大家好,又见面了,我是你们的朋友全栈君。
更新:
AI时代已经到了,各位小伙伴如果还有类似的需求,现在已经有很成熟的免费OCR库了,不用再挖古董文章了,钻研精神要保持,但也不用处处自己造轮子了哦
要做实时OCR扫描的可以参考
Google ML:
https://developers.google.com/ml-kit/language/translation
PaddleOCR:
https://github.com/PaddlePaddle/PaddleOCR
遇到一个需求,要用手机扫描纸质面单,获取面单上的手机号,最后决定用tesseract这个开源OCR库,移植到Android平台是tess-two
Android平台tess-two地址:https://github.com/tesseract-ocr
我把手机号扫描的算法封装了一下,Demo地址:http://blog.csdn.net/mr_sk/article/details/79077271
评论里有人想要我训练的数字字库,这里贴出来(只训练了 黑体、微软雅黑、宋体 0-9的数字,其他字体识别率会降低)
数字字库地址:http://download.csdn.net/download/mr_sk/10186145 (现在上传资源好像不能免费下载了,至少要收两个积分…)
这篇博客主要是记录我的思路,大多是散乱的笔记,所以大家遇到报错什么的不要急,看看demo和Log总能找到问题
我遇到的坑(只想了解用法的可以跳过)
Tesseract虽然是个很强大的库,但直接使用的话,并不适用于连续识别的需求,因为tess-two对解析图像的清晰度和文字规范度有很高的要求,用相机随便获取的一张预览图扫出来错误率非常高(如果用电脑截图文字区域,识别很高),手写的就更不用说了,几乎全是乱码,而且识别速度很慢,一张200*300的图片都要好几秒
所以在没有优化的情况下,直接用tess-two 来作文字识别,只能是拍一张照,然后等待识别结果,比如识别文章、扫描身份证等,如果像我的需求,需要识别面单上的手机号,可能一分钟需要扫描几十个手机号,那就必须要达到毫秒级的解析速度,直接使用常规的方法肯定是不行的,那怎么办呢?
tess-two的识别算法当然是没办法处理了,那就得从其他方面去想办法
第一个:是在字库方面,官方的一个英文字库 30M,但是你面临的需求需要这么重量级的字库吗?比如我扫描手机号的功能,面单上都是黑体字,手机号只有纯数字, 就这么点识别范围去检索一个30M的字库,显然多了很多无用功
解决办法就是:
训练自己的字库,如果你需要毫秒级的扫描速度,那你的需求涉及的扫描内容 范围一定很小(前面说过,如果你要做文章识别之类的,那就用官方字库,拍一张照片,等几秒钟,完全是可以接受的),这样就可以根据需求范围内 常见的 ”字体“ 和 ”字符“来训练专门的字库,这样你就能使用一个轻量级的定制字库,极大的减少了解析时间,比如我手机号的数字子库,只有100KB,识别我处理后的图片,从官方字库的1.5-3秒,减少到了300-500ms
字库训练 详情参考https://www.cnblogs.com/cnlian/p/5765871.html
第二个: 就是在把图片交给tess-two解析之前,先进行简单的内容过滤,如上面所说的,即便是我把一张图片的解析速度压缩到了300-500ms,依然存在一个问题,那就是识别频率,要做连续扫描,相机肯定是一直开着的,那一秒钟几十帧的图片,你该解析哪一张呢?
每一张都解析的话,对性能是很大的消耗,也要考虑一些用低端机的用户,而且每次解析的时间不等,识别结果也很混乱,那就只有每次取一帧解析,拿到解析结果后,再去解析下一帧那么问题又来了:相机一秒几十帧,一打开相机,第一帧就开始解析了,这样下一次开始解析就在300-500ms之后了,如果用户在对准手机号的前一刻,正好开始了一帧画面的解析,那等到开始解析手机号,至少也在几百毫秒以后了,加上手机号本身的解析时间,从对准到拿到结果,随随便便就超过了1秒,加上每次识别速度不定,可能特殊情况耗时更久,这样必然会感到很明显的延迟,那该怎么处理呢?
解决办法就是:
在图片交给tess-two之前,先进行图片二级裁切,第一次裁切就是利用界面的扫描框,拿到需要扫描的区域,然后进行内容过滤,把明显不可能包含手机号的图像直接忽略,不进行解析,这个过程需要遍历图片的像素,用jni处理时间不超过10ms,即便是用java处理,也只有10-50ms,只要能忽略大部分的无用的图像,那就解决了这个延迟的问题,并且在过滤的同时,如果被判断为有用图片,那就能同时拿到需要解析的文字块,然后进行第二次裁切,拿到更小的图片,进一步提升解析速度至于过滤的方式,我写了针对手机号的过滤,在文章最下面的单行文本优化方案部分,有相似需求的可以看看,然后针对自己的需求,来写过滤算法
至于最后扫描的内容的提取,可以用正则公式来筛选关键信息如:手机号、网址、邮箱、身份证、银行卡号 等
Demo截图
图一


图二

图三
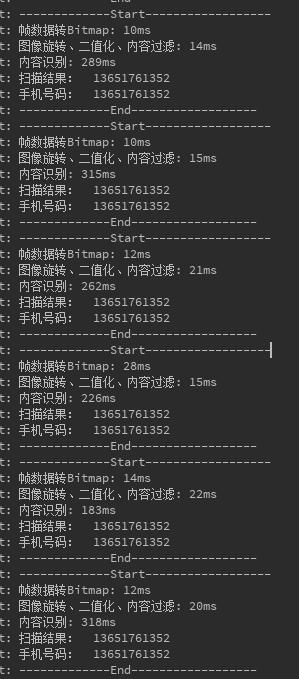
水印清除
图四

图五

**图一:**是扫描线没有对准手机号码,未捕捉到手机号的状态,这种状态下,每一帧都会在10-30ms之内被确定扫描线没有对准一个手机号而被过滤掉,不交给tess-two解析,直接放弃这一帧数据
**图二:**是扫描线对准了手机号,经过过滤算法后,捕捉到一个包含11位字符的蚊子块,基本确认存在手机号
**图三:**是 图二 状态下的识别结果
**图四:**是被水印干扰的手机号所得到的二值化图片
**图五:**是清除水印后取到的手机号区域(只适用于图五这种文字底部的干扰)
tess-two基本使用
这里是基本用法,我最早写的,效率不高但代码易读,是tess-two的使用方法,识别还是有明显延迟,优化方案我放在了文章后面的优化部分,Demo也更新了最新的优化方案,如果对这方面比较熟练,可以从后面开始看,这里由简入繁
集成很简单,build.gradle中加入:
compile ‘com.rmtheis:tess-two:6.0.0’
//后面我已经换到8.0.0,上传的demo是在6.0.0下运行的
compile ‘com.rmtheis:tess-two:8.0.0’
编译一下,框架的集成就ok了,不过tess-two的文字库是需要另外下载的,我们一般只需要中文和英文两种就可以了,特殊需求可以自己训练
字体库下载地址:https://github.com/tesseract-ocr/tessdata
英文:eng.traineddata
简体中文:chi_sim.traineddata
将这两个字体库文件,放到sd卡,路径必须为 **/tessdata/
路径为什么一定要为**/tessdata/呢?在TessBaseApi类的初始化方法中会检查你的文字库目录,代码如下
/**
* datapath是你传入的文字库路径,可以看到这里在传入的datapath后加了一个"tessdata"目录
* 然后验证了这个目录是否存在,如果不在,就会报错"数据目录必须包含tessdata目录"
*/
File tessdata = new File(datapath + "tessdata");
//tessdata是否存在且是个目录
if (!tessdata.exists() || !tessdata.isDirectory())
throw new IllegalArgumentException("Data path must contain subfolder tessdata!");
然后就是使用了,这里我的字体库文件都放在 “根目录/Download/tessdata“中
解析图片代码如下:
public class OcrUtil {
//字体库路径,此路径下必须包含tessdata文件夹,但不用把tessdata写上
static final String TESSBASE_PATH = Environment.getExternalStorageDirectory() + File.separator + "Download" + File.separator;
//英文
static final String ENGLISH_LANGUAGE = "eng";
//简体中文
static final String CHINESE_LANGUAGE = "chi_sim";
/**
* 识别英文
*
* @param bmp 需要识别的图片
* @param callBack 结果回调(携带一个String 参数即可)
*/
public static void ScanEnglish(final Bitmap bmp, final MyCallBack callBack) {
new Thread(new Runnable() {
@Override
public void run() {
TessBaseAPI baseApi = new TessBaseAPI();
//初始化OCR的字体数据,TESSBASE_PATH为路径,ENGLISH_LANGUAGE指明要用的字体库(不用加后缀)
if (baseApi.init(TESSBASE_PATH, ENGLISH_LANGUAGE)) {
//设置识别模式
baseApi.setPageSegMode(TessBaseAPI.PageSegMode.PSM_AUTO);
//设置要识别的图片
baseApi.setImage(bmp);
//开始识别
String result = baseApi.getUTF8Text();
baseApi.clear();
baseApi.end();
callBack.response(result);
}
}
}).start();
}
}
好了,识别工具写好了,接下要做的就是,打开相机、获取预览图、裁切出需要的区域,然后交给tess-two识别,这里我直接吧SurfaceView封装了一下,自动打开相机开始预览,下面是扫描手机号的代码:
public class CameraView extends SurfaceView implements SurfaceHolder.Callback, Camera.PreviewCallback {
private final String TAG = "CameraView";
private SurfaceHolder mHolder;
private Camera mCamera;
private boolean isPreviewOn;
//默认预览尺寸
private int imageWidth = 1920;
private int imageHeight = 1080;
//帧率
private int frameRate = 30;
public CameraView(Context context) {
super(context);
init();
}
public CameraView(Context context, AttributeSet attrs) {
super(context, attrs);
init();
}
public CameraView(Context context, AttributeSet attrs, int defStyleAttr) {
super(context, attrs, defStyleAttr);
init();
}
private void init() {
mHolder = getHolder();
//设置SurfaceView 的SurfaceHolder的回调函数
mHolder.addCallback(this);
mHolder.setType(SurfaceHolder.SURFACE_TYPE_PUSH_BUFFERS);
}
@Override
public void surfaceCreated(SurfaceHolder holder) {
//Surface创建时开启Camera
openCamera();
}
@Override
public void surfaceChanged(SurfaceHolder holder, int format, int width, int height) {
//设置Camera基本参数
if (mCamera != null)
initCameraParams();
}
@Override
public void surfaceDestroyed(SurfaceHolder holder) {
try {
release();
} catch (Exception e) {
}
}
private boolean isScanning = false;
/**
* Camera帧数据回调用
*/
@Override
public void onPreviewFrame(byte[] data, Camera camera) {
//识别中不处理其他帧数据
if (!isScanning) {
isScanning = true;
new Thread(new Runnable() {
@Override
public void run() {
try {
//获取Camera预览尺寸
Camera.Size size = camera.getParameters().getPreviewSize();
//将帧数据转为bitmap
YuvImage image = new YuvImage(data, ImageFormat.NV21, size.width, size.height, null);
if (image != null) {
ByteArrayOutputStream stream = new ByteArrayOutputStream();
//将帧数据转为图片(new Rect()是定义一个矩形提取区域,我这里是提取了整张图片,然后旋转90度后再才裁切出需要的区域,效率会较慢,实际使用的时候,照片默认横向的,可以直接计算逆向90°时,left、top的值,然后直接提取需要区域,提出来之后再压缩、旋转 速度会快一些)
image.compressToJpeg(new Rect(0, 0, size.width, size.height), 80, stream);
Bitmap bmp = BitmapFactory.decodeByteArray(stream.toByteArray(), 0, stream.size());
//这里返回的照片默认横向的,先将图片旋转90度
bmp = rotateToDegrees(bmp, 90);
//然后裁切出需要的区域,具体区域要和UI布局中配合,这里取图片正中间,宽度取图片的一半,高度这里用的适配数据,可以自定义
bmp = bitmapCrop(bmp, bmp.getWidth() / 4, bmp.getHeight() / 2 - (int) getResources().getDimension(R.dimen.x25), bmp.getWidth() / 2, (int) getResources().getDimension(R.dimen.x50));
if (bmp == null)
return;
//将裁切的图片显示出来(测试用,需要为CameraView setTag(ImageView))
ImageView imageView = (ImageView) getTag();
imageView.setImageBitmap(bmp);
stream.close();
//开始识别
OcrUtil.ScanEnglish(bmp, new MyCallBack() {
@Override
public void response(String result) {
//这是区域内扫除的所有内容
Log.d("scantest", "扫描结果: " + result);
//检索结果中是否包含手机号
Log.d("scantest", "手机号码: " + getTelnum(result));
isScanning = false;
}
});
}
} catch (Exception ex) {
isScanning = false;
}
}).start();
}
}
/**
* 获取字符串中的手机号
*/
public String getTelnum(String sParam) {
if (sParam.length() <= 0)
return "";
Pattern pattern = Pattern.compile("(1|861)(3|5|8)\\d{9}$*");
Matcher matcher = pattern.matcher(sParam);
StringBuffer bf = new StringBuffer();
while (matcher.find()) {
bf.append(matcher.group()).append(",");
}
int len = bf.length();
if (len > 0) {
bf.deleteCharAt(len - 1);
}
return bf.toString();
}
/**
* Bitmap裁剪
*
* @param bitmap 原图
* @param width 宽
* @param height 高
*/
public static Bitmap bitmapCrop(Bitmap bitmap, int left, int top, int width, int height) {
if (null == bitmap || width <= 0 || height < 0) {
return null;
}
int widthOrg = bitmap.getWidth();
int heightOrg = bitmap.getHeight();
if (widthOrg >= width && heightOrg >= height) {
try {
bitmap = Bitmap.createBitmap(bitmap, left, top, width, height);
} catch (Exception e) {
return null;
}
}
return bitmap;
}
/**
* 图片旋转
*
* @param tmpBitmap
* @param degrees
* @return
*/
public static Bitmap rotateToDegrees(Bitmap tmpBitmap, float degrees) {
Matrix matrix = new Matrix();
matrix.reset();
matrix.setRotate(degrees);
return Bitmap.createBitmap(tmpBitmap, 0, 0, tmpBitmap.getWidth(), tmpBitmap.getHeight(), matrix,
true);
}
/**
* 摄像头配置
*/
public void initCameraParams() {
stopPreview();
//获取camera参数
Camera.Parameters camParams = mCamera.getParameters();
List<Camera.Size> sizes = camParams.getSupportedPreviewSizes();
//确定前面定义的预览宽高是camera支持的,不支持取就更大的
for (int i = 0; i < sizes.size(); i++) {
if ((sizes.get(i).width >= imageWidth && sizes.get(i).height >= imageHeight) || i == sizes.size() - 1) {
imageWidth = sizes.get(i).width;
imageHeight = sizes.get(i).height;
//
break;
}
}
//设置最终确定的预览大小
camParams.setPreviewSize(imageWidth, imageHeight);
//设置帧率
camParams.setPreviewFrameRate(frameRate);
//启用参数
mCamera.setParameters(camParams);
mCamera.setDisplayOrientation(90);
//开始预览
startPreview();
}
/**
* 开始预览
*/
public void startPreview() {
try {
mCamera.setPreviewCallback(this);
mCamera.setPreviewDisplay(mHolder);//set the surface to be used for live preview
mCamera.startPreview();
mCamera.autoFocus(autoFocusCB);
} catch (IOException e) {
mCamera.release();
mCamera = null;
}
}
/**
* 停止预览
*/
public void stopPreview() {
if (mCamera != null) {
mCamera.setPreviewCallback(null);
mCamera.stopPreview();
}
}
/**
* 打开指定摄像头
*/
public void openCamera() {
Camera.CameraInfo cameraInfo = new Camera.CameraInfo();
for (int cameraId = 0; cameraId < Camera.getNumberOfCameras(); cameraId++) {
Camera.getCameraInfo(cameraId, cameraInfo);
if (cameraInfo.facing == Camera.CameraInfo.CAMERA_FACING_BACK) {
try {
mCamera = Camera.open(cameraId);
} catch (Exception e) {
if (mCamera != null) {
mCamera.release();
mCamera = null;
}
}
break;
}
}
}
/**
* 摄像头自动聚焦
*/
Camera.AutoFocusCallback autoFocusCB = new Camera.AutoFocusCallback() {
public void onAutoFocus(boolean success, Camera camera) {
postDelayed(doAutoFocus, 1000);
}
};
private Runnable doAutoFocus = new Runnable() {
public void run() {
if (mCamera != null) {
try {
mCamera.autoFocus(autoFocusCB);
} catch (Exception e) {
}
}
}
};
/**
* 释放
*/
public void release() {
if (isPreviewOn && mCamera != null) {
isPreviewOn = false;
mCamera.setPreviewCallback(null);
mCamera.stopPreview();
mCamera.release();
mCamera = null;
}
}
}
布局文件:
<?xml version="1.0" encoding="utf-8"?>
<RelativeLayout xmlns:android="http://schemas.android.com/apk/res/android"
android:layout_width="match_parent"
android:layout_height="match_parent"
android:gravity="center_horizontal">
<!--相机预览窗口,上面设置的预览大小是1080x1920,为保证比例,记得Activity的style不要加ActionBar,保证全屏显示-->
<test.com.ocrtest.CameraView
android:id="@+id/main_camera"
android:layout_width="match_parent"
android:layout_height="match_parent" />
<!--扫描框,和上面裁切规则一样,宽度为屏幕的一半,高度对应上面的x50(1080P分辨率下为168px)-->
<TextView
android:layout_width="@dimen/x160"
android:layout_height="@dimen/x50"
android:layout_centerInParent="true"
android:background="@drawable/fillet_gray_border_btn" />
<!--显示被裁切出的图片,需要setTag到CameraView中,详见上面CameraView代码-->
<ImageView
android:id="@+id/main_image"
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:layout_centerHorizontal="true" />
</RelativeLayout>
更新
对于文字识别这块,我之后还尝试了几种方案,这里列举一下
1、tess-two
适用场景:小区域连续扫描解析 (比如识别手机号、单词 等)
优点:免费开源、本地解析、英文数字识别率可观
缺点:识别速度慢、需要做大量优化(下面我会贴出我针对自己的项目做出的一些优化,避免解析大部分无意义的画面,二值化提高识别率等)
2、各个平台的OCR API,比如百度、腾讯、合合信息 等
适用场景:识别频率不高、需要识别大图(比如拍一张照,点确认,拿到结果,就OK了 像身份证 银行卡识别)
优点:识别率高
缺点: 收费(费用不高)、解析速度太依赖网络质量、无本地解析SDK,需要上传图片然后获取解析结果,因为不能每一帧都上传解析,所以不能用作连续扫描
我之前尝试过百度ocr,方案是给用户一个按钮,用户点击之后,取相机最近的一帧照片上传给百度,然后跳过其他帧,等待用户下一次点击解析按钮。通过压缩裁切图片,我已经把图片压缩到10+kb、在网速良好的情况下,解析速度能达到0.5秒,但如果网速不好,体验急剧下降
3、有一些平台提供本地Ocr解析的SDK(比如合合信息)
适用场景:大部分需求都能实现
优点: 解析速度快、识别率高
缺点: 费用奇高 -_-(企业合作级别的费用)
对于tess-two的进一步优化(这里针对我的需求,只识别单行手机号):
文章开头说过了,提高效率最重要的就是训练出为自己需求量身定做的字库,我需要识别的面单上的手机号,全部是黑体的数字,那我就针对“黑体 数字”来训练我的字库,我训练出来的字库大小100+KB,识别优化后的手机号图片,只要300-500ms,再过滤掉大部分无意义图像,就可以实现连续扫描,而官方的包识别至少1.5-3秒,如果再无法过滤无意义图像,那识别一个手机号10秒钟能搞定你就谢天谢地了
训练方法在文章开头有链接,至于训练用的模板图片,文章最下面的优化代码中,把最终取到的图像保存下来去训练就好了
对于把图片交给tess-two之前的优化
主要包括:减小图片的尺寸大小、二值化图片使文字黑白分明、判断图片内容是否无意义
1、裁切图片
根据上面文章的代码,是先把一帧的数据转为图片,然后旋转90°,然后根据扫描框在界面上的位置,裁切出需要的区域,如下
ByteArrayOutputStream stream = new ByteArrayOutputStream();
//将帧数据转为图片
image.compressToJpeg(new Rect(0, 0, size.width, size.height), 80, stream);
Bitmap bmp = BitmapFactory.decodeByteArray(stream.toByteArray(), 0, stream.size());
//这里返回的照片默认横向的,先将图片旋转90度
bmp = rotateToDegrees(bmp, 90);
//然后裁切出需要的区域,具体区域要和UI布局中配合,这里取图片正中间,宽度取图片的一半,高度这里用的适配数据,可以自定义
bmp = bitmapCrop(bmp, bmp.getWidth() / 4, bmp.getHeight() / 2 - (int) getResources().getDimension(R.dimen.x25), bmp.getWidth() / 2, (int) getResources().getDimension(R.dimen.x50));
那么问题就在裁切和旋转的时候了,假如相机一帧的像素是1920*1080,而我需要的只是扫描框内的一点内容,把一整张图片都提取出来,加上旋转这张大图片,然后再裁切,无疑浪费了很多时间
解决办法:
直接计算逆向90°情况下的提取区域
上边裁切范围是:屏幕正中间、宽度为屏幕的一半、高度为R.dimen.x50 的一个矩形
那么矩形的位置就取图片正中间
left=bmp.getWidth() / 4
top=bmp.getHeight()/ 2 – R.dimen.x25
width=bmp.getWidth() / 2
height= R.dimen.x50如果逆向90°,长宽倒转,矩形的位置就变成
left=bmp.getWidth()/ 2 – R.dimen.x25 (原来的top)
top=bmp.getHeight()/4 (原来的right)
width=R.dimen.x50 (原来的height)
height= bmp.getHeight()/2 (原来的width)ByteArrayOutputStream stream = new ByteArrayOutputStream();
image.compressToJpeg(new Rect(left , top, left+width, top+height), 80,
stream);
Bitmap bmp = BitmapFactory.decodeByteArray(stream.toByteArray(), 0, stream.size());
这样直接提取需要的区域,就节省了整张图片旋转和第二次裁切的时间
2、旋转、二值化 图片,过滤无用内容
接下来的旋转和二值化,是纯像素算法,如果能放在jni中实现更好,经过我测试效率会快好几倍(Java大概10-50ms,Jni基本在10ms以下,虽然几十毫秒的时间差,跟tess-two的解析时间比,效果不明显),这里还是用Java来表现逻辑
上面已经直接提取出了需要解析的矩形区域,接下来只需要旋转一张像素小了很多倍的图片 还是上面文章中的方法
rotateToDegrees(bmp, 90)
旋转之后,就是一张方向正确的识别区域了,现在需要做的就是二值化,将图片变为黑白两色,提高识别率(因为要遍历所有的像素,为了节省时间,在二值化的同时,同步进行无用内容过滤)
无用内容过滤:
如文章开头介绍,在相机打开之后,每一秒都有几十帧数据,什么时候解析呢?这里我做出了一些过滤(下面的过滤算法,只适用于和我的需求类似的场景(扫描手机号、单行文本))
怎么过滤呢?先来想想场景,什么样的图片可以认为图中可能有手机号呢?
第一:手机号完整的在矩形区域内,不会有超出矩形区域的部分,也就是说手机号部分不会有贴边的像素
第二:如果要扫描手机号,肯定会将手机号至少填充扫描框的50%高度(这个比例自己掌握,看你的扫描距离,我后来减到了10%,捕捉手机号依然很准确)
有了这两个条件,就有了判断标准,图片中必须有 上下左右没有贴边,且高度大于50%的有色区域,才能初步判断图中可能存在手机号码然后我就实现方式,我的思路是:
这里实现一个单行文字捕捉,首先准备 left、top、right、bottom 四个变量,就是最终需要的单行文字区域1、先黑白化图片,这个过程需要遍历像素,在遍历期间,同时来做过滤,这里遍历是一行一行的,所以在第一次遍历中,能判断文字行数:比如在遍历某一行的像素时,只要发现一个黑色像素,说明这一行不是空行,那就记录一下这里已经有文字占了一行像素,下一行如果还是找到黑色像素,那就把当前记录的文字加一行像素高度,直到某一行全部是白色像素,说明这一行文字结束了,下面再有黑色像素就算是第二行文字了
2、如果第一行像素就发现了黑色像素点,说明这行文字是贴着文字上边缘的,八成是只露出了一半的文字,肯定不是解析对象,那就不用记录他,直到遇到一行全是白色像素,表示这行贴边的文字结束了,接下来的文字就要开始记录了(没错,如果有一条竖着的黑线,从上贯穿到下,那这个图片肯定被认为全是贴边文字,直接过滤掉,我的识别环境不会有这个情况,所以没有做更细致的过滤,需要判断这种情况的,自己写算法 -_-)
3、每一行文字记录结束都跟上一行文字比较,选高度更高的一行文字留下,其他的跳过(前面说了这里是单行识别,只选没有贴边的文字最高的一行),等遍历结束,最高的一行的top 和 bottom留下,就得到的解析对象的上下边缘
4、需要留意的是,上一个过滤贴边文字的条件,只过滤了超出上边缘的文字,那超出下边缘的文字呢?很简单,每行文字记录完成后才会和上一行比较,就是说每次遇到一整行白色像素的空白行时,才会更新top和bottom,如果最后一行贴边了那就不会再遇到空白行,自动就放弃了
下面在代码中解释细节
/**
* 转为二值图像 并判断图像中是否可能有手机号
*
* @param bmp 原图bitmap
* @param tmp 二值化阈值 超出阈值的像素置为白色,否则为黑色
* @return
*/
public Bitmap convertToBMW(final Bitmap bmp, int tmp) {
int width = bmp.getWidth(); // 获取位图的宽
int height = bmp.getHeight(); // 获取位图的高
int[] pixels = new int[width * height]; // 通过位图的大小创建像素点数组
bmp.getPixels(pixels, 0, width, 0, 0, width, height);//得到图片的所有像素
int lineHeight = 0;//当前记录的一行文字已经累计的高度,每次遇到一行有黑色像素点时 +1
//目标行,每遇到一个黑色像素,就会+1,本行就不会在记录lineHeight,下一行在遇到黑色像素,就继续+1,保证每行lineHeight最多 +1 一次
int row = 0;
//当前记录的一行文字是否超出边缘(如果第一行就发现黑色像素,就为true了,直到遇到空白行,还原false)
boolean isOutOfRect= false;
//最终捕捉到的单行文字在图片中的矩形区域
int left = 0;
int top = 0;
int right = 0;
int bottom = 0;
int alpha = 0xFF << 24;
for (int i = 0; i < height; i++) {
for (int j = 0; j < width; j++) {
int grey = pixels[width * i + j];
// 分离三原色
alpha = ((grey & 0xFF000000) >> 24);
int red = ((grey & 0x00FF0000) >> 16);
int green = ((grey & 0x0000FF00) >> 8);
int blue = (grey & 0x000000FF);
if (red > tmp) {
red = 255;
} else {
red = 0;
}
if (blue > tmp) {
blue = 255;
} else {
blue = 0;
}
if (green > tmp) {
green = 255;
} else {
green = 0;
}
pixels[width * i + j] = alpha << 24 | red << 16 | green << 8
| blue;
//这里是二值化化的判断,if里是白色,else里是黑色
if (pixels[width * i + j] == -1 || (i == height - 1 && j == width - 1)) {
//将当前像素赋值为白色
pixels[width * i + j] = -1;
/**
lineHeight>0 : 如果当前记录行的文字高度大于0
row == i : 当前是不是目标行,每行第一次发现黑色像素就会+1,所以只有当前行还没出现黑色像素时,才会 == i
j == width - 1 : 当前像素是不是本行的最后一个像素点
综上所述,这里的判断条件为 : 已经捕捉到一行文字,而且这一行已经结束了还没发现黑色像素,这行文字该结束了
*/
if (lineHeight > 0 && row == i && j == width - 1) {
//这行文字是不是超出边缘的文字,如果是,直接跳过,开始记录下一行
if (!isOutOfBorder) {
//跟上一行的文字高度比较,记录下高度更高的一行文字的top 和 bottom
int h = bottom - top;
if (lineHeight > h) {
//这里我把top 和 bottom 都加了1/4的行高,为了有一点留白,其实加不加无所谓
top = i - lineHeight - (lineHeight / 4);
bottom = i - 1 + (lineHeight / 4);
}
}
//这行文字既然已经结束了,下一行文字肯定不是超出边缘的了
isOutOfRect= false;
//上一行文字已经处理完成,行高归0,开始记录下一行
lineHeight = 0;
}
} else {
//这里是黑色像素,将当前像素点赋值为黑色
pixels[width * i + j] = -16777216;
//如果当前行 = 目标行(遇到这行第一个黑色像素就会+1,到下一行才会相等)
if (i >= row) {
//如果当前的黑色像素 位于第一行像素 或 最后一行像素,那就是超出边缘的文字
if (i == 0 || i == height - 1)
isOutOfRect= true;
//行高+1
lineHeight++;
//目标行转移到下一行
row = i + 1;
}
}
}
}
/** 如果通过第一次过滤后,没有找到一行有意义的文字,或者找到了,文字高度占比还不到解析图片的20%,
那这张图片八成是无意义的图片,不用解析,直接下一帧(当你对着墙或者什么无聊的东西扫描的时候,
这里就会直接结束,不会浪费时间去做文字识别)
*/
if (bottom - top < height * 0.2f) {
isScanning = false;
return null;
}
/**
到这里,上面的筛选已经通过了,我们已经定位到了一行目标文字的 top 和 bottom
接下来就要定位left 和 right 了
还是需要遍历一次,不过只需要 top-bottom 正中间的一行像素,思路同上,通过文字间距
来将这一行文字分成横向的几个文字块,至于区分条件,就看文字间的间隔,超过正常宽度就
算是一个文字块的结束,至于正常的文字间隔就要按需求而定了,比如这里扫描手机号,手机
号是11位的,那两个数字之间的距离说破天也不会超过图片宽度的 1/11,那我就定为1/11
那问题又来了,如果刚好手机号在这块图像右边的上半部分,下半部分是在手机号左边的无用文字,
只是因为高度重叠,上面取行高时被当成了一行,那这里只取top-bottom正中间的一条像素,
遍历到手机号所在的右边一半时,不是只能找到空白像素?
这就没办法了,只取一条像素行,一是为了减少耗时,二是让我的脑细胞少死一点,你要扫描手机号,
还非要把手机号完美躲开正中间,那我就不管了.....
*/
//文字间隔,每次遇到白色像素点+1,每次遇到黑色像素点归0,当space > 宽度的1/11时,就算超过正常文字间距了
int space = 0;
//当前文字块宽度,每当遇黑色像素点时,更新宽度,space 超过宽度的1/11时,归0,文字块结束
int textWidth = 0;
//当前文字开始X坐标,文字块宽度 = 结束点 - startX
int startX = 0;
//遍历top-bottom 正中间一行像素
for (int j = 0; j < width; j++) {
//如果是白色像素
if (pixels[width * (top + (bottom - top) / 2) + j] == -1) {
/**
如果已经捕捉到了文字块,而且space > width / 11 或者已经遍历结束了,
那这个文字块的宽度就取到了
*/
if (textWidth > 0 && (space > width / 11 || j == width - 1)) {
//同高度一样,比较上一个文字块的宽度,留下最大的一个 top 和 bottom
if (textWidth > right - left) {
//这里取left 和 right 一样加了一个space/2的留白
left = j - space - textWidth - (space / 2);
right = j - 1;
}
//既然当前文字块已经结束,就把参数重置,继续捕捉下一个文字块
space = 0;
startX = 0;
}
space++;
} else {
//这里是黑色像素
//记录文字块的开始X坐标
if (startX == 0)
startX = j;
//文字块当前宽度
textWidth = j - startX;
//文字间隔归0
space = 0;
}
}
//如果最终捕捉到的文字块,宽度还不到图片宽度的30%,同样跳过,八成不是手机号,就不要浪费时间识别了
if (right - left < width * 0.3f) {
isScanning = false;
return null;
}
/**
到这里 已经捕捉到了一个很可能是手机号码的文字块,区域就是 left、top、right、bottom
把这个区域的像素,取出来放到一个新的像素数组
*/
int targetWidth = right - left;
int targetHeight = bottom - top;
int[] targetPixels = new int[targetWidth * targetHeight];
int index = 0;
for (int i = top; i < bottom; i++) {
for (int j = left; j < right; j++) {
if (index < targetPixels.length)
targetPixels[index] = pixels[width * i + j];
index++;
}
}
//销毁之前的图片
bmp.recycle();
// 新建图片
final Bitmap newBmp = Bitmap.createBitmap(targetWidth, targetHeight, Bitmap.Config.ARGB_8888);
//把捕捉到的图块,写进新的bitmap中
newBmp.setPixels(targetPixels, 0, targetWidth, 0, 0, targetWidth, targetHeight);
//将裁切的图片显示出来(测试用,需要为CameraView setTag(ImageView))
//主线程 {
// @Override
// public void run() {
// ImageView imageView = (ImageView) getTag();
// imageView.setVisibility(View.VISIBLE);
// imageView.setImageBitmap(newBmp);
// }
//};
//这里可以把这块图像保存到本地,可以做个按钮,点击时把saveBmp=true,就可以采集一张,采集几张之后,拿去做tesseract 训练,训练出适合自己需求的字库,才是提高效率的关键
// if (saveBmp) {
// saveBmp = false;
// ImageUtils.saveBitmap(scanBmp, System.currentTimeMillis() + ".jpg");
// }
//返回需要交给tess-two识别的内容
return newBmp;
}
更新
图1:捕捉到有 11 位字符的文字块,取到文字块的精准位置,交给tess-two解析
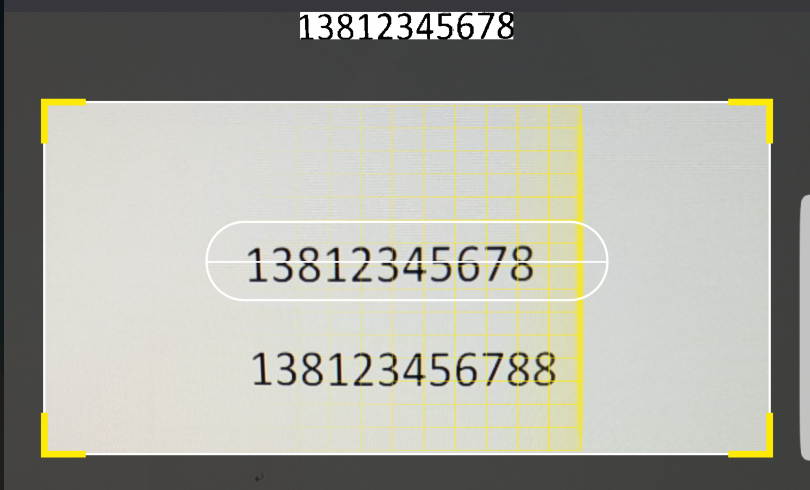
图2:捕捉到有 12 位字符的文字块,不符合手机号码特征,则不进行位置获取和内容识别,直接跳过
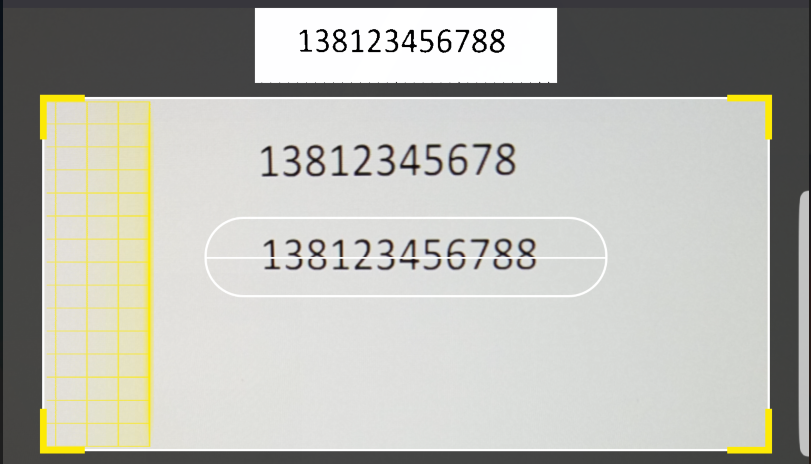
之前的算法还有一些缺陷,会有少数不符合手机号特征的文字块也被捕捉到了,我又换了一种算法,可以捕捉到文字块的精准位置,和包含多少个字符(字符数量不符合特征就也可以过滤掉,如上图2),且有一定的抗干扰能力(效果一般,主要解决我遇到的水印问题)
这里先封装一个工具类,直接调用catchPhoneRect(bitmp,imageView)方法,即可获取一个只包含手机号的精准bitmap,如果返回null,表示没有发现符合手机号特征的文字块(这里捕获时,是先取图片中间一行的像素来初步判断手机号位置,所以UI上需要一条中间线类辅助扫描,如上图1)
我遇到的水印问题:有些面单上的手机号,会被一种免单编号的水印遮住底边,手机号还是能看清楚,但是少数数字的底部被水印连在了一起,导致tesseract 无法识别
这里解决办法就是:通过递归算法,获取每一个字符的精准位置,在获取位置的过程中,如果发现宽度或高度延伸到了不合理的范围,即视为被水印干扰的字符,先跳过这个字符,继续捕捉下一个,直到捕捉到一个没有发现干扰的字符,就可以确定这个文字块中每个字符的正确宽高,这时从头再遍历一次,根据正确的宽高范围来清除水印部分像素
public class TesseractUtil {
private static TesseractUtil mTesseractUtil = null;
private float proportion = 0.5f;
private TesseractUtil() {
}
public static TesseractUtil getInstance() {
if (mTesseractUtil == null)
synchronized (TesseractUtil.class) {
if (mTesseractUtil == null)
mTesseractUtil = new TesseractUtil();
}
return mTesseractUtil;
}
/**
* 调整阈值
*
* @param pro 调整比例
*/
public int adjustThresh(float pro) {
this.proportion += pro;
if (proportion > 1f)
proportion = 1f;
if (proportion < 0)
proportion = 0;
return (int) (proportion * 100);
}
/**
* 识别数字
*
* @param bmp 需要识别的图片
* @param callBack 结果回调
*/
public void scanNumber(final Bitmap bmp, final SimpleCallBack callBack) {
if (checkTesseract()) {
TessBaseAPI baseApi = new TessBaseAPI();
//初始化OCR的字体数据(Constants.BASE_PATH为字库所在路径,Constants.NUMBER_LANGUAGE为字库文件名(不加后缀))
if (baseApi.init(Constants.BASE_PATH, Constants.NUMBER_LANGUAGE)) {
//设置识别模式(单行识别)
baseApi.setPageSegMode(TessBaseAPI.PageSegMode.PSM_SINGLE_LINE);
//设置要识别的图片
baseApi.setImage(bmp);
baseApi.setVariable(TessBaseAPI.VAR_SAVE_BLOB_CHOICES, TessBaseAPI.VAR_TRUE);
//开始识别
String result = baseApi.getUTF8Text();
baseApi.clear();
baseApi.end();
bmp.recycle();
callBack.response(result);
}
}
}
private void showImage(final Bitmap bmp, final ImageView imageView) {
//显示当前图片处理进度(测试用)
MainThread.getInstance().
execute(new Runnable() {
@Override
public void run() {
imageView.setVisibility(View.VISIBLE);
imageView.setImageBitmap(bmp);
}
});
}
//白色色值
private final int PX_WHITE = -1;
//黑色色值
private final int PX_BLACK = -16777216;
//占位色值(这个算法加入了排除干扰的模式,如果在捕捉一个文字的位置时,发现文字的宽度或者高度超出了正常高度,则很有可能这里被水印之类的干扰了,那就把超出正常的范围像素色值变成-2,颜色和白色很接近,会被当作背景色,相当于清除了干扰,不直接变成-1是为了在其他数字被误判为干扰水印时,可以还原)
private final int PX_UNKNOW = -2;
/**
* 转为二值图像 并判断图像中是否可能有手机号
*
* @param bmp 原图bitmap
* @param imageView 显示当前图片处理进度,测试用
* @return
*/
public Bitmap catchPhoneRect(final Bitmap bmp, ImageView imageView) {
int width = bmp.getWidth(); // 获取位图的宽
int height = bmp.getHeight(); // 获取位图的高
int[] pixels = new int[width * height]; // 通过位图的大小创建像素点数组
bmp.getPixels(pixels, 0, width, 0, 0, width, height);
int left = width;
int top = height;
int right = 0;
int bottom = 0;
//计算阈值
measureThresh(pixels, width, height);
/**
* 二值化
* */
binarization(pixels, width, height);
int space = 0;
int textWidth = 0;
int startX = 0;
int centerY = height / 2 - 1;
int textLength = 0;
int textStartX = 0;
/**
* 遍历中间一行像素,粗略捕捉手机号
* 在扫描框中定义了一条中心线,如果每次扫描使用中心线来对准手机号,那么捕捉手机号的速度和准确度都有了很大的提高
* 实现逻辑:先对从帧数据中裁切好的图片进行二值化,然后取最中间一行的像素遍历,初步判断是否可能含有手机号
* 即遍历这一行时,每次遇到一段连续黑色像素,就记录一次textLength++(没一段黑色像素代表一个笔画的宽度),手机号都是11位数字
* 由此可以得知,合理的笔画范围是 最少:11111111111 ,拦腰遍历,会得到11个笔画宽度,textLength=11
* 最多:00000000000 ,拦腰遍历,会得到22个笔画宽度,textLength=22
* 也就是说,最中间一行遍历完成如果 textLength>11 && textLength<22 表示有一定可能有手机号存在(同时得到文字块的left、right),否则一定不存在,直接跳过,解析下一帧
* */
for (int j = 0; j < width; j++) {
if (pixels[width * centerY + j] == PX_WHITE) {
//白色像素,如果发现了连续黑色像素,到这里出现第一个白色像素,那么一个笔画宽度就确认了,textLength++
if (space == 1)
textLength++;
if (textWidth > 0 && startX > 0 && startX < height - 1 && (space > width / 10 || j == width - 1)) {
//如果捕捉到的合理的比划截面,就更新left、right ,如果出现了多个合理的文字块,就取宽度最大的
if (textLength > 10 && textLength < 22)
if (textWidth > right - left) {
left = j - space - textWidth - (space / 2);
if (left < 0)
left = 0;
right = j - 1 - (space / 2);
if (right > width)
right = width - 1;
textStartX = startX;
}
textLength = 0;
space = 0;
startX = 0;
}
space++;
} else {
//一段连续黑色像素的开始坐标
if (startX == 0)
startX = j;
//文字块的宽度
textWidth = j - startX;
space = 0;
}
}
//如果宽度占比过小,直接跳过
if (right - left < width * 0.3f) {
if (imageView != null) {
bmp.setPixels(pixels, 0, width, 0, 0, width, height);
//将裁切的图片显示出来
showImage(bmp, imageView);
} else
bmp.recycle();
return null;
}
/**
*粗略计算文字高度
*这里先粗略取一块高度,确定包含文字,现在已经得知了文字块宽度,那么合理的字符宽度就是 (right - left) / 11,数字通常高度更大,这里就算宽度的1.5倍,然后为了确保包含文字,在中间线的上下各加一个文字高度
*接下来就要捕捉文字块的具体信息了,包括精准的宽度、高度 以及 字符数量
*/
top = (int) (centerY - (right - left) / 11 * 1.5);
bottom = (int) (centerY + (right - left) / 11 * 1.5);
if (top < 0)
top = 0;
if (bottom > height)
bottom = height - 1;
/**
* 判断区域中有几个字符
* */
//已经使用过的像素标记
int[] usedPixels = new int[width * height];
int[] textRect = new int[]{right, bottom, 0, 0};
//当前捕捉文字的rect
int[] charRect = new int[]{textStartX, centerY, 0, centerY};
//在文字块中捕捉到的字符个数
int charCount = 0;
//是否发现干扰
boolean hasStain = false;
startX = left;
int charMaxWidth = (right - left) / 11;
int charMaxHeight = (int) ((right - left) / 11 * 1.5);
int charWidth = 0;//捕获到一个完整字符后得到标准的字符宽度
boolean isInterfereClearing = false;
//循环获取每一个字符的宽高位置
while (true) {
//当前字符的宽高是否正常
boolean isNormal = false;
//是否已经清除干扰,如果在捕捉字符宽高的过程中,发现有水印干扰,会调用clearInterfere()方法,将超出宽高的像素部分置为-2,然后继续捕捉下一个字符
if (!isInterfereClearing){
//如果被水印干扰,在进行递归算法的过程中,高度或宽度会超出正常范围,这里会返回false,如果是没有水印的干净文字块,不会触发else(方法实现在下面)
isNormal = catchCharRect(pixels, usedPixels, charRect, width, height, charMaxWidth, charMaxHeight, charRect[0], charRect[1]);
}else
isNormal = clearInterfere(pixels, usedPixels, charRect, width, height, charWidth, charWidth, charRect[0], charRect[1]);
//记录已经捕捉的字符数量
charCount++;
if (!isNormal) {
//如果第一个字符发现干扰,这里记录有干扰,然后捕捉下一个字符,如果还是有干扰,继续捕捉下一个,直到找到一个正常的字符,那就可以得到一个字符的精准宽度,和高度,然后根据这个正确的宽高,从头再遍历一次,这个就可以把超出这个宽高的像素置为-2
hasStain = true;
if (charWidth != 0) {
usedPixels = new int[width * height];
charRect = new int[]{textStartX, centerY, 0, centerY};
charCount = 0;
isInterfereClearing = true;
}
} else {
//到这里就表示:发现了干扰,而且已经捕捉到一个正确的字符宽高,可以开始清除水印了
if (hasStain && !isInterfereClearing) {
//把位置还原,重新开始遍历,这次一边获取宽高,一边清除水印
usedPixels = new int[width * height];
charWidth = charRect[3] - charRect[1];
charRect = new int[]{textStartX, centerY, 0, centerY};
charCount = 0;
isInterfereClearing = true;
continue;
} else {
if (charWidth == 0) {
charWidth = charRect[3] - charRect[1];
}
//如果没有发现干扰,直接更新文字块的精准位置
if (textRect[0] > charRect[0])
textRect[0] = charRect[0];
if (textRect[1] > charRect[1])
textRect[1] = charRect[1];
if (textRect[2] < charRect[2])
textRect[2] = charRect[2];
if (textRect[3] < charRect[3])
textRect[3] = charRect[3];
}
}
//是否找到下一个字符
boolean isFoundChar = false;
if (!hasStain || isInterfereClearing) {
//获取下一个字符的rect开始点(如果上一个字符的宽高正常这里就可以直接找到下一个字符的起始坐标)
for (int x = charRect[2] + 1; x <= right; x++)
if (pixels[width * centerY + x] != PX_WHITE) {
isFoundChar = true;
charRect[0] = x;
charRect[1] = centerY;
charRect[2] = 0;
charRect[3] = 0;
break;
}
} else {
//如果发现干扰,那么可能还没有得到合理的宽高,还是用开头获取笔画的方式,寻找下一个字符开始捕获的坐标,
for (int x = left; x <= right; x++)
if (pixels[width * centerY + x] != PX_WHITE && pixels[width * centerY + x - 1] == PX_WHITE) {
if (x <= startX)
continue;
startX = x;
isFoundChar = true;
charRect[0] = x;
charRect[1] = centerY;
charRect[2] = x;
charRect[3] = centerY;
break;
}
}
if (!isFoundChar) {
break;
}
}
//得到文字块的精准位置
left = textRect[0];
top = textRect[1];
right = textRect[2];
bottom = textRect[3];
//如果高度合理,且捕捉到的字符数量为11个,那么基本可以确定,这是一个11位的文字块,否则跳过,解析下一帧
if (bottom - top > (right - left) / 5 || bottom - top == 0 || charCount != 11) {
if (imageView != null) {
bmp.setPixels(pixels, 0, width, 0, 0, width, height);
//将裁切的图片显示出来
showImage(bmp, imageView);
} else
bmp.recycle();
return null;
}
/**
* 将最终捕捉到的手机号区域像素提取到新的数组
* */
int targetWidth = right - left;
int targetHeight = bottom - top;
int[] targetPixels = new int[targetWidth * targetHeight];
int index = 0;
for (int i = top; i < bottom; i++) {
for (int j = left; j < right; j++) {
if (index < targetPixels.length) {
if (pixels[width * i + j] == PX_WHITE)
targetPixels[index] = PX_WHITE;
else
targetPixels[index] = PX_BLACK;
}
index++;
}
}
bmp.recycle();
// 新建图片
final Bitmap newBmp = Bitmap.createBitmap(targetWidth, targetHeight, Bitmap.Config.ARGB_8888);
newBmp.setPixels(targetPixels, 0, targetWidth, 0, 0, targetWidth, targetHeight);
//将裁切的图片显示出来
if (imageView != null )
showImage(newBmp, imageView);
return newBmp;
}
private final int MOVE_LEFT = 0;
private final int MOVE_TOP = 1;
private final int MOVE_RIGHT = 2;
private final int MOVE_BOTTOM = 3;
/**
* 捕捉字符
* 这里用递归的算法,从字符的第一个黑色像素,开始,分别进行上下左右的捕捉,如果相邻的像素,也是黑色,就可以扩大这个字符的定位,以此类推,最后得到的就是字符的准确宽高
* 这里之所以没有用递归,而是用循环,是因为递归嵌套的层级太多,会导致 栈溢出
*/
private boolean catchCharRect(int[] pixels, int[] used, int[] charRect, int width, int height, int maxWidth, int maxHeight, int x, int y) {
int nowX = x;
int nowY = y;
//记录动作()
Stack<Integer> stepStack = new Stack<>();
while (true) {
if (used[width * nowY + nowX] == 0) {
used[width * nowY + nowX] = -1;
if (charRect[0] > nowX)
charRect[0] = nowX;
if (charRect[1] > nowY)
charRect[1] = nowY;
if (charRect[2] < nowX)
charRect[2] = nowX;
if (charRect[3] < nowY)
charRect[3] = nowY;
if (charRect[2] - charRect[0] > maxWidth) {
return false;
}
if (charRect[3] - charRect[1] > maxHeight) {
return false;
}
if (nowX == 0 || nowX >= width - 1 || nowY == 0 || nowY >= height - 1) {
return false;
}
}
//当前像素的左边是否还有黑色像素点
int leftX = nowX - 1;
if (leftX >= 0 && pixels[width * nowY + leftX] != PX_WHITE && used[width * nowY + leftX] == 0) {
nowX = leftX;
stepStack.push(MOVE_LEFT);
continue;
}
//当前像素的上边是否还有黑色像素点
int topY = nowY - 1;
if (topY >= 0 && pixels[width * topY + nowX] != PX_WHITE && used[width * topY + nowX] == 0) {
nowY = topY;
stepStack.push(MOVE_TOP);
continue;
}
//当前像素的右边是否还有黑色像素点
int rightX = nowX + 1;
if (rightX < width && pixels[width * nowY + rightX] != PX_WHITE && used[width * nowY + rightX] == 0) {
nowX = rightX;
stepStack.push(MOVE_RIGHT);
continue;
}
//当前像素的下边是否还有黑色像素点
int bottomY = nowY + 1;
if (bottomY < height && pixels[width * bottomY + nowX] != PX_WHITE && used[width * bottomY + nowX] == 0) {
nowY = bottomY;
stepStack.push(MOVE_BOTTOM);
continue;
}
//用循环模拟递归,当一个像素的周围,没有发现未记录的黑色像素,就可以退回上一步,最终效果就和递归一样了,而且不会引起栈溢出
if (stepStack.size() > 0) {
int step = stepStack.pop();
switch (step) {
case MOVE_LEFT:
nowX++;
break;
case MOVE_RIGHT:
nowX--;
break;
case MOVE_TOP:
nowY++;
break;
case MOVE_BOTTOM:
nowY--;
break;
}
} else {
break;
}
}
if (charRect[2] - charRect[0] == 0 || charRect[3] - charRect[1] == 0) {
return false;
}
return true;
}
/**
* 清除干扰
* 和catchCharRect()方法原理一样,但是多了一个逻辑,即超出正常范围的黑色像素,会被当作干扰,置为-2,这一步会导致有些被干扰连在一起的多个字符都被清空,所以在捕捉其他字符时,当发现没有超出范围,又被置为-2的像素,就还原为黑色,这样最终就能实现大部分的水印被清除(只针对我遇到的文字底部的水印)
*/
private final int WAIT_HANDLE = 0;//待处理像素
private final int HANDLED = -1;//已处理像素
private final int HANDLING = -2;//处理过但未处理完成的像素
/**
* 清除干扰
*/
private boolean clearInterfere(int[] pixels, int[] used, int[] charRect, int width, int height, int maxWidth, int maxHeight, int x, int y) {
int nowX = x;
int nowY = y;
//记录动作
Stack<Integer> stepStack = new Stack<>();
boolean needReset = true;
while (true) {
if (used[width * nowY + nowX] == WAIT_HANDLE) {
used[width * nowY + nowX] = HANDLED;
if (charRect[2] - charRect[0] <= maxWidth && charRect[3] - charRect[1] <= maxHeight) {
if (charRect[0] > nowX)
charRect[0] = nowX;
if (charRect[1] > nowY)
charRect[1] = nowY;
if (charRect[2] < nowX)
charRect[2] = nowX;
if (charRect[3] < nowY)
charRect[3] = nowY;
} else {
if (needReset)
needReset = false;
used[width * nowY + nowX] = HANDLING;
pixels[width * nowY + nowX] = PX_UNKNOW;
}
} else if (pixels[width * nowY + nowX] == PX_UNKNOW) {
if (charRect[2] - charRect[0] <= maxWidth && charRect[3] - charRect[1] <= maxHeight) {
pixels[width * nowY + nowX] = PX_BLACK;
if (charRect[0] > nowX)
charRect[0] = nowX;
if (charRect[1] > nowY)
charRect[1] = nowY;
if (charRect[2] < nowX)
charRect[2] = nowX;
if (charRect[3] < nowY)
charRect[3] = nowY;
used[width * nowY + nowX] = HANDLED;
} else {
if (needReset)
needReset = false;
}
}
//当前像素的左边是否还有黑色像素点
int leftX = nowX - 1;
int leftIndex = width * nowY + leftX;
if (leftX >= 0 && pixels[leftIndex] != PX_WHITE && (used[leftIndex] == WAIT_HANDLE || (needReset && used[leftIndex] == HANDLING))) {
nowX = leftX;
stepStack.push(MOVE_LEFT);
continue;
}
//当前像素的上边是否还有黑色像素点
int topY = nowY - 1;
int topIndex = width * topY + nowX;
if (topY >= 0 && pixels[topIndex] != PX_WHITE && (used[topIndex] == WAIT_HANDLE || (needReset && used[topIndex] == HANDLING))) {
nowY = topY;
stepStack.push(MOVE_TOP);
continue;
}
//当前像素的右边是否还有黑色像素点
int rightX = nowX + 1;
int rightIndex = width * nowY + rightX;
if (rightX < width && pixels[rightIndex] != PX_WHITE && (used[rightIndex] == WAIT_HANDLE || (needReset && used[rightIndex] == HANDLING))) {
nowX = rightX;
stepStack.push(MOVE_RIGHT);
continue;
}
//当前像素的下边是否还有黑色像素点
int bottomY = nowY + 1;
int bottomIndex = width * bottomY + nowX;
if (bottomY < height && pixels[bottomIndex] != PX_WHITE && (used[bottomIndex] == WAIT_HANDLE || (needReset && used[bottomIndex] == HANDLING))) {
nowY = bottomY;
stepStack.push(MOVE_BOTTOM);
continue;
}
if (stepStack.size() > 0) {
int step = stepStack.pop();
switch (step) {
case MOVE_LEFT:
nowX++;
break;
case MOVE_RIGHT:
nowX--;
break;
case MOVE_TOP:
nowY++;
break;
case MOVE_BOTTOM:
nowY--;
break;
}
} else {
break;
}
}
return true;
}
private int redThresh = 130;
private int blueThresh = 130;
private int greenThresh = 130;
/**
* 计算扫描线所在像素行的平均阈值
* 我找了一些自动计算阈值的算法,都不太好用,这里就直接采集了中间一行像素的平均值
*/
private void measureThresh(int[] pixels, int width, int height) {
int centerY = height / 2;
int redSum = 0;
int blueSum = 0;
int greenSum = 0;
for (int j = 0; j < width; j++) {
int gray = pixels[width * centerY + j];
redSum += ((gray & 0x00FF0000) >> 16);
blueSum += ((gray & 0x0000FF00) >> 8);
greenSum += (gray & 0x000000FF);
}
redThresh = (int) (redSum / width * 1.5f * proportion);
blueThresh = (int) (blueSum / width * 1.5f * proportion);
greenThresh = (int) (greenSum / width * 1.5f * proportion);
}
/**
* 二值化
*/
private void binarization(int[] pixels, int width, int height) {
for (int i = 0; i < height; i++) {
for (int j = 0; j < width; j++) {
int gray = pixels[width * i + j];
pixels[width * i + j] = getColor(gray);
if (pixels[width * i + j] != PX_WHITE)
pixels[width * i + j] = PX_BLACK;
}
}
}
/**
* 获取颜色
*/
private int getColor(int gray) {
int alpha = 0xFF << 24;
// 分离三原色
alpha = ((gray & 0xFF000000) >> 24);
int red = ((gray & 0x00FF0000) >> 16);
int green = ((gray & 0x0000FF00) >> 8);
int blue = (gray & 0x000000FF);
if (red > redThresh) {
red = 255;
} else {
red = 0;
}
if (blue > blueThresh) {
blue = 255;
} else {
blue = 0;
}
if (green > greenThresh) {
green = 255;
} else {
green = 0;
}
return alpha << 24 | red << 16 | green << 8
| blue;
}
}
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/132441.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
