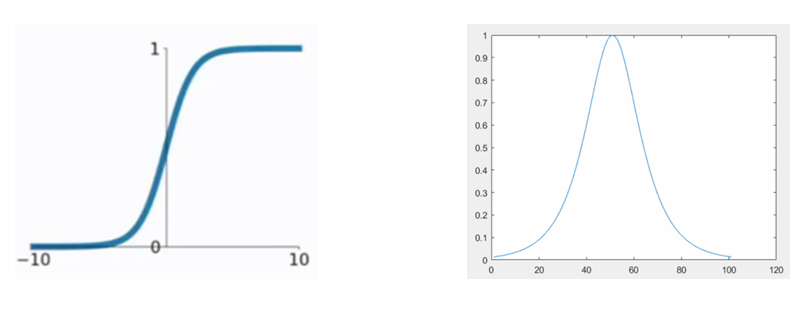
这就是误差反向传播算法中的梯度消失导致无法调整连接权重的问题,对于这个问题,需要在训练的过程中合理地调整学习率 η \eta η,以防止梯度消失。

发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/132882.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
