大家好,又见面了,我是你们的朋友全栈君。
一.简介
Tesseract-OCR支持中文识别,并且开源和提供全套的训练工具,是快速低成本开发的首选。而Tess4J则是Tesseract在Java PC上的应用。在英文和数字识别中性能还是不错的,但是在中文识别中,无论速度还是识别率还是较弱,建议有条件的话,针对场景进行训练,会获得较好结果,本文仅对目前Tess4J的用法进行介绍
二.入门教程
1.去Tess4J官网下载最新的源码包
我们现在最新的是3.4.8
2.创建Java项目并配置Tess4J
- 下载下来的Tess4J目录一般都是如下

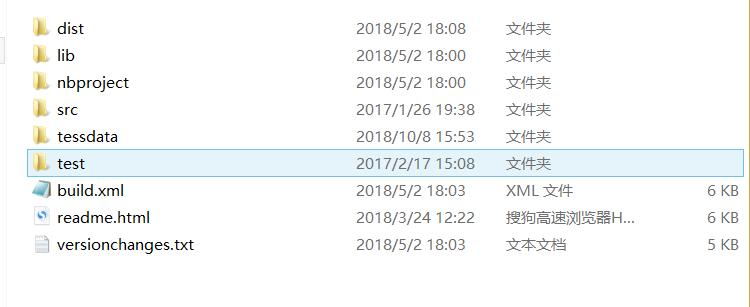
- dist:综合jar,不需要配置dll
- lib:所有相关的jar包
- src:源码包
- tessdata:训练好的字体模型
- test:测试用例
这里要把dist下的jar包和lib下的jar包都要导入Java项目中
3.一个Demo
File file = new File("D:\\1.jpg");
ITesseract instance = new Tesseract();
instance.setDatapath("...");//设置你的Tess4J下的tessdata目录
instance.setLanguage("eng");//指定需要识别的语种
String result = instance.doOCR(file);
System.out.println(result);
- 其中语种就在tessdata目录下
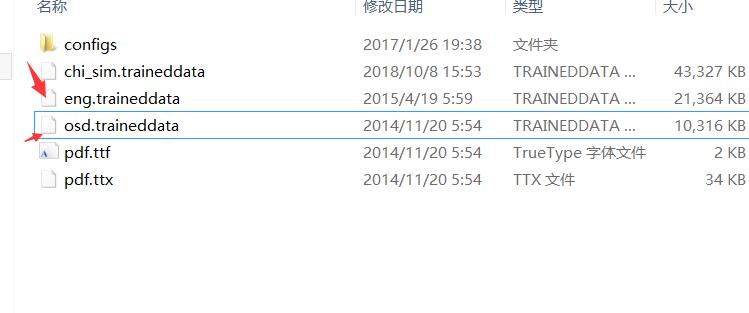
- 你如果要识别的是其他语种
- 可以去其他语种.把对应的traineddata下载放这里
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/132239.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
