大家好,又见面了,我是你们的朋友全栈君。
一,前言
卷积神经网络(Constitutional Neural Networks, CNN)是在多层神经网络的基础上发展起来的针对图像分类和识别而特别设计的一种深度学习方法。先回顾一下多层神经网络:

多层神经网络包括一个输入层和一个输出层,中间有多个隐藏层。每一层有若干个神经元,相邻的两层之间的后一层的每一个神经元都分别与前一层的每一个神经元连接。在一般的识别问题中,输入层代表特征向量,输入层的每一个神经元代表一个特征值。
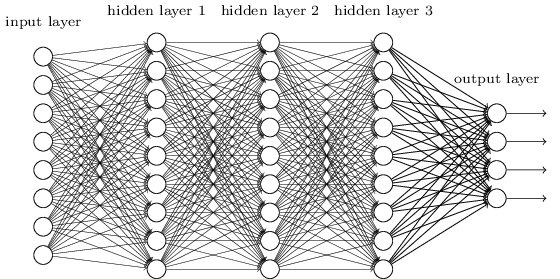
在图像识别问题中,输入层的每一个神经元可能代表一个像素的灰度值。但这种神经网络用于图像识别有几个问题,一是没有考虑图像的空间结构,识别性能会受到限制;二是每相邻两层的神经元都是全相连,参数太多,训练速度受到限制。
而卷积神经网络就可以解决这些问题。卷积神经网络使用了针对图像识别的特殊结构,可以快速训练。因为速度快,使得采用多层神经网络变得容易,而多层结构在识别准确率上又很大优势。
二,卷积神经网络的结构
卷积神经网络有三个基本概念:局部感知域(local receptive fields),共享权重(shared weights)和池化(pooling)。
局部感知域: 在上图中的神经网络中输入层是用一列的神经元来表示的,在CNN中,不妨将输入层当做二维矩阵排列的神经元。
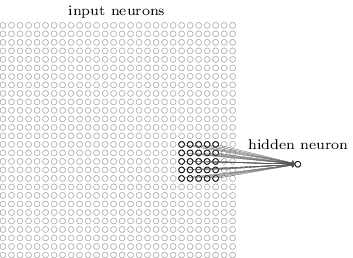
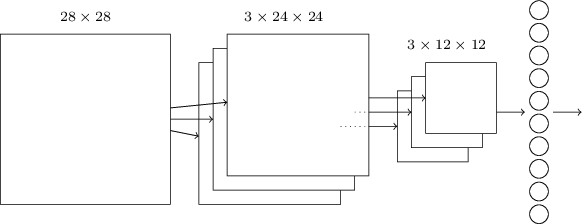
与常规神经网络一样,输入层的神经元需要和隐藏层的神经元连接。但是这里不是将每一个输入神经元都与每一个隐藏神经元连接,而是仅仅在一个图像的局部区域创建连接。以大小为28X28的图像为例,假如第一个隐藏层的神经元与输入层的一个5X5的区域连接,如下图所示:
这个5X5的区域就叫做局部感知域。该局部感知域的25个神经元与第一个隐藏层的同一个神经元连接,每个连接上有一个权重参数,因此局部感知域共有5X5个权重。如果将局部感知域沿着从左往右,从上往下的顺序滑动,就会得对应隐藏层中不同的神经元,如下图分别展示了第一个隐藏层的前两个神经元与输入层的连接情况。
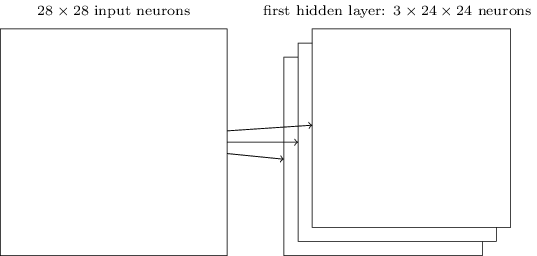
如果输入层是尺寸为28X28的图像,局部感知域大小为5X5,那么得到的第一个隐藏层的大小是24X24。


共享权重: 上面得到的第一隐藏层中的24X24个神经元都使用同样的5X5个权重。第 j 个隐藏层中第
k
这里
σ
是神经元的激励函数(可以是sigmoid函数、thanh函数或者rectified linear unit函数等)。
b
是该感知域连接的共享偏差。
wl,m
是个5X5共享权重矩阵。因此这里有26个参数。
ax,y
代表在输入层的
x,y
处的输入激励。
这就意味着第一个隐藏层中的所有神经元都检测在图像的不同位置处的同一个特征。因此也将从输入层到隐藏层的这种映射称为特征映射。该特征映射的权重称为共享权重,其偏差称为共享偏差。
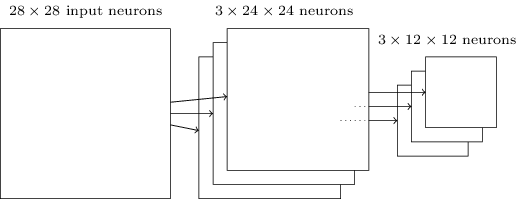
为了做图像识别,通常需要不止一个的特征映射,因此一个完整的卷积层包含若干个不同的特征映射。下图中是个三个特征映射的例子。
在实际应用中CNN可能使用更多的甚至几十个特征映射。以MNIST手写数字识别为例,学习到的一些特征如下:
这20幅图像分别对应20个不同的特征映射(或称作filters, kernels)。每一个特征映射由5X5的图像表示,代表了局部感知域中的5X5个权重。亮的像素点代表小的权重,与之对应的图像中的像素产生的影响要小一些。暗的像素点代表的大的权重,也意味着对应的图像中的像素的影响要大一些。可以看出这些特征映射反应了某些特殊的空间结构,因此CNN学习到了一些与空间结构有关的信息用于识别。

池化层(pooling layers) 池化层通常紧随卷积层之后使用,其作用是简化卷积层的输出。例如,池化层中的每一个神经元可能将前一层的一个2X2区域内的神经元求和。而另一个经常使用的max-pooling,该池化单元简单地将一个2X2的输入域中的最大激励输出,如下图所示:
如果卷积层的输出包含24X24个神经元,那么在池化后可得到12X12个神经元。每一个特征映射后分别有一个池化处理,前面所述的卷积层池化后的结构为:
Max-pooling并不是唯一的池化方法,另一种池化方法是 L2−pooling ,该方法是将卷积层2X2区域中的神经元的输出求平方和的平方根。尽管细节与Max-pooling不一样,但其效果也是简化卷积层输出的信息。

将上述结构连接在一起,再加上一个输出层,得到一个完整的卷积神经网络。在手写数字识别的例子中输出层有十个神经元,分别对应0,1, … ,9的输出。
网络中的最后一层是一个全连接层,即该层的每个神经元都与最后一个Max-pooling层的每个神经元连接。
这个结构这是一个特殊的例子,实际CNN中也可在卷积层和池化层之后可再加上一个或多个全连接层。
三,卷积神经网络的应用
3.1 手写数字识别
Michael Nielsen提供了一个关于深度学习和CNN的在线电子书,并且提供了手写数字识别的例子程序,可以在GitHub上下载到。该程序使用Python和Numpy, 可以很方便地设计不同结构的CNN用于手写数字识别,并且使用了一个叫做Theano的机器学习库来实现后向传播算法和随机梯度下降法,以求解CNN的各个参数。Theano可以在GPU上运行,因此可大大缩短训练过程所需要的时间。CNN的代码在network3.py文件中。
作为一个开始的例子,可以试着创建一个仅包含一个隐藏层的神经网络,代码如下:
>>> import network3
>>> from network3 import Network
>>> from network3 import ConvPoolLayer, FullyConnectedLayer, SoftmaxLayer
>>> training_data, validation_data, test_data = network3.load_data_shared()
>>> mini_batch_size = 10
>>> net = Network([
FullyConnectedLayer(n_in=784, n_out=100),
SoftmaxLayer(n_in=100, n_out=10)], mini_batch_size)
>>> net.SGD(training_data, 60, mini_batch_size, 0.1,
validation_data, test_data)该网络有784个输入神经元,隐藏层有100个神经元,输出层有10个神经元。在测试数据上达到了97.80%的准确率。
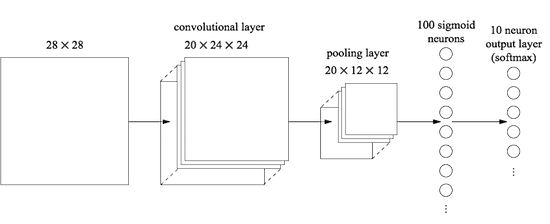
如果使用卷积神经网络会不会比它效果好呢?可以试一下包含一个卷积层,一个池化层,和一个额外全连接层的结构,如下图
在这个结构中,这样理解:卷积层和池化层学习输入图像中的局部空间结构,而后面的全连接层的作用是在一个更加抽象的层次上学习,包含了整个图像中的更多的全局的信息。
>>> net = Network([
ConvPoolLayer(image_shape=(mini_batch_size, 1, 28, 28),
filter_shape=(20, 1, 5, 5),
poolsize=(2, 2)),
FullyConnectedLayer(n_in=20*12*12, n_out=100),
SoftmaxLayer(n_in=100, n_out=10)], mini_batch_size)
>>> net.SGD(training_data, 60, mini_batch_size, 0.1,
validation_data, test_data) 这种CNN的结构达到的识别准确率为98.78%。如果想进一步提高准确率,还可以从以下几方面考虑:
- 再添加一个或多个卷积-池化层
- 再添加一个或多个全连接层
- 使用别的激励函数替代sigmoid函数。比如Rectifed Linear Units函数: f(z)=max(0,z). Rectified Linear Units函数相比于sigmoid函数的优势主要是使训练过程更加快速。
- 使用更多的训练数据。Deep Learning因为参数多而需要大量的训练数据,如果训练数据少可能无法训练出有效的神经网络。通常可以通过一些算法在已有的训练数据的基础上产生大量的相似的数据用于训练。例如可以将每一个图像平移一个像素,向上平移,向下平移,向左平移和向右平移都可以。
- 使用若干个网络的组合。创建若干个相同结构的神经网络,参数随机初始化,训练以后测试时通过他们的输出做一个投票以决定最佳的分类。其实这种Ensemble的方法并不是神经网络特有,其他的机器学习算法也用这种方法以提高算法的鲁棒性,比如Random Forests。
3.2 ImageNet图像分类
Alex Krizhevsky等人2012年的文章“ImageNet classification with deep convolutional neural networks”对ImageNet的一个子数据集进行了分类。ImageNet一共包含1500万张有标记的高分辨率图像,包含22,000个种类。这些图像是从网络上搜集的并且由人工进行标记。从2010年开始,有一个ImageNet的图像识别竞赛叫做ILSVRC(ImageNet Large-Scale Visual Recognition Challenge)。 ILSVRC使用了ImageNet中的1000种图像,每一种大约包含1000个图像。总共有120万张训练图像,5万张验证图像(validation images)和15万张测试图像(testing images)。该文章的方法达到了15.3%的错误率,而第二好的方法错误率是26.2%。
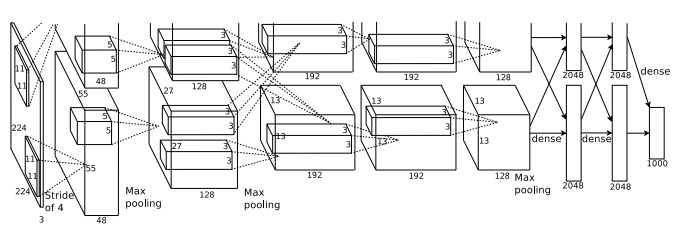
这篇文章中使用了7个隐藏层,前5个是卷积层(有些使用了max-pooling),后2个是全连接层。输出层是有1000个单元的softmax层,分别对应1000个图像类别。
该CNN使用了GPU进行计算,但由于单个GPU的容量限制,需要使用2个GPU (GTX 580,分别有3GB显存)才能完成训练。
该文章中为了防止过度拟合,采用了两个方法。一是人工生成更多的训练图像。比如将已有的训练图像进行平移或者水平翻转,根据主成分分析改变其RGB通道的值等。通过这种方法是训练数据扩大了2048倍。二是采用Dropout技术。Dropout将隐藏层中随机选取的一半的神经元的输出设置为0。通过这种方法可以加快训练速度,也可以使结果更稳定。
输入图像的大小是224X224X3,感知域的大小是11X11X3。第一层中训练得到的96个卷积核如上图所示。前48个是在第一个GPU上学习到的,后48个是在第二个GPU上学习到的。

3.3 医学图像分割
Adhish Prasoon等人在2013年的文章“Deep feature learning for knee cartilage segmentation using a triplanar convolutional neural network”中,用CNN来做MRI中膝关节软骨的分割。传统的CNN是二维的,如果直接扩展到三维则需要更多的参数,网络更复杂,需要更长的训练时间和更多的训练数据。而单纯使用二维数据则没有利用到三维特征,可能导致准确率下降。为此Adhish采用了一个折中方案:使用 xy , yz 和 xz 三个2D平面的CNN并把它们结合起来。
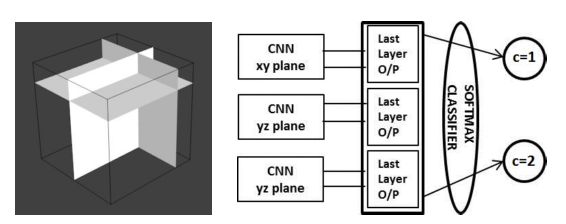
三个2D CNN分别负责对 xy , yz 和 xz 平面的处理,它们的输出通过一个softmax层连接在一起,产生最终的输出。该文章中采用了25个病人的图像作为训练数据,每个三维图像中选取4800个体素,一共得到12万个训练体素。相比于传统的从三维图像中人工提取特征的分割方法,该方法在精度上有明显的提高,并且缩短了训练时间。
3.4 谷歌围棋AlphaGo战胜人类
谷歌旗下DeepMind团队使用深度卷积神经网络在电脑围棋上取得了重大突破。早期,IBM的深蓝超级计算机通过强大的计算能力使用穷举法战胜了人类专业象棋选手,但那不算“智能”。
围棋上的计算复杂度远超象棋,即使通过最强大的计算机也无法穷举所有的可能的走法。计算围棋是个极其复杂的问题,比国际象棋要困难得多。围棋最大有3^361 种局面,大致的体量是10^170,而已经观测到的宇宙中,原子的数量才10^80。国际象棋最大只有2^155种局面,称为香农数,大致是10^47。
DeepMind所研究的AlphaGo使用了卷积神经网络来学习人类下棋的方法,最终取得了突破。AlphaGo在没有任何让子的情况下以5:0完胜欧洲冠军,职业围棋二段樊麾。研究者也让AlphaGo和其他的围棋AI进行了较量,在总计495局中只输了一局,胜率是99.8%。它甚至尝试了让4子对阵Crazy Stone,Zen和Pachi三个先进的AI,胜率分别是77%,86%和99%。可见AlphaGo有多强大。
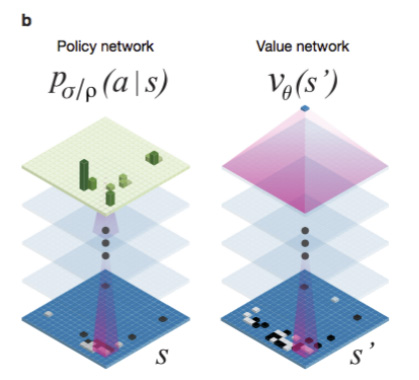
在谷歌团队的论文中,提到“我们用19X19的图像来传递棋盘位置”,来“训练”两种不同的深度神经网络。“策略网络”(policy network)和 “值网络”(value network)。它们的任务在于合作“挑选”出那些比较有前途的棋步,抛弃明显的差棋,从而将计算量控制在计算机可以完成的范围里,本质上和人类棋手所做的一样。
其中,“值网络”负责减少搜索的深度——AI会一边推算一边判断局面,局面明显劣势的时候,就直接抛弃某些路线,不用一条道算到黑;而“策略网络”负责减少搜索的宽度——面对眼前的一盘棋,有些棋步是明显不该走的,比如不该随便送子给别人吃。利用蒙特卡洛拟合,将这些信息放入一个概率函数,AI就不用给每一步以同样的重视程度,而可以重点分析那些有戏的棋着。
参考论文:David Silver, et al. “Mastering the game of Go with deep neural networks and tree search.” Nature doi:10.1038/nature16961.
相关链接:http://www.guokr.com/article/441144/
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/132009.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
