大家好,又见面了,我是你们的朋友全栈君。
Iterative Shrinkage Thresholding Algorithm(ISTA)
ISTA
对于一个基本的线性逆问题:
y = A x + w (1) {y}={A} {x}+{w}\tag{1} y=Ax+w(1)
其中 A ∈ R M × N A\in \mathbb{R}^{M\times N} A∈RM×N, y ∈ R M × 1 y\in \mathbb{R}^{M\times 1} y∈RM×1, w w w是未知噪声。(1)式可用最小二乘法来求解:
x ^ L S = arg mi x n ∥ A x − y ∥ 2 2 (2) \hat{
{x}}_{L S}=\underset{
{x}}{\arg \operatorname{mi}} n\|{A} {x}-{y}\|_{2}^{2}\tag{2} x^LS=xargmin∥Ax−y∥22(2)
当 M = N M=N M=N 且 A A A 非奇异时,最小二乘法的解等价于 A − 1 y A^{-1}y A−1y。然而,在很多情况下, A A A 是病态的(ill-conditioned)。最小二乘是一种无偏估计方法,如果系统是病态的,则会导致其估计方差很大,因此最小二乘法不适用于求解病态方程。
为了求解病态线性系统的逆问题,可以使用岭回归。岭回归方法的主要思想是以可容忍的微小偏差来换取估计的良好效果,实现方差和偏差的一个trade-off。岭回归求解病态问题可以表示为:
x ^ T = arg min x 1 2 ∥ A x − y ∥ 2 2 + λ ∥ x ∥ 2 2 (3) \hat{
{x}}_{T}=\underset{
{x}}{\arg \min} \frac{1}{2}\|{A x}-{y}\|_{2}^{2}+\lambda\|{x}\|_{2}^{2}\tag{3} x^T=xargmin21∥Ax−y∥22+λ∥x∥22(3)
其中 λ > 0 \lambda >0 λ>0 为正则化参数。
另一种求解(1)式的方法是采用 ℓ 1 \ell_1 ℓ1范数作为正则项,这就是经典的LASSO问题:
x ^ = arg min x ∥ A x − y ∥ 2 2 + λ ∥ x ∥ 1 (4) \hat{
{x}}=\underset{
{x}}{\arg \operatorname{min}} \|{A} {x}-{y}\|_{2}^{2}+\lambda\|{x}\|_{1}\tag{4} x^=xargmin∥Ax−y∥22+λ∥x∥1(4)
采用 ℓ 1 \ell_1 ℓ1范数正则项相对于 ℓ 2 \ell_2 ℓ2 范数正则项有两个优势:
- ℓ 1 \ell_1 ℓ1范数正则项能产生稀疏解;
- 对异常值不敏感。
式(4)是一个凸优化问题,通常可以转化为二阶锥规划问题,从而使用内点法等方法求解。然而在大规模问题中,由于数据维度太大,而内点法的算法复杂度为 O ( N 3 ) O(N^3) O(N3),导致求解非常耗时。由于基于梯度的方法算法复杂度小,而且算法结构简单,容易操作,很多研究者研究通过简单的基于梯度的方法来求解(4)式。
在众多基于梯度的算法中,ISTA算法是一种非常受关注的算法,ISTA算法在每一次迭代中通过一个收缩/软阈值操作来更新 x x x,其具体迭代格式如下:
x k + 1 = S α λ ( x k + α A T ( y − A x k ) ) x k + 1 = S λ L ( x k + 1 L A T ( y − A x k ) ) ( α = 1 L ) (5) \begin{aligned} x^{k+1}&=S_{\alpha \lambda}\left(x^{k}+\alpha A^{T}(y-A x^{k})\right)\\\tag{5} x^{k+1}&=S_{\frac{\lambda}{L}}\left(x^{k}+\frac{1}{L} A^{T}(y-A x^{k})\right)\quad (\alpha=\frac{1}{L}) \end{aligned} xk+1xk+1=Sαλ(xk+αAT(y−Axk))=SLλ(xk+L1AT(y−Axk))(α=L1)(5)
PS:第二个式子就是 α = 1 L \alpha=\frac{1}{L} α=L1时的情况,论文中证明只有当 L ≥ σ m a x ( D T D ) L \geq \sigma_{max}(D^TD) L≥σmax(DTD)时,才能保证收敛性, 其中 σ m a x ( A ) \sigma_{max}(A) σmax(A)表示 A A A 的最大特征值。
其中 S θ ( x ) S_{\theta}(x) Sθ(x) 是软阈值操作函数:
S θ ( x ) = sign ( x ) ⋅ max ( ∣ x ∣ − θ , 0 ) (6) S_{\theta}(x)=\operatorname{sign}(x) \cdot \max (|x|-\theta, 0)\tag{6} Sθ(x)=sign(x)⋅max(∣x∣−θ,0)(6)
下面我们对式(5)进行推导:
首先,对于式(5),我们记:
arg min x f ( x ) : = arg min x 1 2 ( A x − y ) T ( A x − y ) + λ ∥ x ∥ 1 (7) \mathop {\arg \min }\limits_xf(x):=\mathop {\arg \min }\limits_x \frac{1}{2}{(Ax – y)^T}(Ax – y) + \lambda {\left\| x \right\|_1}\tag{7} xargminf(x):=xargmin21(Ax−y)T(Ax−y)+λ∥x∥1(7)
其中, f ( x ) f(x) f(x)的第一项可以看作时重构项,第二项可以看作是正则化项。对于该优化问题,我们可以很容易想到利用梯度下降法来求解。
首先,对 f f f 求 x x x 的偏导:
∂ f ∂ x = ∂ f 1 ∂ x + ∂ f 2 ∂ x = A T ( A x − y ) + λ sign ( x ) (8) \frac{\partial f}{\partial x} =\frac{\partial f_{1}}{\partial x}+\frac{\partial f_{2}}{\partial x} =A^{T}(A x-y)+\lambda \operatorname{sign}(x)\tag{8} ∂x∂f=∂x∂f1+∂x∂f2=AT(Ax−y)+λsign(x)(8)
对于第一项:
x k + 1 = x k − α A T ( A x − y ) (9) x^{k+1}=x^{k}-\alpha A^{T}(A x-y)\tag{9} xk+1=xk−αAT(Ax−y)(9)
对于第二项:
x k + 1 = x k − α λ sign ( x ) (10) x^{k+1}=x^{k}-\alpha \lambda \operatorname{sign}(x)\tag{10} xk+1=xk−αλsign(x)(10)
但是,符号函数 s i g n ( z ) sign(z) sign(z) 在 0 处是不可微的!怎么处理?
ISTA做了如下处理:
shrink ( x , α λ ) : { i f s i g n ( x ) ≠ s i g n ( x − α λ s i g n ( x ) ) : t h e n x = 0 e l s e : x = x − α λ s i g n ( x ) (11) \operatorname{shrink}(x,\alpha\lambda):\left\{ {\begin{aligned} &{if\ {\mathop{\rm sign}\nolimits} (x) \ne {\mathop{\rm sign}\nolimits} (x – \alpha \lambda {\mathop{\rm sign}\nolimits} (x)):then\;x = 0}\\ &{else:x = x – \alpha \lambda {\mathop{\rm sign}\nolimits} (x)} \end{aligned}} \right.\tag{11} shrink(x,αλ):{
if sign(x)=sign(x−αλsign(x)):thenx=0else:x=x−αλsign(x)(11)
简单来说,因为 ℓ 1 \ell_1 ℓ1范数在0附近不可微,所以就将0的邻域设置为可微!下图其实就是收缩算子的图像。
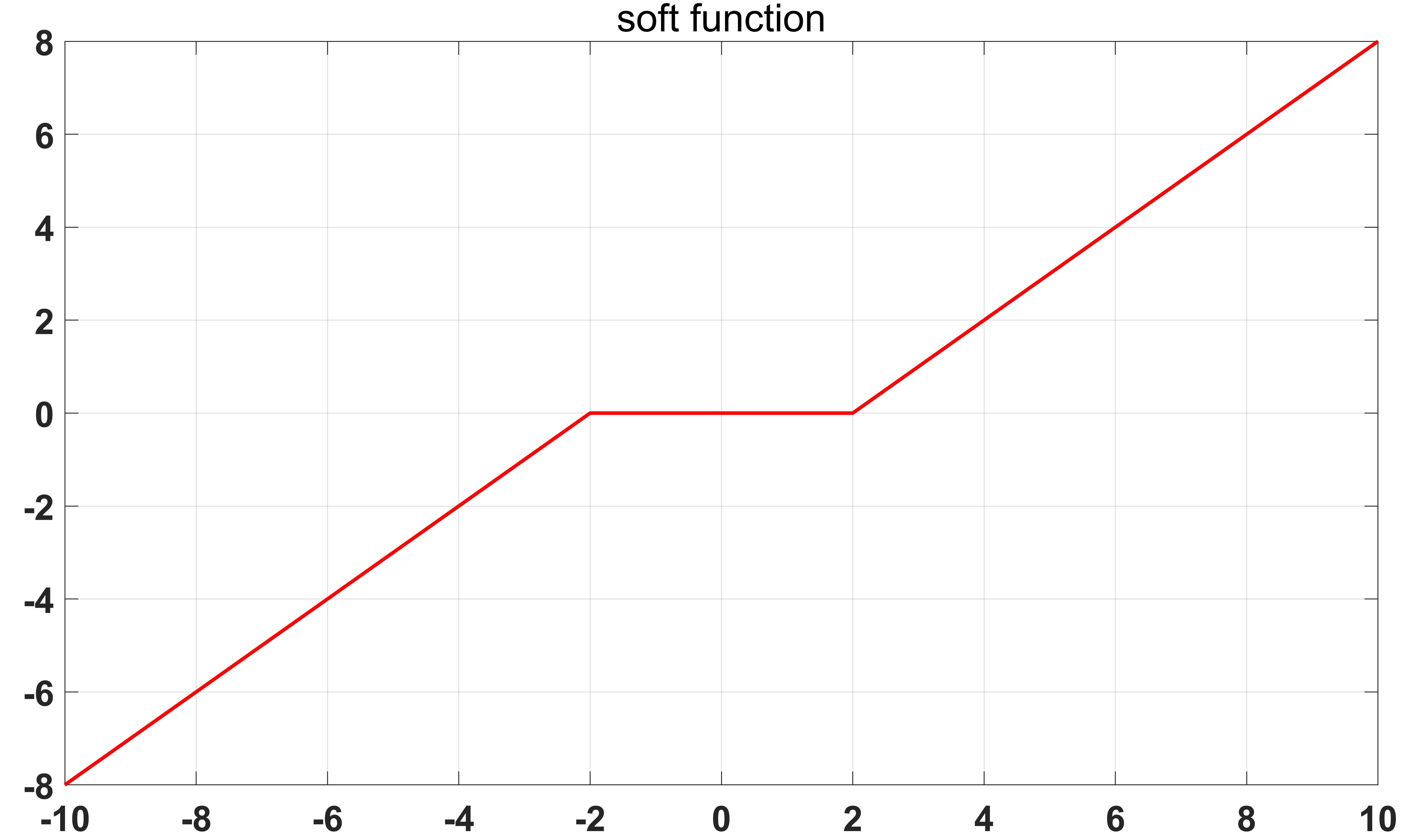

上面的两项的处理过程概括起来就是ISTA算法:
- 初始化 x ( 0 ) = 0 x^{(0)} = 0 x(0)=0
- 当 x ( k ) x^(k) x(k)未收敛
- x k = x k − α A T ( A x − y ) x^{k}=x^{k}-\alpha A^{T}(A x-y) xk=xk−αAT(Ax−y)
- x k + 1 = shrink ( x k , α λ ) x^{k+1}=\operatorname{shrink}\left(x^{k}, \alpha \lambda\right) xk+1=shrink(xk,αλ)
其实带进去算一下,就可以知道 shrink ( x k , α λ ) \operatorname{shrink}\left(x^{k}, \alpha \lambda\right) shrink(xk,αλ)其实就是上面的 S θ ( x ) S_{\theta}(x) Sθ(x),所以ISTA可以总结如下:
x k + 1 = S α λ ( x k + α A T ( y − A x k ) ) S θ ( x ) = sign ( x ) ⋅ max ( ∣ x ∣ − θ , 0 ) (12) \begin{aligned} x^{k+1}&=S_{\alpha \lambda}\left(x^{k}+\alpha A^{T}(y-A x^{k})\right)\\ S_{\theta}(x)&=\operatorname{sign}(x) \cdot \max (|x|-\theta, 0)\tag{12} \end{aligned} xk+1Sθ(x)=Sαλ(xk+αAT(y−Axk))=sign(x)⋅max(∣x∣−θ,0)(12)
证明完毕。
参考文献
- Beck A, Teboulle M. A fast iterative shrinkage-thresholding algorithm for linear inverse problems[J]. SIAM journal on imaging sciences, 2009, 2(1): 183-202.
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/132007.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
