大家好,又见面了,我是你们的朋友全栈君。
该系统为基于协同过滤算法的Django电影推荐系统, 点击跳转 详情介绍如下所示。
技术介绍
- 前端: bootstrap3 + jquery.js
- 后端: django 2.2.1 + djangorestframework(负责api部分)
- 数据库: mysql5.7 / sqlite3
- 算法: 基于用户的协同过滤/基于物品的协同过滤
数据集介绍
豆瓣数据集
基于requests的python爬虫去抓取豆瓣电影的电影信息,包含图片信息,总共2250部。
数据属性:
id,title ,image_link ,country ,years ,director_description,leader,star ,description,all_tags,imdb,language,time_length
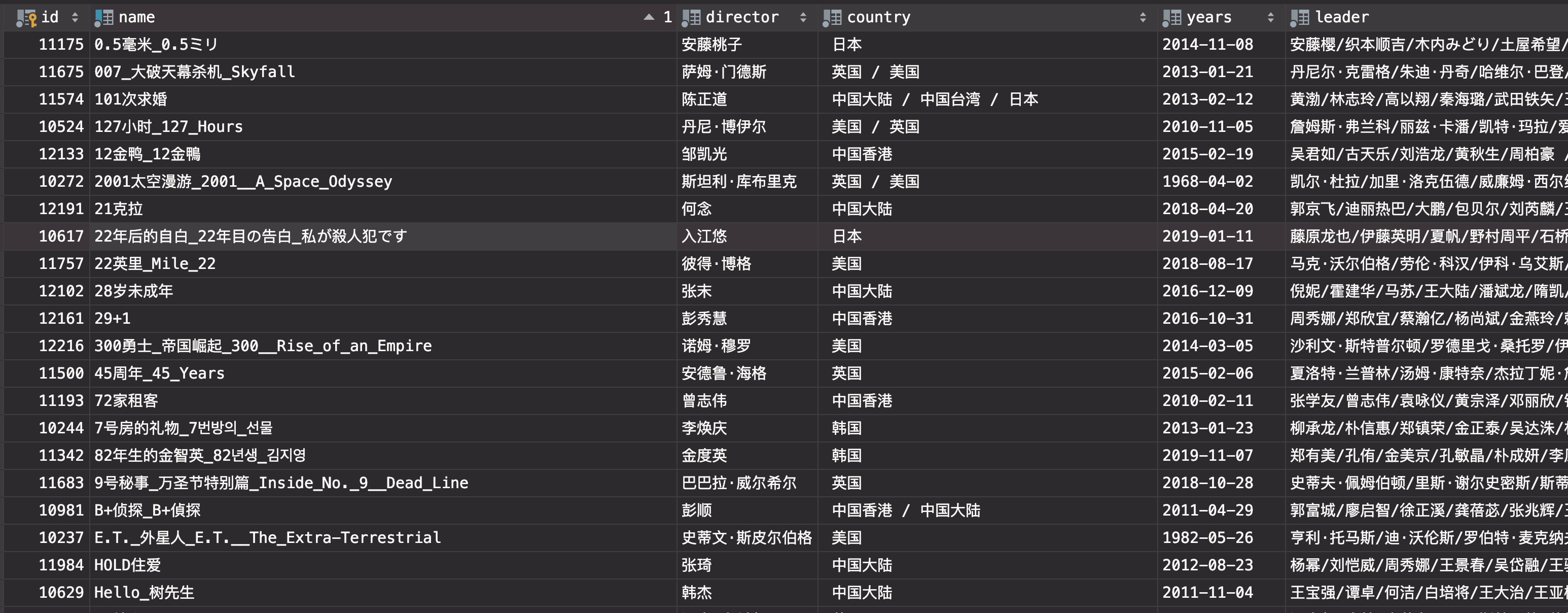

评分: 附带随机生成数据的脚本,可以随机生成指定数目的用户和用户的评分
movielens数据集
movielens 100k数据集+图片
数据维度: movieId,title,genres,picture
电影数量: 37544
评分数量: 93202+
movielens数据集+图片+用户数据和评分数据+csv存储
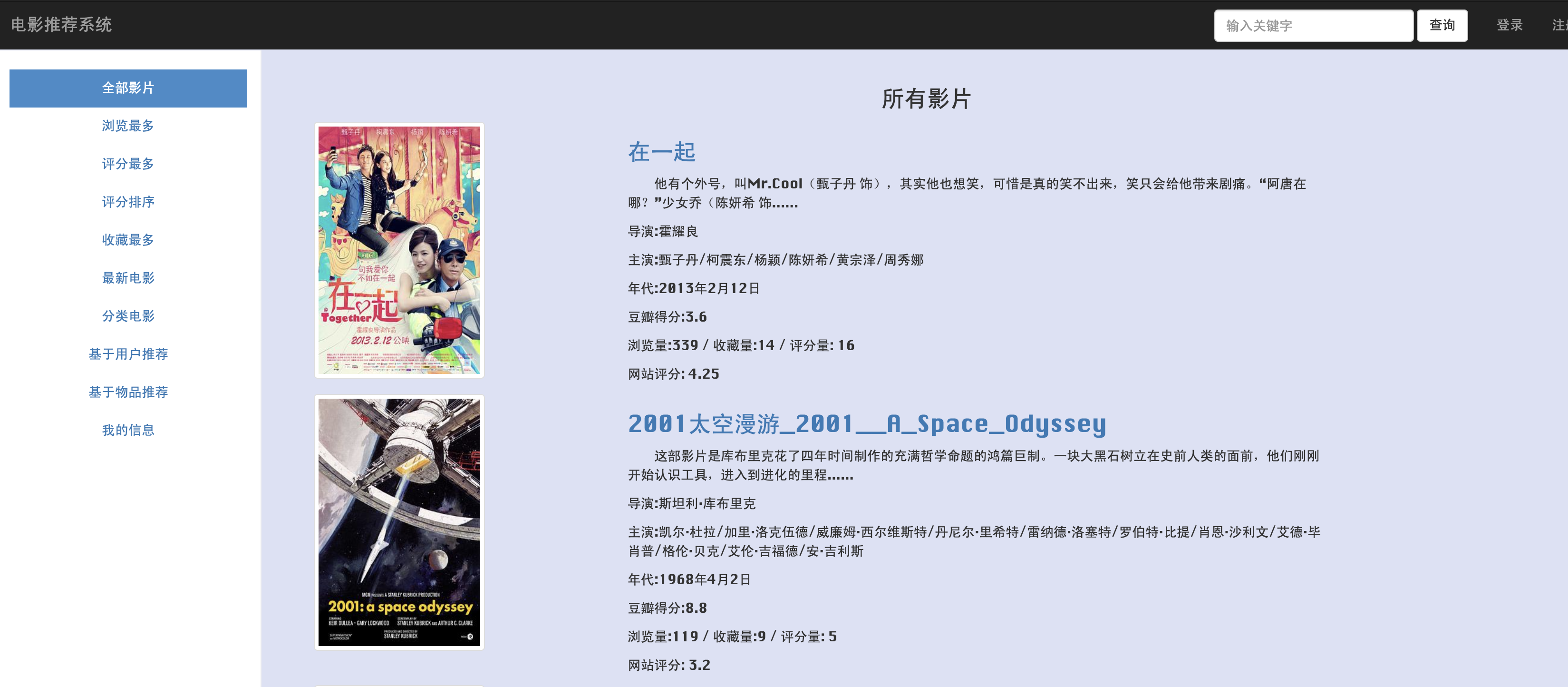
功能介绍
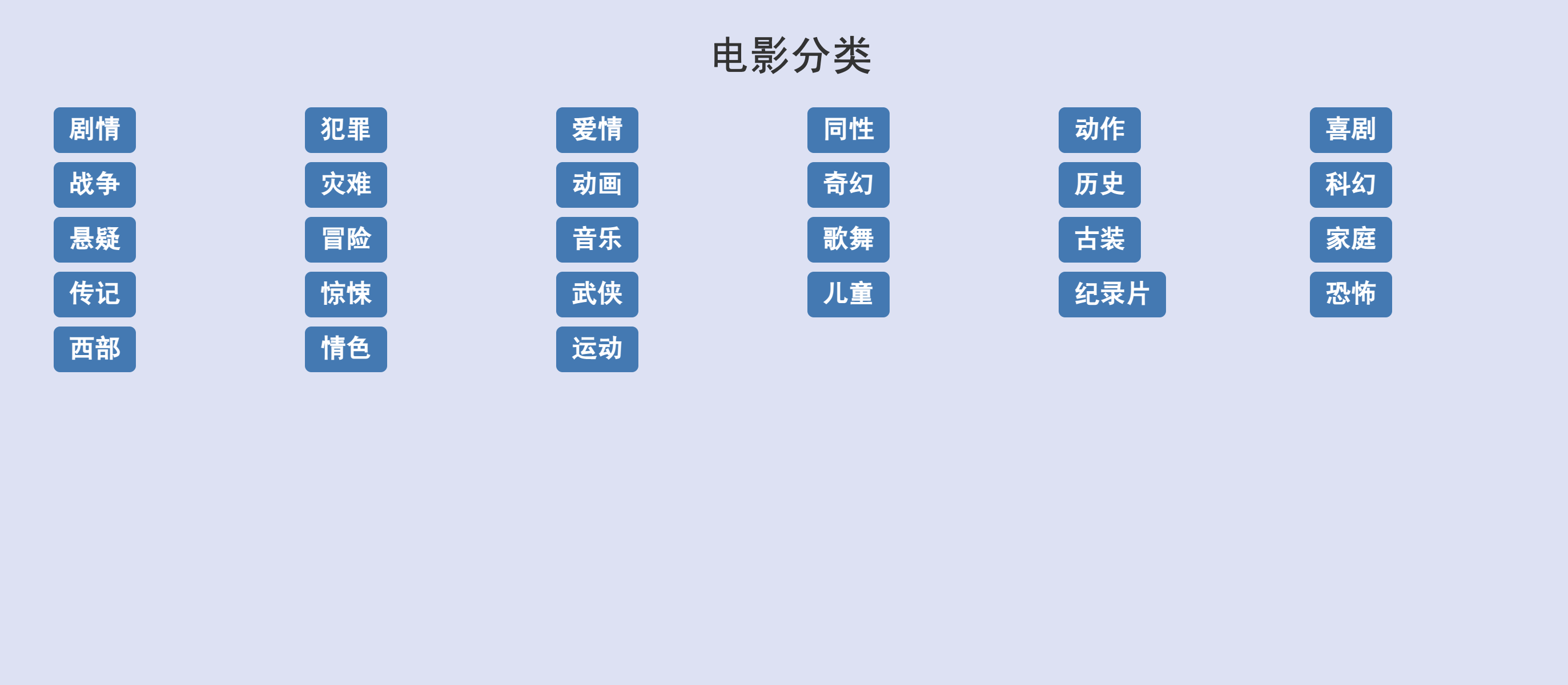
电影展示,电影搜索,标签分类
标签分类
用户的登录,注册,修改信息
用户注册界面

用户登录界面
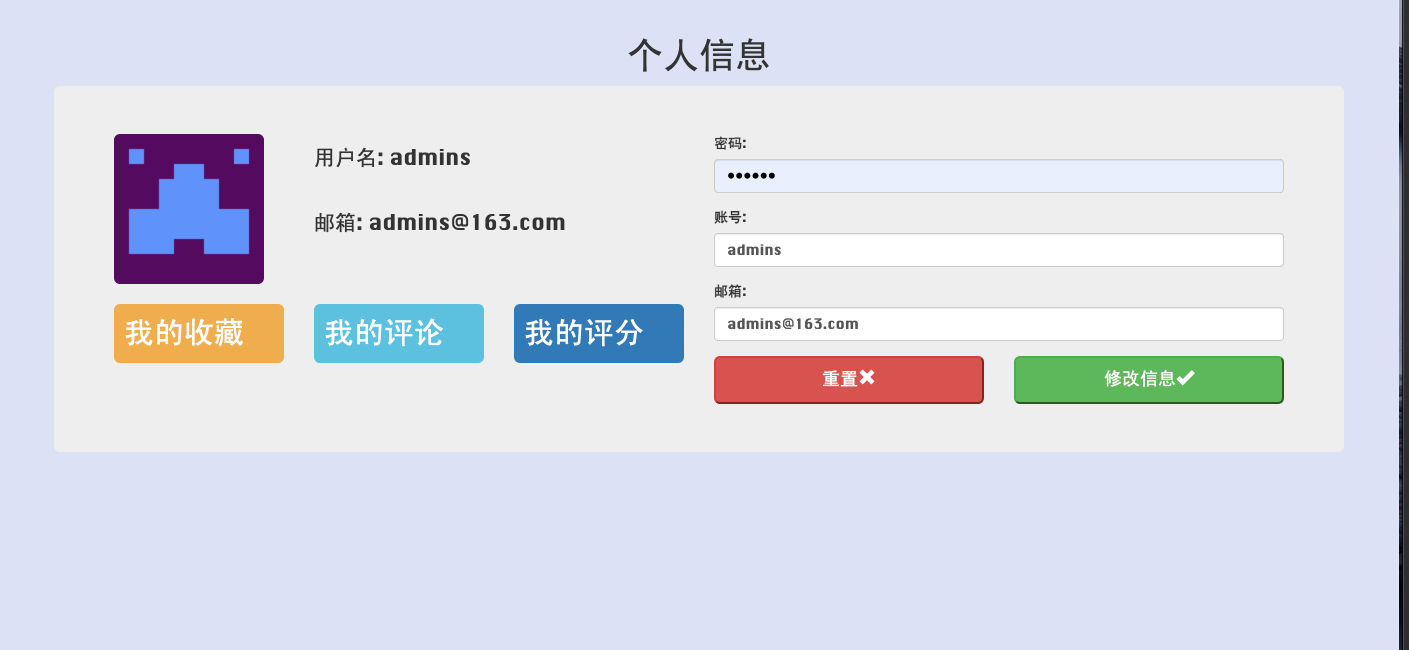
用户个人信息
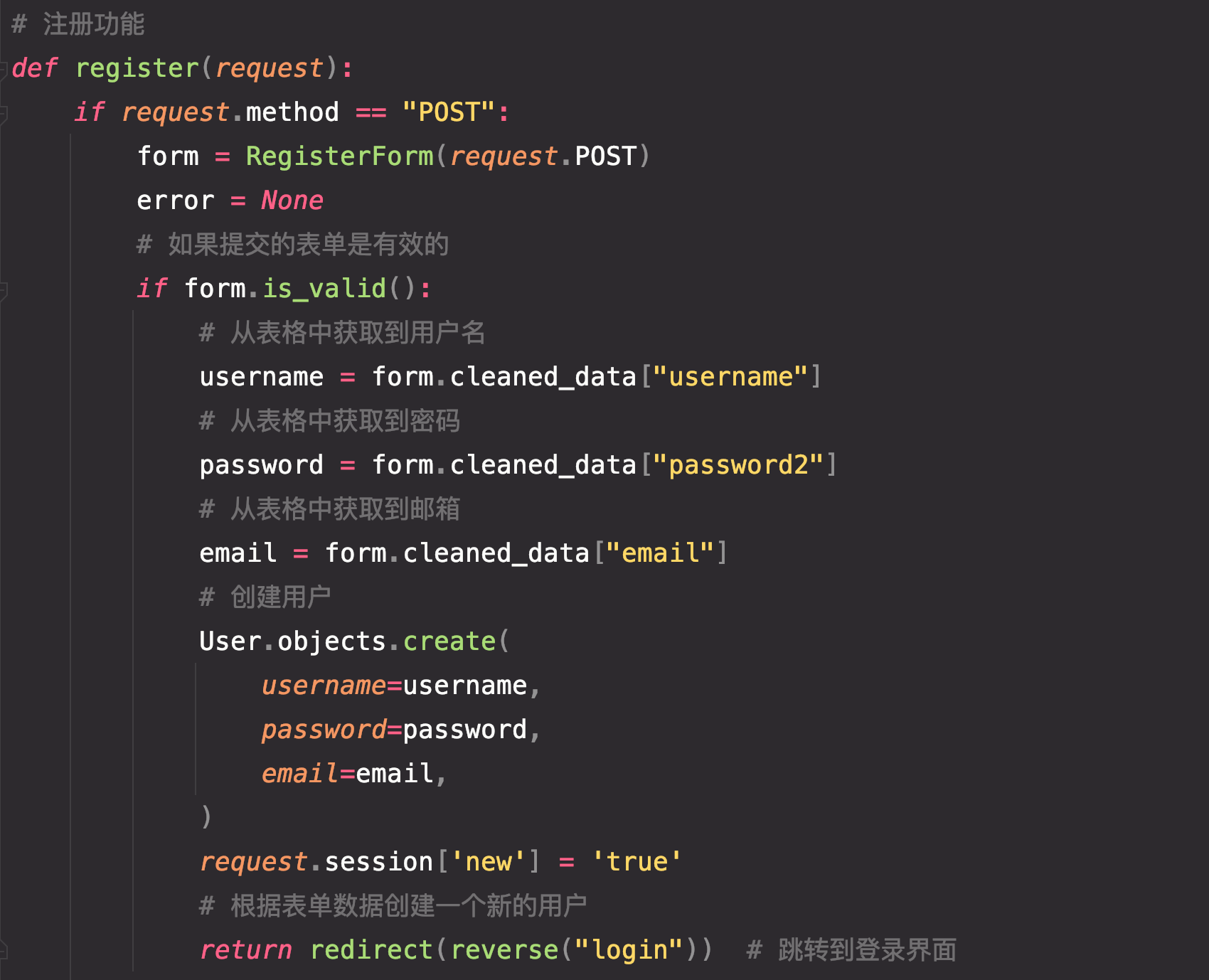
用户注册代码
用户对电影的打分,收藏和电影的详情页面

基于user和Item的协同过滤推荐算法,为用户推荐想看的电影
用户推荐界面

用户推荐部分代码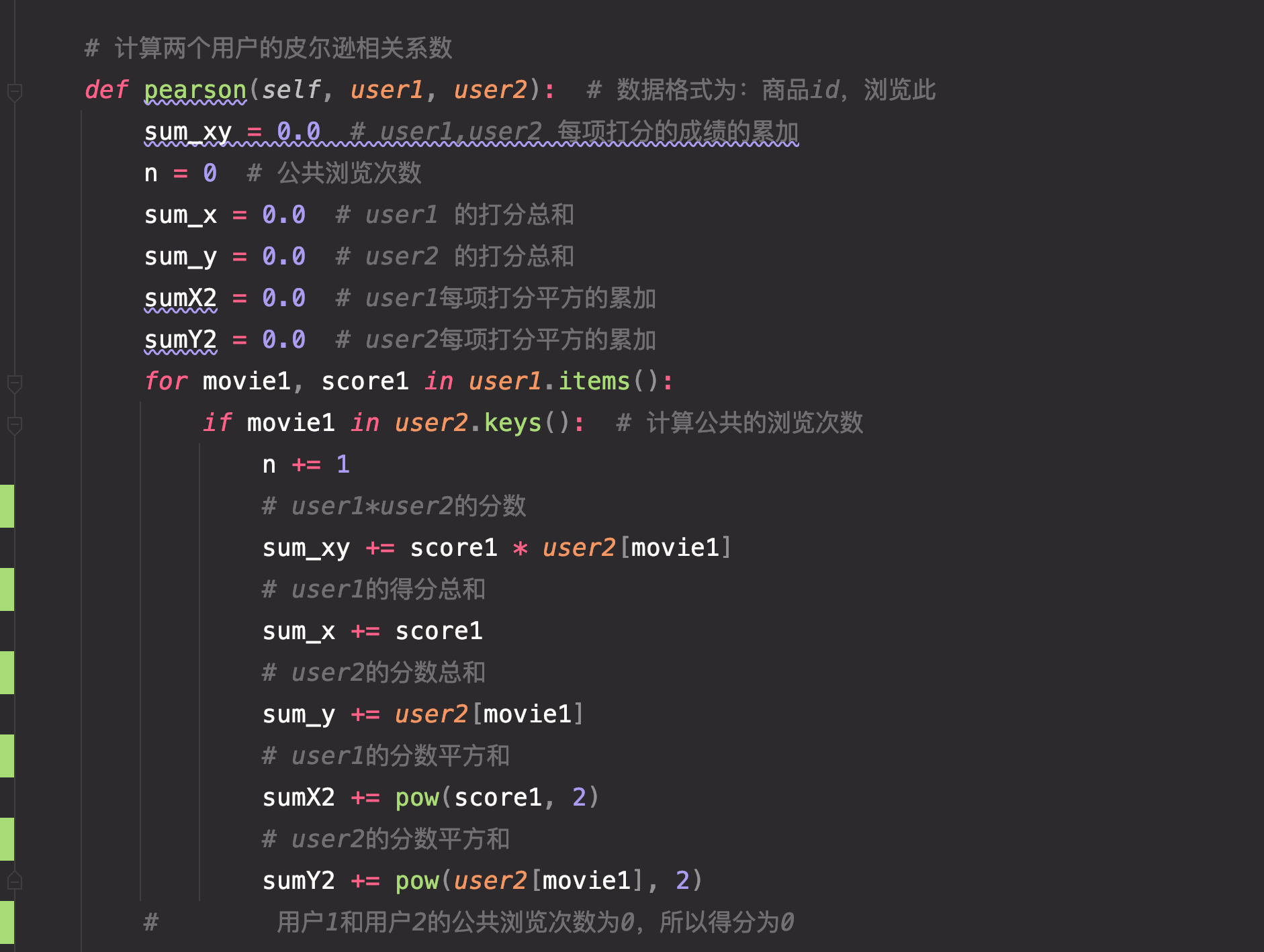
物品推荐界面

物品推荐部分代码
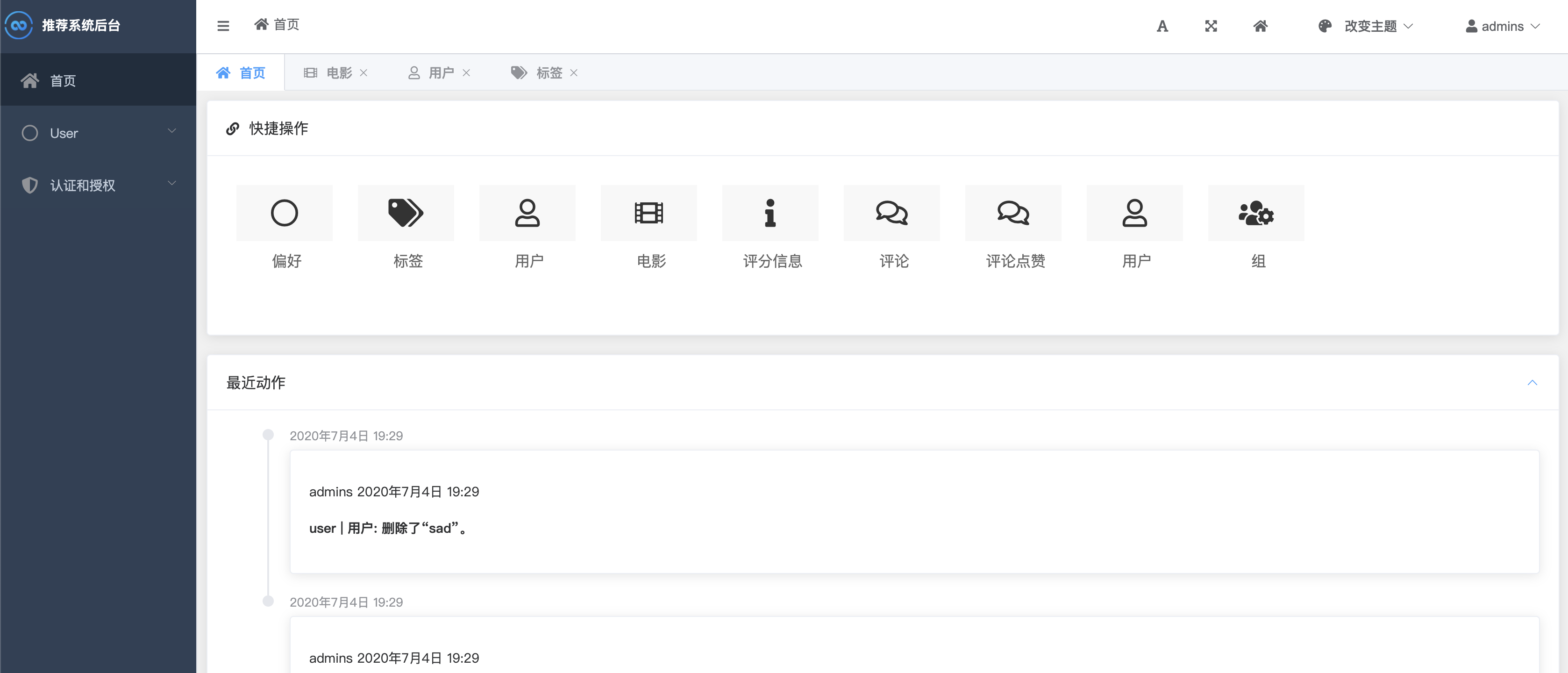
后台管理系统,可以进行电影信息的增删改查
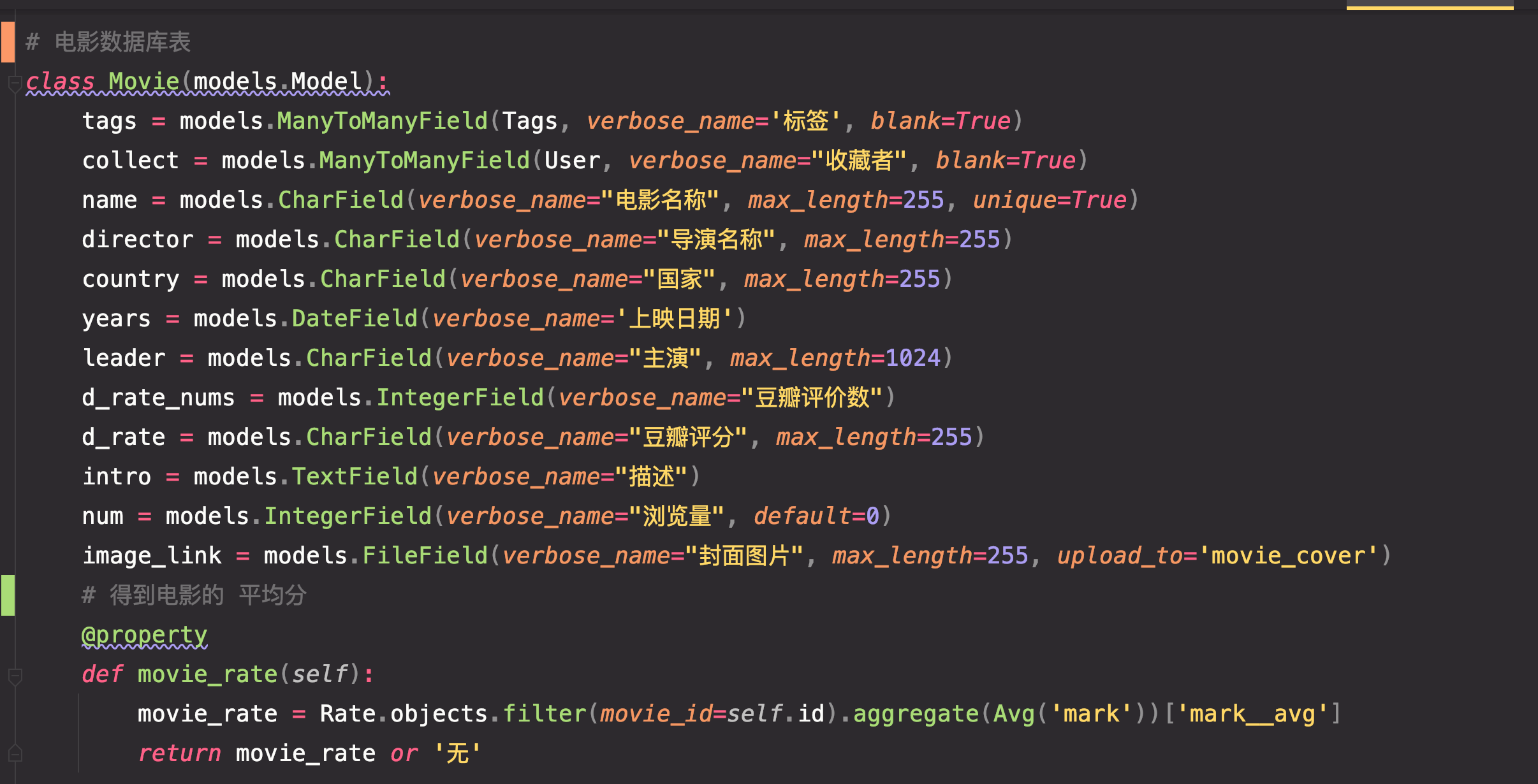
数据库模型代码
算法介绍
冷启动问题解决
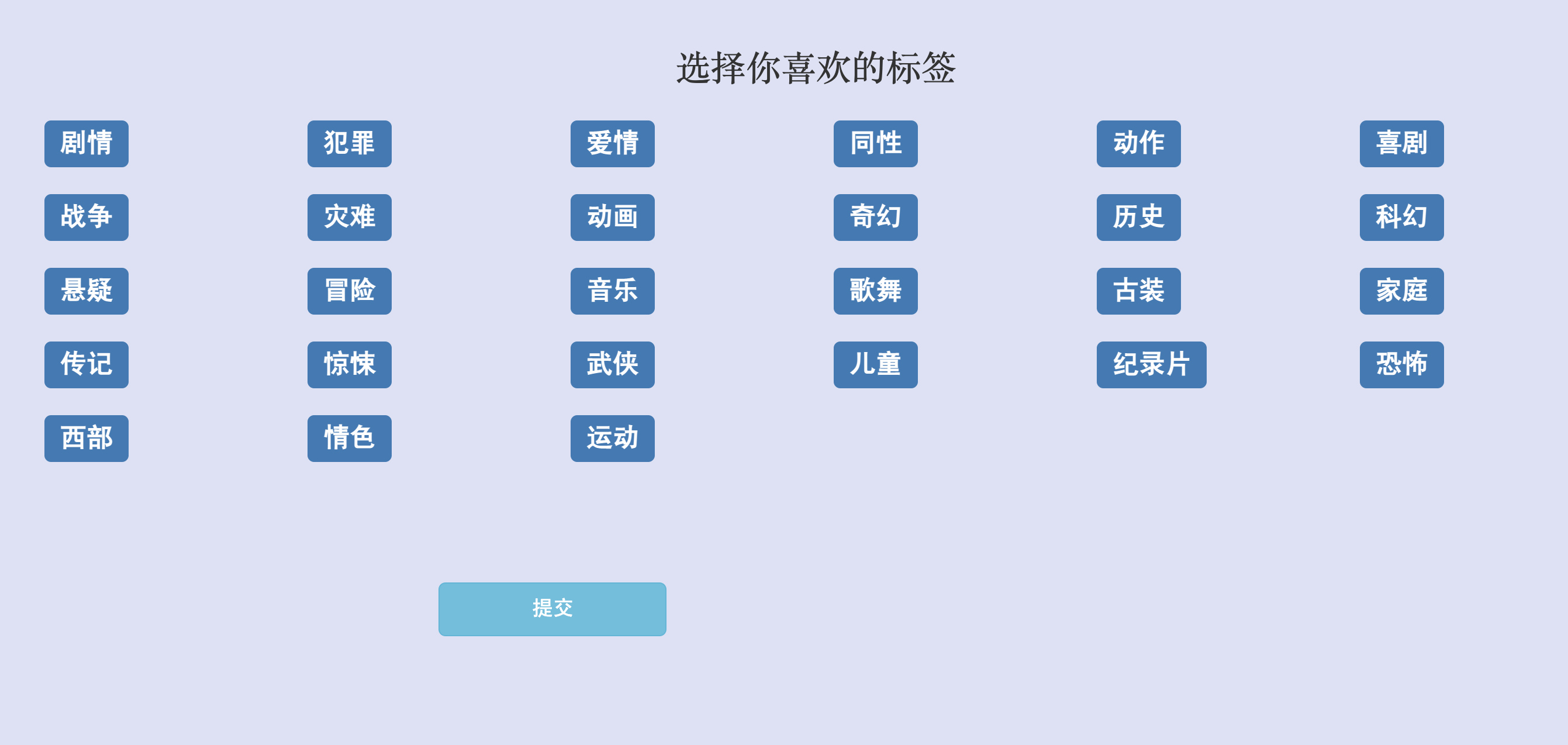
在用户首次注册的时候会为用户提供感兴趣的标签选择界面。然后在用户未进行打分的情况下,会为用户推荐喜欢标签的电影。
推荐算法改进—-结合标签的协同过滤推荐
在冷启动页面用户选择标签后将用户对这些标签标签的喜爱值设为5。
在用户为电影打分后,会根据此电影的标签来更新用户对标签喜爱值得分。
在根据协同过滤得到为用户推荐的电影后,如果推荐的电影数量不足15部,则从用户喜爱的标签中选取一部分电影来填充
更新标签喜爱值的策略将用户对电影的打分值减三然后加到喜爱值表中。
基于用户的协同过滤
算法: 协同过滤, 根据用户的打分来进行推荐。从所有打分的用户中找出和当前用户距离最近的n用户,然后从n个用户打分的电影中找15个当前用户未看过的电影。
最近距离算法通过协同过滤来实现。
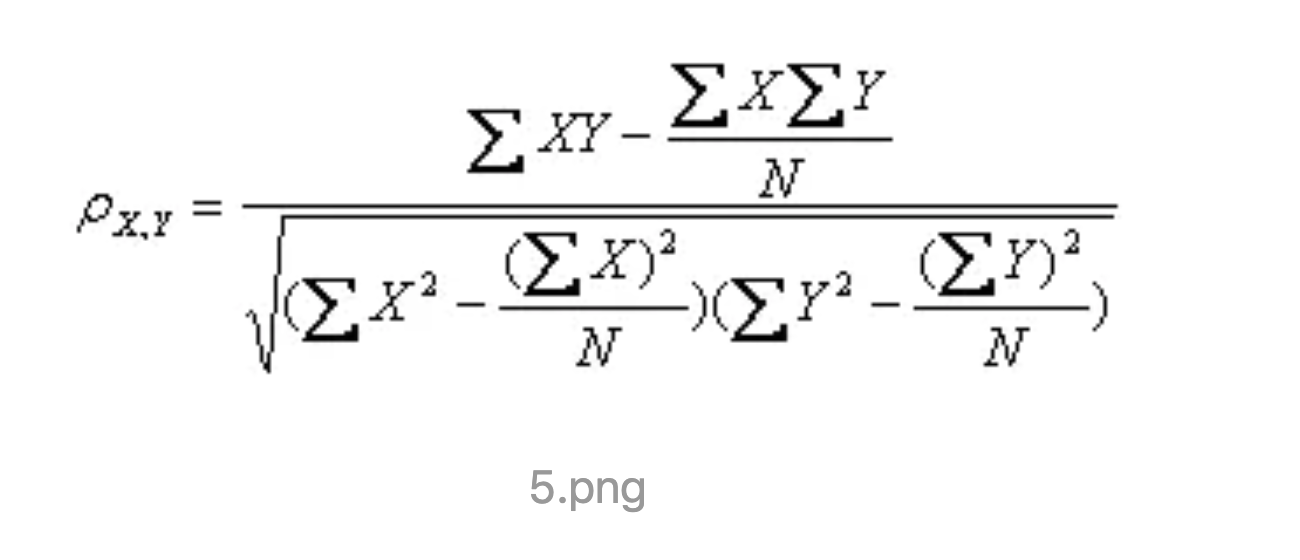
推荐算法—协同过滤 – 简书 此项目采用的是皮尔逊相关系数来计算相似度。采取基于用户模型的的协同过滤(Neighbor-based Collaborative Filtering)。
皮尔森距离公式:
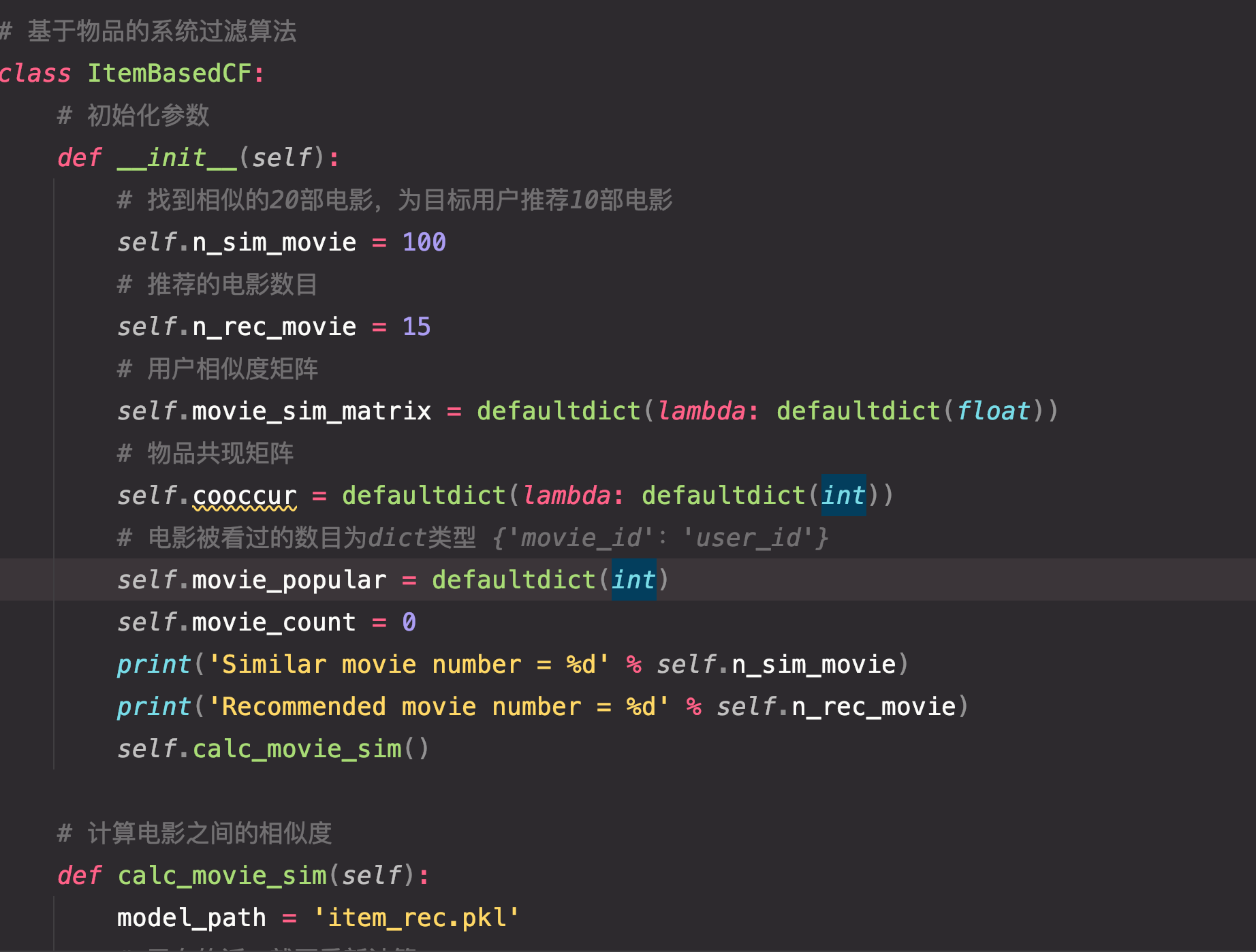
基于物品的协同过滤
计算物品之间的相似度,然后根据相似度来推荐
物品间的共现矩阵,两个物品同时被n个用户购买
物品间的相似度
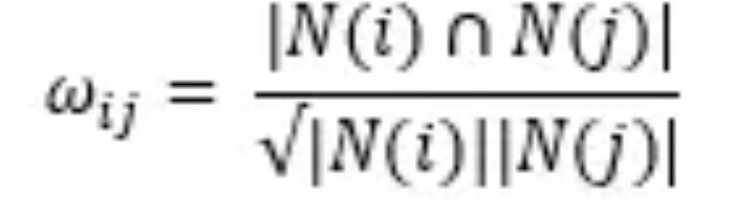
相似度:共现值/N的点赞值M的点赞值 开根号
推荐值: 相似度评分
根据用户点赞过得商品来寻找相似度推荐。
计算每个点赞过的物品和所有未点赞物品之间的得分。得分=相似度*打分值
得分越高表示越相似。 然后返回结果
基于tensorflow/文本卷积网络的推荐
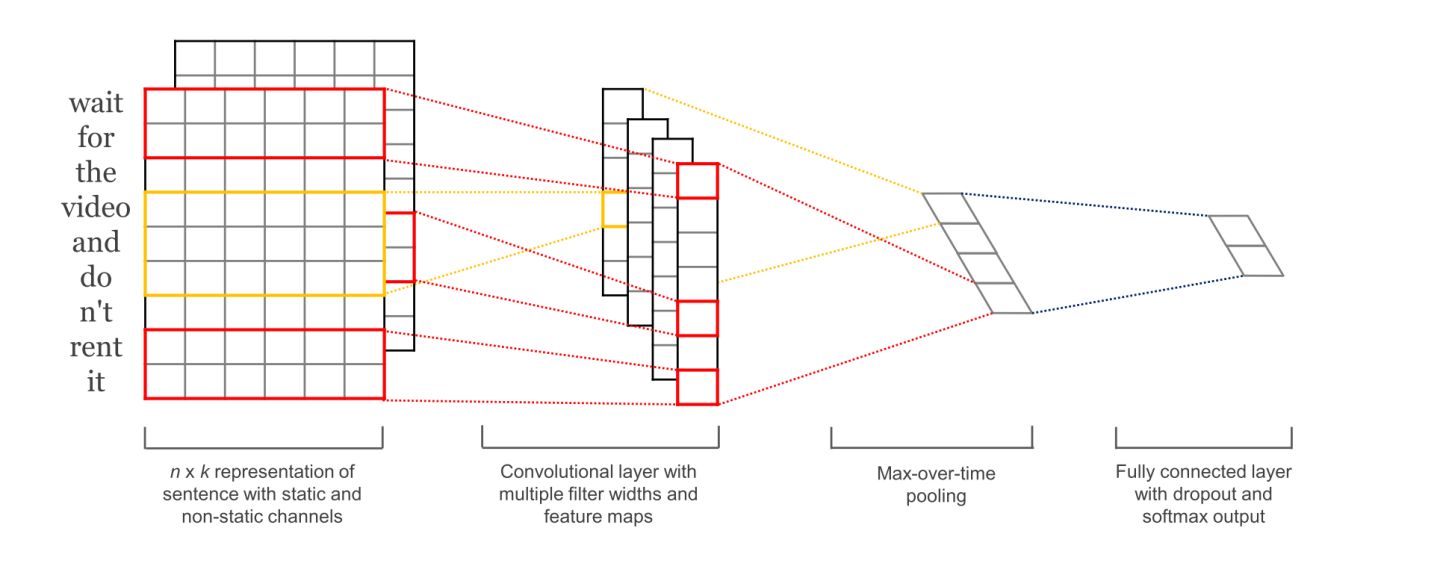
通过movielens所提供的用户信息: 年龄—性别—职业。这三个数据维度来刻画用户数据信息。然后构造文本卷积网络来生成模型。用户可以根据自己的年龄/性别等特征信息来得到个性化的推荐。
网络的第一层是词嵌入层,由每一个单词的嵌入向量组成的嵌入矩阵。下一层使用多个不同尺寸(窗口大小)的卷积核在嵌入矩阵上做卷积,窗口大小指的是每次卷积覆盖几个单词。这里跟对图像做卷积不太一样,图像的卷积通常用2×2、3×3、5×5之类的尺寸,而文本卷积要覆盖整个单词的嵌入向量,所以尺寸是(单词数,向量维度),比如每次滑动3个,4个或者5个单词。第三层网络是max pooling得到一个长向量,最后使用dropout做正则化,最终得到了电影Title的特征。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/132055.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
