大家好,又见面了,我是你们的朋友全栈君。
1.初识Auto Encoder
1986 年Rumelhart 提出自动编码器的概念,并将其用于高维复杂数据处理,促进了神经网络的发展。自编码神经网络是一种无监督学习算法,它使用了反向传播算法,并让目标值等于输入值,比如y(i)=x(i) 。下图是一个自编码神经网络的示例。

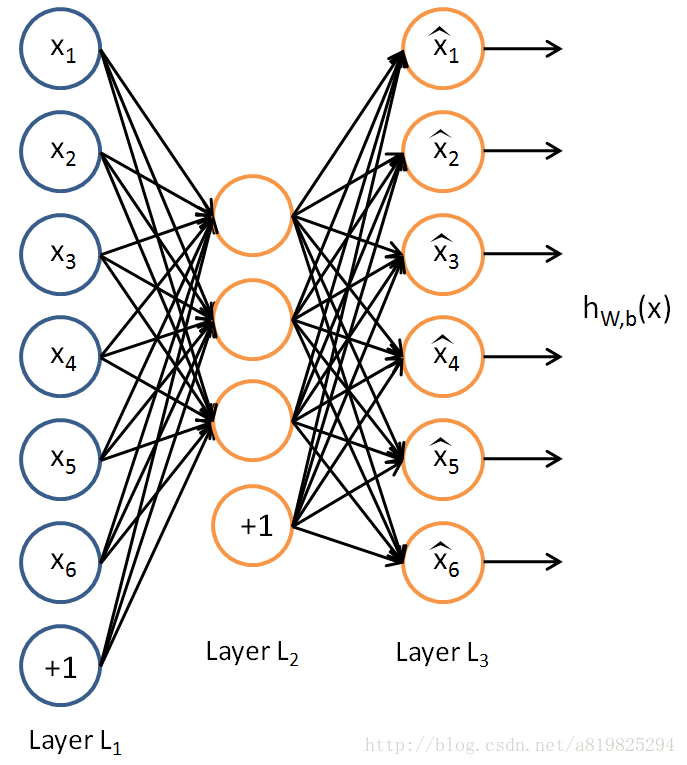
自动编码器(autoencoder) 是神经网络的一种,该网络可以看作由两部分组成:一个编码器函数h = f(x) 和一个生成重构的解码器r = g(h)。传统上,自动编码器被用于降维或特征学习。
自编码神经网络尝试学习的一个函数为:
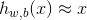
换句话说,它尝试逼近一个恒等函数,从而使得输出x(2)接近于输入x(1) 。恒等函数虽然看上去不太有学习的意义,但是当我们为自编码神经网络加入某些限制,比如限定隐藏神经元的数量,我们就可以从输入数据中发现一些有趣的结构。
举例来说,假设某个自编码神经网络的输入x 是一张 10×10图像(共100个像素)的像素灰度值,于是 n=100 ,其隐藏层L2中有50个隐藏神经元。
注意,输出也是100维。由于只有50个隐藏神经元,我们迫使自编码神经网络去学习输入数据的压缩表示,也就是说,它必须从50维的隐藏神经元激活度向量a(2)中重构出100维的像素灰度值输入x 。
一些需要注意的问题:
如果网络的输入数据是完全随机的,比如每一个输入都是一个跟其它特征完全无关的独立同分布高斯随机变量,那么这一压缩表示将会非常难学习。但是如果输入数据中隐含着一些特定的结构,比如某些输入特征是彼此相关的,那么这一算法就可以发现输入数据中的这些相关性。事实上,这一简单的自编码神经网络通常可以学习出一个跟主元分析(PCA)结果非常相似的输入数据的低维表示。
2.Deep Auto Encoder(DAE)
2006 年,Hinton 对原型自动编码器结构进行改进,进而产生了DAE,先用无监督逐层贪心训练算法完成对隐含层的预训练,然后用BP 算法对整个神经网络进行系统性参数优化调整,显著降低了神经网络的性能指数,有效改善了BP 算法易陷入局部最小的不良状况。
简单来说,DAE相对于原始的Auto Encoder加大了深度,提高学习能力,更利于预训练。如图2所示,一个5层的DAE,隐层节点数从高到低,再从低到高,最终只需要取得L(3)的向量即可。
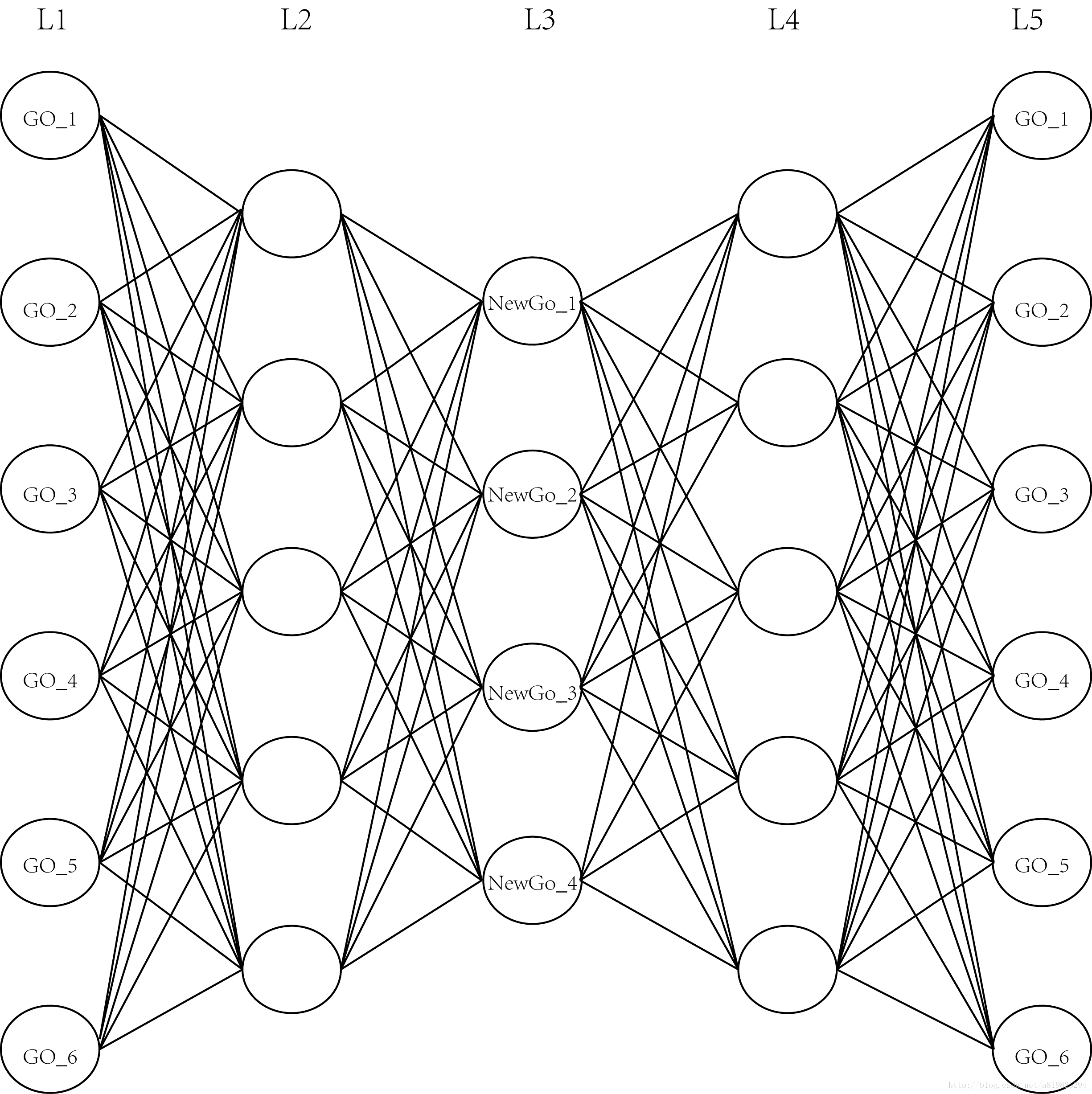
3.利用keras实现DAE
# -*- coding: utf-8 -*-
import pandas as pd
import numpy as np
from keras.layers import Dense,Activation,Input
from keras.models import Sequential,Model
import theano
#可以自行替换为自己的数据
go = pd.read_csv('./clear_data/gene_ontology.csv')
go_id = go['Gene_ID']
go = go.drop(['Gene_ID'],axis=1)
inputDims = go.values.shape[1]
EncoderDims = 100
AutoEncoder = Sequential()
AutoEncoder.add(Dense(input_dim=inputDims,output_dim=EncoderDims,activation='relu'))
AutoEncoder.add(Dense(input_dim=EncoderDims,output_dim=inputDims,activation='sigmoid'))
AutoEncoder.compile(optimizer='adadelta',loss='binary_crossentropy')
AutoEncoder.fit(go.values,go.values,batch_size=32,nb_epoch=50,shuffle=True) #,validation_data4.取DAE隐层向量
get_feature = theano.function([AutoEncoder.layers[0].input],AutoEncoder.layers[0].output,allow_input_downcast=False)
new_go = get_feature(go)参考文献:
(1)Rumelhart DE,Hinton GE,Williams RJ. Learning representations by back-propagating errors[J]. Nature,1986,323: 533-536.
(2)Hinton GE,Osinder S,Teh Y W. A fast learning algorithm for deep belief nets[J].Neural Computation,2006,18( 7) : 1527-1554.
(3)http://deeplearning.stanford.edu/wiki/index.php/Autoencoders_and_Sparsity
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/132861.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
