大家好,又见面了,我是你们的朋友全栈君。
原文地址:http://preshing.com/20120612/an-introduction-to-lock-free-programming
无锁编程是一项挑战,不仅仅是因为自身的复杂性所致,还与初次探索该课题的困难性相关。
我很幸运,我第一次介绍无锁 (lock-free,也称为 lockless) 编程,是 Bruce Dawson 的出色而全面的白皮书《无锁编程注意事项》。和大多数人一样,我有机会将 Bruce 的建议用到无锁代码的编写和调试中,例如在 Xbox360 平台上的开发。
从那时起,出现了很多好的素材,包括抽象的理论、实例的正确性的证明以及一些硬件的细节。我在脚注中会有一些引用。有时,不同来源的资料是不同的。例如,一些材料假设了顺序一致性,这就回避了困扰 C/C++ 无锁代码的内存排序问题。新的 C++11 的原子操作库标准提供了新的工具,这会挑战现有的无锁算法。
在本文中,我会重新介绍无锁编程,首先对其进行定义,然后从众多信息提炼出少数重要的概念。我会使用流程图来展示各个概念间的关系,然后我们将涉足一些细节问题。任何学习无锁编程的程序员,都应该能理解如何在多线程代码中使用互斥量,理解一些高级同步机制,例如信号和事件等。
无锁编程是什么
人们常常将无锁编程描述成不使用 互斥量(Mutex,一种锁的机制)的程序。这个说法是对的,但并不全面。被广泛接受的基于学术报告的定义含有更广义的含义。从本质上来说,无锁编程是描述一些代码的一个属性,它并没有过多描述代码是如何写的。
基本上,你的代码的一些部分符合如下条件,即可被认为是无锁的。反之,如果你的代码一些部分不符合下述条件,则被认为不是无锁的。
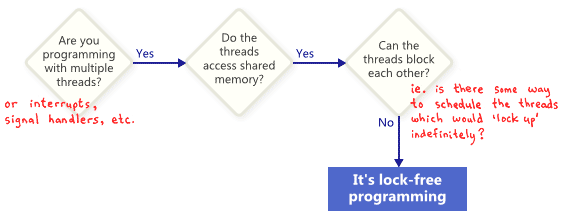

在该场景中,“无锁” 中的 “锁” 并不是直接指互斥量,而是指 “锁定” 整个应用的所有可能的方式,不论是死锁、活锁甚至可能是线程调度的方式都是你最大的敌人。最后一点听起来似乎很好笑,却是至关重要的一点。首先,共享互斥量被排除了,因为一旦一个线程获取了互斥量,你最大的敌人将永远无法再次调度那个线程。当然,真实的操作系统不是那样做的,只是我们是如此定义的。
下面这个简单的例子没有使用互斥量,但仍然不是无锁的。X初始值为0。作为练习题,请考虑如何调度两个线程,才能使得两个都不退出循环?
while (X == 0)
{
X = 1 - X;
}
没人期待整个大型的应用是完全无锁的。通常,我们可以从整个代码库中识别出一系列无锁操作。例如,在一个无锁队列中有少许的无锁操作,像push、pop,或许还有isEmpty等等。
《多处理器编程艺术》的作者Herlihy和Shavit,趋向于将这些操作表达成类的方法,并提出了一个简单的无锁的定义(第150页):“在一个无限的执行过程中,会不停地有调用结束”。换句话说,程序能不断地调用这些无锁操作的同时,许多调用的也是不断地在完成。从算法上来说,在这些操作的执行过程中,系统锁定是不可能的。
无锁编程的一个重要的特性就是,如果挂起一个单独的线程,不会阻碍其它线程执行。作为一组线程,他们使用特定的无锁操作来完成这个特性。这揭示了无锁编程在中断处理程序和实时系统方面的价值。因为在这些情况下,特定的操作必须在特定的时间内完成,不论程序的状态如何。
最后的精确描述:设计用于阻塞的操作不会影响算法运行,这种代码才是无锁的。例如在无锁队列的操作中,当队列为空时,队列的弹出操作会有意地阻塞。但其它的代码路径仍然被认为是无锁的。
无锁编程技术
事实证明,当你试图满足无锁编程的无阻塞条件时,会出现一系列技术:原子操作、内存屏障、避免ABA问题,等等。从这里开始,事情很快变得棘手了。
那么,这些技术间是如何相互关联的?我将它们放在下面的流程图中进行展示。下文将逐一阐述。
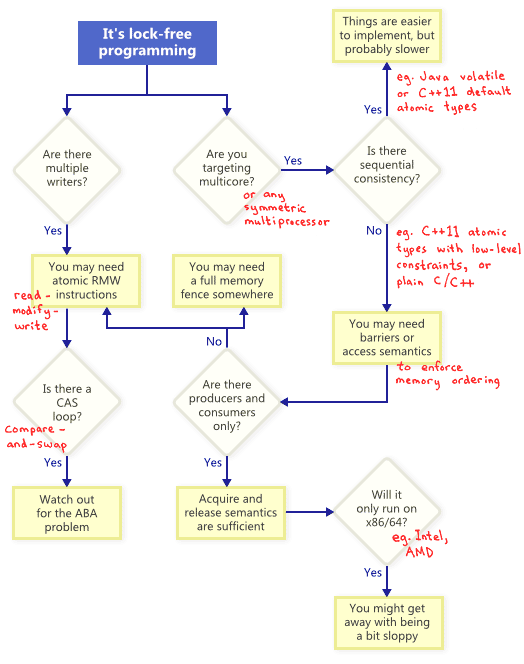
原子的 Read-Modify-Write 操作
所谓原子操作是指,通过一种看起来不可分割的方式来操作内存:线程无法看到原子操作的中间过程。在现代的处理器上,有很多操作本身就是的原子的。例如,对简单类型的对齐的读和写通常就是原子的。
Read-Modify-Write(RMW)操作更进一步,它允许你按照原子的方式,操作更复杂的事务。当一个无锁的算法必须支持多个写入者时,原子操作会尤其有用,因为多个线程试图在同一个地址上进行RMW时,它们会按“一次一个”的方式排队执行这些操作。我已经在我的博客中涉及了RMW操作了,如实现 轻量级互斥量、递归互斥量 和 轻量级日志系统。
RMW 操作的例子包括:Win32上 的 _InterlockedIncrement,iOS 上的 OSAtomicAdd32 以及 C++11 中的 std::atomic<int>::fetch_add。需要注意的是,C++11 的原子标准不保证其在每个平台上的实现都是无锁的,因此最好要清楚你的平台和工具链的能力。你可以调用 std::atomic<>::is_lock_free 来确认一下。
不同的 CPU 系列支持 RMW 的方式也是不同的。例如,PowerPC 和 ARM 提供 load-link/store-conditional 指令,这实际上是允许你实现你自定义的底层 RMW 操作。常用的 RMW 操作就已经足够了。
如上面流程图所述,即使在单处理器系统上,原子的 RMW 操作也是无锁编程的必要部分。没有原子性的话,一个线程的事务会被中途打断,这可能会导致一个错误的状态。
Compare-And-Swap 循环
或许,最常讨论的 RMW 操作是 compare-and-swap (CAS)。在Win32上,CAS 是通过如 _InterlockedCompareExchange 等一系列指令来提供的。通常,程序员会在一个事务中使用 CAS 循环。这个模式通常包括:复制一个共享的变量至本地变量,做一些特定的工作(改动),再试图使用 CAS 发布这些改动。
void LockFreeQueue::push(Node* newHead)
{
for (;;)
{
// Copy a shared variable (m_Head) to a local.
Node* oldHead = m_Head;
// Do some speculative work, not yet visible to other threads.
newHead->next = oldHead;
// Next, attempt to publish our changes to the shared variable.
// If the shared variable hasn't changed, the CAS succeeds and we return.
// Otherwise, repeat.
if (_InterlockedCompareExchange(&m_Head, newHead, oldHead) == oldHead)
return;
}
}
这样的循环仍然有资格作为无锁的,因为如果一个线程检测失败,意味着有其它线程成功—尽管某些架构提供一个 较弱的CAS变种 。无论何时实现一个CAS循环,都必须十分小心地避免 ABA 问题。
顺序一致性
顺序一致性(Sequential consistency)意味着,所有线程就内存操作的顺序达成一致。这个顺序是和操作在程序源代码中的顺序是一致的。在顺序一致性的要求下,像我 另一篇文章 演示的那样的有意的内存重排序不再可能了。
一种实现顺序一致性的简单(但显然不切实际)的方法是禁用编译器优化,并强制所有线程在单个处理器上运行。 即使线程在任意时间被抢占和调度,处理器也永远不会看到自己的内存影响。
某些编程语言甚至可以为在多处理器环境中运行的优化代码提供顺序一致性。 在C ++ 11中,可以将所有共享变量声明为具有默认内存排序约束的C ++ 11原子类型。 在Java中,您可以将所有共享变量标记为volatile。下面是 我之前一个案例 用C++11风格重写的例子。
std::atomic X(0), Y(0);
int r1, r2;
void thread1()
{
X.store(1);
r1 = Y.load();
}
void thread2()
{
Y.store(1);
r2 = X.load();
}
因为 C ++ 11 原子类型保证顺序一致性,所以结果 r1 = r2 = 0 是不可能的。 为此,编译器会在后台输出其他指令——通常是 内存围栏 和/或 RMW 操作。 与程序员直接处理内存排序的指令相比,那些额外的指令可能会使实现效率降低。
内存保序
正如前面流程图所建议的那样,任何时候做多核(或者任何对称多处理器)的无锁编程,如果你的环境不能保证顺序一致性,你都必须考虑如何来防止 内存重新排序。
在当今的架构中,增强内存保序性的工具通常分为三类,它们既防止 编译器重新排序 又防止 处理器重新排序:
获取语义可防止按照程序顺序对其进行操作的内存重新排序,而释放语义则可防止对其进行操作前的内存重新排序。 这些语义尤其适用于存在生产者/消费者关系的情况,其中一个线程发布一些信息,而另一个线程读取它。 在以后的文章中,我还将对此进行更多讨论。
不同的处理器有不同的内存模型
在内存重新排序方面,不同的CPU系列具有不同的习惯。 每个CPU供应商都记录了这些规则,并严格遵循了硬件。 例如,PowerPC 和 ARM 处理器可以相对于指令本身更改内存存储的顺序,但是通常,英特尔和 AMD 的 x86 / 64 系列处理器不会。 我们说以前的处理器具有更宽松的内存模型。
有人倾向于将这些特定于平台的细节抽象出来,尤其是C ++ 11为我们提供了编写可移植的无锁代码的标准方法。 但是目前,我认为大多数无锁程序员至少对平台差异有所了解。 如果需要记住一个关键的区别,那就是在x86 / 64指令级别上,每次从内存中加载都会获取语义,并且每次存储到内存都将提供释放语义–至少对于非SSE指令和非写组合内存 。 因此,过去通常会编写可在x86 / 64上运行但 在其他处理器上无法运行 的无锁代码。
如果你对硬件如何处理内存重新排序的细节感兴趣,我建议看看《Is Pararllel Programming Hard》的附录C。无论如何,请记住,由于编译器对指令的重新排序,也会发生内存重新排序。
在这篇文章中,我没有对无锁编程的实际方面说太多,例如:什么时候做? 我们真正需要多少? 我也没有提到验证无锁算法的重要性。 尽管如此,我希望对某些读者来说,本入门对无锁概念有基本的了解,因此您可以继续阅读其他内容而不会感到困惑。
参考文献
[1] 无锁编程注意事项
[2] Locks Aren’t Slow; Lock Contention Is
[3] 实现自己的轻量级互斥量
[4] 实现一个递归互斥量
[5] 一个轻量级内存日志系统
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/132631.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
