大家好,又见面了,我是你们的朋友全栈君。
RCNN的提出首次利用了CNN来提取图片特征,大大提高了检测精度。
整体思路:输入一张图片,selective search方法提取2000个proposal region,由于CNN输入图片的大小是固定的,所以需要把proposal region变成同样的大小(比如227×227),然后通过五层卷积层和两个全连接层,然后用SVM进行分类

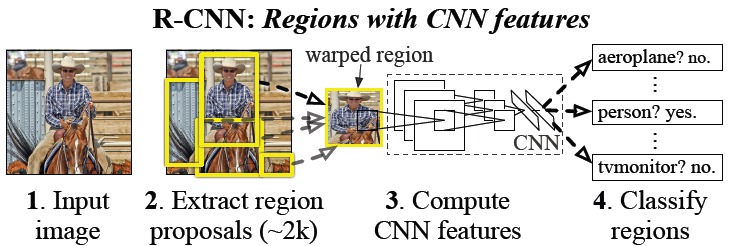
因为我们后面还要继续用这2000个候选框图片,继续训练CNN、SVM。然而人工标注的数据一张图片中就只标注了正确的bounding box,我们搜索出来的2000个矩形框也不可能会出现一个与人工标注完全匹配的候选框。因此我们需要用IOU为2000个bounding box打标签,以便下一步CNN训练使用。在CNN阶段,如果用selective search挑选出来的候选框与物体的人工标注矩形框的重叠区域IoU大于0.5,那么我们就把这个候选框标注成物体类别,否则我们就把它当做背景类别
预训练:用AlexNet在ILSVRC 2012数据集上训练提取特征。
fine-tuning:由于论文中的数据集有21类(物体类别20+1背景),因此把AlexNet最后的softmax变为21,进行训练。
SVM训练:输入是f7的特征,输出的是是否属于该类别,训练结果是得到SVM的权重矩阵W,这里负样本的选定和前面的有所不同,将IOU的阈值从0.5改成0.3,即IOU<0.3的是负样本,正样本是Ground Truth。IOU的阈值选择和前面fine-tuning不一样,主要是因为:前面fine-tuning需要大量的样本,所以设置成0.5会比较宽松。而在SVM阶段是由于SVM适用于小样本,所以设置0.3会更严格一点。
回归:用pool5的特征6*6*256维和bounding box的ground truth来训练回归
文献paper给我们证明了一个理论,如果你不进行fine-tuning,也就是你直接把Alexnet模型当做万金油使用,类似于HOG、SIFT一样做特征提取,不针对特定的任务。然后把提取的特征用于分类,结果发现p5的精度竟然跟f6、f7差不多,而且f6提取到的特征还比f7的精度略高;如果你进行fine-tuning了,那么f7、f6的提取到的特征最会训练的svm分类器的精度就会飙涨。
据此我们明白了一个道理,如果不针对特定任务进行fine-tuning,而是把CNN当做特征提取器,卷积层所学到的特征其实就是基础的共享特征提取层,就类似于SIFT算法一样,可以用于提取各种图片的特征,而f6、f7所学习到的特征是用于针对特定任务的特征。打个比方:对于人脸性别识别来说,一个CNN模型前面的卷积层所学习到的特征就类似于学习人脸共性特征,然后全连接层所学习的特征就是针对性别分类的特征了。
还有另外一个疑问:CNN训练的时候,本来就是对bounding box的物体进行识别分类训练,是一个端到端的任务,在训练的时候最后一层softmax就是分类层,那么为什么作者闲着没事干要先用CNN做特征提取(提取fc7层数据),然后再把提取的特征用于训练svm分类器?这个是因为svm训练和cnn训练过程的正负样本定义方式各有不同,导致最后采用CNN softmax输出比采用svm精度还低。
事情是这样的,cnn在训练的时候,对训练数据做了比较宽松的标注,比如一个bounding box可能只包含物体的一部分,那么我也把它标注为正样本,用于训练cnn;采用这个方法的主要原因在于因为CNN容易过拟合,所以需要大量的训练数据,所以在CNN训练阶段我们是对Bounding box的位置限制条件限制的比较松(IOU只要大于0.5都被标注为正样本了);
然而svm训练的时候,因为svm适用于少样本训练,所以对于训练样本数据的IOU要求比较严格,我们只有当bounding box把整个物体都包含进去了,我们才把它标注为物体类别,然后训练svm
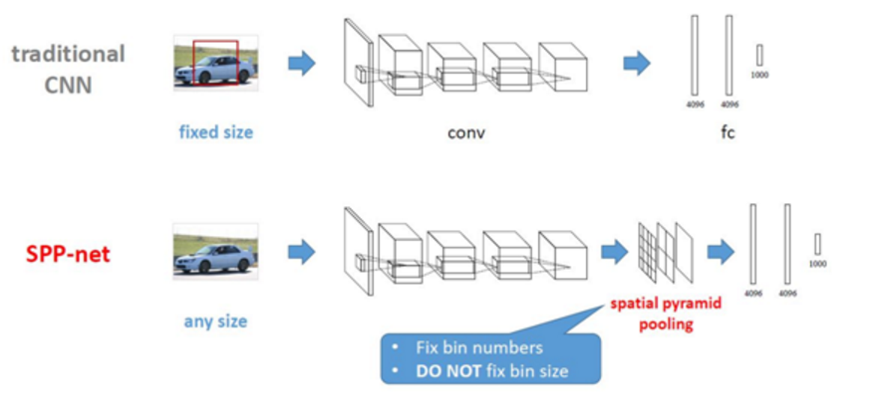
SPPnet:由于RCNN需要输入固定的大小proposal region,这样检测各种大小的图片的时候,需要经过crop,或者warp等一系列操作,这都在一定程度上导致图片信息的丢失和变形,限制了识别精确度。
那么为什么CNN要有固定大小的图片输入呢?主要是因为约束的长度来源于全连接层,因此SPP-Net在最后一个卷积层后,接入了金字塔池化层,使用这种方式,可以让网络输入任意的图片,而且还会生成固定大小的输出。
参考地址:https://blog.csdn.net/hjimce/article/details/50187029
https://blog.csdn.net/v1_vivian/article/details/73275259
https://www.cnblogs.com/gongxijun/p/7172134.html
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/132506.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
