大家好,又见面了,我是你们的朋友全栈君。
自连接查询
假想以下场景:某一电商网站想要对站内产品做层级分类,一个类别下面有若干子类,子类下面也会有别的子类。例如数码产品这个类别下面有笔记本,台式机,智能手机等;笔记本,台式机,智能手机又可以按照品牌分类;品牌又可以按照价格分类,等等。也许这些分类会达到一个很深的层次,呈现一种树状的结构。那么这些数据要怎么在数据库中表示呢?我们可以在数据库中创建两个字段来存储id和类别名称,使用第三个字段存储类别的子类或者父类的id,最后通过自连接去查询想要的结果。
自连接查询其实等同于连接查询,需要两张表,只不过它的左表(父表)和右表(子表)都是自己。做自连接查询的时候,是自己和自己连接,分别给父表和子表取两个不同的别名,然后附上连接条件。看下面的例子:
1. 创建数据表:
create table tdb_cates(
id smallint primary key auto_increment,
cate_name varchar(20) not null,
parent_id smallint not null
);
注:cate_name表示分类的名称,parent_id表示父类的id。
2. 插入数据:
insert into tdb_cates(cate_name, parent_id) values('数码产品', 0);
insert into tdb_cates(cate_name, parent_id) values('家用产品', 0);
insert into tdb_cates(cate_name, parent_id) values('笔记本', 1);
insert into tdb_cates(cate_name, parent_id) values('智能手机', 1);
insert into tdb_cates(cate_name, parent_id) values('电器', 2);
insert into tdb_cates(cate_name, parent_id) values('家具', 2);
insert into tdb_cates(cate_name, parent_id) values('冰箱', 5);
insert into tdb_cates(cate_name, parent_id) values('洗衣机', 5);
insert into tdb_cates(cate_name, parent_id) values('汽车品牌', 0);
insert into tdb_cates(cate_name, parent_id) values('别克', 9);
insert into tdb_cates(cate_name, parent_id) values('宝马', 9);
insert into tdb_cates(cate_name, parent_id) values('雪佛兰', 9);
insert into tdb_cates(cate_name, parent_id) values('家纺', 0);查询结果:
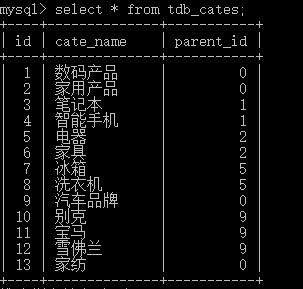

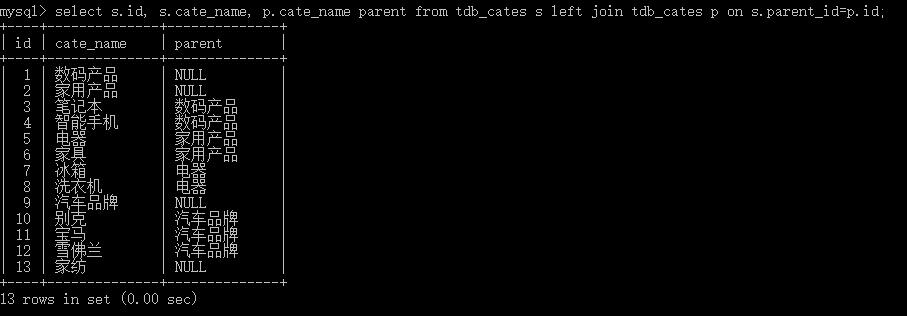
3. 查询所有分类以及分类的父类:假想有左右两张表(都是tdb_cates),左表是子表,右表是父表;查询子表的id,子表的cate_name,父表的cate_name;连接条件是子表的parent_id等于父表的id。
select s.id, s.cate_name, p.cate_name from tdb_cates s left join tdb_cates p on s.parent_id=p.id;查询结果:
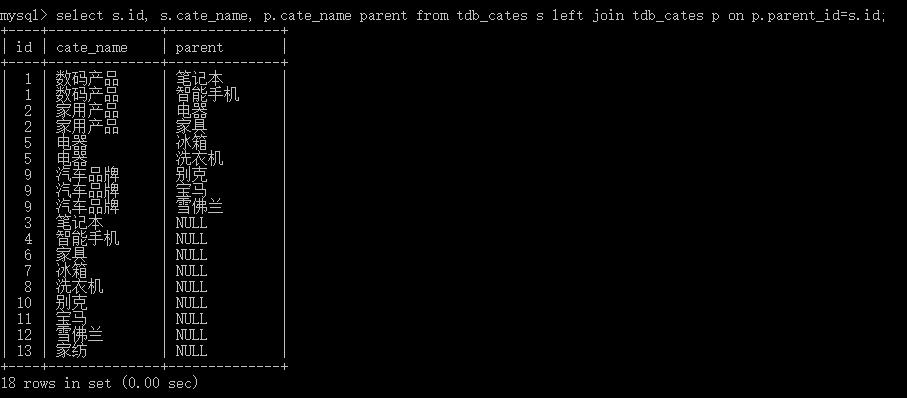
4. 查询所有分类以及分类的子类:还是假想有左右两张表(都是tdb_cates),左表是子表,右表是父表;查询子表的id,子表的cate_name,父表的cate_name;连接条件是子表的id等于父表的parent_id。
select s.id, s.cate_name, p.cate_name from tdb_cates s left join tdb_cates p on p.parent_id=s.id;查询结果:
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/132874.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
