大家好,又见面了,我是你们的朋友全栈君。
这几天在各大媒体上接触到了人工智能机器学习,觉得很有意思,于是开始入门最简单的机器算法——神经网络训练算法(Neural Network Training);以前一直觉得机器学习很高深,到处是超高等数学、线性代数、数理统计。入坑发现确实是这样!但是呢由项目实例驱动的学习比起为考试不挂科为目的的学习更为高效、实用!在遗传算法、神经网络算法的学习入门之后觉得数学只要用心看没问题的(即使是蒙特卡洛和马尔科夫问题),但是呢需要把数学统计应用到程序中,来解决实际的问题这是两码事。主要呢还是需要动手打代码。下面呢是今天的机器学习之神经网络学习入门记录篇,希望帮助到同样入门采坑的哥们,一起进步!
一、主题闲扯
神经网络学习-顾名思义,就是类似我们人类的学习方式,通过模拟神经元的活动,在神经系统中进行信息处理、存储记忆和反馈的生物机理功能。其实这样是机器学习算法的共性吧,所有的智能算法都是善于发现生活中的常见情节推广到计算仿真的范畴,例如:遗传算法、烟花算法、蚁群算法、模拟退火算法等等。
神经网络学习是人工智能领域的基本算法之一,它是在1943年被心理学家McCulloch和数学家Pitts合作提出的数学模型。并在之后不断完善发展到今天的。它的主要应用领域涉及到模式识别、智能机器人、非线性系统识别、知识处理等。
二、算法理论
2.1、人工神经元模型
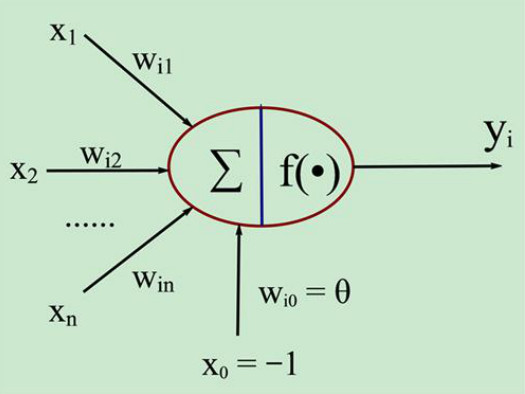

这里我们先解释一下机器学习的一些特性,总体来说呢,机器学习的核心就是学习。这个学习过程呢就是通过已知来训练机器。比如:我们通过大量的青蛙图像数据样本来进行输入训练算法,使得我们给这个程序算法一张新的青蛙图像,它能利用训练数据的学习来判断我们新给它的图像数据是青蛙。所以呢,机器学习算法来说就是通过输入变量到算法,算法通过分析反馈进行判断,最后做出结果。
在上图中是简化的神经元模型,我们的Xi是一系列的输入变量,对应在其箭头方向上的是一个权重系数。权重系数呢是为了消除样本数据的偏差,通常是一个rand函数在0-1之间的取值。通过输入变量Xi和其自己的权重系数Wi的乘积的求和输入到神经元上。此时神经元得到了输入变量和其权重的乘积累加和。通过**映射函数F(x)**来进行映射得到结果。以上就是一个简单的神经元模型和信息传递过程。
也可以简化成下面的数学推导公式:我们可以把输入变量和对应权重变换成矩阵相乘,这在Matlab中的运算时是十分有利的。
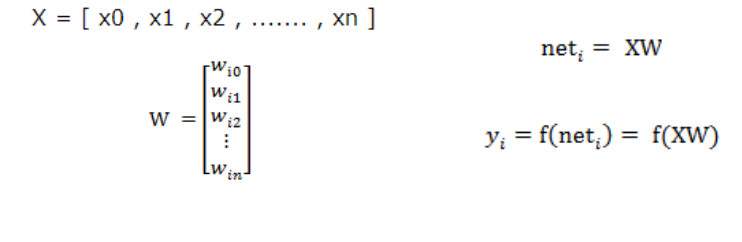
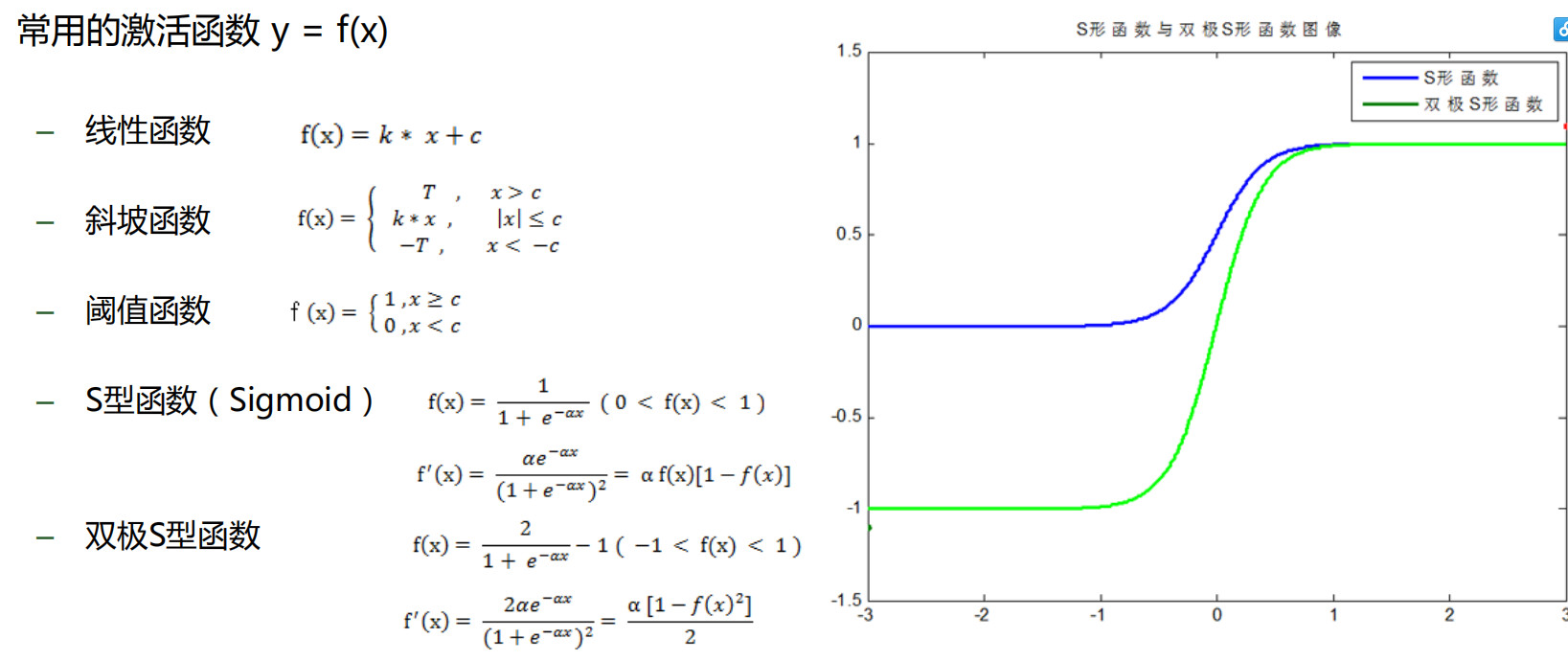
对于以上的输入变量和对应权重值我们很容易处理,但是这个模型的核心是基于激活函数F(x)的,下面是我们常见的一些激活函数:
2.2、神经网络模型
我们的神经网络是由若干的神经元连接而成的,我们常见的模型分类为:
1、连接方式:前向神经网络和递归神经网络*(反馈神经网络)
2、训练方式:监督式学习和非监督式学习
3、按照实现功能:拟合(回归)神经网络 vs. 分类神经网络
2.3、BP(反向传递)神经网络概述:
概述、
1、Backpropagation is a common method of teaching artificial neural networks how to
perform a given task.
2、It is a supervised learning method, and is a generalization of the delta rule. It
requires a teacher that knows, or can calculate, the desired output for any input in
the training set.
3、 Backpropagation requires that the activation function used by the artificial neurons
(or “nodes”) be differentiable
算法学习过程
Phase 1:神经传递
- 通过神经网络进行训练模式输入的向前传播以产生传播的输出激活。
- 训练模式中通过神经网络对传播的输出激活进行反向传播,目标是生成所有输出和隐藏神经元的增量以便进行反馈调整。
Phase 2: 权值更新 - 用它的输出增量和输入激活变量来得到权重的梯度。
- 通过从权重中减去它的比例来使权重朝着相反的梯度方向移动(最小梯度法)。
算法递进过程图解:(Source:)
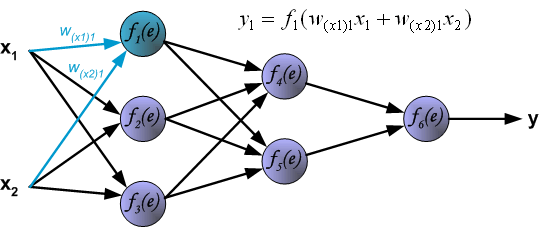
该项目描述了利用反向传播算法实现多层神经网络的教学过程。为了说明这一过程,有两个输入和一个输出的三层神经网络,如下图所示:

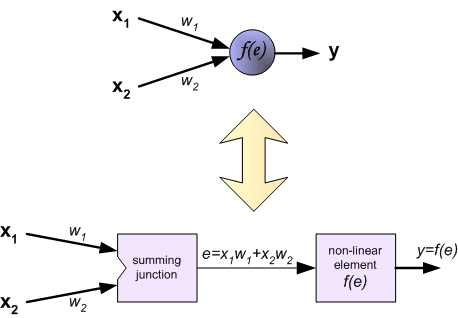
1、每个神经元由两个单位组成。第一个单元添加权重系数和输入信号,第二个单元实现非线性功能,称为神经元激活功能。信号e是加法器输出信号,y=f(e)是非线性元件的输出信号。信号y也是神经元的输出信号。如下图:
**2、**为了训练神经网络,我们需要训练数据集。训练数据集由输入信号(x1和x2)组成,并分配相应的目标(期望输出)z。网络训练是一个迭代的过程。在每个迭代中权重系数的节点使用新的训练数据集的数据被修改。修改计算使用下面描述的算法:每个教学步骤开始迫使这两个输入信号从训练集,在这个阶段我们可以确定每个网络层中的每个神经元的输出信号值。下面的图片说明了信号是如何传播的。
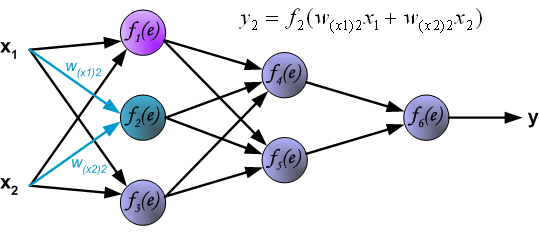
同理如下:
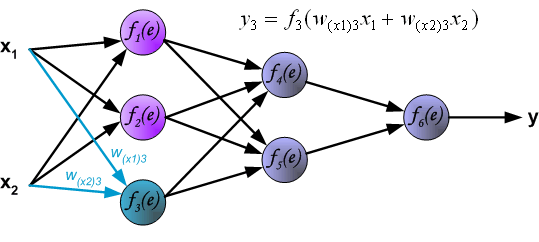
**3、**通过隐藏层传播信号。符号wmn表示下一层神经元的输出和神经元n的输入之间的连接。
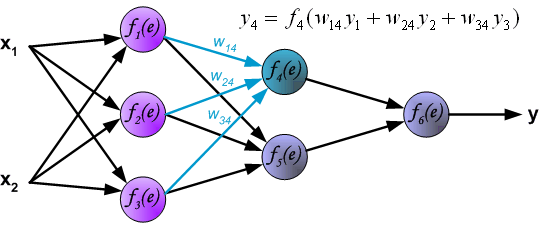
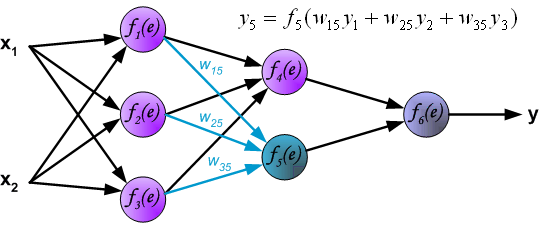
**4、**通过输出层传播信号
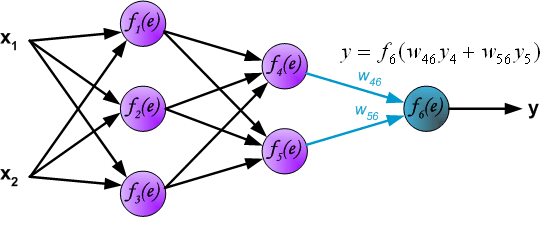
**5、**在接下来的算法步骤中,将网络y的输出信号与期望的输出值(目标)进行比较,在训练数据集中找到了输出信号。这种差异被称为输出层神经元的错误信号d。
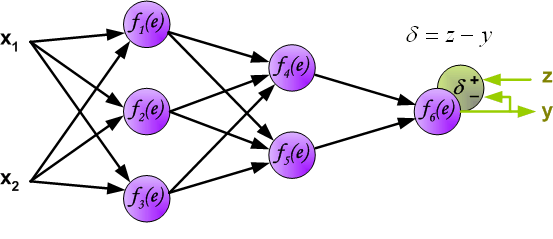
6、直接计算内部神经元的错误信号是不可能的,因为这些神经元的输出值是未知的。多年来,多人网络训练的有效方法一直是未知的。只有在80年代中期,反向传播算法才被设计出来。这个想法是将错误信号d(在单个教学步骤中计算)返回给所有神经元,输出信号是被讨论神经元的输入信号。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-AAqp7IzE-1641367604580)(http://galaxy.agh.edu.pl/~vlsi/AI/backp_t_en/backprop_files/img09.gif)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UMRWhiSF-1641367604580)(http://galaxy.agh.edu.pl/~vlsi/AI/backp_t_en/backprop_files/img10.gif)]
7、用于传播错误的权重系数,等于在计算输出值时使用的系数。只有数据流的方向被改变(信号从一个输出到另一个输入)。该技术适用于所有网络层。如果传播错误来自少数神经元,它们就会被添加。下面的例子是:
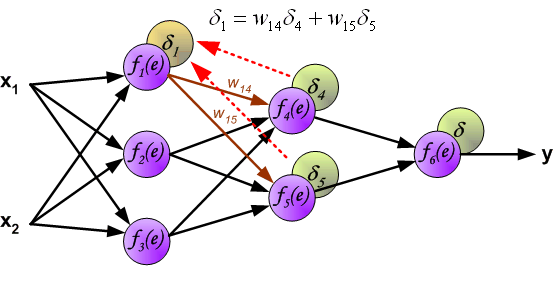
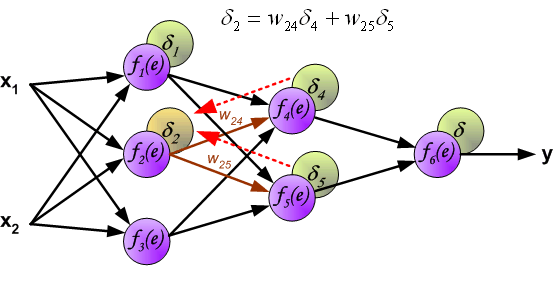
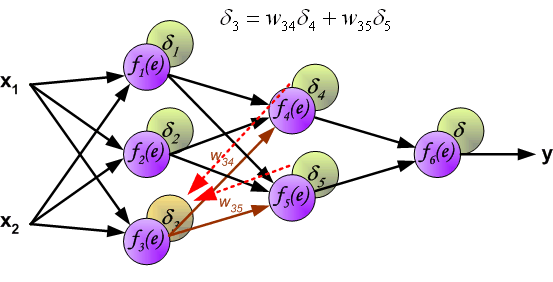
8、当计算每个神经元的错误信号时,可以修改每个神经元输入节点的权重系数。在下面的公式中,df(e)/de代表了神经元激活功能的导数(权重被修改)。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-AQAtpMCB-1641367604581)(http://galaxy.agh.edu.pl/~vlsi/AI/backp_t_en/backprop_files/img14.gif)]
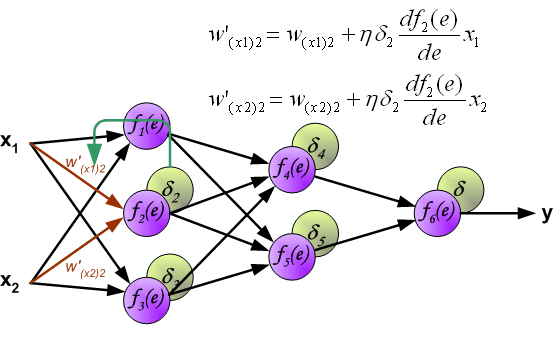
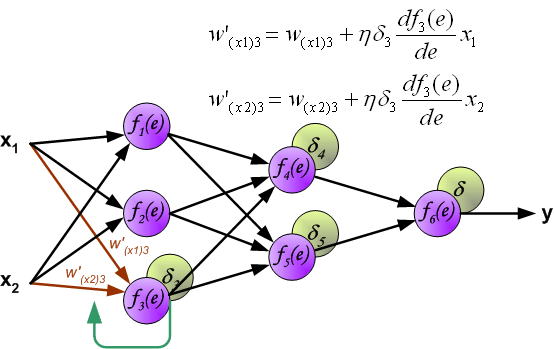
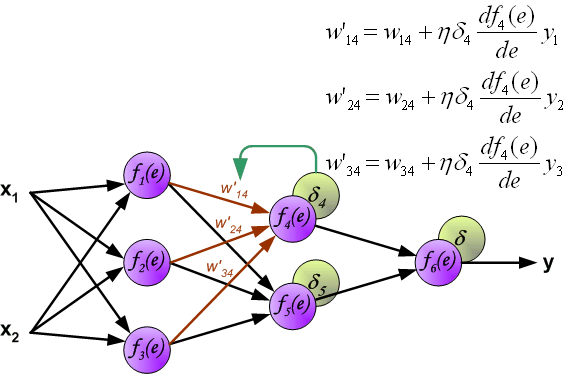
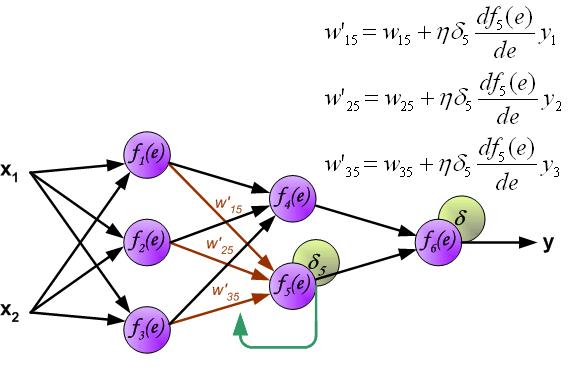
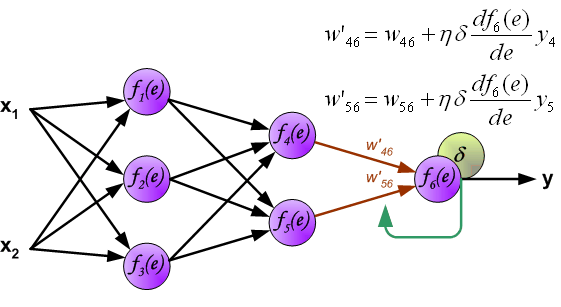
8、系数h(罗马字符学习因子)影响网络训练速度。有一些技术可以选择这个参数。第一种方法是用参数的大值开始教学过程。当权重系数被确定时,参数正逐渐减少。第二种,更复杂的方法,开始以小的参数值教学。在教学过程中,在教学过程中,在教学过程中增加了参数,在最后阶段又减少了。以较低的参数值启动教学过程,可以确定权重系数的符号。
插入重点:有导师学习的神经网络状态:
有导师学习状态简而言之就是对输入的训练集,可以根据网络中的实际输出与期望输出之间的误差来反向调整个连接权值的学习方法。其主要步骤如下:
- 从样本数据中随机性的选取一个样本数据{Ai,Bi},其中Ai是输出,Bi是期望输出
- 通过训练得出实际输出Oi
- 求误差D = Bi – Oi
- 根据步骤3得到的误差D,来调整各隐含层之间连接权值
- 对,每个样本重复用以上步骤,直到对整体样本数据来说,误差收敛到控制范围内为止。
有导师学习算法:Delta学习规则
Delta是一种简单的经典有导师算法规则。根据实际输出与期望输出的差别;来调整连接权。其数学表达:
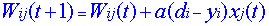
在上述公式中,Wij表示的是神经元 i 到 j之间的连接权。di是神经元i的期望输出;Yi是神经元 i 的实际输出****。Xj是神经元的状态。,如果是激活状态则为1,否则为0或者**-1**。
通过神经元j的实际输出与期望值比较取值,我们可以知道Delta的本质,就是如果实际输出大于期望输出(di – yi)为负数,就是减小所有输入为正的连接权值。增大输入为负的权值。反之,如果实际输出小与期望输出。则增大输入为正的连接权值,减小输入为负的连接权值。
2.4、数据归一化
什么是归一化?
将数据映射到[0, 1]或[-1, 1]区间或其他的区间。
为什么要归一化?
- 输入数据的单位不一样,有些数据的范围可能特别大,导致的结果是神经网络收敛慢、训练时间长。
- 数据范围大的输入在模式分类中的作用可能会偏大,而数据范围小的输入作用就可能会偏小。
- 由于神经网络输出层的激活函数的值域是有限制的,因此需要将网络训练的目标数据映射到激活函数的值域。例如神经网络的输出层若采用S形激活函数,由于S形函数的值域限制在(0,1),也就是说神经网络的输出只能限制在(0,1),所以训练数据的输出就要归一化到[0,1]区间。
- S形激活函数在(0,1)区间以外区域很平缓,区分度太小。例如S形函数f(X)在参数a=1时,f(100)与f(5)只相差0.0067
归一化算法
1、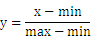
其中min为x的最小值,max为x的最大值,输入向量为x,归一化后的输出向量为y。上式将数据归一化得到[0,1]区间,当激活函数采用S形函数时(值域为(0,1))时这条公式适用。
2、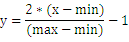
这条公式将数据归一化到[-1, 1]区间。当激活函数采用双极S形函数(值域为(-1,1))时,该公式适用。
归一化算法重点知识函数:
几个要说明的函数接口:
[Y,PS] = mapminmax(X)
[Y,PS] = mapminmax(X,FP)
Y = mapminmax('apply',X,PS)
X = mapminmax('reverse',Y,PS)
用实例来讲解,测试数据 x1 = [1 2 4], x2 = [5 2 3];
>> [y,ps] = mapminmax(x1)
y =
-1.0000 -0.3333 1.0000
ps =
name: 'mapminmax'
xrows: 1
xmax: 4
xmin: 1
xrange: 3
yrows: 1
ymax: 1
ymin: -1
yrange: 2
其中y是对进行某种规范化后得到的数据,这种规范化的映射记录在结构体ps中.让我们来看一下这个规范化的映射到底是怎样的?
y = (ymax-ymin)*(x-xmin)/(xmax-xmin) + ymin;
[关于此算法的一个问题.算法的假设是每一行的元素都不想相同,那如果都相同怎么办?实现的办法是,如果有一行的元素都相同比如xt = [1 1 1],此时xmax = xmin = 1,把此时的变换变为y = ymin,matlab内部就是这么解决的.否则该除以0了,没有意义!]
也就是说对x1 = [1 2 4]采用这个映射 f: 2*(x-xmin)/(xmax-xmin)+(-1),就可以得到y = [ -1.0000 -0.3333 1.0000]
我们来看一下是不是: 对于x1而言 xmin = 1,xmax = 4;
则y(1) = 2*(1 – 1)/(4-1)+(-1) = -1;
y(2) = 2*(2 – 1)/(4-1)+(-1) = -1/3 = -0.3333;
y(3) = 2*(4-1)/(4-1)+(-1) = 1;
看来的确就是这个映射来实现的.
对于上面algorithm中的映射函数 其中ymin,和ymax是参数,可以自己设定,默认为-1,1;
比如:
>>[y,ps] = mapminmax(x1);
>> ps.ymin = 0;
>> [y,ps] = mapminmax(x1,ps)
y =
0 0.3333 1.0000
ps =
name: 'mapminmax'
xrows: 1
xmax: 4
xmin: 1
xrange: 3
yrows: 1
ymax: 1
ymin: 0
yrange: 1
则此时的映射函数为: f: 1*(x-xmin)/(xmax-xmin)+(0)
如果我对x1 = [1 2 4]采用了某种规范化的方式, 现在我要对x2 = [5 2 3]采用同样的规范化方式[同样的映射],如下可办到:
>> [y1,ps] = mapminmax(x1);
>> y2 = mapminmax('apply',x2,ps)
y2 =
1.6667 -0.3333 0.3333
即对x1采用的规范化映射为: f: 2*(x-1)/(4-1)+(-1),(记录在ps中),对x2也要采取这个映射.
x2 = [5,2,3],用这个映射我们来算一下.
y2(1) = 2(5-1)/(4-1)+(-1) = 5/3 = 1+2/3 = 1.66667
y2(2) = 2(2-1)/(4-1)+(-1) = -1/3 = -0.3333
y2(3) = 2(3-1)/(4-1)+(-1) = 1/3 = 0.3333
X = mapminmax(‘reverse’,Y,PS)的作用就是进行反归一化,讲归一化的数据反归一化再得到原来的数据:
>> [y1,ps] = mapminmax(x1);
>> xt = mapminmax('reverse',y1,ps)
xt =
1 2 4
此时又得到了原来的x1(xt = x1);
**
三、神经网络参数定义以及对BP神经网络性能的影响
**
常见的训练函数:
训练方法 训练函数
梯度下降法 traingd
有动量的梯度下降法 traingdm
自适应lr梯度下降法 traingda
自适应lr动量梯度下降法 traingdx
弹性梯度下降法 trainrp
Fletcher-Reeves共轭梯度法 traincgf
Ploak-Ribiere共轭梯度法 traincgp
Powell-Beale共轭梯度法 traincgb
量化共轭梯度法 trainscg
拟牛顿算法 trainbfg
一步正割算法 trainoss
Levenberg-Marquardt trainlm
神经网路学习的参数:
训练参数 参数介绍
net.trainParam.epochs 最大训练次数(缺省为10)
net.trainParam.goal 训练要求精度(缺省为0)
net.trainParam.lr 学习率(缺省为0.01)
net.trainParam.max_fail 最大失败次数(缺省为5)
net.trainParam.min_grad 最小梯度要求(缺省为1e-10)
net.trainParam.show 显示训练迭代过程(NaN表示不显示,缺省为25)
net.trainParam.time 最大训练时间(缺省为inf)
net.trainParam.mc 动量因子(缺省0.9)
net.trainParam.lr_inc 学习率lr增长比(缺省为1.05)
net.trainParam.lr_dec 学习率lr下降比(缺省为0.7)
net.trainParam.max_perf_inc 表现函数增加最大比(缺省为1.04)
net.trainParam.delt_inc 权值变化增加量(缺省为1.2)
net.trainParam.delt_dec 权值变化减小量(缺省为0.5)
net.trainParam.delt0 初始权值变化(缺省为0.07)
net.trainParam.deltamax 权值变化最大值(缺省为50.0)
net.trainParam.searchFcn 一维线性搜索方法(缺省为srchcha)
net.trainParam.sigma 因为二次求导对权值调整的影响参数(缺省值5.0e-5)
net.trainParam.lambda Hessian矩阵不确定性调节参数(缺省为5.0e-7)
net.trainParam.men_reduc 控制计算机内存/速度的参量,内存较大设为1,否则设为2(缺省为1)
net.trainParam.mu u的初始值(缺省为0.001)
net.trainParam.mu_dec u的减小率(缺省为0.1)
net.trainParam.mu_inc u的增长率(缺省为10)
net.trainParam.mu_max u的最大值(缺省为1e10)
神经网络学习主要函数说明
newff:前馈网络创建函数
语法:
net = newff(A,B,{C},‘trainFun’,‘BLF’,‘PF’)。
A:一个n*2的矩阵,第i行元素为输入信号Xi的最大最小值
B:一个K维行向量,其元素为网络中各个节点的数量。
C:一个K维字符串行向量,每一个分量为对应层的神经元的激活函数,默认为“tansig”
trainFun:为学习规则的采用的训练算法。默认为:“trainlm”
BLF:BP权值/偏差学习函数。默认为:“learngdm”
PF:性能函数,默认为“mse”
train函数
语法:
即网络学习函数:
[net,tr,YI,E] = train(net,X,Y)
X:网络实际输入
Y:网络应有输出
tr:网络跟踪信息
YI:网络实际输出
E:误差矩阵
sim函数
**语法:**Y = sim(net,X)
X:输入给网络的KN矩阵,K为网络输入个数,N为样本数据量
Y:输出矩阵QN,其中Q为网络输出个数
四、实例解读:
利用三层BP神经网络来完成非线性函数的逼近任务,其中隐层神经元个数为五个。
样本数据:

代码如下:
clear;
clc;
X=-1:0.1:1;
D=[-0.9602 -0.5770 -0.0729 0.3771 0.6405 0.6600 0.4609...
0.1336 -0.2013 -0.4344 -0.5000 -0.3930 -0.1647 -.0988...
0.3072 0.3960 0.3449 0.1816 -0.312 -0.2189 -0.3201];
figure;
plot(X,D,'*'); %绘制原始数据分布图
net = newff([-1 1],[5 1],{'tansig','tansig'});
net.trainParam.epochs = 100; %训练的最大次数
net.trainParam.goal = 0.005; %全局最小误差
net = train(net,X,D);
O = sim(net,X);
figure;
plot(X,D,'*',X,O); %绘制训练后得到的结果和误差曲线
V = net.iw{1,1}%输入层到中间层权值
theta1 = net.b{1}%中间层各神经元阈值
W = net.lw{2,1}%中间层到输出层权值
theta2 = net.b{2}%输出层各神经元阈值
最后得到结果:
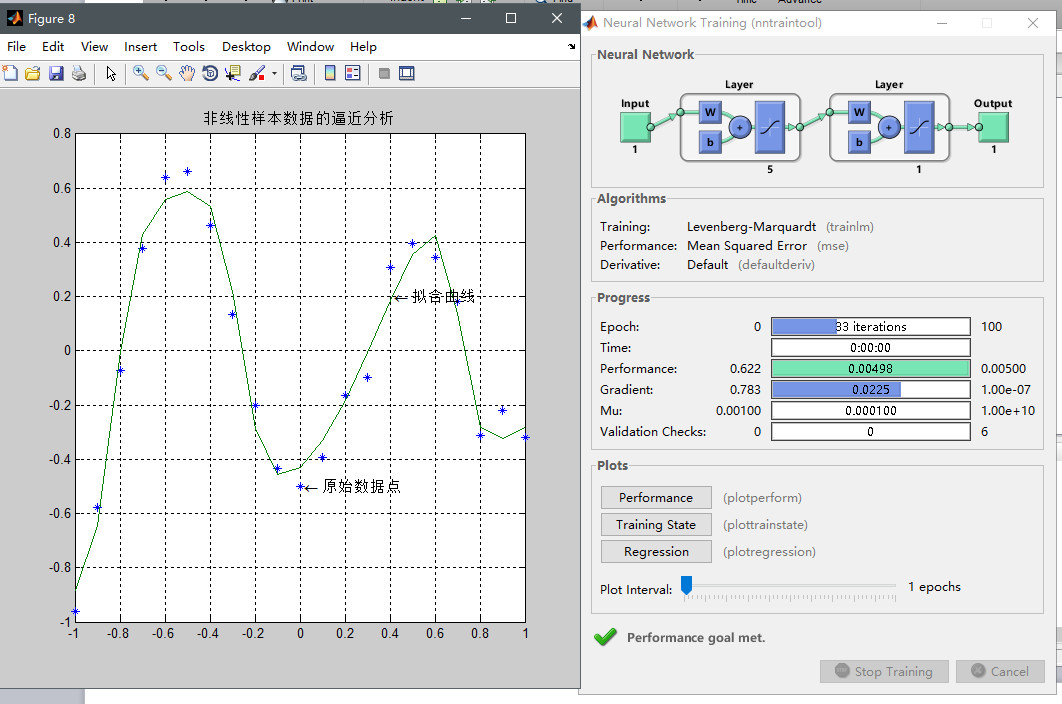
**
五、学习总结
**
通过神经网络的学习入门,发现机器学习的共性和乐趣;由浅入深、循序渐进。虽然看起来很是晦涩难懂。但是一门心思钻进去,最后做出实例是一种巨大的喜悦和自豪。从中得到知识的喜悦和探索规律的满足。
总结神经网络:
1、导入需要处理的数据。
2、对数据进行打乱,随机获取实验数据和目标数据。(其中包括归一化:mapminmax)
3、构建一个训练网络:newwff
4、对构建的网络进行训练:train
5、进行数据仿真操作sin(net,x)
6、验证和后评价
7、绘图直观的显示数据模拟训练的效果。
在上面的神经网络训练中,我们要清楚构建神经网络的实验数据和目标收敛数据都是从原始数据中随机获取的。
**By:wangyun 2018-01-28 11:01:57**
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/132500.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
