大家好,又见面了,我是你们的朋友全栈君。
写在前面:我是「且听风吟」,目前是某上市游戏公司的大数据开发工程师,热爱大数据开源技术,喜欢分享自己的所学所悟,现阶段正在从头梳理大数据体系的知识,以后将会把时间重点放在Spark和Flink上面。
如果你也对大数据感兴趣,希望在这个行业一展拳脚。欢迎关注我,我们一起努力,一起学习。博客地址:https://ropledata.blog.csdn.net
博客的名字来源于:且听风吟,静待花开。也符合我对技术的看法,想要真正掌握一门技术就需要厚积薄发的毅力,同时保持乐观的心态。你只管努力,剩下的交给时间!


文章目录
一、前言
本文版本说明:
- ElasticSearch版本:7.7 (目前最新版)
- Kibana版本:7.7(目前最新版)
ElasticSearch在实际生产里通常和LogStash,Kibana,FileBeat一起构成Elastic Stack来使用,它是这些组件里面最核心的一个。因此学好ElasticSearch的必要性不言而喻,但是由于ElasticSearch官方更新太过频繁且文档陈旧,同时在Linux下安装配置的过程较繁杂,不利于入门使用。
为了帮助大家快速入门ElasticSearch,并掌握ElasticSearch和Kibana的使用。本文会把最新版的ElasticSearch的知识点用通俗易懂的语言来展现,并会在核心概念上和MySql对比,同时给大家介绍百分百成功的极速安装配置方法,让大家可以把时间更多的用在技术研究上。
注意:下文咱们把ElasticSearch简称为ES,对可能出现的疑问进行标红并解释。

二、ES的概念及使用场景
ElasticSearch是一个分布式,高性能、高可用、可伸缩、RESTful 风格的搜索和数据分析引擎。通常作为Elastic Stack的核心来使用,Elastic Stack大致是如下这样组成的:
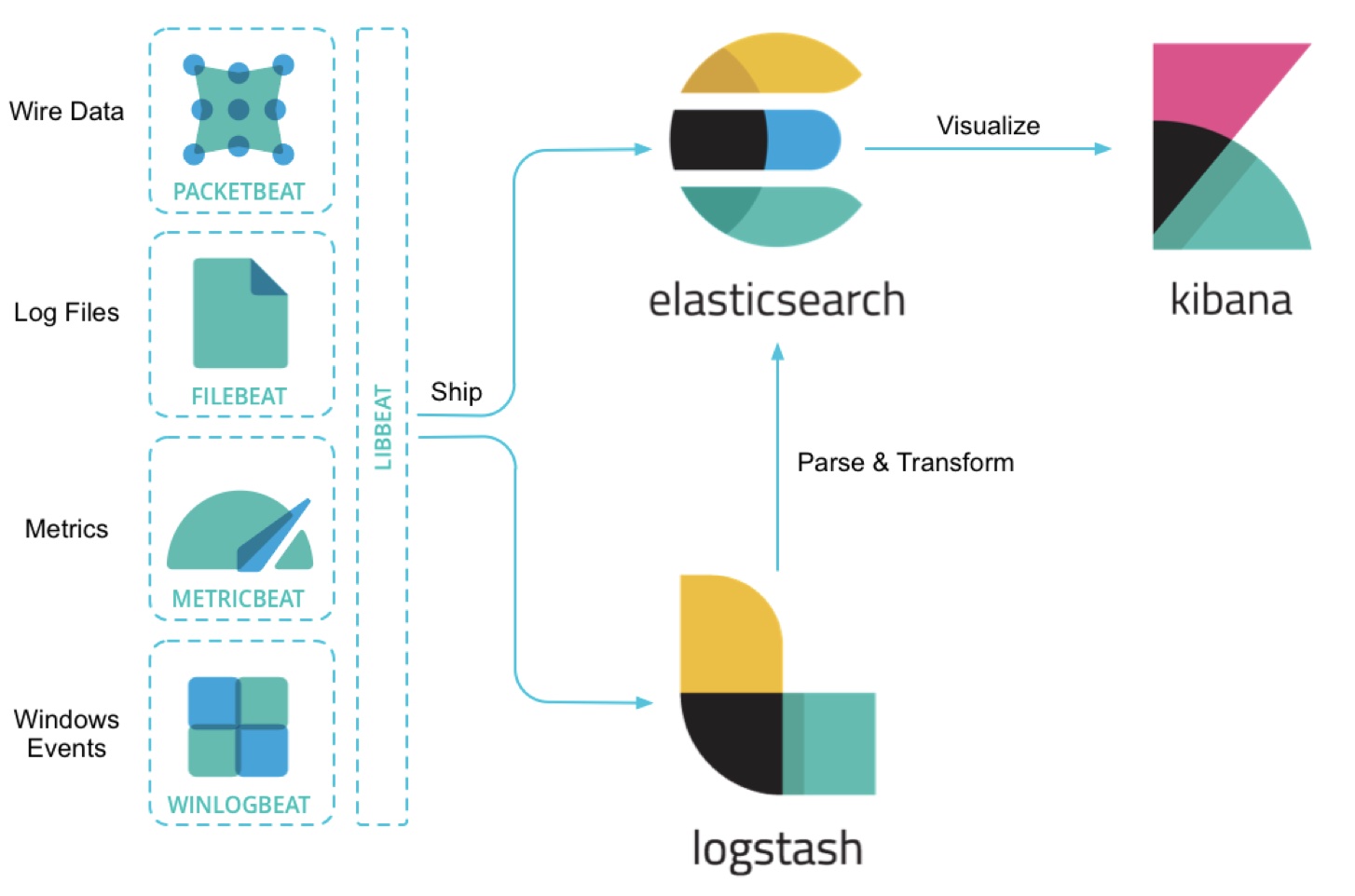
ES是一个近实时(NRT)的搜索引擎,一般从添加数据到能被搜索到只有很少的延迟(大约是1s),而查询数据是实时的。一般我们可以把ES配合logstash,kibana来做日志分析系统,或者是搜索方面的系统功能,比如在网上商城系统里实现搜索商品的功能也会用到ES。
疑问一:搜索商品的时候为啥要用ES呢?用sql的like进行模糊查询,它不香吗?
我们假设一个场景:我们要买苹果吃,咱们想买天水特产的花牛苹果,然后在搜索框输入
天水花牛苹果,这时候咱们希望搜索到所有的售卖天水花牛苹果的商家,但是如果咱们技术上根据这个天水花牛苹果使用sql的like模糊查询,是不能匹配到诸如天水特产花牛苹果,天水正宗,果园直送精品花牛苹果这类的不连续的店铺的。所以sql的like进行模糊查询来搜索商品还真不香!
三、基本概念
很多人第一次学习ES,看到基本概念后瞬间懵逼了,这是啥玩意呀,乱七八糟!别急,我整理了一下ES和mysql相关的基本概念的对比表格,先看一下:
| ES | MySql |
|---|---|
| 字段 | 列 |
| 文档 | 一行数据 |
| 类型(已废弃) | 表 |
| 索引 | 数据库 |
看完这个表格后,建议像背单词那样盖住右半部分的MySql,通过左边的概念来联想在MySql里的概念,加深记忆!
然后我们组合起来,所谓ES里的数据其实就是指索引下的类型里面的JSON格式的数据。
下面我们对这些概念分别进行详细的解释:
3.1、文档(Document)
-
我们知道Java是面向对象的,而Elasticsearch是面向文档的,也就是说文档是所有可搜索数据的最小单元。ES的文档就像MySql中的一条记录,只是ES的文档会被序列化成json格式,保存在Elasticsearch中;
-
这个json对象是由字段组成,字段就相当于Mysql的列,每个字段都有自己的类型(字符串、数值、布尔、二进制、日期范围类型);
-
当我们创建文档时,如果不指定字段的类型,Elasticsearch会帮我们自动匹配类型;
-
每个文档都有一个ID,类似MySql的主键,咱们可以自己指定,也可以让Elasticsearch自动生成;
-
文档的json格式支持数组/嵌套,在一个索引(数据库)或类型(表)里面,你可以存储任意多的文档。
注意:虽然在实际存储上,文档存在于某个索引里,但是文档必须被赋予一个索引下的类型才可以。
3.2、类型(Type)
类型就相当于MySql里的表,我们知道MySql里一个库下可以有很多表,最原始的时候ES也是这样,一个索引下可以有很多类型,但是从6.0版本开始,type已经被逐渐废弃,但是这时候一个索引仍然可以设置多个类型,一直到7.0版本开始,一个索引就只能创建一个类型了(_doc)。这一点,大家要注意,网上很多资料都是旧版本的,没有对这点进行说明。
3.3、索引(Index)
- 索引就相当于MySql里的数据库,它是具有某种相似特性的文档集合。反过来说不同特性的文档一般都放在不同的索引里;
- 索引的名称必须全部是小写;
- 在单个集群中,可以定义任意多个索引;
- 索引具有mapping和setting的概念,mapping用来定义文档字段的类型,setting用来定义不同数据的分布。
除了这些常用的概念,我们还需要知道节点概念的作用,因此咱们接着往下看!
3.4、节点(node)
- 一个节点就是一个ES实例,其实本质上就是一个java进程;
- 节点的名称可以通过配置文件配置,或者在启动的时候使用
-E node.name=ropledata指定,默认是随机分配的。建议咱们自己指定,因为节点名称对于管理目的很重要,咱们可以通过节点名称确定网络中的哪些服务器对应于ES集群中的哪些节点; - ES的节点类型主要分为如下几种:
- Master Eligible节点:每个节点启动后,默认就是Master Eligible节点,可以通过设置
node.master: false来禁止。Master Eligible可以参加选主流程,并成为Master节点(当第一个节点启动后,它会将自己选为Master节点);注意:每个节点都保存了集群的状态,只有Master节点才能修改集群的状态信息。 - Data节点:可以保存数据的节点。主要负责保存分片数据,利于数据扩展。
- Coordinating 节点:负责接收客户端请求,将请求发送到合适的节点,最终把结果汇集到一起
- Master Eligible节点:每个节点启动后,默认就是Master Eligible节点,可以通过设置
- 注意:每个节点默认都起到了Coordinating node的职责。一般在开发环境中一个节点可以承担多个角色,但是在生产环境中,还是设置单一的角色比较好,因为有助于提高性能。
3.5、分片(shard)
了解分布式或者学过mysql分库分表的应该对分片的概念比较熟悉,ES里面的索引可能存储大量数据,这些数据可能会超出单个节点的硬件限制。
为了解决这个问题,ES提供了将索引细分为多个碎片的功能,这就是分片。这里咱们可以简单去理解,在创建索引时,只需要咱们定义所需的碎片数量就可以了,其实每个分片都可以看作是一个完全功能性和独立的索引,可以托管在集群中的任何节点上。
疑问二:分片有什么好处和注意事项呢?
- 通过分片技术,咱们可以水平拆分数据量,同时它还支持跨碎片(可能在多个节点上)分布和并行操作,从而提高性能/吞吐量;
- ES可以完全自动管理分片的分配和文档的聚合来完成搜索请求,并且对用户完全透明;
- 主分片数在索引创建时指定,后续只能通过Reindex修改,但是较麻烦,一般不进行修改。
3.6、副本分片(replica shard)
熟悉分布式的朋友应该对副本对概念不陌生,为了实现高可用、遇到问题时实现分片的故障转移机制,ElasticSearch允许将索引分片的一个或多个复制成所谓的副本分片。
疑问三:副本分片有什么作用和注意事项呢?
当分片或者节点发生故障时提供高可用性。因此,需要注意的是,副本分片永远不会分配到复制它的原始或主分片所在的节点上;
可以提高扩展搜索量和吞吐量,因为ES允许在所有副本上并行执行搜索;
默认情况下,ES中的每个索引都分配5个主分片,并为每个主分片分配1个副本分片。主分片在创建索引时指定,不能修改,副本分片可以修改。
看到这里,各位一定对ES有所了解了,那么接下来就是安装配置并使用了!有不少朋友初学时查阅资料,选择安装win版本,这里我不推荐,因为实际工作中,ES不可能安装在win下。但是根据官方文档安装Linux版本时,又会遇到各种奇葩问题,咋办呢?别急,我这里有一本极速安装方法,百分百不出错,咱们接着往下看!

四、极速安装配置
咱们如果想很爽的使用ES,需要安装3个东西:ES、Kibana、ElasticSearch Head。通过Kibana可以对ES进行便捷的可视化操作,通过ElasticSearch Head可以查看ES的状态及数据,可以理解为ES的图形化界面。
那如何进行极速且不出错的安装配置呢?答案很简单,站在巨人的肩膀上!用docker启动前辈们已经配置好的ES环境不就可以了吗?!咱们做开发的应该把时间花在刀刃上,而不是花费大量时间去安装配置。
首先开始安装ES、Kibana,同时安装这两个加启动,一共需要3步,3行代码搞定:
-
搜索docker镜像库里可用的ES镜像:
docker search elasticsearch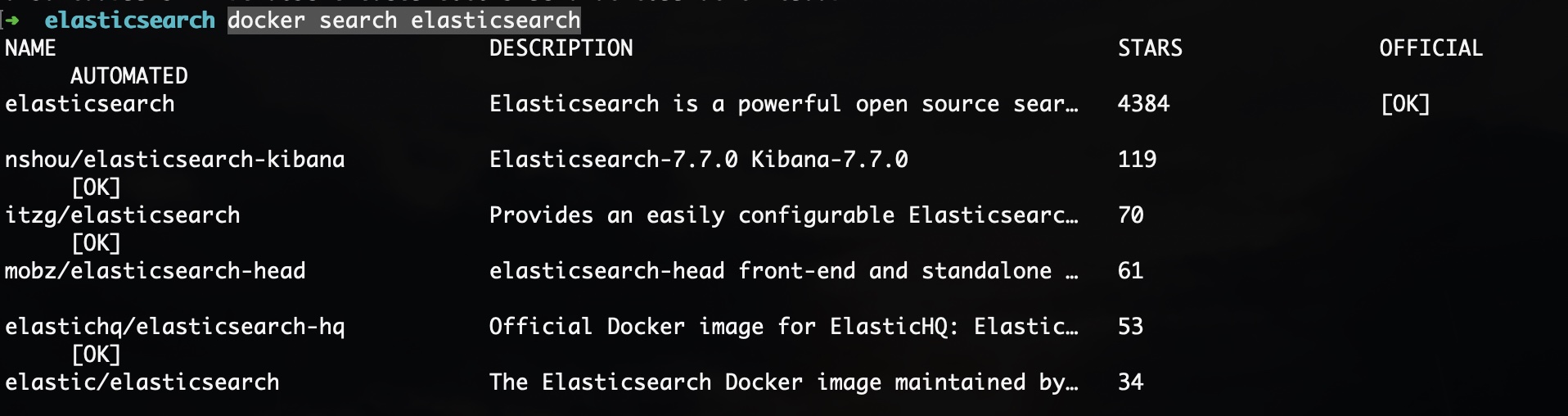
可以看到,stars排名第一的是官方的ES镜像,第二是大牛已经融合了ES7.7和Kibana7.7的镜像,那咱们就用第二个了。
-
把这个镜像从镜像库拉下来:
docker pull nshou/elasticsearch-kibana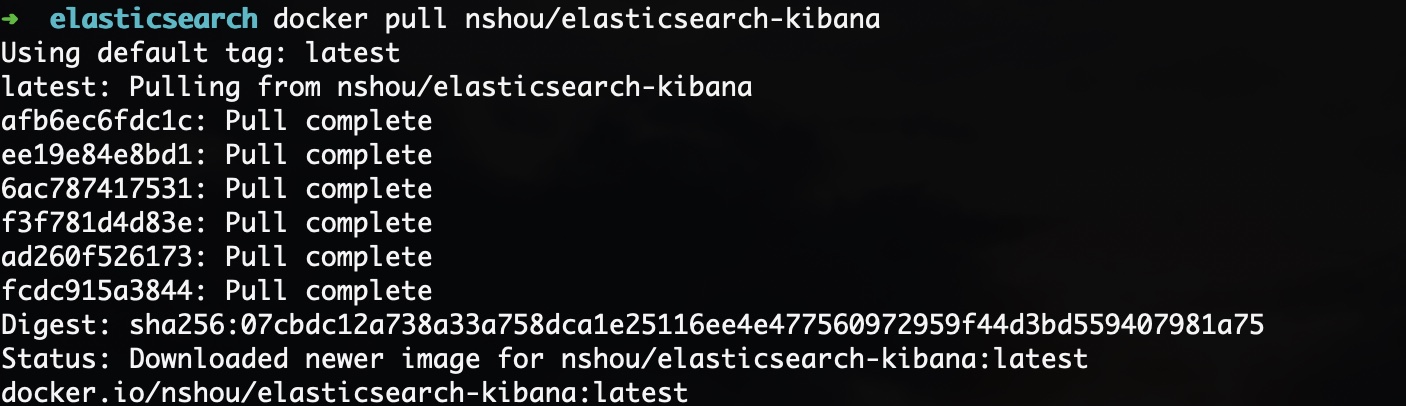
-
最后咱们把镜像启动为容器就可以了,端口映射保持不变,咱们给这个容器命名为eskibana,到这里ES和Kibana就安装配置完成了!容器启动后,它们也就启动了,一般不会出错,是不是非常方便?节省大把时间放到开发上来,这也是我一直推荐docker的原因。
docker run -d -p 9200:9200 -p 9300:9300 -p 5601:5601 --name eskibana nshou/elasticsearch-kibana
咱们还需要安装ElasticSearch Head,它相当于是ES的图形化界面,这个更简单,它是一个浏览器的扩展程序,直接在chrome浏览器扩展程序里下载安装即可:
-
打开chrome浏览器,在扩展程序chrome应用商店那里,搜索elasticsearch:
-
选择ElasticSearch Head,点击
添加至Chrome,进行扩展程序的安装即可:
到这里咱们的ES、Kibana、ElasticSearch Head都已经安装完成了,下面咱们验证一下,看是否安装成功!
-
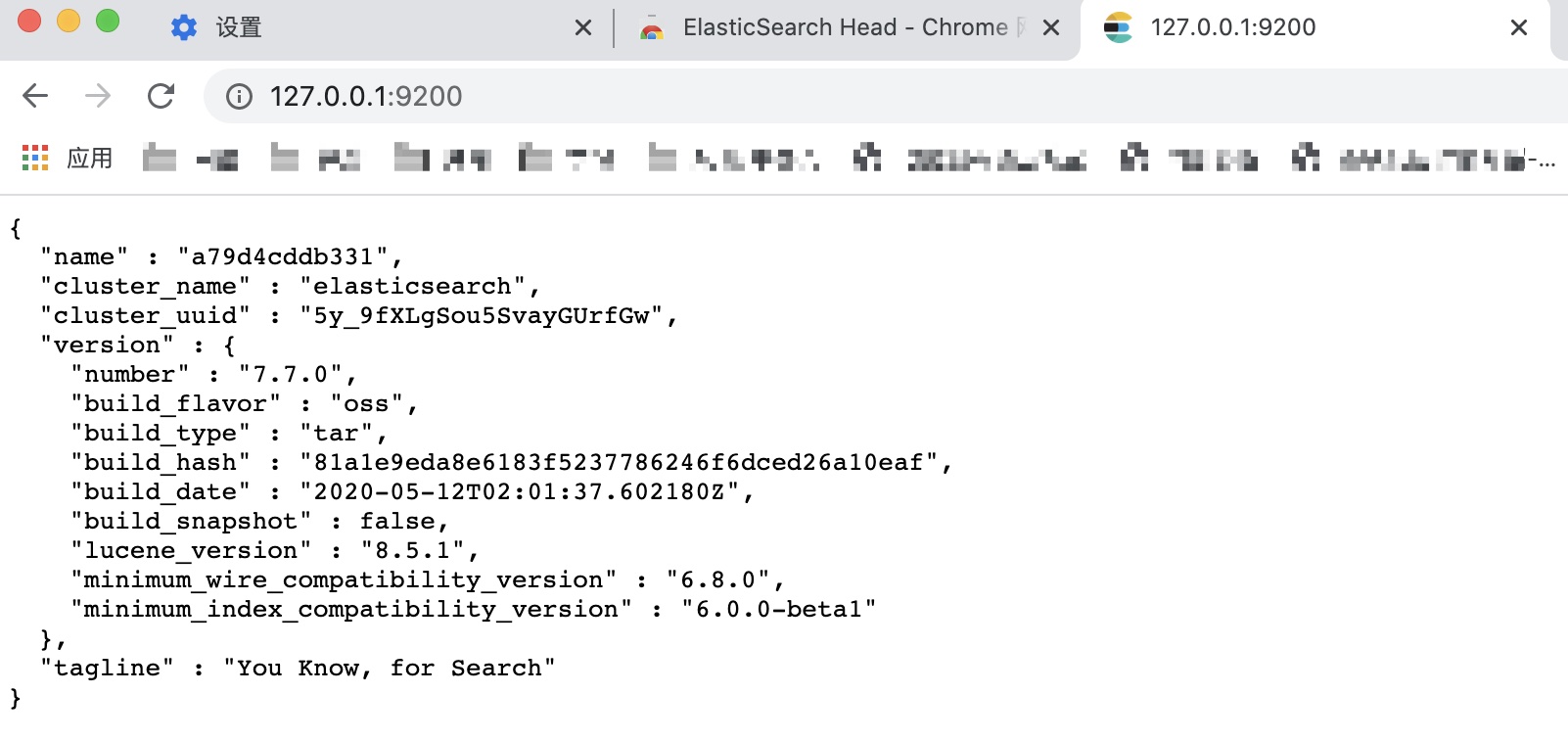
验证ES:
打开浏览器,输入IP:端口,比如我的:
http://127.0.0.1:9200/,然后就看到了那句经典的:You Know, for Search:
-
验证Kibana:
打开浏览器,输入Kibana的IP:端口,比如我的:
http://127.0.0.1:5601/,然后会看到如下界面:
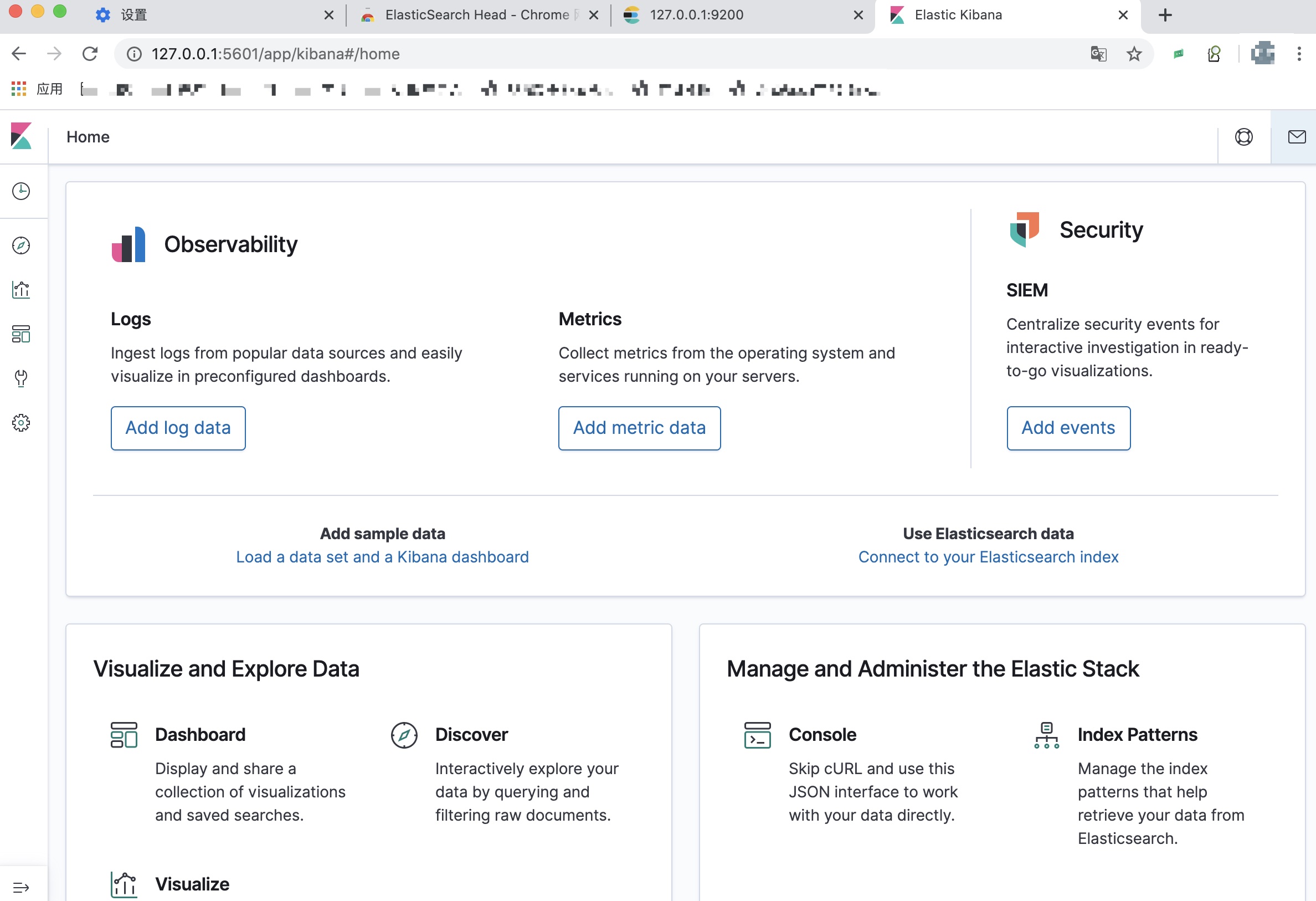
这里面可以提供很多模拟数据,感兴趣的可以自己玩玩,咱们学习期间只要使用左下角那个扳手形状的Dev Tools就可以了,点击后,会出现如下界面:
-
验证ES Head:
这个更简单,只需要点击之前咱们安装的那个扩展程序图标就可以了:
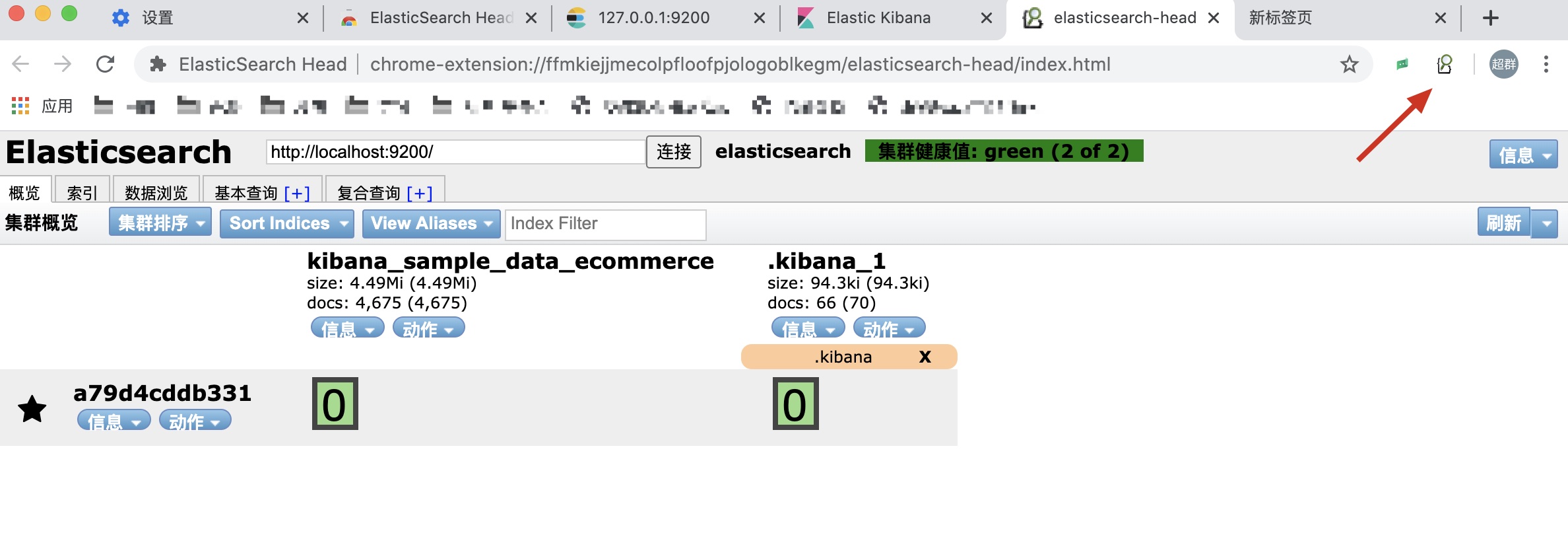
点击信息,还可以看到集群或者索引的信息,很方便,大家没事可以玩一玩,熟悉一下:
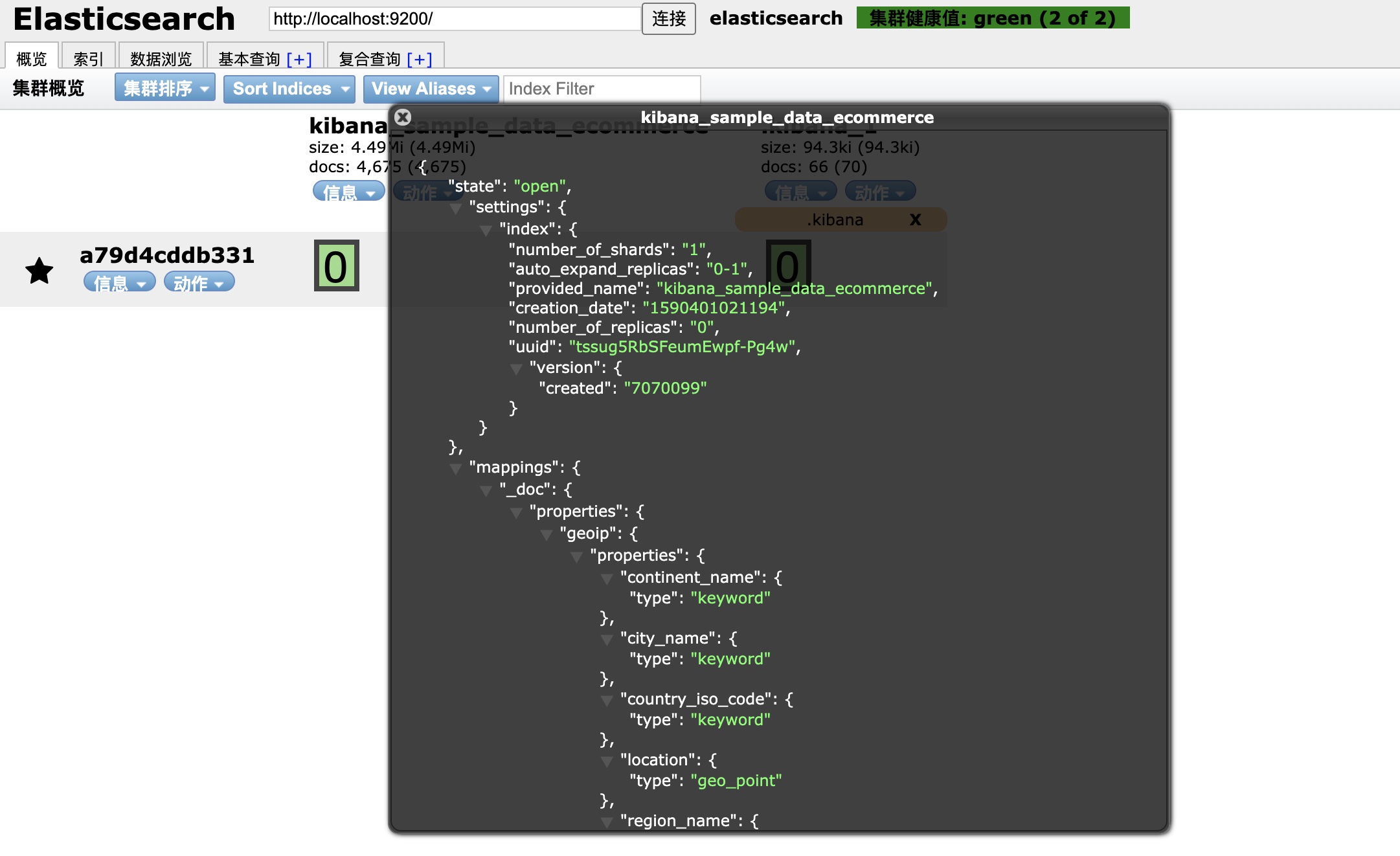
通过验证,我们已经全部安装配置成功了,那么接下来,就让我们一起练习一下基础的增删改查,加深对ES的理解吧!
五、基础使用
前面我们已经介绍过了ES 是RESTful 风格的系统,所以我们需要先掌握RESTful 的四个关键词:PUT(修改),POST(添加),DELETE(删除),GET(查询)。其中在ES里面PUT和POST的界限并不是很分明,有时候PUT也作为添加。
好了,下面就开始愉快的code吧~
5.1、索引基础操作
-
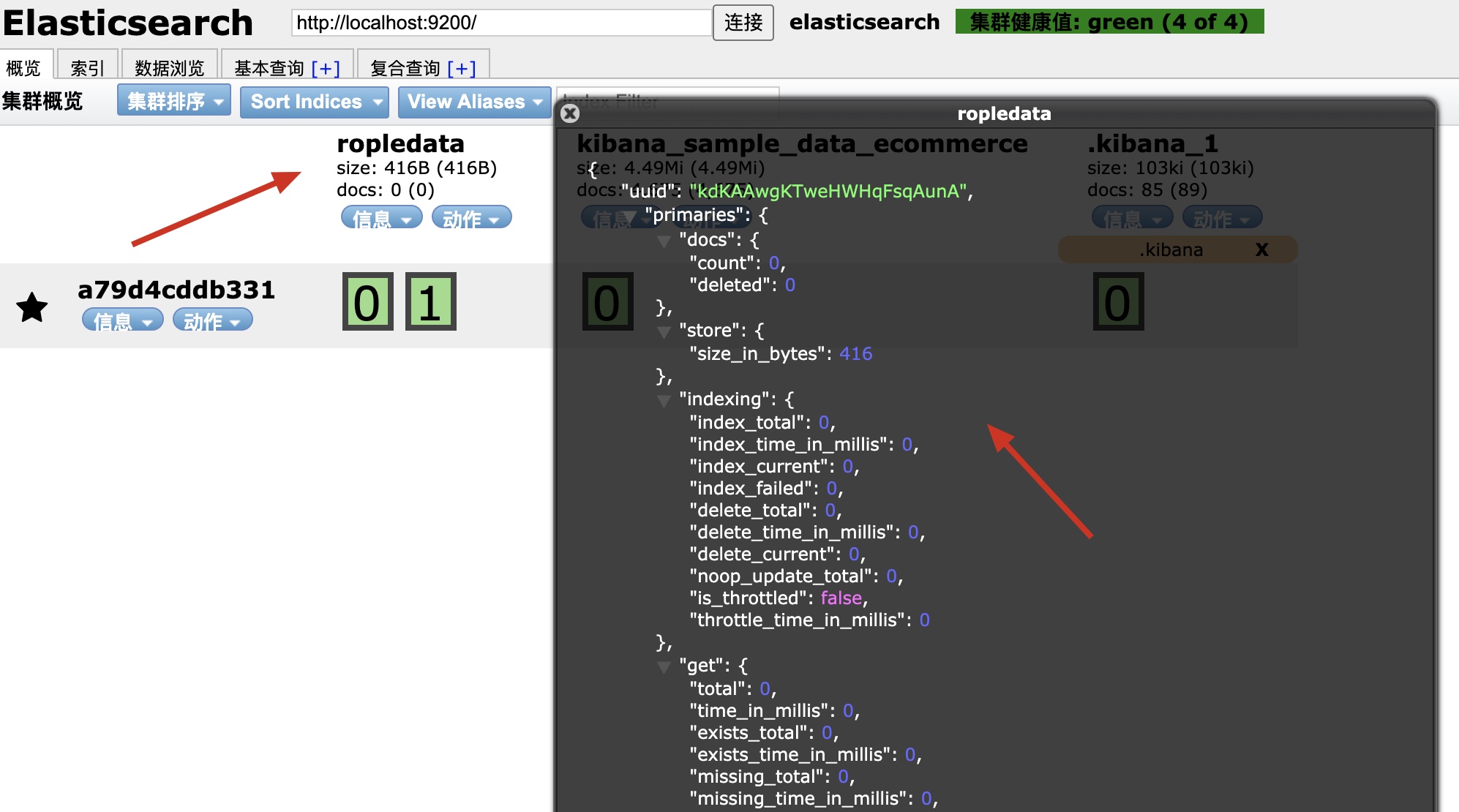
创建一个空索引
如下代码,咱们创建了一个0副本2分片的ropledata索引,然后咱们可以在Elasticsearch Head里刷新一下,并查看索引的信息:
PUT /ropledata { "settings": { "number_of_shards": "2", "number_of_replicas": "0" } }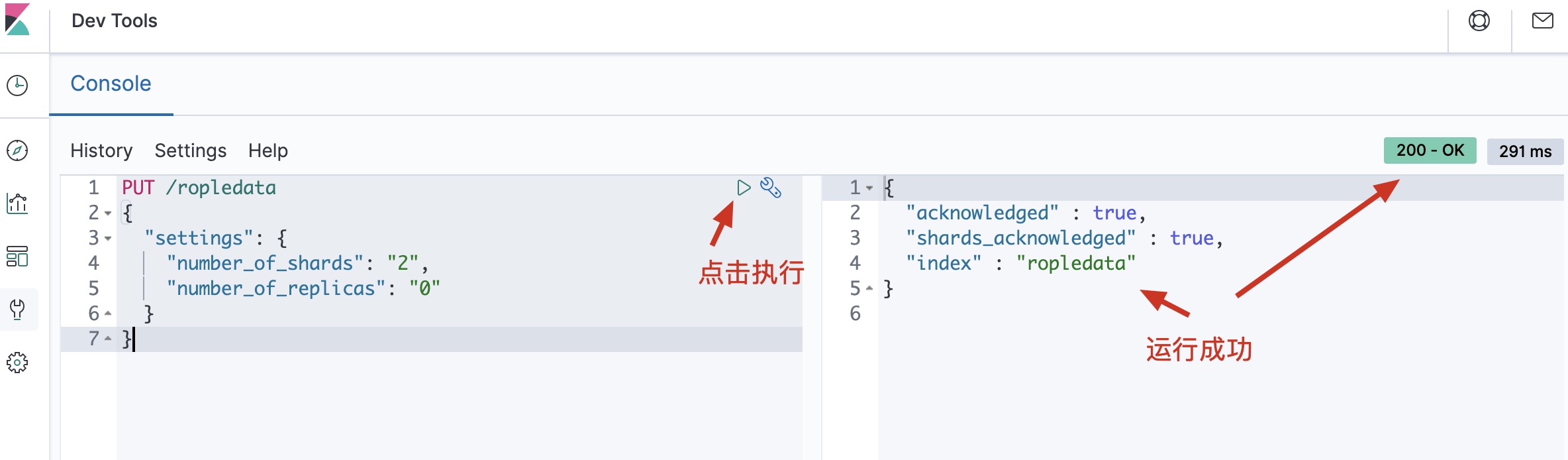
-
修改副本
咱们如果对刚才创建的索引副本数量不满意,可以进行修改,注意:分片不允许修改。
PUT ropledata/_settings { "number_of_replicas" : "2" }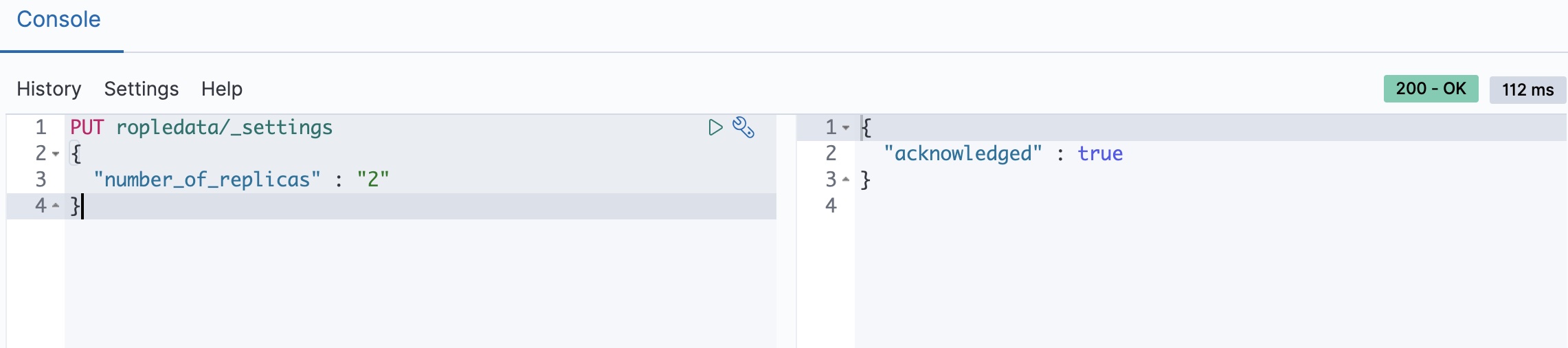
-
删除索引
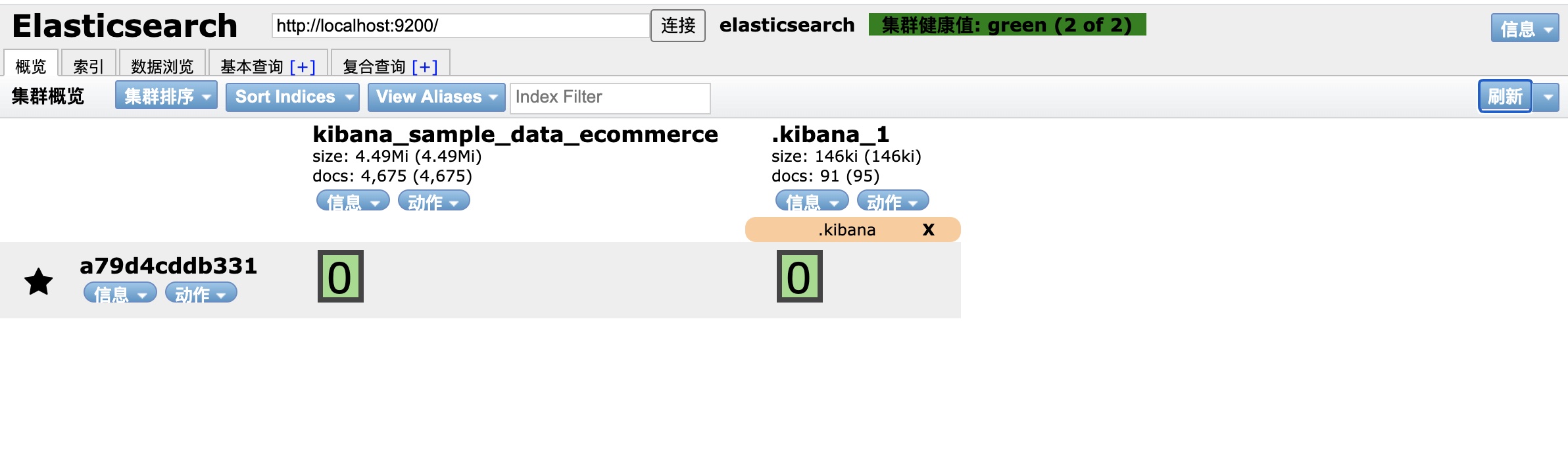
当这个索引不想用了,可以进行删除,执行如下命令即可,执行成功后,刷新ElasticSearch Head可以看到刚才创建的ropledata索引消失了:
DELETE /ropledata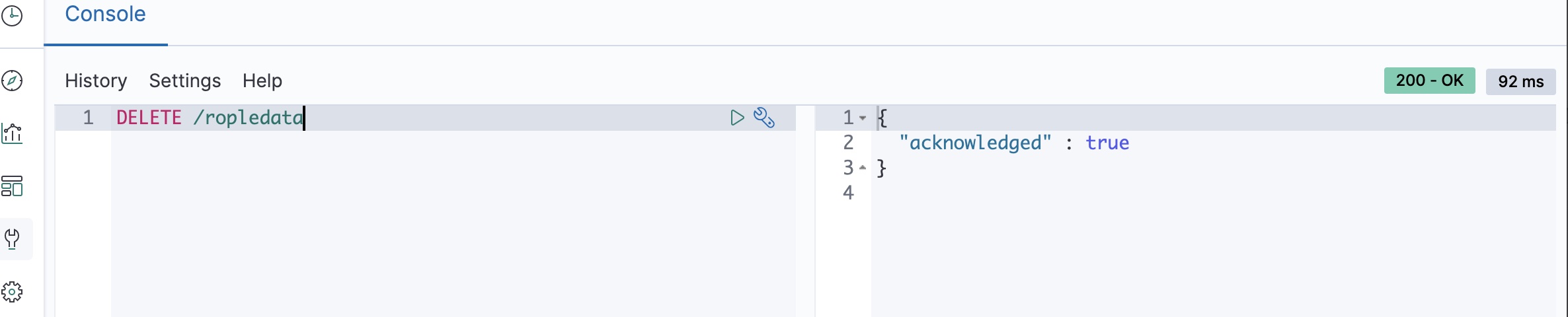
5.2、数据增删改查
-
插入数据
插入数据的时候可以指定id,如果不指定的话,ES会自动帮我们生成。我们以指定id为例,如下代码是我们创建了一个101的文档,创建成功后,可以在Elasticsearch Head的数据浏览模块里看到这些数据,代码及演示如下:
//指定id POST /ropledata/_doc/101 { "id":1, "name":"且听_风吟", "page":"https://ropledata.blog.csdn.net", "say":"欢迎点赞,收藏,关注,一起学习" }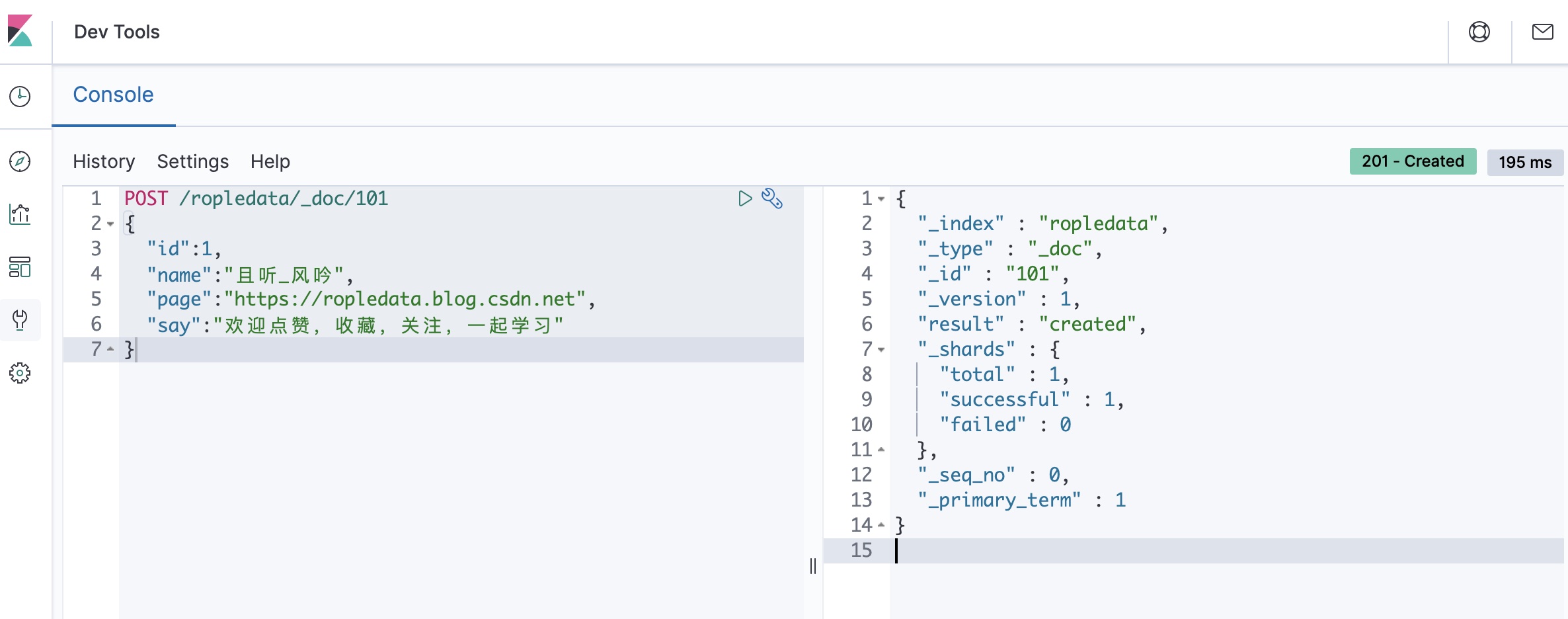
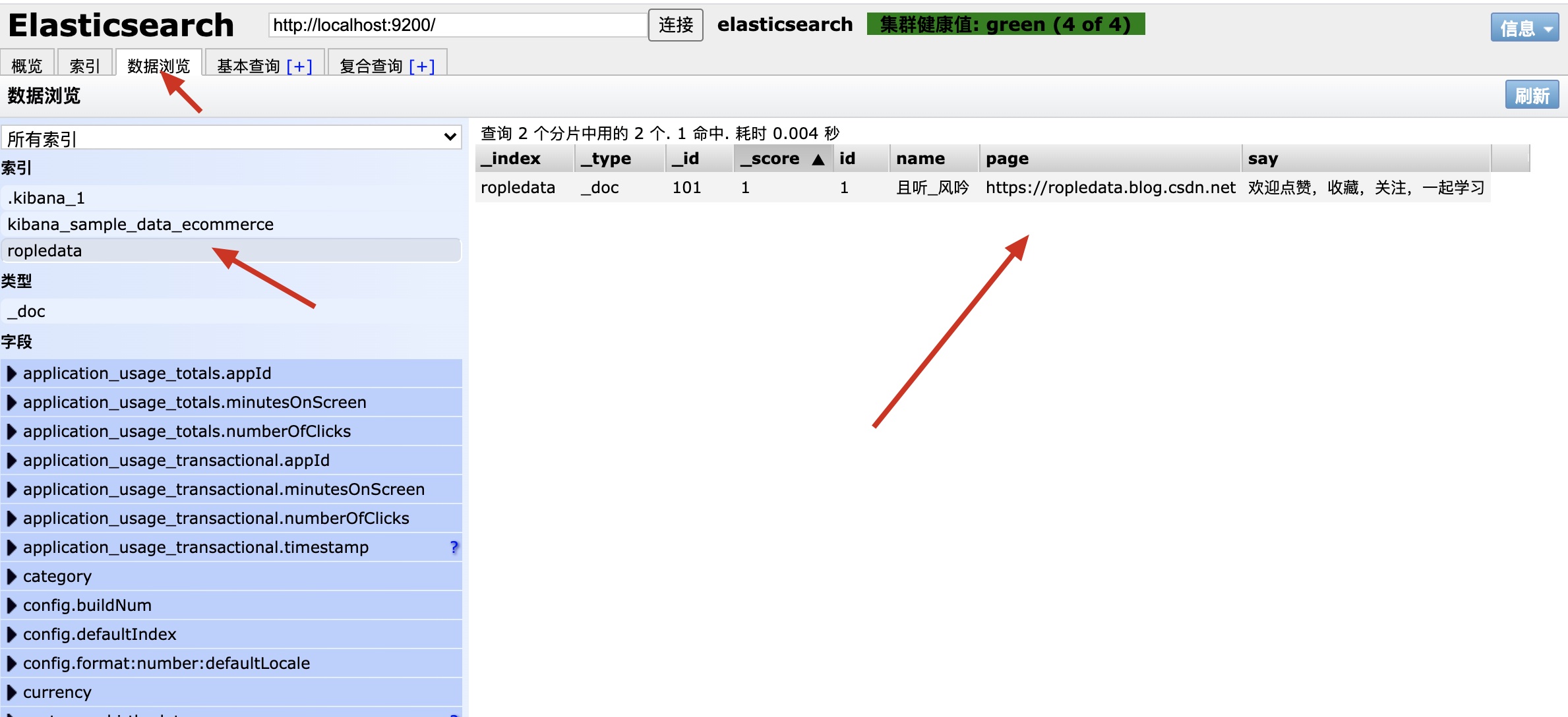
-
修改数据
这里大家要特别注意,ES里的文档是不可以修改的,但是可以覆盖,所以ES修改数据本质上是对文档的覆盖。ES对数据的修改分为全局更新和局部更新,咱们分别进行code并对比:
-
全局更新
PUT /ropledata/_doc/101 { "id":1, "name":"且听_风吟", "page":"https://ropledata.blog.csdn.net", "say":"再次欢迎点赞,收藏,关注,一起学习" }大家可以多全局更新几次,会发现每次全局更新之后这个文档的
_version都会发生改变!
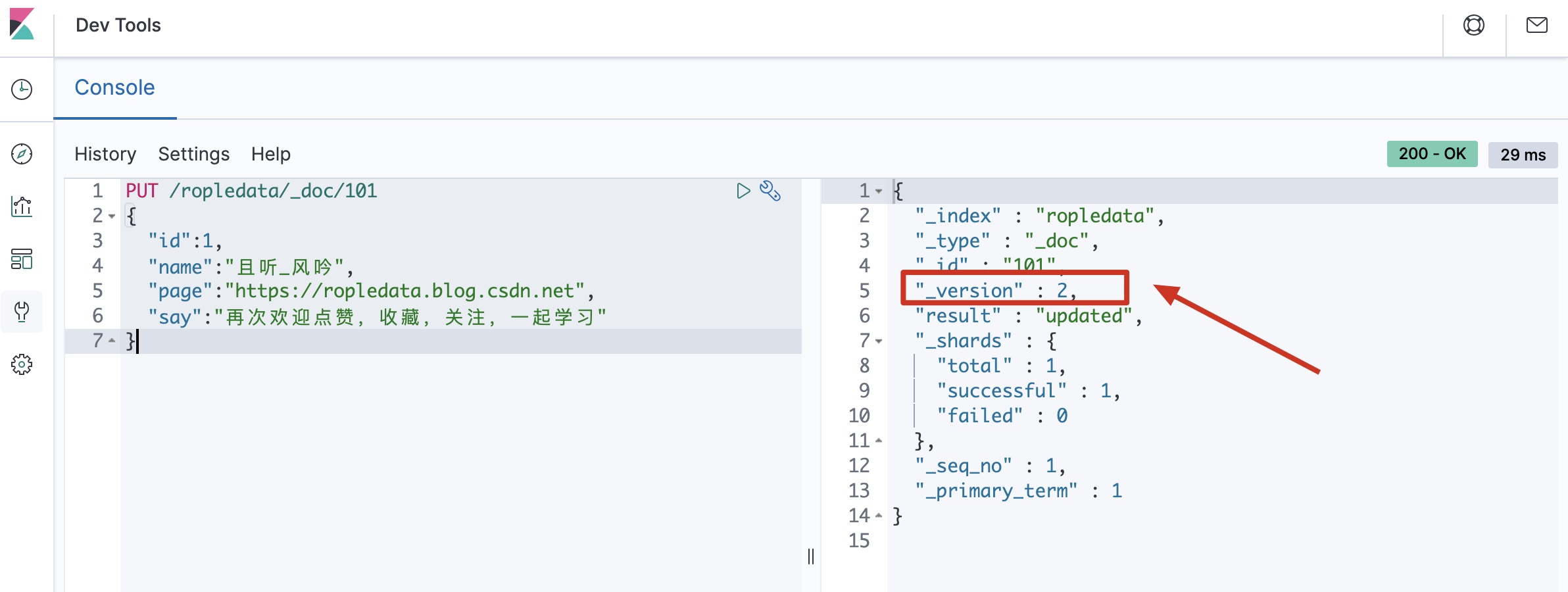
-
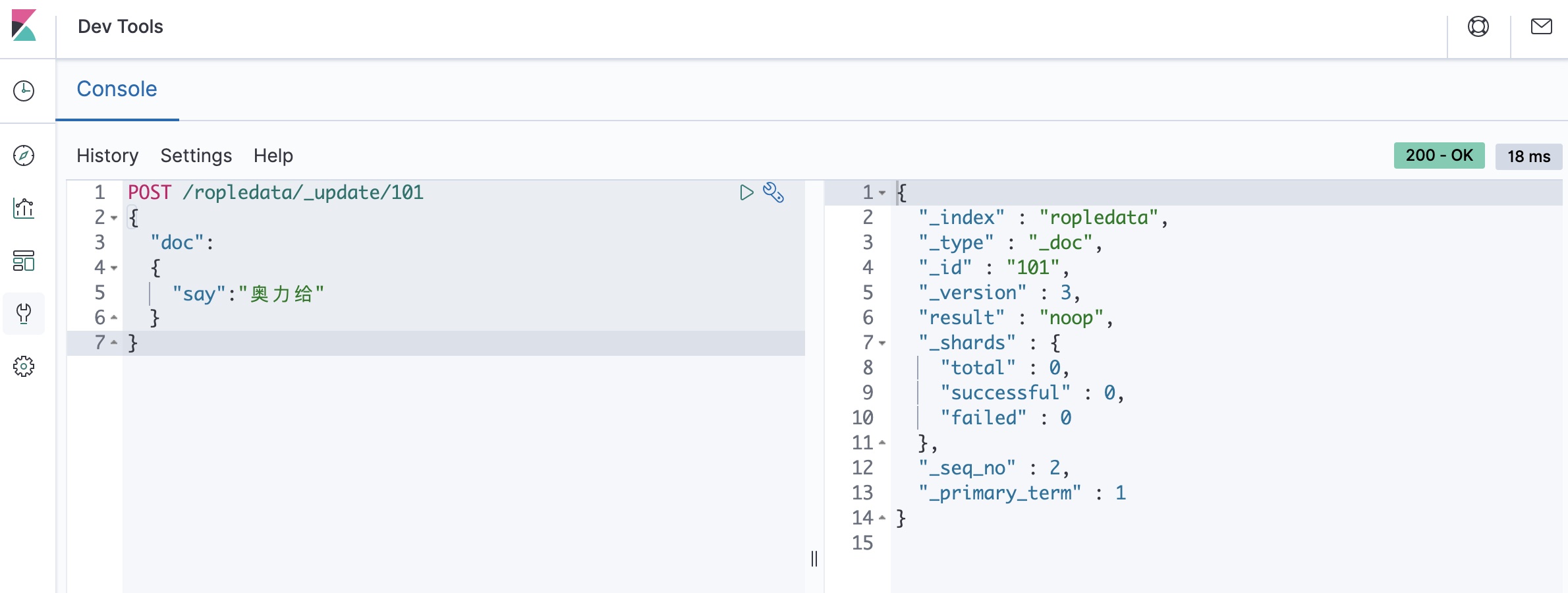
局部更新
POST /ropledata/_update/101 { "doc": { "say":"奥力给" } }这时候我们可以多次去执行上面的局部更新代码,会发现除了第一次执行,后续不管又执行了多少次,
_version都不再变化!
疑问四:局部更新的时候ES底层的流程是怎样的?和全局更新相比性能怎么样?
局部更新的底层流程:
- 内部先获取到对应的文档;
- 将传递过来的字段更新到文档的json中(这一步实质上也是一样的);
- 将老的文档标记为deleted(到一定时候才会物理删除);
- 将修改后的新的文档创建出来。
性能对比:
- 全局更新本质上是替换操作,即使内容一样也会去替换;
- 局部更新本质上是更新操作,只有遇到新的东西才更新,没有新的修改就不更新;
- 局部更新比全局更新的性能好,因此推荐使用局部更新。
-
-
查询数据
ES的数据查询知识点非常多,也非常复杂,后面我打算单独讲解演示,本文只展示最基本的根据id搜索数据的code:
GET /ropledata/_doc/101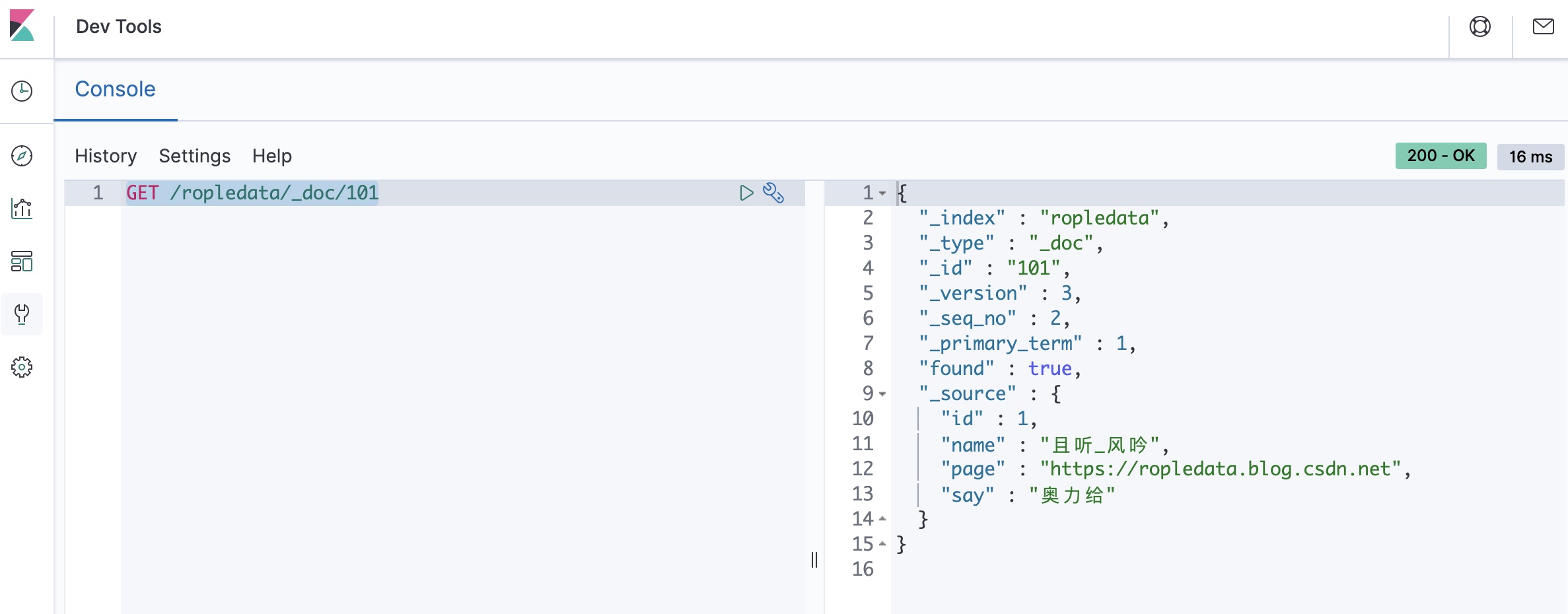
-
删除数据
比如我们想把ropledata索引下的id为101的文档删除,可以使用如下命令:
DELETE /ropledata/_doc/101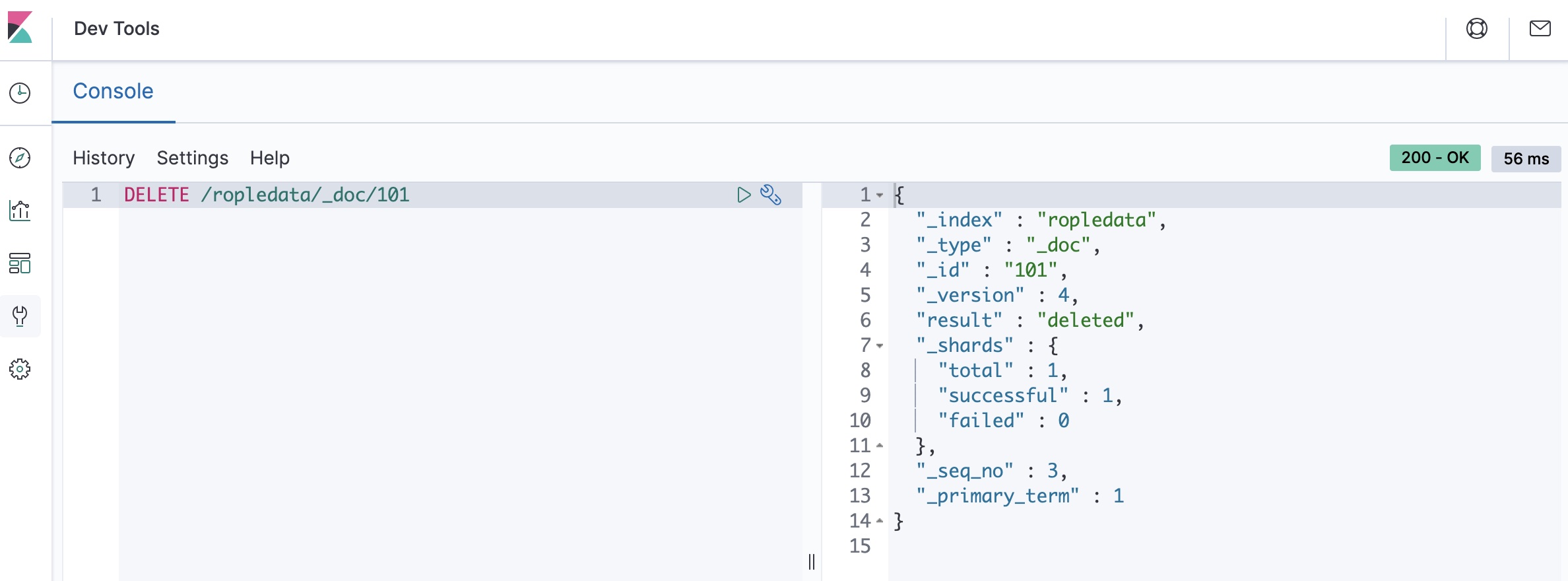
疑问五:查询或者删除的时候指定的ID是文档里面得字段id吗?
不是的,这点容易混淆,查询或者删除时候用到的ID是创建文档时候指定或者ES自动生成的那个id,而不是文档里面的那个叫
id字段!文档里面的文档字段是可以没有id的。
六、总结
本文我们对ES的基本概念进行了清晰的解释,并用最有效率的方式进行了安装配置,也对基础的增删改查进行了图文并茂的演示。掌握了这些可以说对ES已经入门了,写这篇文章的目的也已经达到了!ES还有很多复杂的查询,中文分词,倒排索引等技术点需要我们去掌握,后续我将会整理出来,咱们一起学习!
如果您对我的文章感兴趣,欢迎关注点赞收藏,如果您有疑惑或发现文中有不对的地方,还请不吝赐教,非常感谢!!
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/132540.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
