大家好,又见面了,我是你们的朋友全栈君。
前言
本课程来自深度之眼deepshare.net,部分截图来自课程视频。
文章标题:A Convolutional Neural Network For Modelling Sentences
原标题翻译:一种用于句子建模的卷积神经网络
作者:Nal Kalchbrenner等
单位:University of Oxford
发表会议及时间:ACL2014
在线LaTeX公式编辑器
动态卷积网络DCNN和n-gram思想用于句分类
第一课 论文导读
a. 序列问题
自然语言处理的输入输出基本上都是序列,序列问题是自然语言处理最本质的问题,形形色色的自然语言处理应用都需要用到句子的语义。如何去从句子中提取特征,抽取语义,是一个非常重要的问题。我们需要掌握基本的句子建模的抽取方法。
b. 表征的意义
表征是信息处理非常重要的问题,我们经常会听到各种各样的表征,都会觉得和当前的任务的关系不大,但其实几乎所有的任务,都是不断地寻求一个最佳的表征,明确了表征的目的意义之后,在处理问题的时候,我们将有一个基本的方向。
c. 词表征
如果说自然语言处理问题中,几乎所有的问题都是序列问题,那么最细粒度的表征就是词表征,因为这些序列都由有词构成的,词表征是自然语言处理必要的基本功,解决任何有关的问题都必须要了解的知识点。
句子建模简介
| 语音 | 图像 | 文字 |
|---|---|---|
  |
 |
 |
表征represent的目的:既能够表示原有文字的独一无二性,又能表示文字与文字之间的联系
Aim:represent the semantic content of a sentence.
Problem:individual sentences are rarely observed,let’s start from word.
词表征Word Representation
Problem with words as discrete symbols
Example: in web search, if user searches for “Seattle motel”, we would like to match documents containing “Seattle hotel”
But:
motel=[0 0 0 0 0 0 0 1 0 0 0 0]
hotel=[0 1 0 0 0 0 0 0 0 0 0 0]
These two vectors are orthogonal.
There is no natural notion of similarity for one-hot vectors!
解决方法:
基于分布式相似性的表征Distributional Similarity based representations
Distributional semantics:A word’s meaning is given by the words that frequently appear close-by
When a word w appears in a text, its context is the set of words that appear nearby(within a fixed-size windows)
Use the many contexts of w to build up a representation of w

How to make neighbors represent words?
Answer:With a cooccurrence matrix X
Window based co-occurrence matrix
·Window around each word captures both syntactic(POS) and semantic information
·Window length 1(more common:5-10)
·Symmetric(irrelevant whether left or right context)
基于窗口的共现矩阵Window based co-occurrence matrix
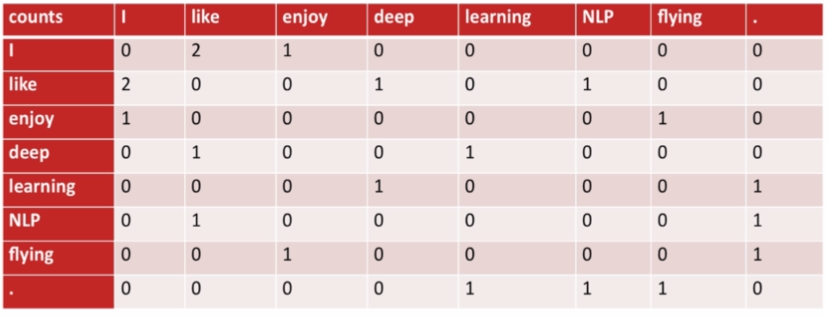
Example corpus:
·I like deep learning.
·I like NLP.
·I enjoy flying.
窗口大小为1的时候共现矩阵为:
简单共现向量的问题Problems with simple cooccurrence vectors
不能处理没有出现过的单词
·Increase in size with vocabulary
·Very high dimensional:require a lot of storage
·Subsequent classification models have sparse issues
·Models are less robust
通过上面的讨论我们发现没有用这么高的维度来表示词向量
低维向量的解决方案Solution:Low dimensional vectors
·Idea:store “most” of the important information in a fixed, small number of dimensions: a dense vector
·Usually around 25-1000 dimensions
·How to reduce the dimensionality
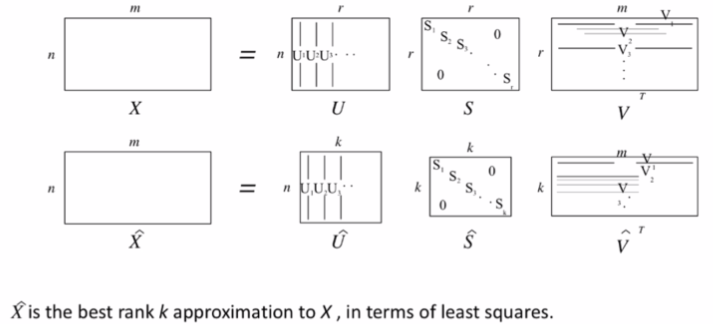
方法1:在共现矩阵X上降维
奇异值分解(SVD),把稀疏矩阵进行分解,提取出有用的部分,从而使得维度的降低。
Single Value Decomposition of cooccurrence matrix X.
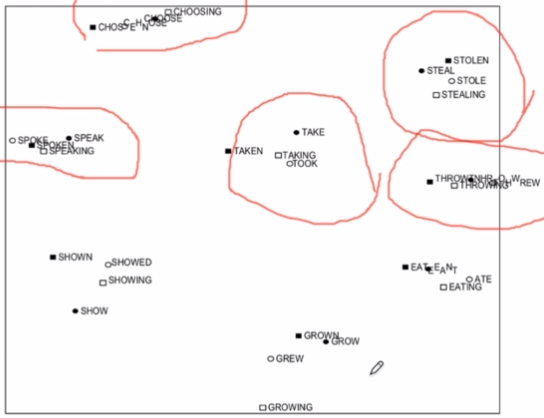
下面看两个例子(An Improved Model of Semantic Similarity Based on Lexical Co-Occurrence Rohde et al.2005):
下图中同一个词,不同语态下的不同表示能够聚集在一起。
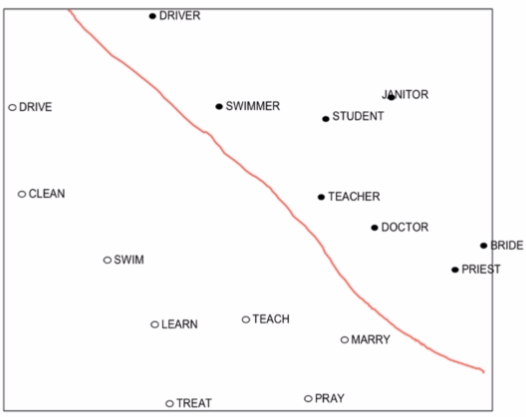
下面的例子红线下方是动词,上方是名词。
SVD问题:
主要是计算复杂度上,SVD的复杂度为n的平方。
·Computational cost scales quadratically for n matrix:O(mn2) flops (when n<m).
·Bad for millions of words or documents.
·Hard to incorporate new words or documents.
Solution:Directly learn low-dimensional word vectors.
·Instead of capturing co-occurrence counts directly.
·Predict surrounding words of every word.
·Faster and can easily incorporate a new sentence/document or add a word to the vocabulary.
方法2:直接学习低维向量
实际上就是之前学习过的文章Word2Vec
Word2Vec Overview:
Predict surrounding words


t这个词对m窗口大小的词都有不同预测的概率,然后把所有预测词的概率累乘起来。然后每个位置的预测概率再累乘起来。
·Predict surrounding words in a window of length m of every word.
·Objective function: Maximize the log probability of any context word given the current center word.
·Likelihood= L ( θ ) = ∏ t = 1 T ∏ − m ≤ j ≤ m j / = 0 P ( w t + j ∣ w t ; θ ) L(\theta)=\prod_{t=1}^T\prod_{\underset{j/=0}{-m≤j≤m}}P(w_{t+j}|w_t;\theta) L(θ)=∏t=1T∏j/=0−m≤j≤mP(wt+j∣wt;θ)
·objective function J ( θ ) = − 1 T ∑ t = 1 T ∑ − m ≤ j ≤ m j / = 0 l o g P ( w t + j ∣ w t ) J(\theta)=-\frac{1}{T}\sum_{t=1}^T\sum_{\underset{j/=0}{-m≤j≤m}}logP(w_{t+j}|w_t) J(θ)=−T1∑t=1T∑j/=0−m≤j≤mlogP(wt+j∣wt)
· θ \theta θ represents all variables we optimize.
These representations are very good at encoding dimensions of similarity!
- Analogies testing dimensions of similarity can be solved quite well just by doing vector subtraction in the embedding space (Semantically)语义相似性表达不错。
· Xshirt-Xclothing ≈ Xchair -Xfurniture
· Xking-Xman ≈ Xqueen-Xwoman - Similarly for verb and adjective morphological forms (Syntactically)词的不同词性上也有很好的表达。
· Xapple-Xapples ≈ Xcar-Xcars ≈ Xfamily-Xfamilies
词的表征就学到这里,接下来看看在词表征的基础上句子的建模如何做。
从词向量到句子建模
前期知识储备
CNN:了解卷积神经网络(CNN)的结构,掌握CNN的基本工作原理
word2vec:了解word2vec的动机,具体算法,实现细节(大厂面试几乎必问)
句子建模:了解句子建模的意义与应用
线性代数:熟练推导出SVD正交分解,并阐述其几何意义
第二课 论文精读
论文整体框架
■Abstract:采用什么方法,取得了什么结果
■Introduction:是摘要的扩展补充,之前解决相同方法是怎么做的,之前的方法的发展脉络是怎么样的。对应的优缺点。
■Background:本文采用的方法,有什么缺点
■Model
Convolutional Neural Networks with Dynamic k-Max Pooling
■Analysis
Properties of the Sentence Model
■Experiments:模型训练的细节
■Conclusion:本方法的优点,工作,未来的展望。
1.快速了解文章大意
·Abstract
2.复现论文
·Model
·Experiments
3.分析
·Analysis
4.背景学习
·Introduction
·Background
经典算法模型
神经句子模型Neural Sentence Models
·bag-of-words I bag-of-n-grams
·Time-delay Neural Networks:时间延迟网络
·Recurrent Neural Networks:RNN
·Recursive neural networks:递归神经网络
下面根据一个例子,逐个模型进行讲解:
词袋模型
先用word2vec或者其他方法把词转换成向量表征(通过lookup进行查找)
然后把这些词表征简单相加起来,在加上偏置bias得到一个得分scores
然后再用softmax函数进行分类
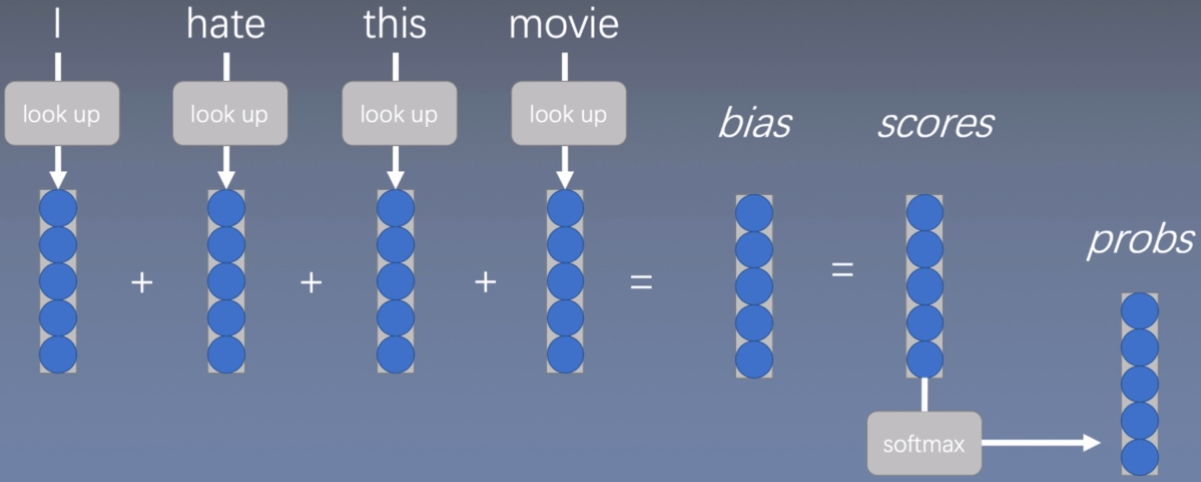
这个模型虽然能够体现出词在句子中的重要性,但是忽略了词与词之间的相互关系。然后对这个模型进行了改进得到:
连续词袋模型
就是在单词向量相加之后,再做一个线性变换,进一步增大模型容量,使得模型更加复杂,更好的拟合这些数据。但是只加上线性变换并不能完全(从根本上)脱离之前词袋模型的缺点。
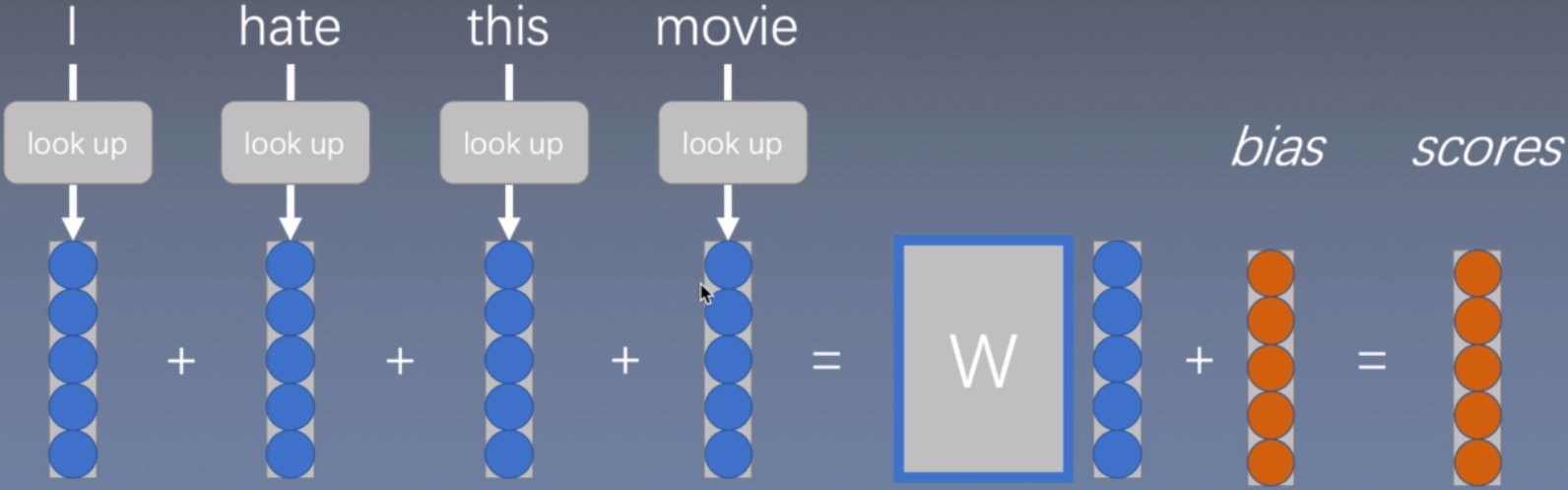
进一步改进:
深度的连续词袋模型
把得到的词向量表征输入到tanh函数中,再输入到tanh函数中,再丢到线性函数中完成拟合。
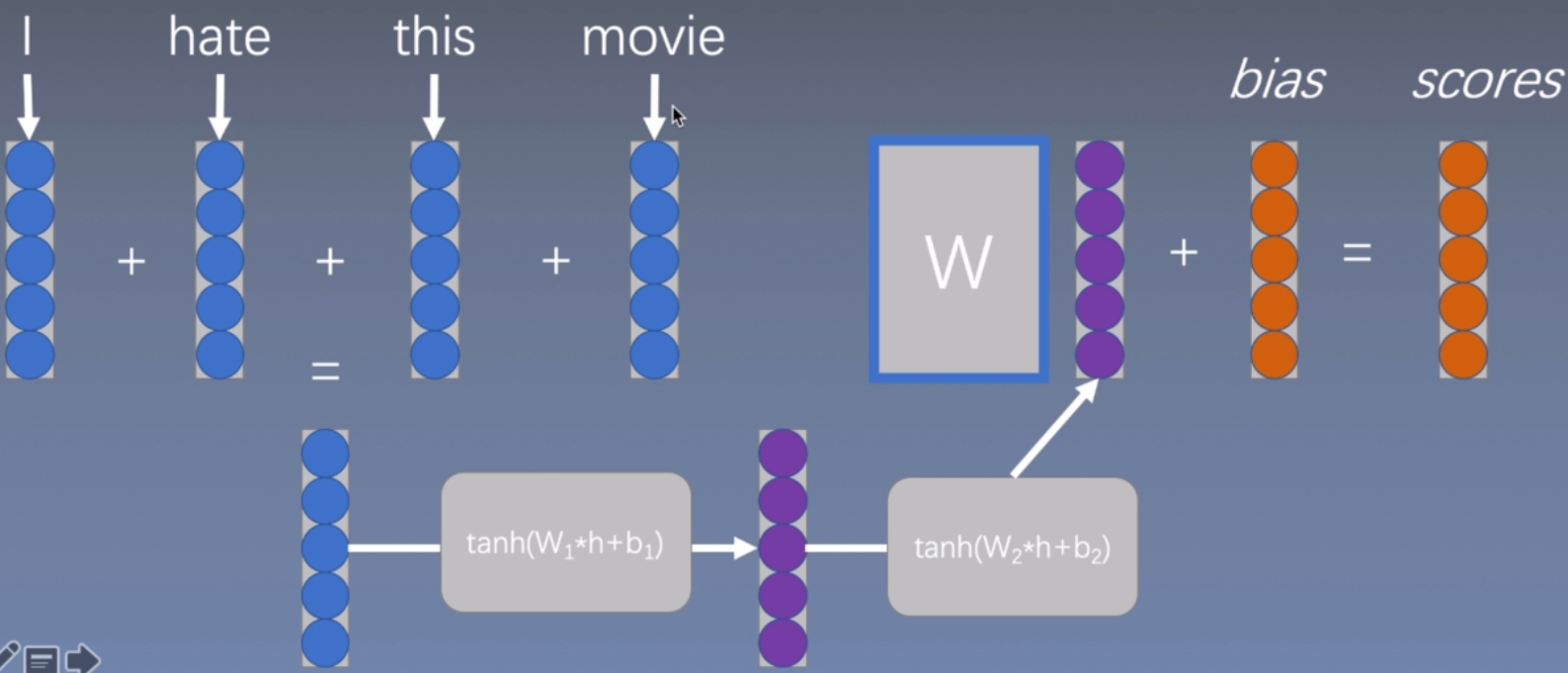
但是仍然没有考虑词组搭配之类的影响。
what do the vectors represent?
· feature combinations(a node in the second layer might be “feature 1 AND feature 5 are active”)
·e.g. capture things such as “not”AND “hate”
· BUT! Cannot handle “not hate”
为了解决上面的问题,提出了:
n-grams词袋模型
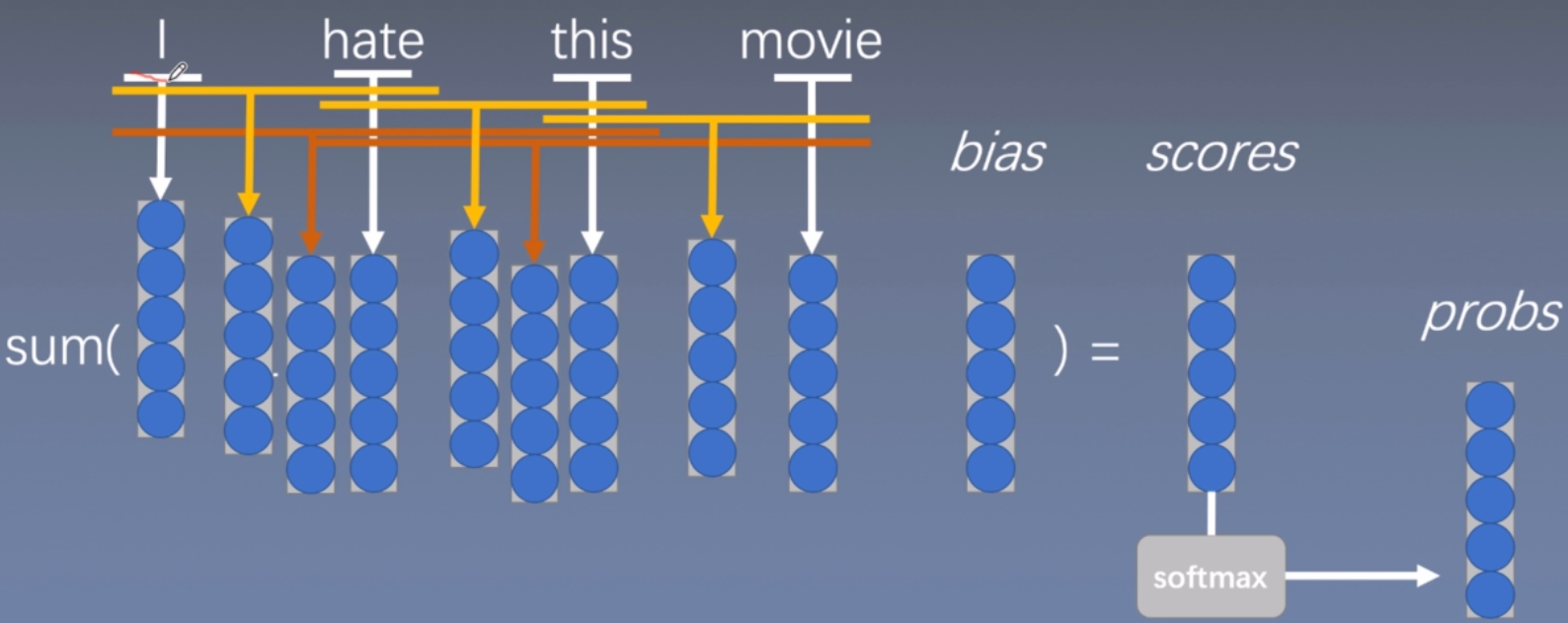
上图中的黄色和深黄色分布显示了n=2和n=3的模型。
Why bag of n-grams?
·allow us to capture combination features in a simple way “don’t love”,“not the best”
·works pretty well
What problems with bag of n-grams?
·parameter explosion
·No sharing between similar words/n-grams
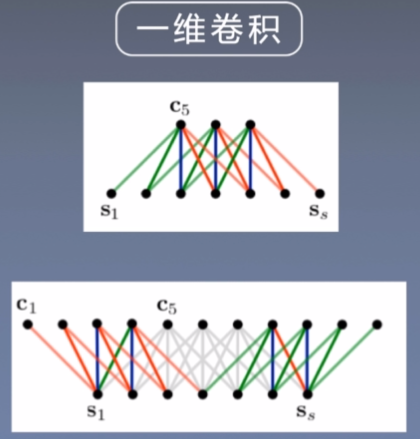
1维卷积/时间延迟网络
可以看到,使用下面的卷积方式进行扫描,一次2个词向量,和上面的n=2是一样效果,但是和上面不一样的是,这个是卷积操作,意味着这里是可以共享参数的。
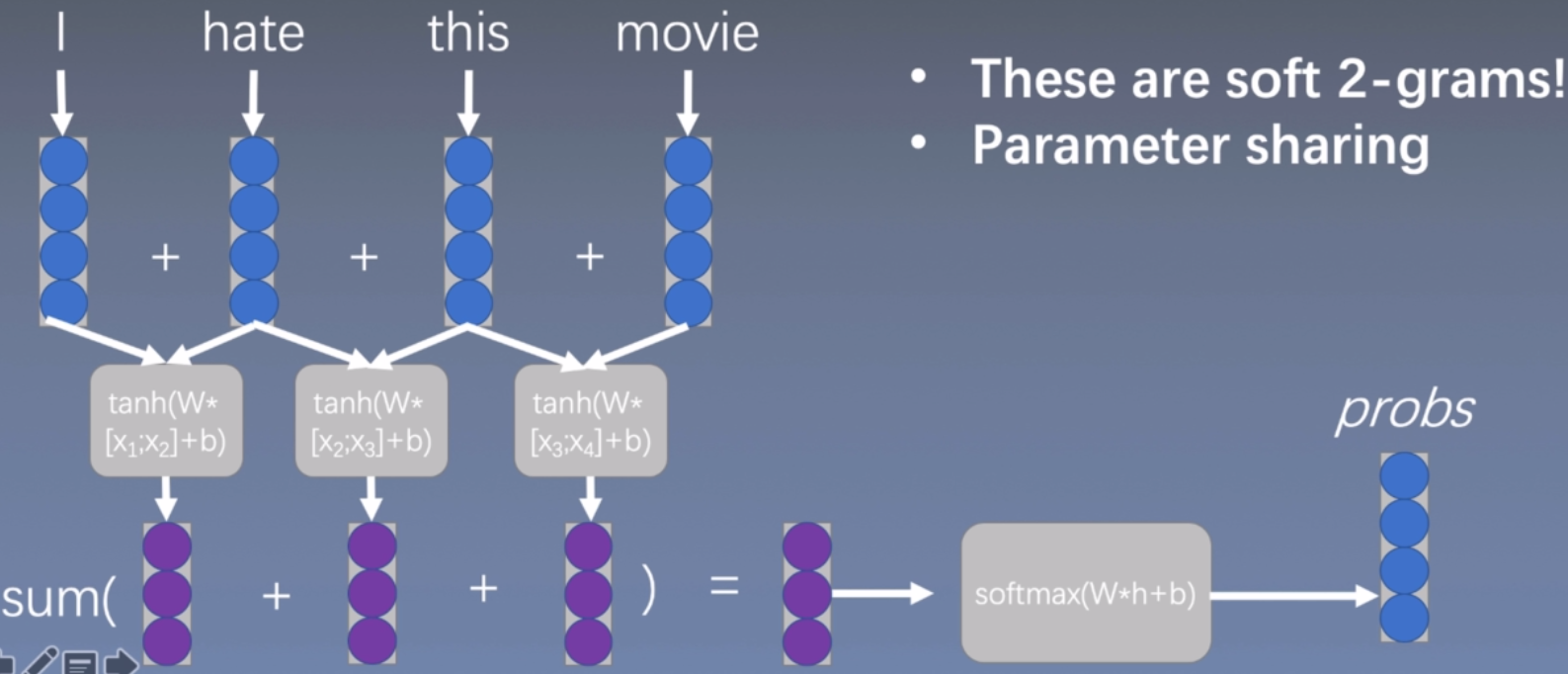
小结:(挺重要)
Generally based on 1D convolutions
but often uses terminology/functions borrowed from computer vision for historical reasons
Two main paradigms
(基于上下文窗口的建模)context window modeling: for tagging, etc. get the surrounding context before tagging
(基于句子的建模)sentence modeling: do convolution to extract n-grams, pooling to combine over whole sentence
循环神经网络
output the result from the last hidden state bias to the last hidden state
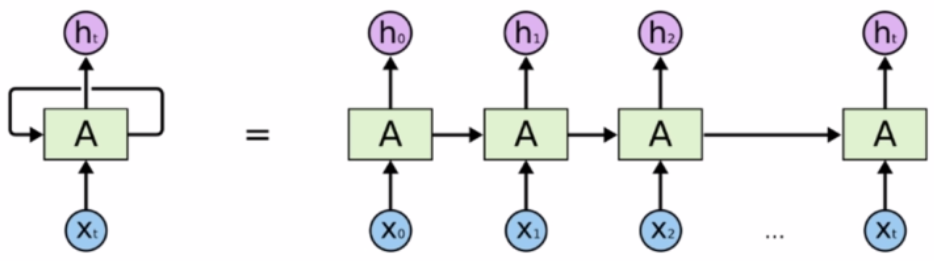
这个方式对于最后一个词是有偏置的(也就是最后一个词权重要大些)
递归神经张量网络Recursive Neural Tensor Networks
和RNN一样,这个方式对于最后一个词是有偏置的(也就是最后一个词权重要大些)
·Extended the previous state-of-the-art in sentiment analysis by a large margin.
·Best performing out of a family of recursive networks(Recursive Autoencoders,Socher et al,2011;Matrix-Vector Recursive Neural Networks,Socher et al.,2012).
·Composition function is expressed as atensor-each slice of the tensor encodes different composition.
·Can discern negation at different scopes.
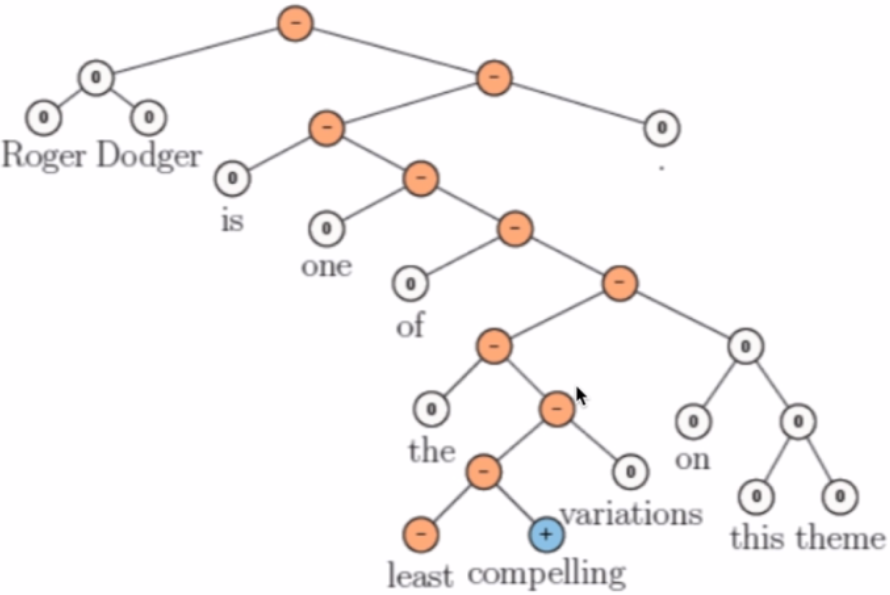
上图来自:Socher et al,“Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank”,EMNLP 2013
缺点:
· Need parse trees to be computed beforehand.
· Phrase-level classification is expensive to obtain.
· Hard to adopt to other domains(e.g. Twitter).
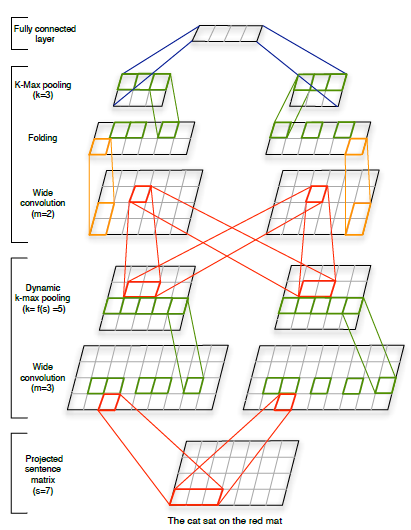
论文提出的模型
最下面是一个句子,然后根据每一个词的向量表征投射成为一个矩阵
一维卷积
c j = m T s j − m + 1 : j c_j=m^Ts_{j-m+1:j} cj=mTsj−m+1:j
· m ∈ ℜ m m\in \real^m m∈ℜm convolutional filter,m是卷积核
· s ∈ ℜ n s\in \real^n s∈ℜn sequence of length n,s是长度为n的序列
· s i ∈ ℜ s_i\in \real si∈ℜ single feature value of i-th word in sequence s
Narrow Convolution: c l e n g t h = s l e n g t h − m l e n g t h + 1 c_{length}=s_{length}-m_{length}+1 clength=slength−mlength+1,其实就是普通卷积计算
Wide Convolution: c l e n g t h = s l e n g t h + m l e n g t h − 1 c_{length}=s_{length}+m_{length}-1 clength=slength+mlength−1
用文章中的例子来看,s是有7个单词,所以 s l e n g t h = 7 s_{length}=7 slength=7,使用的卷积核大小都是5
宽卷积增强了输入的边界部分。
最大时间延迟网络
句子的矩阵是由若干个词嵌入组成,大小是d×s,d是词向量大小,s是句子中词的个数。然后用m-gram大小的卷积核进行特征提取(第一个箭头),虽然句子的长度是不一样的,但是在max pooling阶段直接取句子中最重要的特征,解决了长度不一样的问题。
w i ∈ ℜ d w_i\in \real^d wi∈ℜdvector of d
c i ∈ ℜ d c_i\in\real^d ci∈ℜd vector of d
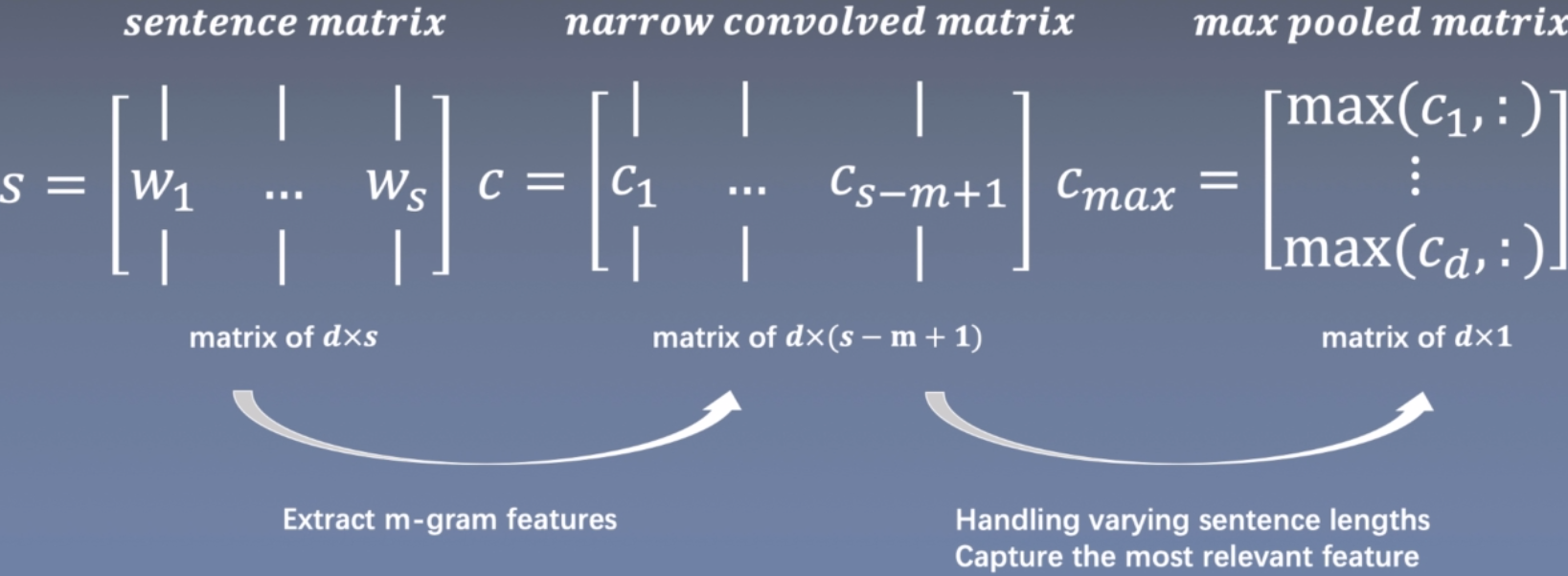
Advantages
·Sensitive to the order of the words
·Not depend on external language-specific features such as dependency or constituency parse trees
·Give largely uniform importance to the signal coming from each words in the sentence(except words at the margin)
Disadvantages
Convolution
·Range of feature limited to the span of the weights
·Increasing m will make detector larger but exacerbate the neglect of the margins
·Minimum sizes
Max pooling
·Cannot distinguish whether a relevant feature in one of the rows occurs just one time or more
·Forget the order in which the features occur
宽卷积
reach the entire sentence! (including the words at the margins)
普通(窄)卷积后维度一般是会变小的,这个的nlp上没法玩,句子本来就短,宽卷积则是会变大
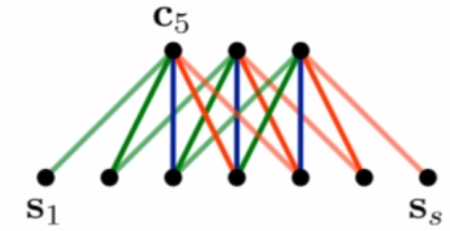
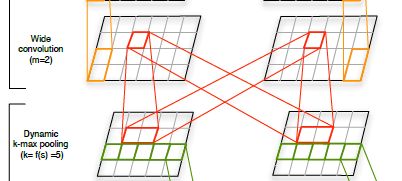
K-最大池化
取k个最大值,而且保持抽取这些值的顺序,这样就会解决之前只抽取最大值会忽略句子中词与词的关系(只有一个特征有什么相互关系),另外保持顺序也解决了最大延时网络中的max pooling不能保存语序的缺点。
·Given a value k Sequence p ∈ ℜ p p\in\real^p p∈ℜp Length p≥k
·Select thesubsequence p m a x k p_{max}^k pmaxk of the k highest values of p
·Keep the original order
·After the topmost convolutional layer
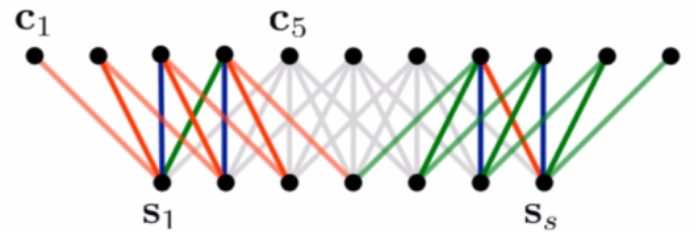
文章中还有一种方法叫:Dynamic k-max pooling,这个方法中k的值是可以变化的,不是固定不变的。
动态k-最大池化
k l = m a x ( k t o p , ⌈ L − l L s ⌉ ) k_l=max(k_{top},\left \lceil \frac{L-l}{L}s \right \rceil) kl=max(ktop,⌈LL−ls⌉)
· l l l is the number of the current convolutional layer
·L is the total number of convolutional layers in the network
· k t o p k_{top} ktop is the fixed topmost pooling parameter e.g.
a network with 3 convolutional layers and k t o p k_{top} ktop =3, length s=18
the pooling parameter in the first layer k 1 k_{1} k1=12
the pooling parameter in the second layer k 2 k_{2} k2=6
the pooling parameter in the third layer k 3 k_{3} k3= k t o p k_{top} ktop =3
Detect the l t h l_{th} lth order feature occurring at most k l k_{l} kl times
非线性的特征函数
M = [ d i a g ( m : , 1 ) , . . . d i a g ( m : , m ) ] M=[diag(m_{:,1}),…diag(m_{:,m})] M=[diag(m:,1),...diag(m:,m)]
a = g ( M [ w j ⋮ w j + m − 1 ] + b ) a=g(M \begin{bmatrix} w_j\\ \vdots \\ w_{j+m-1} \end{bmatrix}+b) a=g(M⎣⎢⎡wj⋮wj+m−1⎦⎥⎤+b)
思考:为什么M是对角矩阵。
多个特征图
Convolve multiple feature maps into next layer and form higher order feature.
就是下图中的部分:
F j i + 1 = ∑ k = 1 n m j , k i + 1 ∗ F k i F_j^{i+1}=\sum_{k=1}^nm_{j,k}^{i+1}*F_k^i Fji+1=k=1∑nmj,ki+1∗Fki
F j i , . . . , F n i i t h F_j^i,…,F_n^i \space i_{th} \space Fji,...,Fni ith order feature maps in the same layer
m j , k i + 1 m_{j,k}^{i+1} mj,ki+1 forms an order-4 tensor
m的4阶张量是哪4阶?
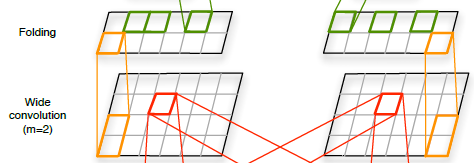
折叠Folding
·individual row can have many orders
·Different rows are independent of each other
·Sum every two rows in a feature map component-wise
橙色部分,可以减少参数。
分析(单词顺序)
·Sensitive to the order of the words in the input sentence
·Discriminate whether a specific n-gram occurs in the input(wide convolution)
·Tell the relative position of the most relevant n-grams(dynamic k-max pooling)
·NBoW models insensitive to word order
RNN sensitive to word order while it has a bias towards the latest words it inputs
·Recursive Neural Networks sensitive to word order but has a bias toward the topmost nodes in the tree
·Max-TDNN sensitive to word order but max pooling only picks single n-gram feature in each row of the sentence matrix
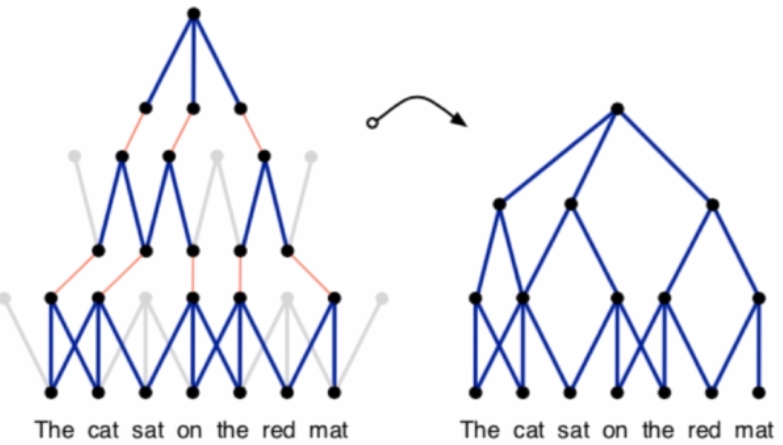
分析(结构)
·DCNN induces an internal complex feature graph over the input
·NBoW is a shallow model
·RNN has a linear chain structure
·Max-TDNN induces a single fixed-range feature subgraphs
·Recursive Neural Networks follows the structure of an external parse tree(clear hierarchy of feature orders)
实验和结果
实验
1.Sentiment Prediction in Movie Reviews
2.Question Type Classification
3.Twitter Sentiment Prediction with Distant Supervision
影评中的情感预测
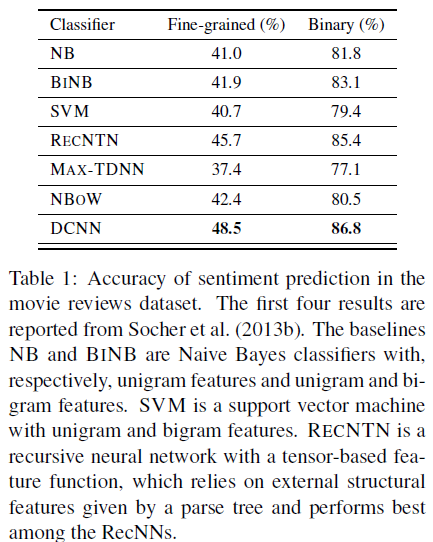
·Binary
·Positive
·Negative
·Fine-grained
·Positive
·Somewhat positive
·Neutral
·Somewhat negative
·negative
问题类型的分类

·Six question types
·Position
·Person
·Numeric information
…
通过远程监督的Twitter情感预测
·Binary
·Automatically labelled as positive or negative depending on the emoticon
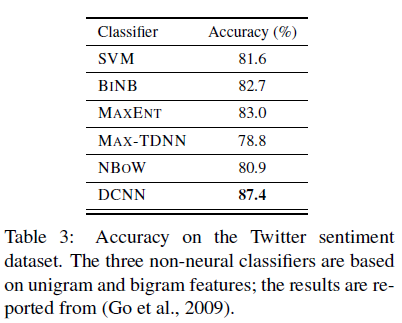
特征检测器的可视化

讨论和总结
问题
如何增大特征检测的扫描范围:Wide convolution
如何捕捉到句子更复杂的特征关系:Dynamic k-max pooling
如何捕捉到不同维度特征的关系:folding
创新点:
A新的句子模型:动态的卷积网络
B在句子分类和情感分类问题效果很好
C不需要额外的特征,解析树
参考文献
主要参考了cs224n课程的lecture11.
[1]http://web.stanford.edu/class/cs224n/slides/cs224n-2019-lecture11-convnets.pdf
文章动机什么的看这个:
[2]http://phontron.com/class/nn4nlp2019/assets/slides/nn4nlp-04-cnn.pdf
[3]https://wwww.slideshare.net/ANISHBHANUSHALl1/cnn-for-modeling-sentence
[4]http://www.people.fas.harvard.edu/-yoonkim/data/sent-cnn-slides.pdf
作业:
- 回答下列问题:
a. 文章中的公式5是什么意思,为什么用对角阵拼接,写出公式推导步骤?
b. 为什么说将公式5中的矩阵补全,就可以卷积考虑到不同的维度的关系?
c. 如果这里用到了residual connection,该怎么使用,具体的公式怎么改? - 关闭一切资源,从0开始写出Dynamic CNN网络。
复现(略)
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/132876.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
