大家好,又见面了,我是你们的朋友全栈君。
目录
文章目录
背景
我们处在技术快速发展的时代,竞争变得前所未有的激烈,不仅要十八般武艺俱全,还得选对正确的技术,跟上发展的脚步,并贴上精研某个专业方向的标签。我们不仅要面对多线程和并发,还要考虑多核时代的并行计算,无锁编程或许是一种选择,可能会提升性能,也可能避免锁的使用引起的错误,同时会带来编程习惯的变革。
不可否认,无锁技术是目前各种并发解决方案中比较受争议的一种,尽管它基于最基本的编程技术,不依赖于任何语言和平台,但是这项技术有些诡异,掌握起来颇有难度,有点曲高和寡,所以没有大面积应用在编程中。
技术本身没有对错,仁者见仁,智者见智,选择和实际match的方法,并不断的进行深入和优化。不管你是否在项目中使用无锁技术,了解和研究这项技术本身都会对理解并发编程有很大的帮助。
锁的分类
死锁、活锁
活锁、死锁本质上是一样的,原因是在获取临界区资源时,并发多个进程/线程声明资源占用(加锁)的顺序不一致,死锁是加不上就死等,活锁是加不上就放开已获得的资源重试,其实单机场景活锁不太常见。举个例子资源A和B,进程P1和P2,
start:
P1 lock A
P2 lock B
P1 lock B fail context switch
P2 lock A fail context switch
P1 release A
P2 release B
goto start
单个core时如果调度的不好还是有可能出现的,多core情况下,冲突窗口很小,很难出现两个进程的节奏碰的这么巧。
但是在分布式场景下,由于加锁失败,而要释放已获得的资源再重试,这个过程涉及网络通信,冲突窗口变大,使得活锁出现概率也变大。比如paxos的prepare和accept,两个并发提案P1和P2,P2用更大proposal id的prepare形成多数派,将使得之前已经prepare成功的P1无法accept,P1只能用更更大的proposal id重试,而使得P2又无法accept,把prepare和accept看做两个资源A和B,每个提案都是按BAB的顺序获取资源(因为prepare阶段的应答蕴含了对accept增加了限制),过程中存在BA和AB两种资源获取顺序,是典型的活锁场景
一个是mutex.lock,一个是mutex.trylock
In concurrent computing, a deadlock is a state in which each member of a group of actions, is waiting for some other member to release a lock
A livelock is similar to a deadlock, except that the states of the processes involved in the livelock constantly change with regard to one another, none progressing. Livelock is a special case of resource starvation; the general definition only states that a specific process is not progressing.
A real-world example of livelock occurs when two people meet in a narrow corridor, and each tries to be polite by moving aside to let the other pass, but they end up swaying from side to side without making any progress because they both repeatedly move the same way at the same time.
Livelock is a risk with some algorithms that detect and recover from deadlock. If more than one process takes action, the deadlock detection algorithm can be repeatedly triggered. This can be avoided by ensuring that only one process (chosen randomly or by priority) takes action.
通俗得讲,活锁应该是一系列进程在轮询地等待某个不可能为真的条件为真。活锁的时候进程是不会blocked,这会导致耗尽CPU资源,这是与死锁最明显的区别。
饥饿、饿死(starvation):
是指如果线程T1占用了资源R,线程T2又请求封锁R,于是T2等待。T3也请求资源R,当T1释放了R上的封锁后,系统首先批准了T3的请求,T2仍然等待。然后T4又请求封锁R,当T3释放了R上的封锁之后,系统又批准了T4的请求…,T2可能永远等待。
优先级反转(Priority inversion)
优先级反转是指一个低优先级的任务持有一个被高优先级任务所需要的共享资源。高优先任务由于因资源缺乏而处于受阻状态,一直等到低优先级任务释放资源为止。而低优先级获得的CPU时间少,如果此时有优先级处于两者之间的任务,并且不需要那个共享资源,则该中优先级的任务反而超过这两个任务而获得CPU时间。如果高优先级等待资源时不是阻塞等待,而是忙循环,则可能永远无法获得资源,因为此时低优先级进程无法与高优先级进程争夺CPU时间,从而无法执行,进而无法释放资源,造成的后果就是高优先级任务无法获得资源而继续推进。
解决方案:
(1)设置优先级上限,给临界区一个高优先级,进入临界区的进程都将获得这个高优先级,如果其他试图进入临界区的进程的优先级都低于这个高优先级,那么优先级反转就不会发生。
(2)优先级继承,当一个高优先级进程等待一个低优先级进程持有的资源时,低优先级进程将暂时获得高优先级进程的优先级别,在释放共享资源后,低优先级进程回到原来的优先级别。嵌入式系统VxWorks就是采用这种策略。
++这里还有一个八卦,1997年的美国的火星探测器(使用的就是vxworks)就遇到一个优先级反转问题引起的故障。简单说下,火星探测器有一个信息总线,有一个高优先级的总线任务负责总线数据的存取,访问总线都需要通过一个互斥锁(共享资源出现了);还有一个低优先级的,运行不是很频繁的气象搜集任务,它需要对总线写数据,也就同样需要访问互斥锁;最后还有一个中优先级的通信任务,它的运行时间比较长。平常这个系统运行毫无问题,但是有一天,在气象任务获得互斥锁往总线写数据的时候,一个中断发生导致通信任务被调度就绪,通信任务抢占了低优先级的气象任务,而无巧不成书的是,此时高优先级的总线任务正在等待气象任务写完数据归还互斥锁,但是由于通信任务抢占了CPU并且运行时间比较长,导致气象任务得不到CPU时间也无法释放互斥锁,本来是高优先级的总线任务也无法执行,总线任务无法及时执行的后果被探路者认为是一个严重错误,最后就是整个系统被重启。Vxworks允许优先级继承,然而遗憾的工程师们将这个选项关闭了。++
(3)第三种方法就是使用中断禁止,通过禁止中断来保护临界区,采用此种策略的系统只有两种优先级:可抢占优先级和中断禁止优先级。前者为一般进程运行时的优先级,后者为运行于临界区的优先级。火星探路者正是由于在临界区中运行的气象任务被中断发生的通信任务所抢占才导致故障,如果有临界区的禁止中断保护,此一问题也不会发生。
护航现象(Lock Convoys)
Lock Convoys是在多线程并发环境下由于锁的使用而引起的性能退化问题。
当多个相同优先级的线程频繁地争抢同一个锁时可能会引起lock convoys问题,一般而言,lock convoys并不会像deadlock或livelock那样造成应用逻辑停止不前,相反地,遭受lock convoys的系统或应用程序仍然往前运行,但是,由于线程们频繁地争抢锁而导致过多的线程环境切换,从而使得系统的运行效率大为降低,而且,若存在同等优先级下不参与锁争抢的线程,则它们可以获得相对较多的处理器资源,从而造成系统调度的不公平性。
本文将解释lockconvoys问题的缘由。
假设一组线程在频繁地获取锁(所谓频繁,指在一个时间片的执行周期内多次获取锁),比如在Windows应用程序中常常用临界区(criticalsection)来保护一个共享变量或者防止一段代码被重入,这是极有可能发生的。
假设线程A获取到了锁,这时发生了线程调度中断,它的时间片用完了,于是,系统调度器交给下一个线程执行,不妨设线程B获得了执行权。由于此锁被线程A获取,所以,当线程B执行到获取锁的操作时,虽然时间片未用完,但不得不放弃执行权。如此继续,所有同等优先级且要竞争此锁的线程都被阻塞。调度器再次回到线程A,很快地线程A释放了锁。在操作系统中,释放一个锁,意味着内核中如果有线程正在等待该锁,则它的状态就可以变成运行态。比如,线程B的获取操作成功。但此时,内核只是将线程B标记为锁的所有者,而线程A继续执行。很快地,线程A又要获取锁了,由于该锁已经被标记给线程B了,所以线程A不得不放弃时间片,将控制权交给调度器。调度器终于可以捡起线程B,将处理器的执行权交给它。等到线程B释放了锁,下一个线程获得锁的所有权,并且等到线程B放弃执行权或者结束时间片之后就有机会被执行。此过程一直持续,经过一轮之后又会回到线程A,从而继续下一轮的争抢。在此期间,这些线程总是未执行满时间片就不得不放弃执行权。下面的图说明了三个线程在争抢一个锁时候的执行情况。
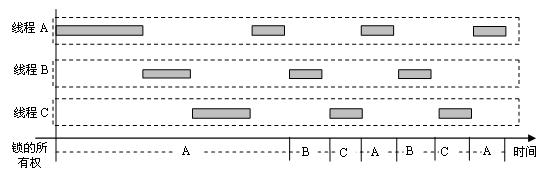
假设一个线程在一个满时间片的执行过程中要多次获取/释放锁,它一旦释放了锁,则意味着,只要存在锁竞争,它在分配给它的当前时间片内已经无法再重新获得锁了。所以,它只能执行到它的下一次获取操作为止。譬如,参与竞争的线程平均执行1/3时间片就要获取锁,那么,线程的实际执行时间变成了1/3时间片。系统的调度粒度变成原来的1/3时间间隔。这引起了3倍数量的线程切换。从上图的右半部分可以看出,每个线程在一轮的循环中,只有1/3时间片的机会。这导致了3倍的线程切换。
除了引起调度粒度变小以外,lockconvoys的另一个问题是造成调度器的时间分配不公平。假设另有一个线程X也是在同等的优先级上运行,但没有参与锁竞争。于是,在每一轮的锁竞争过程中,线程X都有机会被分配一次完整的时间片,于是,这些竞争的线程在一轮中获得1/3时间片,而非竞争的线程可以获得完整的时间片。当然,你可以说这种不公平是由于它们抢锁而引起的,但从时间分配比例而言,参与竞争与不参与竞争的线程是不公平的。下图说明了线程X和A、B、C之间的执行时间差异。


由以上描述可以看出,Lockconvoys的存在条件是,参与竞争的线程频繁地获取锁,锁被一个线程释放以后其所有权便落到了另一个线程的手里。在操作系统中,相同优先级的线程按照FIFO的顺序被调度和执行,竞争同一个锁的线程也按照FIFO的顺序被依次成功地获取到锁。这些条件在现代操作系统中都能被满足,包括Windows。
Lock convoys虽然不是致命的问题,但也可能在实际系统中发生。Sue Loh在她的博客文章中展示了在Windows CE中发生的lock convoy问题。她也讨论了一种合理的缓解lockconvoy的方案,要求在每个线程获取锁的时候先尝试(try),如果尝试多次仍不成功,再阻塞。
References:
[1] Sue Loh, Lock Convoys and How toRecognize Them,http://blogs.msdn.com/b/sloh/archive/2005/05/27/lock-convoys-and-how-to-recognize-them.aspx,2005.
[2] Lock Convoys, http://en.wikipedia.org/wiki/Lock_convoy
角色信息
- CPU的时间片(基本时间单位)
- 临界区资源(共享资源单位)
- 调度单位
自旋锁
自旋锁是一种非阻塞锁,也就是说,如果某线程需要获取自旋锁,但该锁已经被其他线程占用时,该线程不会被挂起,而是在不断的消耗CPU的时间,不停的试图获取自旋锁。互斥量是阻塞锁,当某线程无法获取互斥量时,该线程会被直接挂起,该线程不再消耗CPU时间,当其他线程释放互斥量后,操作系统会激活那个被挂起的线程,让其投入运行。
两种锁适用于不同场景:
如果是多核处理器,如果预计线程等待锁的时间很短,短到比线程两次上下文切换时间要少的情况下,使用自旋锁是划算的。如果是多核处理器,如果预计线程等待锁的时间较长,至少比两次线程上下文切换的时间要长,建议使用互斥量。如果是单核处理器,一般建议不要使用自旋锁。因为,在同一时间只有一个线程是处在运行状态,那如果运行线程发现无法获取锁,只能等待解锁,但因为自身不挂起,所以那个获取到锁的线程没有办法进入运行状态,只能等到运行线程把操作系统分给它的时间片用完,才能有机会被调度。这种情况下使用自旋锁的代价很高。如果加锁的代码经常被调用,但竞争情况很少发生时,应该优先考虑使用自旋锁,自旋锁的开销比较小,互斥量的开销较大。
pthread与tbb中各种锁的对比测试
pthread中提供的锁有:
pthread_mutex_t, pthread_spinlock_t, pthread_rwlock_t。
pthread_mutex_t :
是互斥锁,同一瞬间只能有一个线程能够获取锁,其他线程在等待获取锁的时候会进入休眠状态。因此pthread_mutex_t消耗的CPU资源很小,但是性能不高,因为会引起线程切换。
pthread_spinlock_t :
是自旋锁,同一瞬间也只能有一个线程能够获取锁,不同的是,其他线程在等待获取锁的过程中并不进入睡眠状态,而是在CPU上进入“自旋”等待。自旋锁的性能很高,但是只适合对很小的代码段加锁(或短期持有的锁),自旋锁对CPU的占用相对较高。
pthread_rwlock_t :
是读写锁,同时可以有多个线程获得读锁,同时只允许有一个线程获得写锁。其他线程在等待锁的时候同样会进入睡眠。读写锁在互斥锁的基础上,允许多个线程“读”,在某些场景下能提高性能。
诸如pthread中的pthread_cond_t, pthread_barrier_t, semaphone等,更像是一种同步原语,不属于单纯的锁。
TBB中提供的锁有:
- mutex 互斥锁,等同于pthread中的互斥锁(实际上就是对pthread_mutex_t进行封装)
- recurisive_mutex 可重入的互斥锁,在pthread_mutex_t的基础上加了一个可重入的属性
- spin_metux 自旋锁,与pthread_spinlock_t类似,但是性能比pthread_spinlock_t低28%
- queuing_metux 公平的互斥锁,严格按照等待锁的先后顺序获得锁
- spin_rw_mutex 读写自旋锁,功能与pthread_rwlock_t一致,但是性能比pthread_rwlock_t高很多
- queuing_rw_mutex 公平的读写读写锁,也是严格按照等待锁的先后顺序获得锁
以下是一个拥有3667527个节点的HASH表进行读操作所花费的时间,可以说明各种锁的性能:(多线程的环境为:4CPU的电脑上使用四个线程进行同样的度操作,然后取四个线程读取的平均时间)·单线程不加锁:0.818845s·多线程使用pthread_mutex_t:120.978713s (很离谱吧…………我也吓了一跳)·多线程使用pthread_rwlock_t:10.592172s (多个线程加读锁)·多线程使用pthread_spinlock_t:4.766012s·多个线程使用tbb::spin_mutex:6.638609s (从这里可以看出pthread的自旋锁比TBB的自旋锁性能高出28%)·多个线程使用tbb::spin_rw_mutex:3.471757s (并行读的环境下,这是所有锁中性能最高的)
无锁
无锁,英文一般翻译为lock-free,是利用处理器的一些特殊的原子指令来避免传统并行设计中对锁的使用。
如果一个共享数据结构的操作不需要互斥,那么它是无锁的。如果一个进程或线程在操作中间被中断,其他进程或线程的操作不受影响。[Herlihy 1991]
笔者对于无锁的实践都是在一个进程下关于多线程并发的,所以后面我们只讨论多线程。
为什么要无锁?(界定问题)
- 首先是性能考虑。
通信项目一般对性能有极致的追求,这是我们使用无锁的重要原因。当然,无锁算法如果实现的不好,性能可能还不如使用锁,所以我们选择比较擅长的数据结构和算法进行lock-free实现,比如Queue,对于比较复杂的数据结构和算法我们通过lock来控制,比如Map(虽然我们实现了无锁Hash,但是大小是限定的,而Map是大小不限定的)。
对于性能数据,后续文章会给出无锁和有锁的对比。(通过实验进行对比)
- 其次是避免锁的使用引起的错误和问题:
死锁(dead lock)、
活锁(live lock)、
锁护送(lock convoy)、
优先级反转(priority inversion)
- 死锁(dead lock):两个以上线程互相等待
- 锁护送(lock convoy):多个同优先级的线程反复竞争同一个锁,抢占锁失败后强制上下文切换,引起性能下降
- 优先级反转(priority inversion):低优先级线程拥有锁时被中优先级的线程抢占,而高优先级的线程因为申请不到锁被阻塞
如何无锁?(界定问题)
在现代的 CPU 处理器上,很多操作已经被设计为原子的,比如对齐读(Aligned Read)和对齐写(Aligned Write)等。Read-Modify-Write(RMW)操作的设计让执行更复杂的事务操作变成了原子操作,当有多个写入者想对相同的内存进行修改时,保证一次只执行一个操作。
RMW 操作在不同的 CPU 家族中是通过不同的方式来支持的:
- x86/64 和 Itanium 架构通过 Compare-And-Swap (CAS) 方式来实现
- PowerPC、MIPS 和 ARM 架构通过 Load-Link/Store-Conditional (LL/SC) 方式来实现
笔者都是在x64下进行实践的,用的是CAS操作,CAS操作是lock-free技术的基础,我们可以用下面的代码来描述:
template <class T> bool CAS(T* addr, T expected, T value)
{
if (*addr == expected)
{
*addr = value;
return true;
}
return false;
}
在GCC中,CAS操作如下所示:
bool __sync_bool_compare_and_swap (type *ptr, type oldval type newval, ...)
type __sync_val_compare_and_swap (type *ptr, type oldval type newval, ...)
这两个函数提供原子的比较和交换,如果ptr == oldval,就将newval写入ptr,第一个函数在相等并写入的情况下返回true,第二个函数的内置行为和第一个函数相同,只是它返回操作之前的值。
后面的可扩展参数(…)用来指出哪些变量需要memory barrier,因为目前gcc实现的是full barrier,所以可以略掉这个参数。
除过CAS操作,GCC还提供了其他一些原子操作,可以在无锁算法中灵活使用:
type __sync_fetch_and_add (type *ptr, type value, ...)type
__sync_fetch_and_sub (type *ptr, type value, ...)type
__sync_fetch_and_or (type *ptr, type value, ...)type
__sync_fetch_and_and (type *ptr, type value, ...)type
__sync_fetch_and_xor (type *ptr, type value, ...)type
__sync_fetch_and_nand (type *ptr, type value, ...)type
__sync_add_and_fetch (type *ptr, type value, ...)type
__sync_sub_and_fetch (type *ptr, type value, ...)type
__sync_or_and_fetch (type *ptr, type value, ...)type
__sync_and_and_fetch (type *ptr, type value, ...)type
__sync_xor_and_fetch (type *ptr, type value, ...)type
__sync_nand_and_fetch (type *ptr, type value, ...)
_sync*系列的built-in函数,用于提供加减和逻辑运算的原子操作。这两组函数的区别在于第一组返回更新前的值,第二组返回更新后的值。
笔者开发无锁算法感触最深的是复杂度的分解,比如多线程对于一个双向链表的插入或删除操作,如何能一步一步分解成一个一个串联的原子操作,并能保证事务内存的一致性。
CAS等原子操作
在开始说无锁队列之前,我们需要知道一个很重要的技术就是CAS操作——Compare & Set,或是 Compare & Swap,现在几乎所有的CPU指令都支持CAS的原子操作,X86下对应的是 CMPXCHG 汇编指令。有了这个原子操作,我们就可以用其来实现各种无锁(lock free)的数据结构。
这个操作用C语言来描述就是下面这个样子:(代码来自Wikipedia的Compare And Swap词条)意思就是说,看一看内存*reg里的值是不是oldval,如果是的话,则对其赋值newval。
int compare_and_swap (int* reg, int oldval, int newval)
{
int old_reg_val = *reg;
if (old_reg_val == oldval)
*reg = newval;
return old_reg_val;
}
这个操作可以变种为返回bool值的形式(返回 bool值的好处在于,可以调用者知道有没有更新成功):
bool compare_and_swap (int *accum, int *dest, int newval)
{
if ( *accum == *dest ) {
*dest = newval;
return true;
}
return false;
}
与CAS相似的还有下面的原子操作:(这些东西大家自己看Wikipedia吧)
Fetch And Add,一般用来对变量做 +1 的原子操作
Test-and-set,写值到某个内存位置并传回其旧值。汇编指令BST
Test and Test-and-set,用来低低Test-and-Set的资源争夺情况
注:在实际的C/C++程序中,CAS的各种实现版本如下:
- GCC的CAS
GCC4.1+版本中支持CAS的原子操作(完整的原子操作可参看 GCC Atomic Builtins)
bool __sync_bool_compare_and_swap (type *ptr, type oldval type newval, ...)
type __sync_val_compare_and_swap (type *ptr, type oldval type newval, ...)
- Windows的CAS
在Windows下,你可以使用下面的Windows API来完成CAS:(完整的Windows原子操作可参看MSDN的InterLocked Functions)
InterlockedCompareExchange ( __inout LONG volatile *Target,
__in LONG Exchange,
__in LONG Comperand);
- C++11中的CAS
C++11中的STL中的atomic类的函数可以让你跨平台。(完整的C++11的原子操作可参看 Atomic Operation Library)
template< class T >
bool atomic_compare_exchange_weak( std::atomic* obj,
T* expected, T desired );
template< class T >
bool atomic_compare_exchange_weak( volatile std::atomic* obj,
T* expected, T desired );
无锁队列的链表实现
下面的东西主要来自John D. Valois 1994年10月在拉斯维加斯的并行和分布系统系统国际大会上的一篇论文——《Implementing Lock-Free Queues》。
我们先来看一下进队列用CAS实现的方式:
EnQueue(x) //进队列
{
//准备新加入的结点数据
q = new record();
q->value = x;
q->next = NULL;
do {
p = tail; //取链表尾指针的快照
} while( CAS(p->next, NULL, q) != TRUE); //如果没有把结点链在尾指针上,再试
CAS(tail, p, q); //置尾结点
}
我们可以看到,程序中的那个 do- while 的 Re-Try-Loop。就是说,很有可能我在准备在队列尾加入结点时,别的线程已经加成功了,于是tail指针就变了,于是我的CAS返回了false,于是程序再试,直到试成功为止。这个很像我们的抢电话热线的不停重播的情况。
你会看到,为什么我们的“置尾结点”的操作(第12行)不判断是否成功,因为:
- 如果有一个线程T1,它的while中的CAS如果成功的话,那么其它所有的 随后线程的CAS都会失败,然后就会再循环,
- 此时,如果T1 线程还没有更新tail指针,其它的线程继续失败,因为tail->next不是NULL了。
- 直到T1线程更新完tail指针,于是其它的线程中的某个线程就可以得到新的tail指针,继续往下走了。
这里有一个潜在的问题——如果T1线程在用CAS更新tail指针的之前,线程停掉或是挂掉了,那么其它线程就进入死循环了。下面是改良版的EnQueue()
EnQueue(x) //进队列改良版
{
q = new record();
q->value = x;
q->next = NULL;
p = tail;
oldp = p
do {
while (p->next != NULL)
p = p->next;
} while( CAS(p.next, NULL, q) != TRUE); //如果没有把结点链在尾上,再试
CAS(tail, oldp, q); //置尾结点,不准了。
}
我们让每个线程,自己fetch 指针 p 到链表尾。但是这样的fetch会很影响性能。而通实际情况看下来,99.9%的情况不会有线程停转的情况,所以,更好的做法是,你可以接合上述的这两个版本,如果retry的次数超了一个值的话(比如说3次),那么,就自己fetch指针。
好了,我们解决了EnQueue,我们再来看看DeQueue的代码:(很简单,我就不解释了)
DeQueue() //出队列
{
do{
p = head;
if (p->next == NULL){
return ERR_EMPTY_QUEUE;
}
while( CAS(head, p, p->next) != TRUE );
return p->next->value;
}
我们可以看到,DeQueue的代码操作的是 head->next,而不是head本身。这样考虑是因为一个边界条件,我们需要一个dummy的头指针来解决链表中如果只有一个元素,head和tail都指向同一个结点的问题,这样EnQueue和DeQueue要互相排斥了。
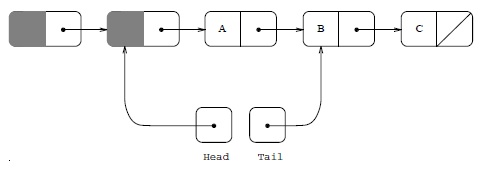
ABA问题
ABA问题可以俗称为“调包问题”,我们先看一个生活化的例子:
你拿着一个装满钱的手提箱在飞机场,此时过来了一个火辣性感的美女,然后她很暖昧地挑逗着你,并趁你不注意的时候,把用一个一模一样的手提箱和你那装满钱的箱子调了个包,然后就离开了,你看到你的手提箱还在那,于是就提着手提箱去赶飞机了。
我们再看一个CAS化的例子:
若线程对同一内存地址进行了两次读操作,而两次读操作得到了相同的值,通过 “值相同” 来判定 “值没变”是不可靠的。因为在这两次读操作的时间间隔之内,另外的线程可能已经多次修改了该值,这样就相当于欺骗了前面的线程,使其认为 “值没变”,实际上值已经被篡改过了。
下面是 ABA 问题发生的过程:
- T1 线程从共享的内存地址读取值 A;
- T1 线程被抢占,线程 T2 开始运行;
- T2 线程将共享的内存地址中的值由 A 改成 B,然后又改成 A;
- T1 线程继续执行,读取共享的内存地址中的值 A,认为没有改变,然后继续执行
由于 T1 并不知道两次读取的值 A 已经被 “隐性” 的修改过,所以可能产生无法预期的结果。
当 CAS操作循环执行时,存在多个线程交错地对共享的内存地址进行处理,如果实现的不正确,将有可能遇到 ABA 问题。
虽然P1以为变量值没有改变,继续执行了,但是这个会引发一些潜在的问题。ABA问题最容易发生在lock free
的算法中的,CAS首当其冲,因为CAS判断的是指针的地址。如果这个地址被重用了呢,问题就很大了。(地址被重用是很经常发生的,一个内存分配后释放了,再分配,很有可能还是原来的地址)
比如上述的DeQueue()函数,因为我们要让head和tail分开,所以我们引入了一个dummy指针给head,当我们做CAS的之前,如果head的那块内存被回收并被重用了,而重用的内存又被EnQueue()进来了,这会有很大的问题。(内存管理中重用内存基本上是一种很常见的行为)
这个例子你可能没有看懂,维基百科上给了一个活生生的例子——
你拿着一个装满钱的手提箱在飞机场,此时过来了一个火辣性感的美女,然后她很暖昧地挑逗着你,并趁你不注意的时候,把用一个一模一样的手提箱和你那装满钱的箱子调了个包,然后就离开了,你看到你的手提箱还在那,于是就提着手提箱去赶飞机去了。
这就是ABA的问题。
解决ABA的问题
维基百科上给了一个解——使用double-CAS(双保险的CAS),例如,在32位系统上,我们要检查64位的内容
- 一次用CAS检查双倍长度的值,前半部是指针,后半部分是一个计数器。
- 只有这两个都一样,才算通过检查,要吧赋新的值。并把计数器累加1。
这样一来,ABA发生时,虽然值一样,但是计数器就不一样(但是在32位的系统上,这个计数器会溢出回来又从1开始的,这还是会有ABA的问题)
当然,我们这个队列的问题就是不想让那个内存重用,这样明确的业务问题比较好解决,论文《Implementing Lock-Free Queues》给出一这么一个方法——使用结点内存引用计数refcnt!
SafeRead(q)
{
loop:
p = q->next;
if (p == NULL){
return p;
}
Fetch&Add(p->refcnt, 1);
if (p == q->next){
return p;
}else{
Release(p);
}
goto loop;
}
其中的 Fetch&Add和Release分是是加引用计数和减引用计数,都是原子操作,这样就可以阻止内存被回收了。
用数组实现无锁队列
本实现来自论文《 Implementing Lock-Fre》
使用数组来实现队列是很常见的方法,因为没有内存的分部和释放,一切都会变得简单,实现的思路如下:
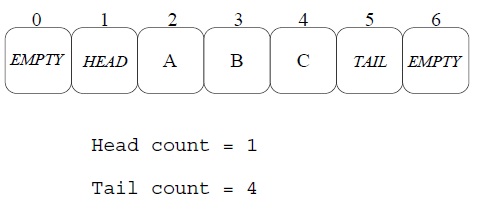
- 数组队列应该是一个ring buffer形式的数组(环形数组)
- 数组的元素应该有三个可能的值:HEAD,TAIL,EMPTY(当然,还有实际的数据)
- 数组一开始全部初始化成EMPTY,有两个相邻的元素要初始化成HEAD和TAIL,这代表空队列。
- EnQueue操作。假设数据x要入队列,定位TAIL的位置,使用double-CAS方法把(TAIL, EMPTY) 更新成 (x, TAIL)。需要注意,如果找不到(TAIL, EMPTY),则说明队列满了。
- DeQueue操作。定位HEAD的位置,把(HEAD, x)更新成(EMPTY, HEAD),并把x返回。同样需要注意,如果x是TAIL,则说明队列为空。
算法的一个关键是——如何定位HEAD或TAIL?
- 我们可以声明两个计数器,一个用来计数EnQueue的次数,一个用来计数DeQueue的次数。
- 这两个计算器使用使用Fetch&ADD来进行原子累加,在EnQueue或DeQueue完成的时候累加就好了。
- 累加后求个模什么的就可以知道TAIL和HEAD的位置了。
如下图所示:
小结
以上基本上就是所有的无锁队列的技术细节,这些技术都可以用在其它的无锁数据结构上。
1)无锁队列主要是通过CAS、FAA这些原子操作,和Retry-Loop实现。
2)对于Retry-Loop,我个人感觉其实和锁什么什么两样。只是这种“锁”的粒度变小了,主要是“锁”HEAD和TAIL这两个关键资源。而不是整个数据结构。
还有一些和Lock Free的文章你可以去看看:
Code Project 上的雄文 《Yet another implementation of a lock-free circular array queue》
Herb Sutter的《Writing Lock-Free Code: A Corrected Queue》– 用C++11的std::atomic模板。
IBM developerWorks的《设计不使用互斥锁的并发数据结构》
【注:我配了一张look-free的自行车,寓意为——如果不用专门的车锁,那么自行得自己锁自己!】
小结
本文简要介绍了无锁编程的基础,我们知道了什么是lock-free,为什么要lock-free以及如何lock-free,最后提出了ABA问题。我们将在下一篇文章《无锁队列》中实例化ABA问题,并给出解决方法。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/132784.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
